
基于词语语义差异性的多标签罪名预测
2019-10-21 09:11王加伟谭红叶王元龙赵红燕
中文信息学报 2019年10期
王加伟,张 虎,谭红叶,王元龙,赵红燕,2,李 茹,3
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 太原科技大学 计算机科学与技术学院, 山西 太原 030024;3. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
0 引言
随着人工智能技术在多个领域的成功应用,智慧司法也受到了相关领域研究者的广泛关注。智慧司法的实现,不仅能提升司法部门的工作效率,同时也能有效降低法律服务的门槛,这有利于促进司法公正公开透明。为了促进智慧司法的研究进展,推动自然语言处理技术在智能判决等实际问题上的应用,国内举办了2018“中国法研杯”司法人工智能挑战赛(CAIL2018)(http://cail.cipsc.org.cn/)。
罪名预测是智能判决的核心任务之一,目的是在给定犯罪事实的条件下自动预测犯罪主体触犯的罪名。其中,犯罪事实是影响定罪量刑的最重要的客观真实情况。主要包括犯罪的基本事实、犯罪情节、性质和对社会的危害程度等要素;罪名是对犯罪特征的高度概括。包括盗窃、故意伤害、故意杀人等。
早期的罪名预测主张使用统计学方法,试图分析大量历史案例找出共性规律并使用统计学模型模拟判决流程。典型工作如Kort等[1]提出的量化分析法和Nagel等[2]提出的关联分析法。此类方法仅在限定规模和特定领域的数据上有效,较难推广到一般性案件中。现阶段多基于文本分类框架构建预测模型,即以大量历史法律文书作为训练文本,以罪名为类别标签,训练机器学习分类模型。代表性工作如Liu等[3]基于文书浅层文本特征的K近邻算法分类预测模型、Luo等[4]和Hu等[5]基于深度神经网络的罪名分类模型等。此类方法在预测效果上取得了一定进步,但忽略了犯罪事实中词语语义差异性的影响,且没有解决数罪并罚情形下多标签罪名预测问题。因此,本文尝试从这两方面改进以提升罪名预测的效果:
(1) 词语语义差异性建模。犯罪事实中各词语的语义重要性在不同罪名的判决中不同,下面通过“盗窃罪”和“抢劫罪”案例解释这种差异性。
依据图1中法条规定: “盗窃罪”与“抢劫罪”的犯罪目的均为“非法占有公私财物”。但“盗窃罪”的犯罪手段为“秘密窃取”,对应案例中的“不备之机、扒窃”等词;而“抢劫罪”的犯罪手段为“使用暴力、胁迫或其他方法强行抢夺”,对应案例中的“言语威胁、劫得”等词。因此,在这两种罪名区分中,用于描述犯罪手段的词语起主要作用,而用于描述犯罪目的的词语起次要作用。而在侵财类罪名与非侵财类罪名的区分中,犯罪目的词则起到关键作用,如“盗窃罪”与“故意伤害罪”的区分等。注意力机制可在文本建模过程依据词语语义的重要程度自动赋予相应的权重,从而使得整体语义的表达更为准确。因此,本文使用注意力机制实现犯罪事实的差异性语义建模。

图1 “盗窃罪”与“抢劫罪”案例对比
(2) 数罪并罚预测。犯罪主体在实施犯罪行为的过程中可能会触犯多种罪行,如抢劫与故意杀人、贪污与受贿等。数据统计发现,数罪并罚案件约占全部的9.1%,因此在罪名预测中须考虑到数罪并罚情形。下面给出数罪并罚案例,如图2所示。

图2 数罪并罚犯罪事实
该案件中被告人实施了两类犯罪行为(酒后驾驶和殴打他人),同时触犯了“危险驾驶罪”与“故意伤害罪”的法条规定,且罪名之间不存在交集。故而,其属于数罪并罚案件。由于本文是基于文本分类框架构建罪名预测模型,则数罪并罚预测可转换文本分类中的多标签分类问题。而数罪并罚中的各罪名相对较为独立,因此,我们便使用分解策略将多标签罪名分解为多个独立的单标签罪名,并对每个罪名进行二元分类。这种策略使得模型既适用于单标签罪名预测也适用于多标签罪名预测,有效地提升了罪名预测的通用性。
1 相关工作
判决自动预测在很早以前就展开了研究。早在1957年,Kort等[1]就试图分析大量历史案例,并使用统计学模型分析预测美国联邦最高法院对于案例的判罚决策。1963年,Nagel等[2]试图使用关联分析的方法解决判决预测问题。1980年,Keown R等[6]验证了一系列线性模型在法律领域相关任务上预测的可行性。1987年,斯坦福大学Gardner[7]探讨了在合同法领域上研究法律推理模型的思路。1991年,Deedman[8]尝试在加拿大的法律体系下构建人工智能专家断案系统。可是,上述模型仅在某些特定的情况下才适用,其通用性较差,且预测能力还处于一个较低的层次。
随着机器学习方法的流行,人们开始将机器学习模型用于罪名预测中。Thompson等[9]使用最近邻算法、重复增量剪枝算法、决策树算法等实现裁判文书的分类;台湾国立大学Liu等[10]针对罪名预测中的多标签问题,将部分多标签的共现视作固定组合,但因罪名共现并非一般性规律,所以其方法通用性较差。Liu等[11]基于之前工作进一步改进,将判决预测分成三个阶段并使用支持向量机模型(Support Vector Machine,SVM)分类,预测结果得到有效提升。2017年,Sulea等[12]则以犯罪事实、犯罪时间和法律规定作为特征,同样使用SVM分类并取得了较好效果。
上述方法大多基于浅层文书特征,训练数据规模也较小,难以应对案情复杂冗长或数据规模较大的情形。随着神经网络在NLP各子任务纷纷取得突破性的成果,如Kim Y[13]、Hochreiter S[14]、Zichao Y[15]及Vaswani A[16]等,研究者也开始尝试将上述神经网络模型融入判决预测中。典型工作有Luo等[4]使用注意力机制将法律条文信息融入文本建模部分以辅助罪名预测;Hu[5]针对低频和易混淆罪名,列出了十个有区分性的属性,并使用注意力机制和多任务学习的方法将这些属性用到预测任务中,取得了较好的效果;Ye H等[17]针对罪名预测可解释性差的问题,从自然语言生成(Natural Language Generation,NLG)的角度,使用了基于编码端罪名标签的Seq2Seq模型,自动生成法院判决观点。
2 基于词语语义差异性的多标签罪名预测模型
本文的罪名预测模型主要包括两个部分: 第一部分是对犯罪事实的语义差异性建模,第二部分是针对数罪并罚情形改进的罪名预测模型。该模型的优势是可以较为准确地表示犯罪事实语义且能同时实现单罪名与数罪并罚罪名预测。模型结构如图3所示,2.2节和2.3节将分别介绍其中文本建模层和罪名预测层的工作机制。
2.1 问题描述
犯罪事实可被视作长度为n的词序列S={w1,w2,…,wn},本文将每个词映射为一个多维连续值的词向量xi∈Rd,则犯罪事实可以表示为矩阵E=x1⊕x2⊕…⊕xn,E∈Rn×d。 罪名标签{盗窃,抢劫,…,故意杀人}表示为集合L={l1,l2,…,lm},其中m为罪名数目,集合元素li在{0,1}上取值,li=1时表示案件涉及罪名i,等于0则相反。罪名预测是基于犯罪事实S的矩阵表示E,使用预测模型f(E)预测出罪名标签集合L。
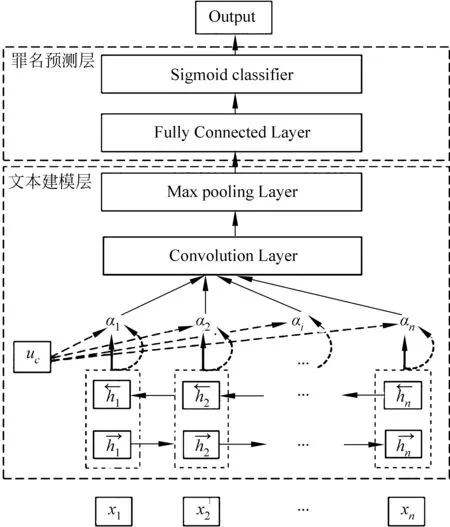
图3 基于词语语义差异性的多标签罪名预测模型
2.2 基于注意力机制的语义差异性建模
2.2.1 Bi-GRU层

2.2.2 注意力层
对于犯罪事实文本,除了需要考虑各词语之间的语义依赖关系,还要体现出各词语在罪名的预测中的语义重要性差异。对于包含犯罪信息较为丰富的词语,在进行高级向量表示时,需要赋予较高的权重。Bi-GRU层有效地融入了上下文信息,使得注意力值的计算更依赖于整体语义,因此本文在Bi-GRU编码后引入注意力机制,从而使得整体语义的表达更为准确。这种结构也符合定罪的逻辑,法官会首先了解案件的整体情况,然后重点关注犯罪过程、犯罪方法、犯罪性质的等细节特征。
本文注意力机制的实现方式如下: 式(4)表示使用多层感知机对Bi-GRU层输出hi进行非线性变换,输出中间向量ui;式(5)用于度量词语语义的重要程度(注意力值)αi,通过计算ui和上下文向量uc的余弦相似度并归一化得到。其中,上下文向量uc可视作当前犯罪事实的抽象语义表示。其本质上是一个可动态更新的模型参数,作用是为各词语语义重要性的计算提供参照。训练过程中随机赋予uc初始值,通过式(5)初步计算各词的注意力权重。然后,通过分类器预测得到属于各类罪名的概率,计算当前时刻的预测概率与实际概率的loss。若loss较大,则代表当前参数不能准确表达犯罪事实的语义。因此,使用反向传播算法继续迭代更新uc参数直到loss值最小,此时的uc可认为是准确表示出了犯罪事实全文信息。关于loss的详细计算将在3.3节给出。
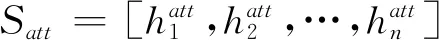
(7)
2.2.3 特征提取层
Bi-GRU编码层与注意力机制实现了上下文信息与词义权重的融入,输出犯罪事实的抽象矩阵表示Satt。 由于Satt维度较高且包含部分噪声,故引入多核卷积神经网络对其进行优化表示。而且卷积神经网络可通过滑动窗口机制对同一区域内的所有特征进行卷积变换从而有效保留词语的局部特征。以Satt作为卷积层输入,使用大小为h的卷积核W∈Rh×d对其进行局部特征提取,如式(8)所示:
其中f(·)为卷积操作,Satt(i,i+h-1)表示Satt第i行到i+h-1行的局部特征。上下滑动卷积窗口得到特征图Mi,如式(9)所示:
下采样使用Max Pooling,目的是选取局部最优特征,计算如下,如式(10)所示:
经过上述操作,完成了犯罪事实的建模与特征抽取,其经全连接层变换后即可输入分类器进行罪名预测。
2.3 多标签罪名预测模型
为了适应数罪并罚情形的罪名预测,本文将其对应的多标签罪名分类问题分解为多个独立单罪名的0-1分类问题。这种预测方式相当于对每一个罪名标签都训练了一个独立的分类器。下面详细介绍这种预测方式的工作机制:
首先将每个案件的罪名标签映射为列表[l1,l2,…,ln],n为罪名总数,li∈{0,1},li=1代表涉及罪名i,li=0相反。这种标签转化策略可将复杂的多标签分类转化成相对简单的0-1分类。基于这种转换,我们使用Sigmoid交叉熵损失函数[18]计算每个标签上的loss,其输入为真实概率分布p(xi)和预测概率分布(置信值)q(xi)。p(xi)使用one-hot映射方式得到,p(xi)∈{0,1};q(xi)由Sigmoid函数对logitsi激活得到,q(xi)∈(0,1),q(xi)计算方式,如式(11)所示:
其中,logitsi为未经归一化的预测“概率”,logitsi∈(-,+), Sigmoid的作用是归一化logitsi,使其值域限定在(0,1)区间,以便与p(xi)计算。下面是loss的具体计算过程。
单案件单罪名的交叉熵loss计算如公式(12)所示:
由于同一案件各罪名之间相互独立,则上式lossi的计算可简化如式(13)所示:
一个案件的所有罪名loss和如式(14)所示:
以p(xji)表示批次训练样本中案件j的第i个罪名的实际概率分布,q(xji)表示其预测概率分布,则一个batch中所有样本的损失总和如式(15)所示:
使用Adam优化函数优化lossbatch,反向传播迭代更新卷积核W、上下文向量uc等模型参数。预测时基于最优参数计算得到预测概率q(xi),比较每个罪名的q(xi)与阈值γ的大小,取q(xi)>γ的所有罪名作为最终预测结果。
3 实验与分析
3.1 数据集及评价指标
实验数据来源于2018“中国法研杯”司法人工智能挑战赛,该数据集基于中国裁判文书网上的公开文书构建,本文依据规模将其划分为Charge-S和Charge-L,表1给出两个数据集的分布情况。对全体数据统计分析得出: 单标签罪名约占90%,多标签罪名约占10%。预处理过程中将出现次数小于80的罪名删除,原因是其对应样本较少,难以支撑深度学习模型训练。此外,由于原始数据集中金钱、年龄、重量等为离散数字表示。如盗窃金额1 000元和10 000元、年龄16岁和30岁等。为提升整体语义表示准确性,减少该类特征的多元化离散分布对判罚的影响,本文依据刑法法条和司法解释对其进行规范化处理,将金额划分为一级金额、二级金额等十个级别;并按是否成年将年龄分为成年和未成年两个级别等。
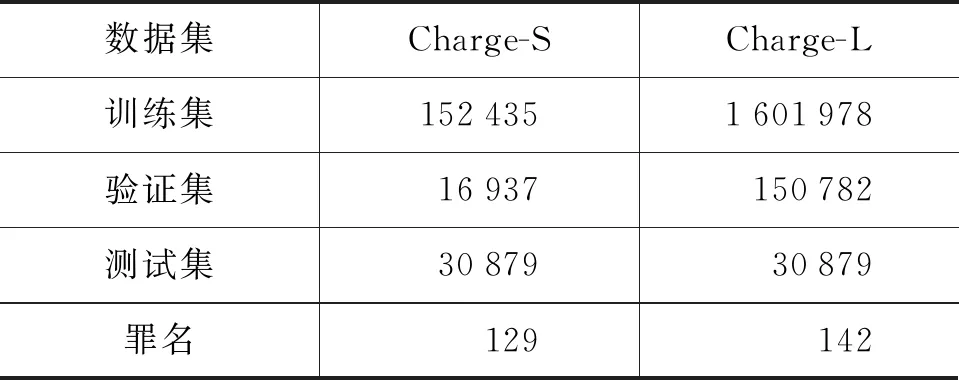
表1 数据集的分布
评价指标使用微平均F1值F1micro、宏平均F1值F1macro及综合F1值F1union,其计算公式分别如式(16)~式(18)所示:
3.2 实验参数设置
参数设置上,使用skip-gram模型[19]训练字向量和词向量,维度均设置为256。对犯罪事实长度统计,发现以字符作为最小语义单元时输入序列的长度总数为450,以词语作为最小语义单元时的长度总数为200。因此,本文将输入序列长度分别固定为450和200,对于长度不符的样例进行padding或者cut处理。卷积核尺寸分别为2,3,4,5。设定学习率随着训练的进行逐渐衰减,初始学习率为0.001,衰减率为0.8,使用批正则化的方式降低过拟合的影响。优化器使用AdamOptimizer[20]。
3.3 结果及分析
为了验证本文方法的有效性,分别设定传统机器学习模型和深度学习模型作为基线对比。传统机器模型分别使用词频-逆文档频率算法(TF-IDF)和卡方检验(CHI)构建特征词典,使用支持向量机SVM作为分类器。深度学习方法主要包括Bi-GRU、CNN、未融合注意力机制的级联模型Bi-GRU-CNN及本文模型GAC(Bi-GRU-Attention-CNN)。为了检验模型对于数罪并罚情形下多标签罪名的预测效果,修改GAC模型得到其单标签罪名预测模型S-GAC。方法是使用Softmax作为分类器,归一化logits后取置信值最大的类别作为预测的罪名。此外,为了研究语义单元粒度对预测性能的影响,以170万篇法律文书作为训练数据训练字向量和词向量,并分别作为深度学习模型的输入。
表2、表3列出了基线模型和本文模型的预测结果对比,图4使用了灰度热力图对注意力层进行可视化,表4给出了分别以字向量和词向量作为输入的实验结果。

表2 Charge-S上的实验结果
续表

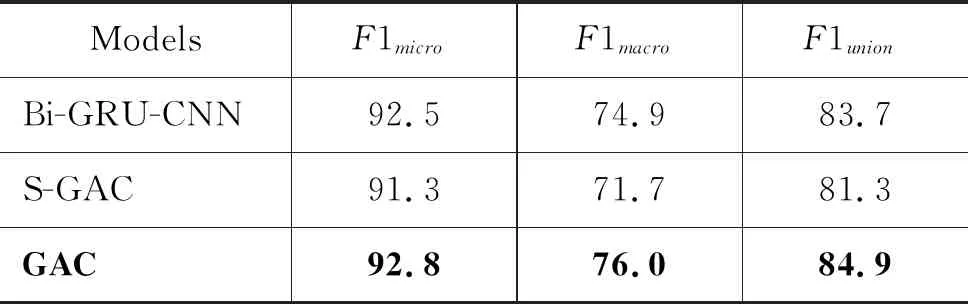
表3 Charge-L上的实验结果
从表2~3的结果可以看出,本文提出的罪名预测模型GAC在两个数据集上均取得较好的预测效果。其F1union值相较于最优基线模型Bi-GRU-CNN,在Charge-S和Charge-L上分别提升了1.2%和 1.4%。Bi-GRU-CNN模型未考虑词语语义之间的差异性,其粗略认为犯罪事实中所有词语的重要性一致或接近,而GAC模型使用注意力机制实现了各词语语义差异表示,该方式的语义表示更为准确。这表明了该模型可以在训练过程中准确捕获各罪名的类别关联性,并有利于提升罪名分类的准确率。
为了检验本文方法对相似、相关罪名的区分能力,以及进一步分析文本建模过程中注意力机制的作用机理,本文选取相似罪名“容留他人吸毒罪”与“贩卖毒品罪”中的两个案例。在预测过程中,分别对其犯罪事实中各词语对应隐层向量的注意力权值αi进行可视化。结果如下图4所示,可以看出,尽管“容留他人吸毒罪”与“贩卖毒品罪”均为毒品犯罪类罪名,但其犯罪事实整体语义侧重仍有所差异。依据司法解释,“容留他人吸毒罪”客观方面表现为容留他人吸食、注射毒品,重点强调主观容留性,忽略其是否存在有偿交易。而“贩卖毒品罪”更多强调毒品的交易行为,毒品种类、交易数量、毒资金额是其关键特征。因此,在“容留他人吸毒罪”案件的可视化图中,“容留”“吸食”等强调容留吸食行为词语的颜色较深;“贩卖毒品罪”中描述毒品交易特征的词语则颜色较深,如“购买”“交易”“出售”“毒资”。这种注意力分布的差异是区分两类相似罪名的关键。通用性词语如“被告人”“李某”“路边”等,其罪名区分能力较弱,对应注意力值也较低。我们同时发现,“海洛因”“冰毒”等毒品名称的权重也较高。原因是其所指语义为“毒品”,而该语义在毒品犯罪与非毒品犯罪(如盗窃、抢劫等罪名)的区分中较为关键。值得注意的是,“在毒品贩卖罪”中出现了标签“money_1”,其是预处理过程中对金钱类数字规范化替换的结果,因为毒资金额在“毒品贩卖罪”相似罪名(如走私、运输毒品罪等)区分过程中较为关键,所以其权重也相应较高。上述分析说明本文注意力机制的使用的确能有效关注到犯罪事实中词语的语义重要性差异,而这种差异性对于同类案件或非同类案件的罪名区分十分关键。

图4 可视化注意力层
从表2、3中还可看出,F1micro值与F1macro值相差较大。在Charge-S数据集中,GAC模型预测结果的F1micro与F1macro相差高达16.8%,Charge-L中也相差15.2%。其主要原因是不同罪名的样本数目占比倾斜严重,从而导致了模型训练的偏置。
图5给出了Charge-S数据集上部分罪名的训练样本数目对比,可以发现不同罪名的样本数量分布很不均衡。其中,“盗窃”与 “倒卖文物”的样本数目比300:1。分类器是以总体分类精度为学习目标,在这种情况下,训练算法势必会导致分类器过多关注多数样本,从而使少数样本分类精度下降。本文也尝试使用采样算法改进模型,但该类方法对性能的提升极为有限,本文将在后续工作中研究更有效的改进思路。
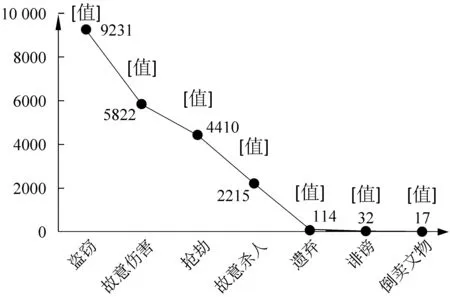
图5 Charge-S上部分罪名的训练样例数目
为了验证模型在数罪并罚类案件的有效性,本文设置了对应的单标签预测模型S-GAC作为对比模型。观察表3发现,在Charge-L数据集上通用GAC模型相比于单罪预测模型S-GAC,F1union提升4.2%。数据集中全部多标签案件约占9%,这表明本文使用的基于Sigmoid的方法确实能有效解决数罪并罚情形下的多罪名预测问题。
为了研究不同粒度的语义单元对于犯罪事实建模的影响,本文还分别对比了预训练字向量和词向量作为输入时的预测结果。表4给出了结果对比。从表4中可以看出,以词向量作为语义表示时的效果在各项指标上均显著优于字向量。在Charge-L数据集上,Word-GRU 与Word-CNN相比于Char-GRU 和Char-CNN,F1union分别提升了1.2%和0.6%,本文使用的GAC模型也提升了1.1%。这一方面,是由于法律文书的撰写用词较为规范,使得分词错误率较低,但使用字向量优势并不明显。另一方面,以词作为语义单元时,便于对犯罪事实中时间、地点、数字这类语义整体性较强的词语编码。而字向量以单字作为语义单元,编码过程中会将整体语义信息拆分成零散信息,影响了语义表示的准确性。由于字典规模远小于词典(本文实验中分别为4 786 和170 827),故基于字向量的模型效率要明显优于基于词向量的模型。

表4 字向量和词向量对比实验结果
4 结语
本文针对性地研究了罪名自动预测中词语的差异性建模以及数罪并罚情形下的罪名预测问题。首先,使用Bi-GRU融入上下文信息以生成犯罪事实总体语义表示。然后,使用注意力机制刻画不同词语的语义重要性差异,再使用多核卷积池化对特征向量降维。最后,经过全连接层和Sigmoid分类器预测得到罪名预测结果。针对数罪并罚情形改进的罪名预测模型也有效解决了其对应的多标签罪名预测。由于法官定罪时的影响因素不仅只有犯罪事实,证据是否完备充足、犯罪情形严重与否、法律条文与司法解释的符合程度等因素对判决的走向也有较大影响。因此,在接下来的工作中,本文将尝试将证据信息、法律条文,司法解释等外部信息融入以辅助罪名预测,改进模型并提升其预测性能。
在此,感谢中译语通科技股份有限公司对于本工作提供的帮助和建议!
猜你喜欢
日本问题研究(2020年2期)2020-06-15
重庆行政(2019年5期)2019-11-18
今日农业(2019年15期)2019-09-03
环球时报(2018-05-19)2018-05-19
中外文摘(2018年10期)2018-05-03
中国检察官·经典案例(2017年2期)2017-04-07
法制与社会(2017年6期)2017-03-11
中国检察官·经典案例(2016年11期)2016-12-07
中国检察官·经典案例(2015年8期)2015-09-15
杂文选刊(2014年11期)2014-10-22
