
基于联合学习的问答情感分类方法
2019-10-21 09:11:14安明慧沈忱林李寿山李逸薇
中文信息学报 2019年10期
安明慧,沈忱林,李寿山,李逸薇
(1. 苏州大学 计算机科学与技术学院,江苏 苏州 215006;2. 香港理工大学 人文学院中文及双语系,香港 999077)
0 引言
随着互联网技术的飞速发展,网络购物成为了广大消费者的首选购物方式,国内电子商务平台也随之迎来了爆发式的增加。2018年“双十一”期间天猫销售额达到了2 135亿元,京东销售额达到了1 598亿元,苏宁的订单量也同比增长了132%。电商平台的飞速发展使得平台上的评价信息也随之飞速增加。对电商平台而言,如何有效利用这些评价信息[1],特别是问答型评论,来进行平台舆情分析、商品质量检测和客服质检[2]等应用的开发,是维护平台公平性和保证用户购物体验的重中之重。情感分析技术在这些领域中扮演着极其重要的角色。
目前,针对电商评论的情感分类方法大多为基于全监督的机器学习方法,这类方法往往需要大规模的标注语料[3]。然而面向问答型评论的情感分类语料集十分匮乏,额外标注大规模问答型评论的成本又十分昂贵,基于此本文探索一种基于联合学习的问答情感分类方法。例1为问答型评论实例,例2为普通评论实例,我们可以发现问答型评论和普通评论具有十分相似的情感描述信息,因此,我们可以使用大量自然标注普通评论通过联合学习的方式,辅助提升问答型情感分类任务的性能。
例1问题:手机是不是很耗电啊?
答案:不会呀。
情感: 正面
例2评论:手机电池很持久,待机耗电很低,用两天没问题,很不错。
情感: 正面
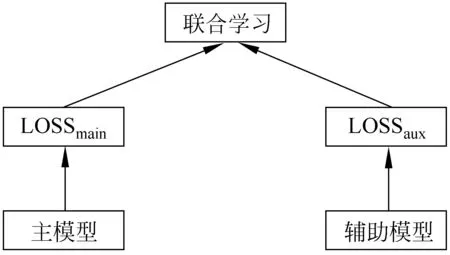
图1 联合学习示意图
众所周知,基于联合学习的方法在自然语言处理领域表现得非常出色,联合学习的模型框架如图1所示,一般由主任务和辅助任务构成,整个模型针对主任务的损失函数和辅助任务的损失函数同时进行优化。Chen等[4]通过对情绪分类任务和情绪原因识别任务进行联合学习,有效结合了二者的情绪特征并大幅提升了这两个任务的性能。Ma等[5]设计了一个基于神经网络的联合学习模型,可以同时进行属性的预测和属性级情感类别的预测。该联合模型能有效结合预测的属性标签信息来提升属性级情感分类任务的性能。基于以上工作的启发,本文提出了一种基于联合学习的问答情感分类方法,通过大量易获得的普通评论,辅助问答情感分类任务。具体而言,我们先通过主任务模型单独学习问答型评论的情感信息,再使用问答型评论和普通评论共同训练辅助任务模型以获取问答型评论的辅助情感信息,再通过联合学习同步更新主任务模型和辅助任务模型参数。实验结果表明,本文提出的基于联合学习的问答情感分类方法能较好地融合问答型评论和普通评论的情感信息,在性能上明显优于其他基线方法。
1 相关工作
1.1 问答情感分类
面向问答型评论文本的情感分类是一项新颖且富有挑战性的任务,该任务由Shen等[6]首次提出,同时Shen等提出了一种基于层次匹配网络的问答情感分类方法,该方法通过切分句子并构建句子级的二元组,再通过层次匹配机制能有效挖掘问答型评论深层次的情感信息。
1.2 联合学习
近年来,联合学习在自然语言处理领域的诸多任务上被证明是十分有效的。严倩等[7]通过联合学习的方法利用丰富的英文事件语料库来帮助中文事件抽取任务,提高了跨语言事件识别的性能。邱盈盈等[8]通过联合深度学习和主动学习的事件抽取方法,在主动学习过程中提高语料标注效率从而提升了事件抽取的性能。Wang等[9]在用户画像识别任务中,通过联合学习使得年龄预测、性别预测和职业预测3个任务的特征互相影响,从而提升了用户画像识别的性能。Li等[10]在事件抽取任务中,提出了一种基于结构化感知机的联合学习模型,通过同时抽取事件触发词和论元的方法提高了句子级别的事件抽取任务的性能。Tu等[11]在跨领域情感分类任务中,将完形填空任务网络作为辅助任务,卷积层次注意力网络作为情感分类任务进行联合学习,提高了跨领域情感分类的性能。Cong等[12]提出了一个基于层次网络的联合学习模型,可以同时进行层面级的情感分类和单词级别的观点抽取,提高了观点词抽取任务的性能。
基于上述工作的启发,为了解决问答型评论数据集匮乏的问题,本文提出了一种基于联合学习的问答情感分类方法,通过大量易获得的普通评论辅助提升问答情感分类任务的性能。
2 方法
本节详细介绍本文提出的基于联合学习的问答情感分类方法,整体框架如图2所示。该方法由主任务和辅助任务构成,主任务模型为基于双向门控注意力机制的神经网络,辅助任务模型为基于双向LSTM和注意力机制的神经网络。
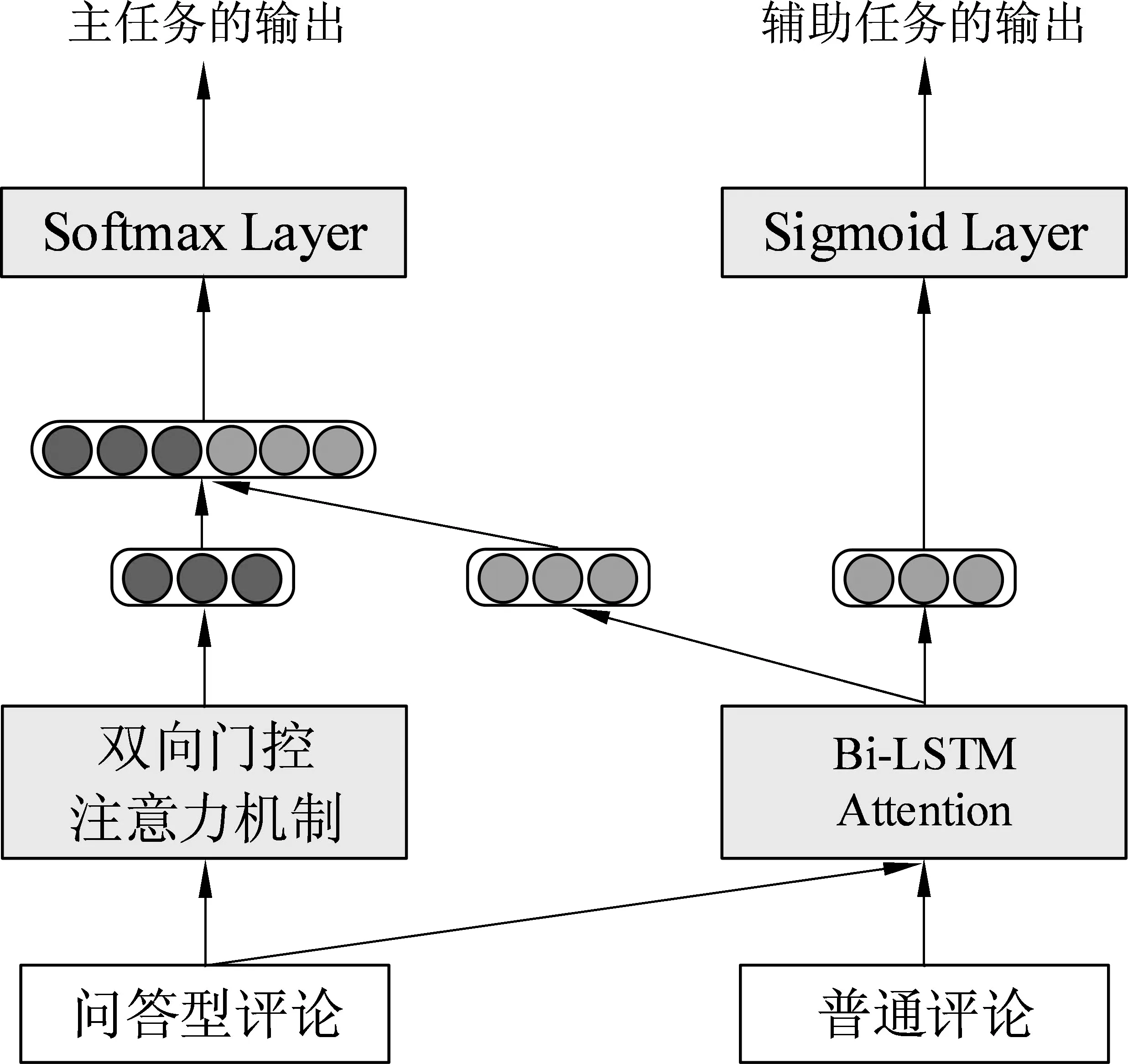
图2 基于联合学习的问答情感分类方法框架图
2.1 主任务
主任务模型由基于双向门控注意力机制的神经网络构成, 它用来挖掘问答型评论的深层次情感匹配信息,其模型结构如图3所示。

为了更好地捕捉问题文本和答案文本之间的情感匹配信息,我们提出了一种双向门控制注意力机制,这是传统注意力机制的一种变体,能够很好地捕捉问题文本和答案文本中词语之间的情感匹配关系,该方法包含问题—答案门控注意力机制以及答案—问题门控注意力机制,具体如下:
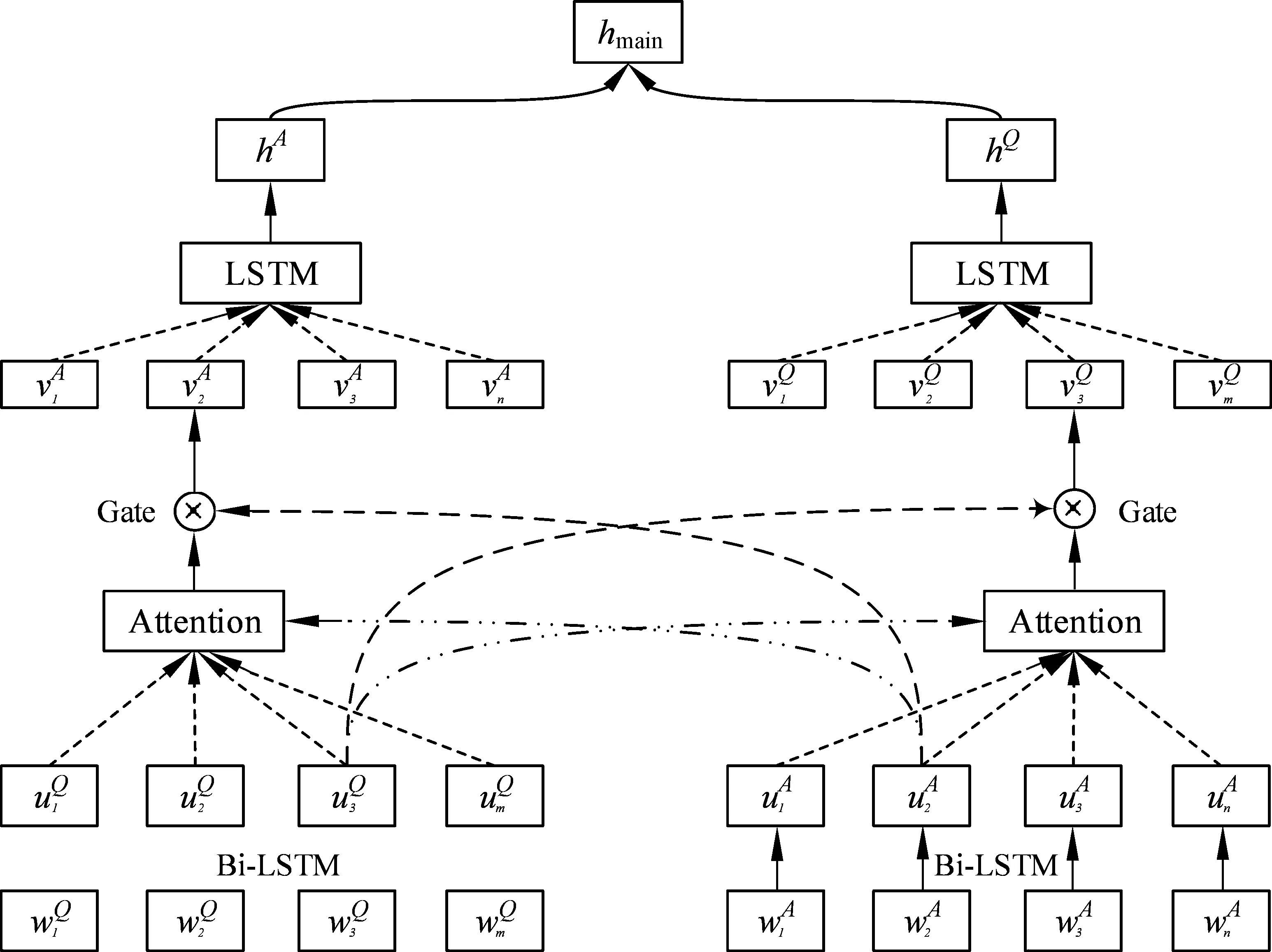
图3 基于双向门控注意力机制的神经网络示意图
其中,ct是注意力机制学习到的问题文本的表示。然后,我们通过门控机制学习答案文本的语义序列表示,如式(6)~式(8)所示。

最后,我们通过一层LSTM来获取答案文本的最终表示向量,如式(9)、式(10)所示。

(9)
hA=LSTM(VA)
(10)
其中,hA为答案文本最终的表示向量。
答案—问题门控注意力机制: 同样地,我们可以通过注意力机制获得由答案信息增强后的问题文本表示,如式(11)~式(13)所示。
其中,ct是注意力机制学习到的答案文本表示。其次,我们通过门控机制学习问题文本的语义序列表示,如式(14)~式(16)所示。

最后,我们通过一层LSTM获取问题文本的最终表示向量,如式(17)、式(18)所示。
其中,hQ为问题文本的情感表示向量。
最终,我们通过向量拼接的方式得到问答型评论的语义表示向量hmain,如式(19)所示。
2.2 辅助任务
辅助任务模型由共享的双向LSTM和注意力机制构成,该模型由问答型评论和普通评论共同训练获得。其模型结构如图4所示。为了简便起见,我们同时将问答型评论中问题文本和答案文本进行拼接,类似于看成一条普通评论来处理。

图4 基于双向门控制注意力机制的神经网络示意图
其中,ut为词语et的隐藏层输出。然后,我们通过注意力机制获取辅助模型最终的向量表示,如式(21)~式(24)所示。
其中,α为注意力权重,Wc和bc为权重矩阵和偏置。h为辅助模型的最终输出的向量表示,我们还规定haux为问答型评论学习到的向量表示,hr为普通评论学习到的向量表示。
2.3 联合学习
最后,我们通过联合学习同时学习和更新主任务模型和辅助任务模型的参数。分类包含主任务模型分类和辅助任务模型分类。
主任务分类: 问答型评论文本的表示最终由两部分组成,一部分是由主任务学习到的语义表示向量hmain,另一部分为辅助任务学习到的向量表示haux,我们将两个向量进行拼接,得到问答型评论的最终向量表示hqa,如式(25)所示。
其中,⊕表示向量的拼接操作。
面向问答型评论文本的情感分类任务共包含四种情感类别,因此,我们通过softmax层获得最终的类别表示,如式(26)所示。
其中,pqa为问答型评论的情感类别输出概率。Wqa和bqa为softmax层的权重和偏置。
主任务模型的目标函数为交叉熵损失函数,定义如式(27)所示。
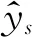
辅助任务分类: 面向普通评论的情感分类任务共包含两种情感类别。因此,我们通过sigmoid层获得最终的类别表示,如式(28)所示。
其中,pr为普通评论的类别输出概率。
辅助任务模型的目标函数同样为交叉熵损失函数,如式(29)所示。
联合学习: 整个模型通过联合学习同时更新参数。因此,整个模型的目标函数,如式(30)所示。
3 实验设计与分析
本节系统评估本文提出的基于联合学习的问答情感分类方法的性能,同时对实验结果进行分析。
3.1 实验设置
数据设置: 实验数据来自Shen等[6]公开的问答型评论语料(1)https://github.com/clshenNLP/QASC/,该语料包含美妆,鞋类和数码3个领域,具体类别分布如表1所示。在本实验中,我们将每个领域随机分为训练集(每个类别的70%样本)、验证集(每个类别的10%样本)以及测试集(每个类别的20%样本)。另外,本实验所使用的普通评论从淘宝(2)http://www.taobao.com/爬取,每条评论自带用户的打分(打分范围为1—5分)。我们将大于3分的认为是包含正面情感的评论,评分低于3分的认为是包含负面情感的评论。通过这种方式在美妆、鞋类和数码3个领域中,每个领域选择5 000条包含正面情感的评论以及5 000条包含负面负面情感的评论。
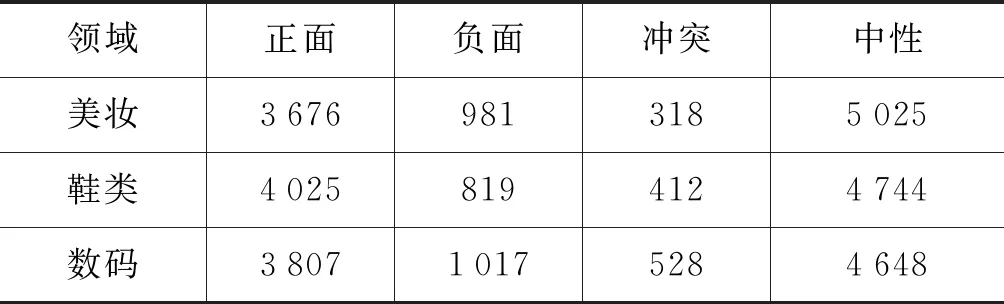
表1 问答情感分类语料集的类别分布
分词和词向量: 我们采用FudanNLP(3)https://github.com/FudanNLP/fnlp/进行中文分词。通过word2vec(4)https://code.google.com/archive/p/word2vec/训练词向量,词向量维度设置为100。
参数设置: 在本实验中,所有的未登录词(out-of-vocabulary, OOV)均通过均匀分布U(-0.01,0.01)进行初始化。LSTM神经网络的一些重要参数如表2所示。模型的优化函数为Adam[14],为了防止神经网络模型训练过程中过拟合的现象,模型均采用了Dropout机制[15]。其余的参数通过验证集调试确定。
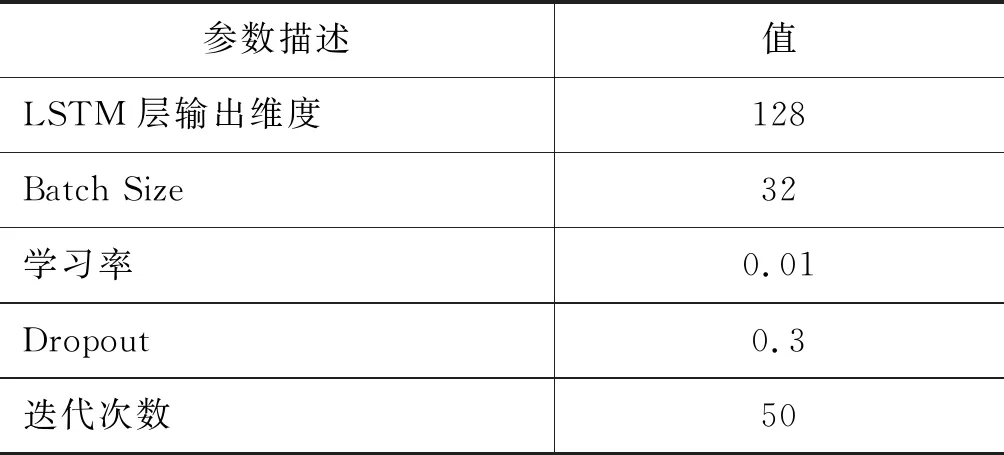
表2 LSTM神经网络的参数设置
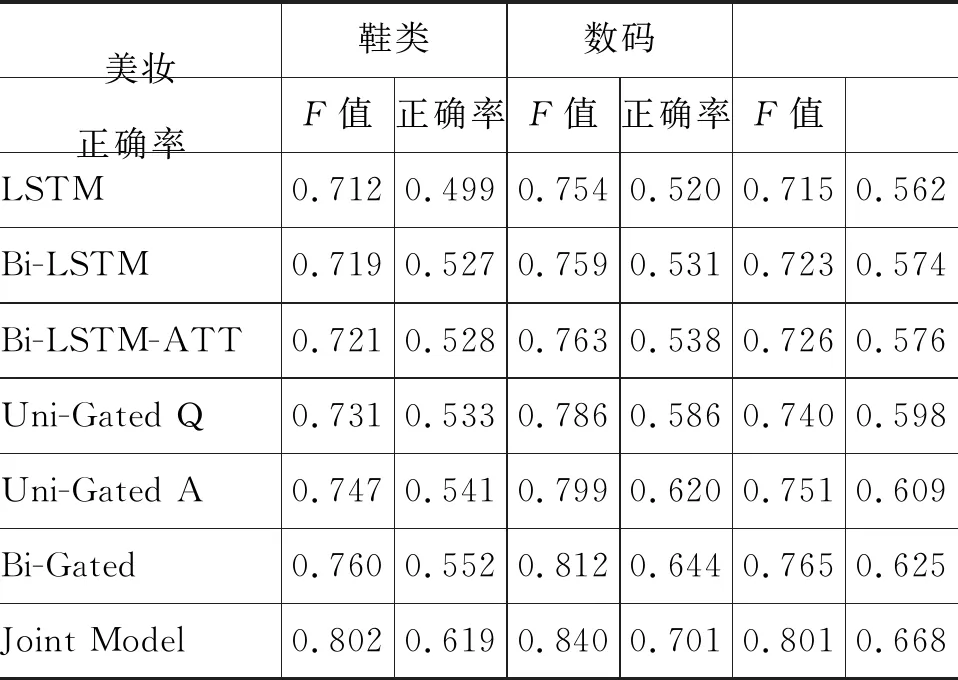
表3 各方法在所有领域的性能结果
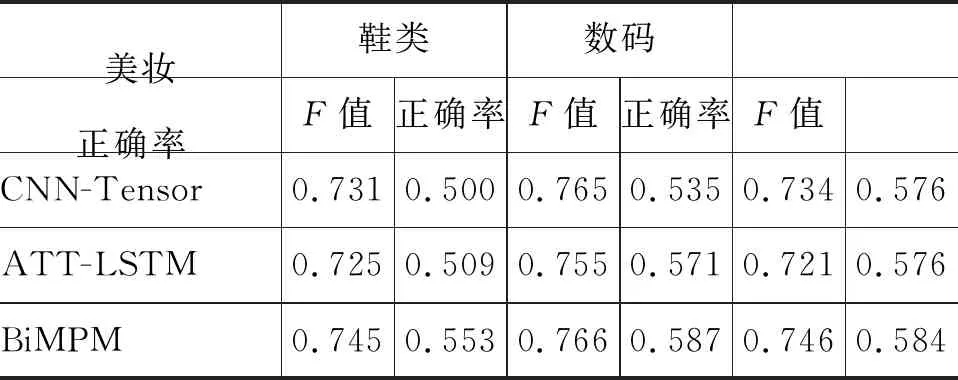
表4 我们的方法与其他方法在所有领域上的性能结果

续表
评价准则: 本文采用正确率(Accuracy)和Macro-F1值作为衡量情感分类性能的指标,与Shen等[6]论文中保持一致。
3.2 实验结果
为了验证基于联合学习的问答情感分类方法的有效性,我们实现了以下几种情感分类方法与之进行比较,具体如下:
LSTM: 将问题文本和答案文本拼接作为一个序列,使用词向量作为特征,LSTM[16]作为分类器。
Bi-LSTM: 将问题文本和答案文本拼接作为一个序列,使用词向量作为特征,双向LSTM[17]作为分类器。
Bi-LSTM-ATT: 本文提出的基于联合学习的问答情感分类方法中的辅助任务模型,由双向LSTM和注意力机制构成。
Uni-Gated Q: 本文提出的基于联合学习的问答情感分类方法中的主任务模型,由单向门控注意力机制构成,即答案—问题门控注意力机制。
Uni-Gated A: 本文提出的基于联合学习的问答情感分类方法中的主任务模型,由单向门控注意力机制构成,即问题—答案门控注意力机制。
Bi-Gated: 本文提出的基于联合学习的问答情感分类方法中的主任务模型,由双向门控注意力机制构成。
Joint Model: 本文提出的基于联合学习的问答情感分类方法,由主任务模型和辅助任务模型联合构成。
表3为各方法在所有三个领域上的实验结果。从中我们可以发现,基于双向LSTM和注意力机制的神经网络方法(Bi-LSTM-ATT)相较于LSTM和Bi-LSTM有一定的提升。这表明加入注意力机制后,能更好获得问答文本中的特定词和句子的重要程度,以便于更好地挖掘问答型评论的情感信息。
其次,基于双向门控注意力机制的方法(Bi-Gated),在性能上明显优于基于单向门控注意力机制的方法(Uni-Gated A、Uni-Gated Q)。这表明在问答型评论中,问题文本和答案文本均包含了重要的情感信息。
最后,本文提出的基于联合学习的问答情感分类方法(Joint Model)在性能上表现最强势。在3个领域上,都取得了最好的分类性能。与Bi-Gated方法相比,在美妆、鞋类和数码3个领域数据集上准确率分别提升了4.2%、2.8%和3.6%,Macro-F1值分别提升了6.7%、5.7%和4.3%。这表明该方法不仅能有效地挖掘问答型评论的情感信息,同时也能较好地融合问答型评论和普通评论的情感表述信息。
为了更全面地说明本文提出的基于联合学习的问答情感分类方法的性能,我们将与其他方法作更深层次的比较:
CNN-Tensor: 本方法由Lei等[18]提出,在句子级情感分类任务上达到了目前最好的性能。
ATT-LSTM: 本方法由Wang等[13]提出,在属性级情感分类任务上达到了目前最好的性能。在本实验中,我们忽略了属性信息,直接通过LSTM的隐藏层输出得到注意力权重。
BiMPM: 本方法由Wang等[19]提出,在问答匹配任务上达到了目前最好的性能。在本实验中,我们将最后得到的问答匹配向量直接通过softmax分类器进行情感分类。
HMN: 基于层次匹配网络的问答情感分类方法本方法由Shen等[6]提出,在问答情感分类任务上取得了目前为止的最佳性能。
Joint Model: 本文提出的基于联合学习的问答情感分类方法,由主任务模型和辅助任务模型联合构成。
表4展示了各方法在所有领域上的性能结果。与处理传统情感分类任务的方法相比,我们的方法Joint Model相较于CNN-Tensor和LSTM-ATT有极大的优势,充分证明了我们的方法不仅能有效挖掘问答型评论的情感信息,还能很好地结合普通评论中的情感表述信息。
其次,将问题和答案看作两个平行的单元采用双向注意力机制的方法(BiMPM)相比于将问题和答案进行简单拼接的单序列输入的方法(CNN-Tensor和ATT-LSTM),取得了更好的分类性能。这说明将问答文本看作两个平行单元进行建模的合理性。
最后,与问答匹配方法 BiMPM、Bi-ATT以及HMN相比,本文提出的方法在性能上有极大的提升。与基线方法中表现最好的方法HMN相比,我们的方法在美妆、鞋类和数码3个领域中正确率分别提升了2.6%、1.3%和 2.2%,F值提升了2.1%、1.8%和2.8%,这充分证明本方法能有效地捕捉问题文本和答案文本之间的语义情感信息,更好地提升问答情感的分类性能。
4 结语
本文针对问答情感分类语料集匮乏的问题,提出了一种基于联合学习的问答情感分类方法。通过大量易获得的普通评论辅助问答情感分类任务,将问答情感分类作为主任务,将普通评论情感分类作为辅助任务。首先,通过主任务模型单独学习问答型评论的情感信息;其次,使用问答型评论和普通评论共同训练辅助任务模型,以获取问答型评论的辅助情感信息;最后,通过联合学习同时学习和更新主任务模型和辅助任务模型的参数。实验结果表明,本文提出的基于联合学习的问答情感分类方法能较好地融合问答型评论和普通评论的情感信息,大幅提升问答情感分类任务的性能。
在未来的工作中,我们将考虑探索其他半监督机器学习方法和强化学习方法,通过选择未标注的问答型评论文本来进一步提升问答情感分类的性能。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
河北理科教学研究(2021年3期)2022-01-18 05:34:24
发明与创新(2021年39期)2021-11-05 07:15:28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
传媒评论(2017年3期)2017-06-13 09:18:10
材料科学与工程学报(2016年1期)2017-01-15 13:33:48
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
