
激光诱导击穿光谱技术对烟草快速分类研究
2019-10-22 11:30:00李昂泽王宪双徐向君何雅格柳宇飞刘瑞斌
中国光学 2019年5期
李昂泽,王宪双,徐向君,何雅格,郭 帅,柳宇飞,郭 伟,刘瑞斌*
(1.北京理工大学 物理学院,北京 100081;2.宝瑞激光科技(常州)有限公司,江苏 常州 213000)
1 引 言
我国有近3.15 亿烟民,香烟的市场巨大,如何提高烟草品质控制是各大烟草公司关注的问题。特别是对一些名贵香烟,市场中充斥着大量的假烟,因缺少快速简便的鉴定方法,不法商家以次充好,欺骗消费者的行为层出不穷。因此有必要研究出一种快速、精确、可靠的香烟种类识别方法。
国内外研究人员对烟草的品质鉴定及管控已展开较多研究,在烟草品质评价和分级上也取得较大的进展。如南华大学的邓晨曦[1]等人通过分析烟草化学成分,利用萤火虫群优化模糊聚类的烟草品质集成分类方法,使烟草品质分类精度上有了较大的提高,并且随着烟草样本数量的增加,分类精度也相应得到提升;北京工业大学的张媛媛[2]等人使用颜色向量表示不同品牌的香烟图像,提取网格图像的颜色空间中的色调直方图标准差作为特征值,构成颜色特征向量,再通过欧氏距离来划分最优的网格数量,组成香烟图像特征向量集合,基于朴素贝叶斯分类器与高斯混合模型分类器进行分类,分类的准确率分别为69%和91%;沈阳农业大学的吴琼[3]等人利用高光谱成像技术,采集了7种香烟的光谱图像,通过对香烟烟丝进行对比分析,很直观地辨别了7种香烟的烟丝色泽和分布信息状况的变化,进而发现这7种香烟烟丝的差异。
以上研究表明香烟的识别具有一定可行性。激光诱导击穿光谱(Laser-Induced Break down Spectroscopy,LIBS)与分类算法相结合的方法也是一种灵敏准确的分析方法。目前,鲜有人使用该方法进行香烟的分类。
LIBS由于具有检测速度快、无需样品处理、对样品损伤小等特点,近年来已经越来越多地应用到水体污染[4-6]、土壤分析[7]、工业评估[8]、食品安全[9-10]、环境检测[11]、考古学[12]、医药分析[13]等物质检测领域。目前利用LIBS检测技术快速评价产品质量和快速分类待测样品已经成为LIBS领域实际应用的热点。
本文相较于其他分类工作拥有以下几个创新点:烟草的快速实时分类,特别是对原始烟叶的快速检测是优化烟丝质量的重要手段,但一直没有适当的高准确度的方法,本文尝试采用LIBS结合SVM的方法,对烟草样品的分类效果证实了LIBS在未来烟草市场应用的可行性;光谱数据处理方面,对特征峰峰位的漂移进行了修正;基于LIBS光谱,对市面上九种香烟按照产地、品牌、焦油含量以及尼古丁含量的不同分别建立分类模型,并获得了准确率较高的判别模型,对香烟的快速识别和准确分类提供了一个较好的方法。
2 实验过程
2.1 实验样品

图1 样品图 Fig.1 Sample pictures
本实验所用香烟有Esse、红梅(HM)、大前门(DQM)、金满堂(JMT)、云烟(YY)、中南海(ZNH)、黄鹤楼(HHL)、芙蓉王(FRW)、中华(ZH)等9种市场上典型的香烟,其产地、价位、品质等方面各不相同。每个品牌的香烟选取两支香烟,将其烟丝取出并用粉碎机粉碎15 s,将粉末状烟丝的颗粒直径控制在200 μm左右。然后用压饼机(压强为15 MPa,作用时间2 min)将样品压成半径为10 mm,厚度为2 mm的饼状,如图1所示。9种香烟的理化值参数如表1所示。

表1 9种香烟的理化参数
2.2 实验装置

图2 实验装置 (M:反射镜) Fig.2 Experimental set-up(M:mirror)
实验装置如图2所示,激光器为主动调Q的Nd∶YAG(QUANTEL,France)固体激光器,波长为1 064 nm,频率为1 Hz,脉宽为7 ns,激光出射能量为30 mJ(最大能量输出100 mJ);光谱仪为三通道光纤光谱仪(Avantes),光谱分辨率为0.1 nm,实验过程中积分时间为1.05 ms;DG535数字延迟脉冲发生器为激光器和光谱仪提供精准的外触发信号,3个通道的光谱采集延迟分别为768.8、769.7和769.66 μs。图2中激光经过反射镜(M)反射调整光路后,经直径为25.4 mm、焦距为60 mm的透镜聚焦到样品表面,收集装置与激光聚焦方向成45°进行光信号收集,并将收集到的光耦合至光纤,再传输至三通道光纤光谱仪完成光谱的分光与光电转换[14]。实验前,先用能量计监测激光脉冲能量波动,直至激光能量波动稳定在5%以内。每种样品的光谱采集都在同样的试验条件下,分别进行320次脉冲打样作为待处理的数据。
香烟样品的等离子体谱图信息如图3所示,根据美国国家标准与技术研究院(NIST)的标准原子光谱数据库,对其元素组成进行了鉴定和标记。根据光谱图可知香烟中主要包含的元素有C、H、Na、Mg、Al、K、Ca等元素。

图3 等离子体发射光谱图 Fig.3 Plasma emission spectra
3 结果与分析
对采集到的LIBS光谱进行处理,建模的具体步骤如下:光谱数据预处理、主成分分析(PCA)、训练集和测试集比例选取、使用训练集训练SVM分类器、SVM分类器对测试集测试分类。
3.1 光谱数据的预处理
对于光谱数据进行预处理,首先删除一些无效数据,本文将波动较大,相对标准偏差(RSD)大于60%的数据视为无效。光谱波动较大除了激光能量抖动外还可能是由于聚焦位置的改变和基体效应的影响;接着对光谱数据进行重组,每4个光谱数据取平均作为一组光谱数据,进一步减少测量的不确定性。重组后,对每个样品的80组数据,进行去背景处理,消除光谱背景常用插值法和窗口平移平滑方法[15]。但是插值法去除背景得到的光谱存在光谱信息丢失,如特征峰的相对强度改变、峰的半高宽信息丢失、峰与峰之间的差异性消失、个别带状分子峰丢失等。因此使用了窗口平滑去背景得到了去背景之后的光谱图[14,16]。其主要过程如下:
(1)将光谱强度视为N个数据点群,即所有的光谱强度是在CCD像素点上光强度的表现;
(2)分割数据点群。将N个数据点群分为n个小点群,即平滑窗口宽度为n,其中
log2n=c(c∈N+) ,
(1)

(3)寻找极值点,找出i组数据中每组中的最小值Li,满足:

(2)
(4)去除背景,将hi组中n个数据点减去极小值Li作为最终光谱强度;
(5)链接窗口,把得到的i组消除背景的数据点按照(2)的逆向操作链接为新的光谱。

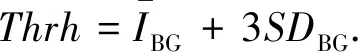
(3)
寻峰处理是将非峰值强度置为零,提高了信号的对比度,峰位漂移的情况在线谱中更容易辨别。由于光谱仪的仪器误差,测量的光谱中,特征峰位有时会有一个像素点的漂移。对比某一列(p列)光谱与其后一列(p+1列)光谱的特征峰的个数,将峰位出现次数较多的那一列作为正常峰位,与其相邻的峰位较少的一列被认为是峰位漂移的结果。此时,需要将漂移的峰位移至正常峰位,得到峰位漂移修正光谱[16]。最后对预处理之后的数据进行光谱数据的归一化,把数据处理成[-1,1]之间,归一化的公式为:

(4)
其中,y为某一幅光谱各个波长处的强度值,min(y)为光谱中强度最小的值,max(y)为光谱中强度最大的值。
图4为原始光谱与预处理光谱的对比图。
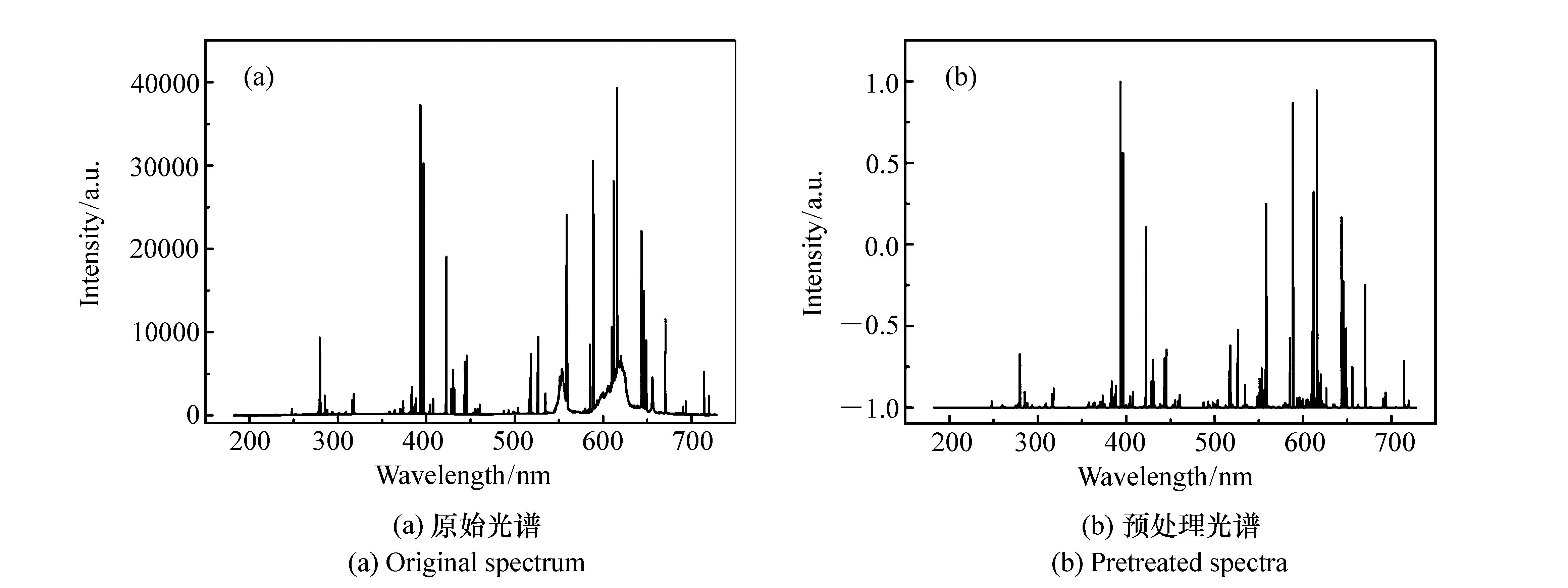
图4 香烟LIBS光谱 Fig.4 Laser-induced breakdown spectra of cigarettes
3.2 主成分分析
预处理后每个样本共计80组光谱数据,每组数据包含6 144个光强,最终得到一个720×6 144的矩阵Z,对矩阵Z进行PCA分析。PCA分析的步骤如下[17]:
(1)对样本数据进行标准化。原始数据标准化采用p维随机变量,选取n个样品,构造样本阵,对样本阵进行如下标准变换:

(5)

(2)计算相关系数矩阵R

(6)

(3)求出协方差矩阵的特征值和特征向量
AR=λR,
(7)
其中,λ称为R的特征值,非零向量R称为A对应于特征值λ的特征向量;
(4)根据主成分贡献率选择主成分;
(5)计算主成分得分。
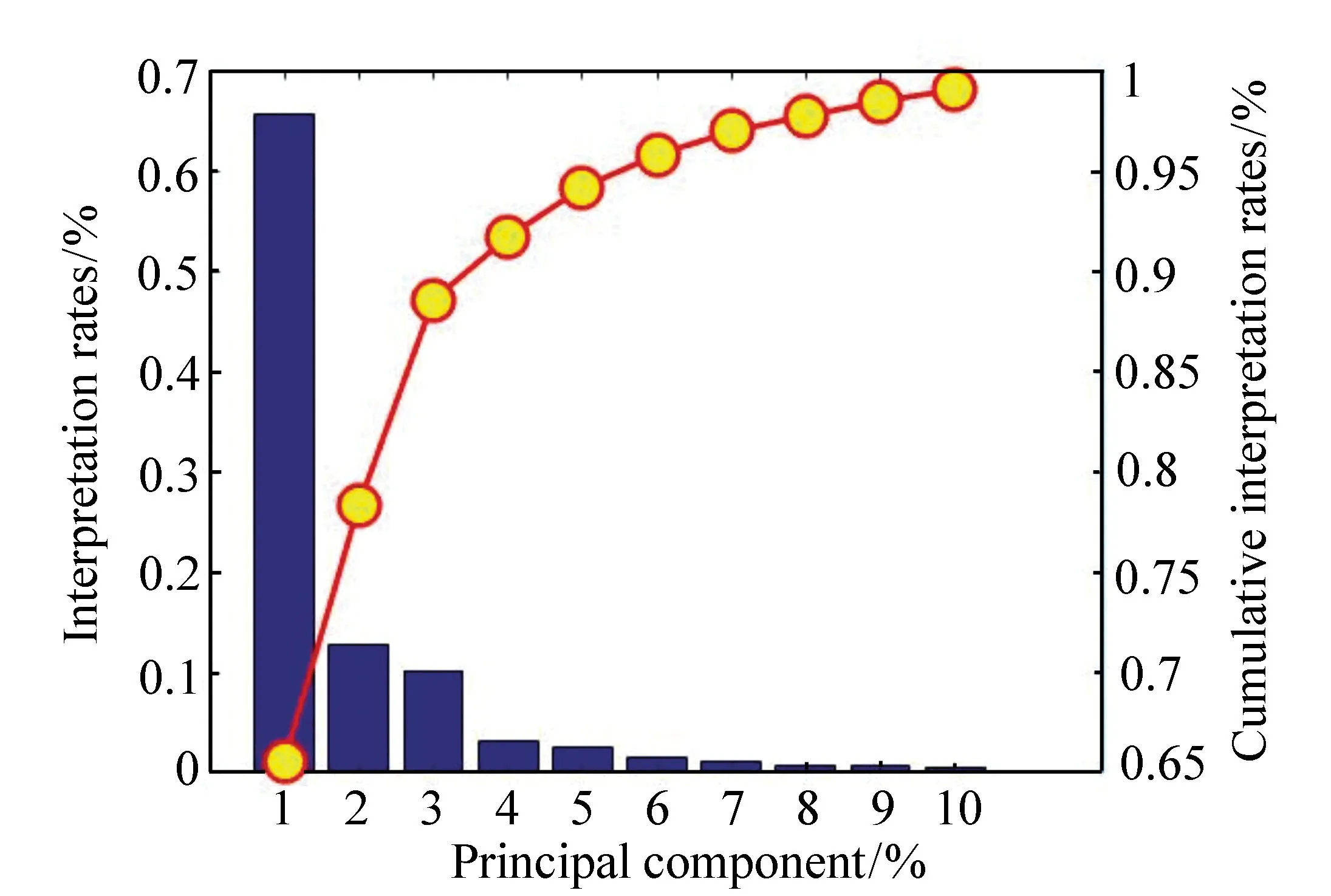
图5 每个主成分得分和主成分累积得分 Fig.5 Each principal component score and principal component cumulative score
通过对香烟LIBS光谱进行PCA分析,得到每个主成分的贡献率和累积贡献率,如图5所示。
由图可知,香烟的前十个主成分贡献之和达到了99.04%,表明使用前10个主成分足以涵盖这种香烟光谱的大部分信息。利用全谱进行SVM分类模型训练,每个光谱所选取的特征点都在十维特征空间中分布。图6(彩图见期刊电子版)给出了前3个主成分组成的三维得分图,每个散点代表一个样本,显示出较好的聚类效果,可以看出,同种香烟的特征点出现明显聚集,可以互相区分。

图6 9种香烟前3个主成分的散点分布图 Fig.6 Scatter diagram of the first three principal components for 9 types of cigarettes
3.3 支持向量机分类方法的研究
支持向量机是统计学习理论和结构风险最小原理基础上发展起来的一种分类识别方法[18]。选择支持向量机进行特征分类的优势在于可以将多维的特征输入映射到高维的核空间,从而使原本不可分的数据获得新的特征,更利于精确分类[19]。对香烟的全部特征峰进行PCA降维之后,提取前10个主成分构建特征空间。作为一种典型的机器学习算法,在特征空间中需要选取训练集和测试集,通过训练集进行建模,再对测试集进行预测。本次识别借助MATLAB中的SVM工具箱中的Linear Kernel核函数进行识别分类,惩罚系数C和核函数参数值分别设置为5和1。
3.4 训练集和测试集的比例选取
首先选择了4种训练集和测试集的比例关系,分别为:55∶25、58∶22、62∶18、65∶15,其测试集的准确率分别是:96.9%、97.47%、96.30%、94.81%,可以看出随着训练集和测试集比例关系的增加,训练集和测试集的准确率都呈现先增加后减少的趋势。因此在10个主成分的条件下选择58∶22的比例关系来进行训练和测试。总的样本量为80个,因此训练集和测试集分别为58个和22个。随机抽取58个样本作为训练集,剩余的22个样本作为测试集,测试结果如表2所示。得到训练集分类准确度平均值为96.70%,测试集的准确度平均值为97.47%。预测结果表明,模型已经基本可以将9种不同香烟进行成功分类。

表2 测试集准确率
基于上述的研究,本文还依据香烟的尼古丁含量、产地、焦油含量进行分类,这3个参数均是参照香烟包装上的参数,分类均取得了很好的结果,模型预测的平均准确率分别是94.72%、95.31%、99.58%。
4 结 论
本文通过采集9种烟草在190~720nm波长范围的LIBS光谱,对窗口平移平滑去背景、峰位漂移修正和归一化预处理后的光谱数据进行主成分分析,提取前10个主成分,并运用SVM方法将烟草按照品牌、焦油含量、尼古丁含量和产地等指标分别建立分类模型,模型的平均准确率分别为97.47%、99.58%、94.72%、95.31%。结果表明利用LIBS光谱对烟草进行快速分类是一种可行的分类技术,为香烟普查和香烟的防伪提供了一种快速而有效的检测手段。
猜你喜欢
海洋科学进展(2023年3期)2023-07-29 11:47:40
奥秘(创新大赛)(2023年3期)2023-05-06 01:48:20
公民与法治(2022年3期)2022-07-29 00:57:24
同位素(2020年6期)2020-12-18 08:03:40
人民交通(2020年17期)2020-09-15 11:36:32
小猕猴学习画刊(2018年10期)2018-11-23 07:03:36
南风(2017年31期)2017-11-10 00:47:04
浙江中西医结合杂志(2017年2期)2017-01-12 18:23:59
光谱学与光谱分析(2016年10期)2016-07-12 12:54:49
当代化工研究(2016年9期)2016-03-20 16:22:08
