
基于区域与全局融合特征的以图搜车算法
2019-10-21 08:08赵清利文莉黄宇恒金晓峰梁添才
现代信息科技 2019年12期
关键词:视频监控
赵清利 文莉 黄宇恒 金晓峰 梁添才

摘 要:在视频监控场景中,由于车辆自身外观的多样性和相似性以及无约束的监控环境,以致很难通过全局外观特征区分不同的车辆目标。与全局外观特征相比较,局部区域特征更具区分能力。同时,为了兼顾算法的速度,本文提出一种基于区域与全局融合特征的以图搜车算法。该算法分为三个阶段:首先,以车辆IDs作为标签信息,训练一个车辆的全局特征网络;其次,加入局部区域特征网络,进而联合训练局部区域特征与全局特征网络;在推理阶段,仅采用全局特征网络的特征计算车辆图像之间的相似度。本文采用视频监控场景的图片作为数据集进行算法测试,结果显示所提出的方法的Top10性能达到了91.3%,特征提取时间与单次特征比对时间分别为13.8ms 和0.0016ms,满足了应用需求。
关键词:视频监控;以图搜车;区域与全局融合特征
中图分类号:TP391.41 文献标识码:A 文章编号:2096-4706(2019)12-0001-04
Abstract:In video surveillance scenario,due to the diversity and similarity of vehicle appearance and unconstrained surveillance environment,it is difficult to distinguish different vehicles by global appearance features. Compared with global appearance features,local region features are more distinctive for vehicle retrieval. At the same time,in order to balance the speed of the algorithm,a vehicle retrieval algorithm based on regional and global fusion feature is proposed in this paper. The algorithm is divided into three stages:firstly,using vehicle IDs as the label to train a vehicles global feature network;secondly,adding a local region feature network,and then the local region feature network and the global feature network are jointly trained;in the inference stage,only using global feature networks features to calculate the similarity between different vehicle images. In this paper,the images of the surveillance video scenario are used as the data set to test the algorithm. The results showed that the performance of Top10 reached 91.3%,and the time of feature extraction and single feature comparison were 13.8ms and 0.0016ms respectively. Therefore,satisfied the application demand.
Keywords:video surveillance;vehicle retrieval;regional and global fusion feature
0 引 言
以图搜车技术是一种跨摄像头的车辆检索技术,利用计算机视觉技术判断图像或视频中是否存在特定车辆。以图搜车技术广泛应用于停车管理、智能交通和智慧城市等领域[1]。
在监控视频场景中,摄像头的视角任意性与偏色、光照与天气的变化、车辆的尺度变化以及遮挡等,造成相同品牌、年款的车辆外观非常类似,而同一目标车辆的差异较大,极大地加剧了以图搜车技术的难度。
1 国内外研究现状
以图搜车技术大部分现有的工作主要集中在特征的设计与学习。由于监控视频场景为无约束的环境,因此传统的手工设计的特征,如sift[2]特征等,对于监控视频场景不够鲁棒。随着近年来深度学习的复兴,深度卷积神经网络在行人重识别、人脸识别等应用中取得了巨大的突破,体现出了深度特征巨大的优势。同时,由于近年来一些公共数据集的发布,如VeRi[3]等,给以图搜车技术的研究提供了极大地方便。Liu X[3]等人提出一种基于深度学习的渐进式方法,其利用车辆的外观特征、车牌信息以及时空信息逐步改善车辆识别的性能。Liu H[4]等人提出一种两分支深度卷积网络分别训练车辆IDs和车辆子品牌。同时,也提出了一个新的距离度量损失函数coupled clusters loss用以加快网络收敛和改善传统的triplet loss对锚点选择的敏感性。Zhou[5]等人提出了一种视角感知注意多视角推理模型用以解决多视角的车辆重识别问题。Wang[6]等人提出一种基于方向不变特征嵌入和时空正则化的方法,其首先预测车辆的20个关键点,然后根据关键点定位4个区域,最后融合4个区域的局部特征和车辆的全局特征用于车辆重识别。Liu X[7]等人提出利用4个不同的分支以获取更具区分能力的车辆特征进行车辆重识别。此工作与本文提出的方法有一定的相似处。然而,本文提出的方法网络结构更加简洁,且避免了车辆属性的标注,更能符合實际应用需求。
虽然,前面的工作使以图搜车的性能取得了巨大的进步,但是仍然可以从许多方面对其进行改进。由于之前大部分基于深度学习的工作倾向于描述车辆的全局外观特征,无法获取到更具区分能力的局部区域特征,且大部分工作所提出的网络都较大,不利于实际应用。因此,本文提出一种基于区域与全局融合特征的以图搜车算法,其采用了区域感知策略以及全局特征与局部区域特征联合学习的策略,以获取更具区分能力的车辆特征表示,进而提高以图搜车的性能。
2 算法流程
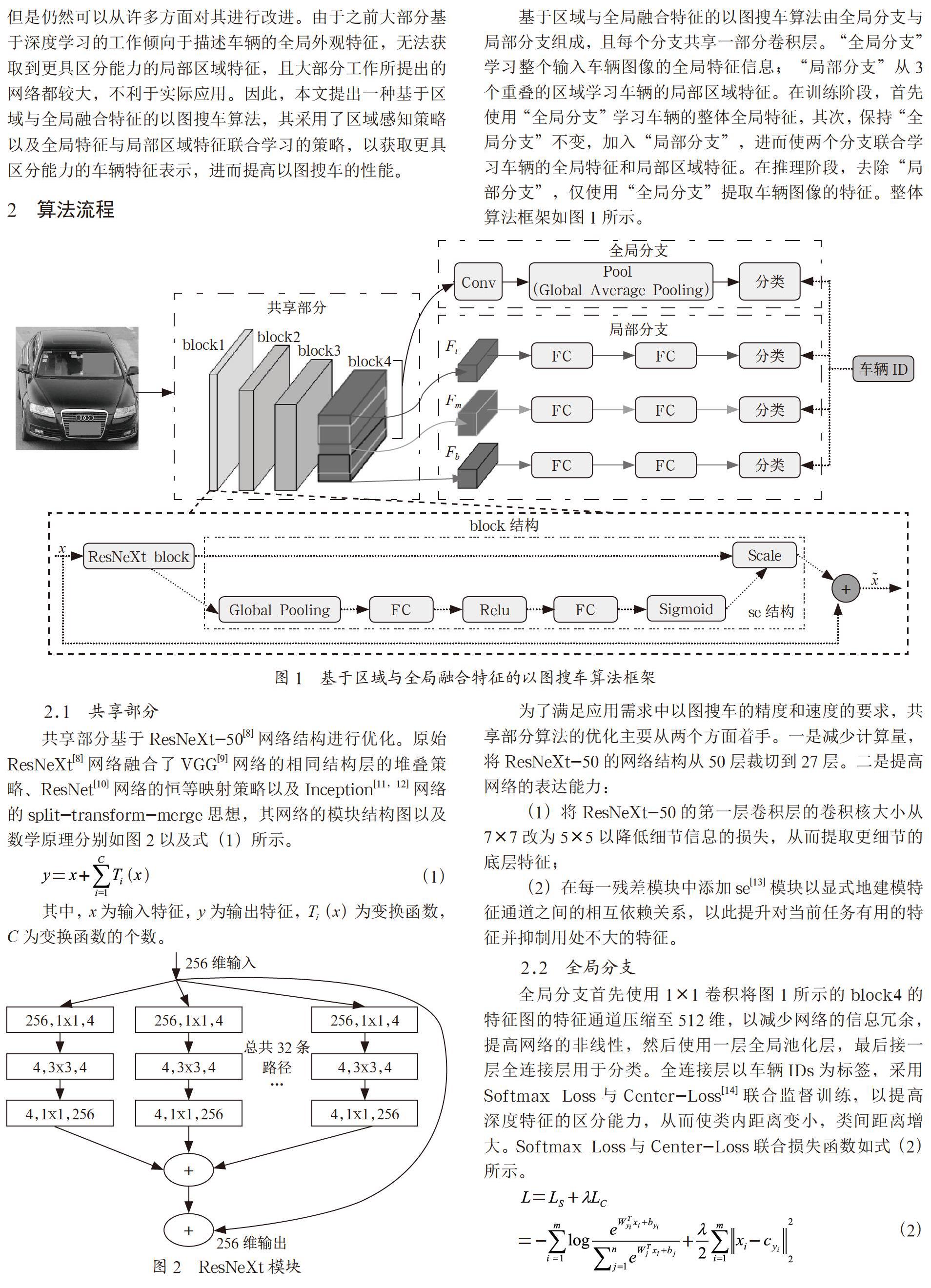
基于区域与全局融合特征的以图搜车算法由全局分支与局部分支组成,且每个分支共享一部分卷积层。“全局分支”学习整个输入车辆图像的全局特征信息;“局部分支”从3个重叠的区域学习车辆的局部区域特征。在训练阶段,首先使用“全局分支”学习车辆的整体全局特征,其次,保持“全局分支”不变,加入“局部分支”,进而使两个分支联合学习车辆的全局特征和局部区域特征。在推理阶段,去除“局部分支”,仅使用“全局分支”提取车辆图像的特征。整体算法框架如图1所示。
2.1 共享部分
共享部分基于ResNeXt-50[8]网络结构进行优化。原始ResNeXt[8]网络融合了VGG[9]网络的相同结构层的堆叠策略、ResNet[10]网络的恒等映射策略以及Inception[11,12]网络的split-transform-merge思想,其网络的模块结构图以及数学原理分别如图2以及式(1)所示。
为了满足应用需求中以图搜车的精度和速度的要求,共享部分算法的优化主要从两个方面着手。一是减少计算量,将ResNeXt-50的网络结构从50层裁切到27层。二是提高网络的表达能力:
(1)将ResNeXt-50的第一层卷积层的卷积核大小从7×7改为5×5以降低细节信息的损失,从而提取更细节的底层特征;
(2)在每一残差模块中添加se[13]模块以显式地建模特征通道之间的相互依赖关系,以此提升对当前任务有用的特征并抑制用处不大的特征。
2.2 全局分支
全局分支首先使用1×1卷积将图1所示的block4的特征图的特征通道压缩至512维,以减少网络的信息冗余,提高网络的非线性,然后使用一层全局池化层,最后接一层全连接层用于分类。全连接层以车辆IDs为标签,采用Softmax Loss与Center-Loss[14]联合监督训练,以提高深度特征的区分能力,从而使类内距离变小,类间距离增大。Softmax Loss与Center-Loss联合损失函数如式(2)所示。
其中,LS表示Softmax Loss,LC表示Center-Loss,xi表示第i个深度特征,其属于第yi类,Wj表示最后一层全连接层权重W的第j列,b表示偏置项,m表示批量的大小,n表示类别数,表示第yi类的特征中心,λ作为两个损失函数之间的平衡。
2.3 局部分支
在实际应用场景中,相似车辆的差异点主要在局部区域特征上,因此设计局部分支用于提取局部区域特征。为了增强特征对车辆视角变化的鲁棒性,本文提出一种学习重叠区域特征的局部分支用于以图搜车,其具体流程如下:首先,将图1中的block4的特征图从高度这个维度按照从上到下的顺序分成3个重叠的局部区域,每一个局部区域对应车辆不同的部分,Ft基本对应车辆的顶部以及挡风玻璃的上半部分,Fm基本对应挡风玻璃部分以及引擎盖上中部分,Fb基本对应引擎盖中下半部分以及车头部分。然后,每一个局部区域后接两层全连接层以产生每一局部区域的特征。最后,使用车辆IDs作为标签,以Softmax Loss作为分类监督信号以促进每个局部区域的特征学习。
局部分支训练时,使用车辆的部分区域特征作为输入以识别车辆,此过程强制网络提取每一个局部区域有识别力的细节特征,进而达到提高以图搜车性能的目的。
2.4 训练与测试
2.4.1 训练
基于区域与全局融合特征的以图搜车算法采用多个分类任务联合训练,其总体损失函数如式(3)所示:
其中,θ代表模型参数,LG代表全局分支的损失,LR代表总的局部分支的损失,Lrt、Lrm、Lrb分别代表局部分支中的上部、中部以及下部的局部区域损失,λrt、λrm、λrb分别代表局部分支中的上部、中部以及下部的局部区域损失的权重。
采用全局分支与局部分支多任务联合训练的方式,不仅让全局分支利用了车辆图像的结构先验,同时也促进了局部分支与全局分支互相学习,使得两个分支都能学习到更有识别力的细节特征。
从零开始同时训练2个分支很难收敛,本文采用循序渐进的方式训练模型。首先,训练全局分支;其次,保持全局分支网络不变,加入局部分支网络,并使用训练好的全局分支的权重初始化全局分支网络,进而联合训练全局分支与局部分支网络。
2.4.2 测试
以图搜车问题是一个实例个体层面上的细粒度分类问题。而分类训练针对的是一种固定类别,当输入非固定类别的图像时,也会被分到分类模型设置的固定类别中,导致识别错误,不具扩展性,因此,为增强模型的扩展性,测试推理阶段,本论文引入距离度量的方式计算车辆图像之间的相似度以进行以图搜车[15]。具体的测试过程分成三个步骤:
(1)特征提取:提取网络的特征;
(2)特征比对:计算特征之间的距离,即相似度;
(3)排序:按照距离从大到小的方式進行排序。
在本文提出的方法中,采用联合训练的方式,使得全局分支的训练可利用车辆图像的结构先验。同时,在局部分支的帮助下,全局分支也可学习到更具识别力的特征,因此,推理阶段我们仅采用全局分支提取车辆的特征,进而采用余弦距离计算特征之间的相似度。余弦距离公式,如式(4)所示。
3 实验
3.1 数据集说明
为了验证本文提出的算法的有效性。使用自建的视频监控场景数据集进行测试。此测试集不仅涵盖了丰富多样的车型(如SUV、轿车、货车、皮卡、MPV、面包车等)、场景(早、中、晚、晴天、阴天、雨天等)以及角度(正面、背面以及侧面),还包括遮挡以及缺失等样本情况。本测试集总共包括26018张图片,4562个车辆目标。本测试集分为查询集和检索集两个部分,在测试集的4562個IDs中,每个IDs选取一张图像作为查询集,共计4562张,剩余的21456张图像作为检索集。本测试集的部分实例如图3所示。
3.2 实验细节
本文提出的方法在caffe[16]深度框架上进行训练和测试。初始学习率设置为0.005,经过10个epochs之后下降10%。Mini-batch的大小设置为128。在训练和测试推理阶段,每张图片的尺寸大小缩放到224pixel×224pixel。
3.3 实验结果与分析
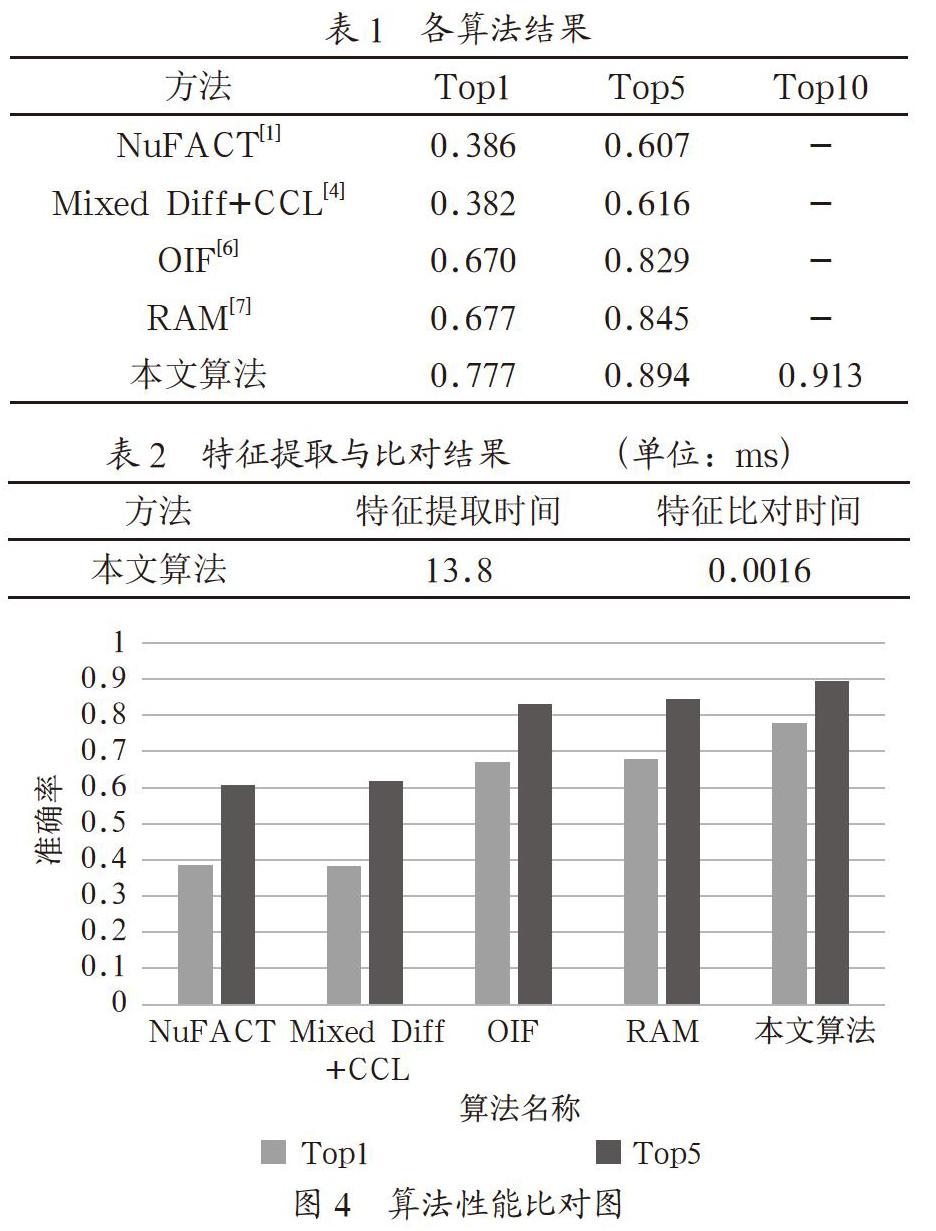
表1中列出的本文算法的数据是在自建的视频监控场景数据集的测试结果,其余列出的数据均为VehicleID[4]数据集的large测试集上的测试结果。Large测试集总共包括19777张图片,2400个车辆IDs。表1中,“-”表示此项指标无结果数据。表2为本文算法的特征提取与特征比对速度结果。图4为各算法性能比对图。
从上述实验结果可以得出,与最新的方法进行比较,本文算法获得了最好的效果,虽然所使用的测试集不同,但本文所使用的视频监控场景测试集的图片数量约为large测试集的1.32倍,车辆IDs数量约为large测试集的1.9倍,在更大的测试集上能取得更好的效果,其恰恰说明了本文算法性能的优越性。同时,从表1与表2可以得到,本文算法的Top10准确率达到了0.913,特征比对时间为13.8ms,特征比对时间为0.0016ms,满足了应用需求。
4 结 论
为满足实际应用对以图搜车算法的精度与速度的要求。本文提出一种基于区域与全局融合特征的以图搜车算法。该算法在训练阶段分为两个步骤:首先,训练一个全局特征网络。其次,保持全局特征网络不变,加入局部区域特征网络,并以第一步骤的权重初始化全局特征网络,进而联合训练局部区域特征网络与全局特征网络,以促进全局特征网络也能够学习到更具区分力的特征。推理阶段,为兼顾算法的精度与速度,本文提出仅采用全局特征网络的特征计算图像之间的相似度。通过在自建的视频监控场景数据集上的评估,验证了本文所提方法的准确性与高效性。
参考文献:
[1] 刘鑫辰.城市视频监控网络中车辆搜索关键技术研究 [D].北京:北京邮电大学,2018.
[2] Lowe D G.Distinctive Image Features from Scale-Invariant Keypoints [J].International Journal of Computer Vision,2004,60(2):91-110.
[3] Liu X,Wu L,Tao M,et al.Deep Learning-Based Approach to Progressive Vehicle Re-identification for Urban Surveillance [C]// European Conference on Computer Vision. Springer,Cham,2016.
[4] Liu H,Tian Y,Wang Y,et al. Deep Relative Distance Learning:Tell the Difference between Similar Vehicles [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE,2016.
[5] Zhou,Y.,Liu L,Shao,L. Vehicle Re-Identification by Deep Hidden Multi-View Inference [J].IEEE Transactions on Image Processing,2018,27(7):3275-3287.
[6] Wang Z,Tang L,Liu X,et al. Orientation Invariant Feature Embedding and Spatial Temporal Regularization for Vehicle Re-identification [C]// 2017 IEEE International Conference on Computer Vision (ICCV). IEEE,2017.
[7] Liu X,Zhang S,Huang Q,et al. RAM:A Region-Aware Deep Model for Vehicle Re-Identification [C]// 2018 IEEE International Conference on Multimedia and Expo (ICME). IEEE,2018.
[8] Xie S,Ross G,Dollar P,et al. Aggregated Residual Transformations for Deep Neural Networks [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2017.
[9] Simonyan K,Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition [J].Computer Science,2014.
[10] He K,Zhang X,Ren S,et al. Deep Residual Learning for Image Recognition [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2016.
[11] Szegedy C,Liu W,Jia Y,et al. Going Deeper with Convolutions [C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2015.
[12] Szegedy C,Vanhoucke V,Ioffe S,et al.Rethinking the Inception Architecture for Computer Vision [J].Computer Science,2015.
[13] Hu J,Shen L,Albanie S,et al. Squeeze-and-Excitation Networks [J].IEEE transactions on pattern analysis and machine intelligence,2019.
[14] Wen Y,Zhang K,Li Z,et al. A Discriminative Feature Learning Approach for Deep Face Recognition [M].Computer Vision–ECCV 2016. Springer International Publishing,2016.
[15] 李熙瑩,周智豪,邱铭凯.基于部件融合特征的车辆重识别算法 [J/OL].计算机工程:1-11.https://doi.org/10.19678/j.issn.1000-3428.0052284,2018-11-30.
[16] Berkeley Artificial Intelligence Research.Caffe is a deep learning framework made with expression [EB/OL].http://caffe.berkeleyvision.org,2019-06-14.
作者简介:赵清利(1982-),男,汉族,河南周口人,经理,博士研究生,研究方向:智能视频分析、深度学习;文莉(1988-),女,汉族,湖南益阳人,算法工程师,硕士研究生,研究方向:智能视频分析、深度学习;黄宇恒(1980-),男,汉族,广东佛山人,研发经理,博士研究生,研究方向:视频图像系统;金晓峰(1985-),男,汉族,山东潍坊人,总监,高级工程师,博士研究生,研究方向:视频大数据;梁添才(1980-),男,汉族,广东广州人,院长,教授级高级工程师,博士研究生,研究方向:智能视频分析、模式识别。
猜你喜欢
软件导刊(2016年12期)2017-01-21
现代电子技术(2016年24期)2017-01-19
中国新通信(2016年21期)2017-01-06
电脑知识与技术(2016年28期)2016-12-21
电子技术与软件工程(2016年20期)2016-12-21
电脑知识与技术(2016年26期)2016-11-24
电脑知识与技术(2016年24期)2016-11-14
数字技术与应用(2016年9期)2016-11-09
