
基于Gate-ResNet-D模型的远程监督关系提取方法
2019-10-21 09:11袁祯祺
中文信息学报 2019年10期
袁祯祺,宋 威,陈 璟,2
(1. 江南大学 物联网工程学院,江苏 无锡 214122;2. 江南大学 物联网技术应用教育部工程研究中心,江苏 无锡 214122)
0 引言
随着互联网技术的飞速发展,如何从网络海量的数据中获取有价值信息成为了当下国内外工业界和学术界的研究热点[1]。而实体关系提取则是信息抽取领域的重要技术,在智能问答、智能搜索、聊天机器人、广告推荐等领域均已被广泛应用[2]。所谓实体关系抽取,即给定具有实体对e1和e2的句子,识别抽取e1和e2之间的关系。关系提取结果的好坏,将对其后续任务的效果产生重要的影响,这引起了自然语言处理领域许多学者、研究人员的极大关注。近年来,深度学习在人工智能领域取得了突破性的进展,自然也就被引入到了实体关系提取任务中来。以往实体关系抽取的深度学习方法使用的多是基于浅层卷积神经网络(convolutional neural network, CNN)或双向长短期记忆神经网络(long short term memory, LSTM)的模型。Zeng[3]等首先将基于神经网络的深度学习模型运用于此项任务,其模型基于卷积神经网络并通过原始单词的输入产生词向量来表示句子特征,与传统机器学习模型相比,取得了显著的进步。Zhou[4]等则运用了基于注意力机制的长短期记忆神经网络来捕获句子中的语义信息。这种方法能够提取候选关系语句的特征信息,并进行加权组合,从而提炼出更精准有用的特征,有效地提高了关系抽取的准确率。
1 远程监督关系提取研究现状
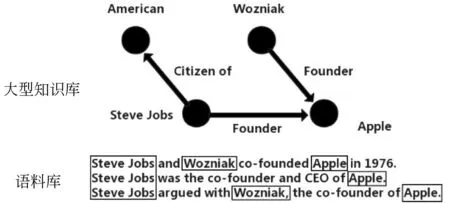
图1 远程监督框架结构
现如今,深度学习模型已被广泛应用于各个领域,而一直困扰着众多国内外学者的便是常用的深度学习方法都需要大量数据来训练模型,以便达到更好的拟合效果。常规训练数据集的构建需要大量人工标注,这将加大研究成本和时间的支出。此外,某些专业领域(如医药、农业、金融、军事等领域)的数据标注还要求标注人员具有一定的专业领域知识,这使得标注工作进展十分缓慢。因此,如何自动地生成大量标注数据成为了研究者们探讨的问题。为此, Mintz[5]等提出了远程监督方法,它基于以下假设: 语料库中所有包含同一实体对(entity pair)的句子可以映射到外部已存在的知识库中。因此,可以通过外部知识库直接对齐大量语料来生成标注数据,达到扩充数据集的目的。由于这种严格的假设导致了远程监督数据集充满了噪声。图1展示了远程监督的基本过程,假设知识库(knowledge base, KB)中存在实体对之间的关系,那么就可以将知识库中的关系引入到正常的自然语言句子中进行训练。例如‘苹果’和‘乔布斯’在知识库中的关系是CEO,那么我们就假设类似于“Steve Jobs发布了Apple的新一代手机”这样的句子中“Steve Jobs”和“Apple”存在CEO的关系。如此,利用知识库对海量的文本数据进行自动标注,得到标注好的数据,随后训练一个分类器,每个类别是一个关系,由此实现关系抽取。
此后,Zeng[6]等又在远程监督数据集上提出一种基于分段卷积神经网络(PCNN)的模型,自动提取句子特征,并通过多示例学习筛选重要的句子,提取实体关系。Lin[7]等和Ji[8]等则都运用了基于注意力机制的深度学习模型来减轻远程监督数据集上噪声的影响。为了将一整段文本中所有的句子考虑在内, Jiang[9]等采用跨句级的最大池化层方案,这使得模型能够提取到句子之间尽可能多的特征信息。Lin[10]等还使用了跨语言的注意力机制来考虑不同语言之间文本信息的一致性和互补性,从中提取到关联信息,运用到实体关系提取中去。Luo[11]等运用了动态转换矩阵来表征噪声并通过Curriculum Learning框架引导训练。
需要注意的是,上述模型大多只采用了一层卷积层和一层最大池化层这样的浅层卷积神经网络来作为句子的解码器。Huang[12]等则首先使用了9层的深度残差网络模型在远程监督数据集上做实体关系提取。然而在卷积神经网络中,数据在经过不同的滤波器后会产生不同的特征通道,尤其是在深度残差网络中,网络层数的数量相较于普通网络更为庞大。再者,深度残差网络的特性致使每层网络的结构差异性很小,这就直接导致了特征通道之间的信息存在优劣。一旦网络加深,就意味着冗余的特征通道会越来越多。
为了过滤深度残差网络中冗余的特征通道,本文提出了一种Gate模块,灵感源于长短期记忆神经网络中的门控机制。该模块先对特征通道进行压缩,使其获得每个特征通道的全局感受野,再通过全连接层生成权重,从而可以不断更新特征通道的权重,使重要的特征通道得以保留及加强,削弱减少不重要的特征通道。Gate模块通过对特征通道的筛选,可以有效防止过拟合问题以及加强网络对文本信息的表示能力。本文设计了一种包含4组Gate模块的深度残差网络来提取句子的特征,并在NYT数据集[13]上做了相关模型的对比实验。本文的主要贡献包含以下三点:
(1) 提出一种具有门控机制的Gate模块来筛选特征通道;
(2) 将Gate模块加入深度残差网络中,并在实体关系提取的远程监督数据集上验证其有效性;
(3) 为了最大程度地保留句子之间的特征,提出双池化层方案,实验结果表明此方案对模型性能有一定提升。
2 Gate-ResNet-D模型
本节具体介绍基于改进深度残差网络的实体关系提取方法,图2是ResNet-Gate-D系统网络结构框架。为了防止网络过拟合的发生,使用了包含4个Gate模块的深度残差网络。主体网络框架包括3个部分:
(1) 词向量表示,即网络输入部分(2.1节);
(2) 包含Gate模块的深度残差网络部分(2.2节);
(3) 双池化层和Softmax输出层部分(2.3~2.5节)。
2.1 词向量表示
词向量描述了一个词在语料中所代表的语义信息,是Gate-ResNet-D模型的基础输入数据。词向量Vw是由词嵌入模型通过大型语料库训练得来的,它可以体现出单词之间的相关性,从而使后续的特征提取更为有效。同时,通过加入每个单词与实体在句子中的相对位置信息,可以对句子中实体对的相对位置以及不同的单词与实体之间的相对位置进行嵌入式表示,提升了关系抽取的效果[7]。每个词的向量表示由两部分组成: 词向量Vw和位置向量Vp,定义为V,如图2中向量表示部分所示。词向量是整个模型的输入,词向量的质量对之后模型的特征提取起着至关重要的作用。本文引入词的位置嵌入信息,将句子中每个词与实体e的相对位置p映射成位置向量Vp。向量Vp是单词在空间上位置信息的低维表示方法,由当前单词到两个实体的位置距离直接决定,能够反映句子中各个单词与实体对之间的位置信息。在词向量输入之后,是整个模型的核心部分,即包含Gate模块的深度残差网络部分。
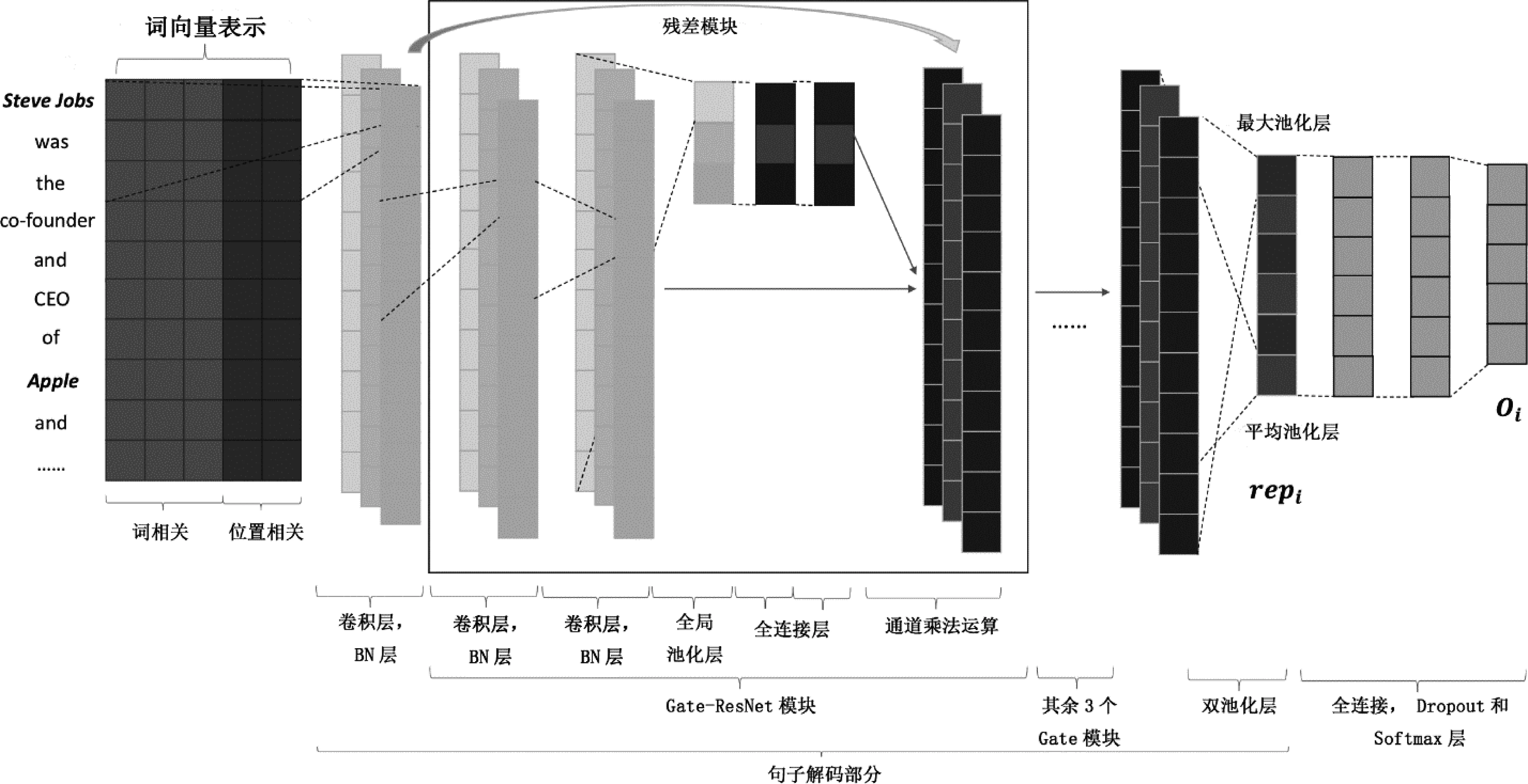
图2 Gate-ResNet-D模型框架图
2.2 Gate模块
在深度残差网络中,由于网络深度的缘故,使得特征通道的数量相对较多。相比于图像处理任务来说,自然语言处理任务对特征通道的感知更为敏感,所以冗余性的特征通道对模型的影响很大。为了更好地使特征通道之间的信息得以完全利用,改善整个深度残差网络的性能,本文提出了Gate模块。该模块类似于长短期记忆神经网络中的门控机制,可以过滤特征通道,通过它使每个特征通道学习到全局特征信息。换言之,它是一种作用在特征通道上的注意力机制。该模块可以通过简单的堆叠来生成网络,图2中展示了包含Gate模块的深度残差网络结构体系(图2中Gate-ResNet模块部分)。我们定义U为来自上层网络通过卷积之后的特征通道,在空间维度H上,通过压缩U来生成统计量z∈RC,其中c是z中的第c个通道,如式(1)所示。
(1)
当特征通道压缩之后,Gate模块采用了一种门控机制,使用Sigmoid激活函数对zc产生权重,如式(2)所示。
s=σ(W2δ(W1z))
(2)
其中δ是非线性激活函数,本文采用了Swish激活函数而不是常用的ReLU激活函数,实验结果表明Swish激活函数对模型性能有一定提升(将在第2.4节和第3.3节中说明)。W1和W2分别代表2层全连接层,如式(3)所示。
(3)
其中r是升降维比例,用于限制模型的复杂度,本文会在实验部分讨论r的取值。
Gate的最终输出是将权重sc与上层卷积后的特征通道uc相乘后得到的,如式(4)所示。
(4)
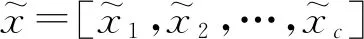
2.3 双池化层
在神经网络架构中,最大池化层,即对邻域内各特征点取最大值,如式(5)所示。
hm=maxai,fori=1,…,K
(5)
其中,hm是最大池化层的输出,ai是各特征值,最大池化层可以抓住邻域内的重要特征。
而另外一种池化层,即平均池化层,对邻域内各特征点求平均值,如式(6)所示。
(6)
其中,hm是平均池化层的输出,ai是各特征值,Nm是邻域内特征数量,平均池化层由于能够尽量保留向量的结构信息,所以可以很好地抓住句子各单词之间的位置信息。
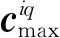
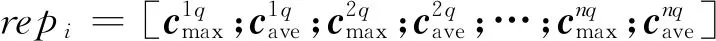
(7)
2.4 Swish激活函数
Swish是一种新型的激活函数,其原始公式如式(8)所示。
f(x)=x·σ(x)
(8)
其中,σ(z)=(1+e-z)即为Sigmoid激活函数,变形Swish-B激活函数的公式则如式(9)所示。
f(x)=x·σ(βx)
(9)
此激活函数拥有不饱和、光滑、非单调性的特征,其中β是一个可训练参数,Prajit[14]等提出了这种新的激活函数,并证明了其有效性。本文通过将这种新型的Swish激活函数替换ReLu激活函数验证了这一点。实验表明,Swish激活函数相较于ReLu激活函数,对模型性能有一定提升。
2.5 全连接层,Softmax及网络优化
在得到每个句子si的向量表示repi后,本文使用了三层的全连接来输出置信度矢量Oi。假设共有M种关系,那么第j个关系的条件概率即如式(10)所示。
(10)
由于深度残差网络的激活输入值会在网络层数加深的情况下产生不断偏移,这种偏移量会使其分布产生变动,最终导致输入值向激活函数的两端非敏感区域靠近,从而使梯度消失。为了防止此现象的发生,本文在每个卷积层之后使用了Batch Normalization[15]标准化技术。BN层的作用就是将激活函数的输入值拉到标准正态分布区间内,使得网络的训练变得高效,加快损失函数收敛速度,直接避免了梯度消失、训练速度慢等问题。
3 实验
本文模型输入采用的是Lin[7]等所用到的词向量模型,该模型是通过NYT语料库训练得来的,设置输入的文本向量固定大小值为100。采用的深度学习框架为tensorflow,版本为1.9.0,优化器采用Adam。
3.1 对比模型
本文分别采用多种基准和变形体模型与Gate-ResNet-D模型进行比较。其中,CNN+ATT和PCNN+ATT[7]都是采用了基于注意力机制的卷积神经网络模型。PCNN通过分段最大池化层代替传统最大池化层来提升模型性能。目前,PCNN+ATT是实体关系提取领域公认的性能较为稳定的模型。ResCNN-9是一种具有9层网络的基准残差网络模型。BLSTM+ATT[4]则是基于双向LSTM和注意力机制的实体关系提取模型。此外,本文还运用了LSTM的变体构造了BGRU+2ATT模型,这种模型具有单词级和句子级两种注意力机制。最后,本文还选取了一种运用强化学习的新型关系提取模型: PE+REINF,该论文发表在2018年的AAAI会议上,其实验证明了该模型相比于传统深度学习模型,拥有非常优秀的性能[16]。本文实验中,采用了相同的常规参数以降低实验变量来获得更准确的实验结果。
3.2 数据来源及评价指标
NYT数据集是一种常用的关系提取数据集,也是目前唯一一个数据量级较大的公共远程监督数据集。由于本文模型的特殊性(层数较深),所以其在数据量级较小的数据集上容易过拟合。该数据集中训练集包含522 661个句子,测试集包含172 448个句子。结合了《纽约时报》中的语料和Freebase中的实体集和关系集匹配结合而成。本文分别采用P-R曲线图,P@N值等各项指标来评价模型的综合性能。与Zeng[16]等所使用的模型评价方法一致,本文选择了最高预测得分句子的关系(不是NA关系)作为整个包的预测结果。
3.3 实验效果及模型性能分析
本节中,主要对本文模型的性能进行详细的分析比较。首先,本文对模型中一项重要参数r做了中间实验来讨论其取值。因为r的取值直接影响整个模型的性能,决定了Gate模块中全连接层的升降维比例,直接关系残差特征的构筑。由表1可知,不同r的取值对P@N值有将近5%的提升,最终本文选取r=64作为模型参数。

表1 r取值对模型性能的影响
从局部转向整体,图3是各种模型整体性能的实验比较,分别将本文提出的Gate-ResNet-D模型与其他基准模型做了比较。不难看出,无论是PE+REINF、PCNN+ATT还是BGRU+2ATT,整体上都有着相近的性能。而具有Gate模块和双池化层加持的ResNet在P-R曲线图中,整体性能有着较为明显的优势。这反映出本文模型对远程监督数据集中噪声的处理更为有效,能提取到更加实际有用的特征信息,从而使模型的整体效果更好。

图3 本文模型与其他模型的比较(注: 每种模型在图中从上至下出现的顺序均按图例排列)
由于多数的深度残差网络都选取ReLU激活函数。为此,本文还比较了有无Gate模块的深度残差网络在替换不同激活函数后整体性能的变化。从图4可以看出,不论有无Gate模块,Swish激活函数都要略好于ReLU激活函数。这证明了Swish激活函数对深度残差网络全连接层的特征映射,有着优于ReLU激活函数的性能。但是在具有Gate模块的深度残差网络中,Swish激活函数体现不出明显的优势,这可能跟全连接层的数量有关[17]。网络深度一旦继续加深,整个模型将更容易过拟合,所以,如何在防止过拟合的同时继续加深网络也将会是下一步的研究计划。
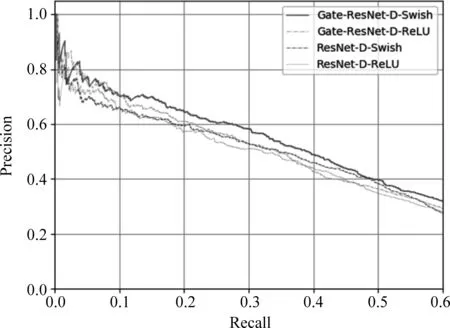
图4 不同激活函数的比较
图5是不同池化层之间模型性能的比较。可以看出,在关系提取任务中,最大池化层的性能要优于平均池化层。而本文提出的双池化层方案,将两种池化层方案相结合,在实验中的表现也证明了这种方案的有效性。
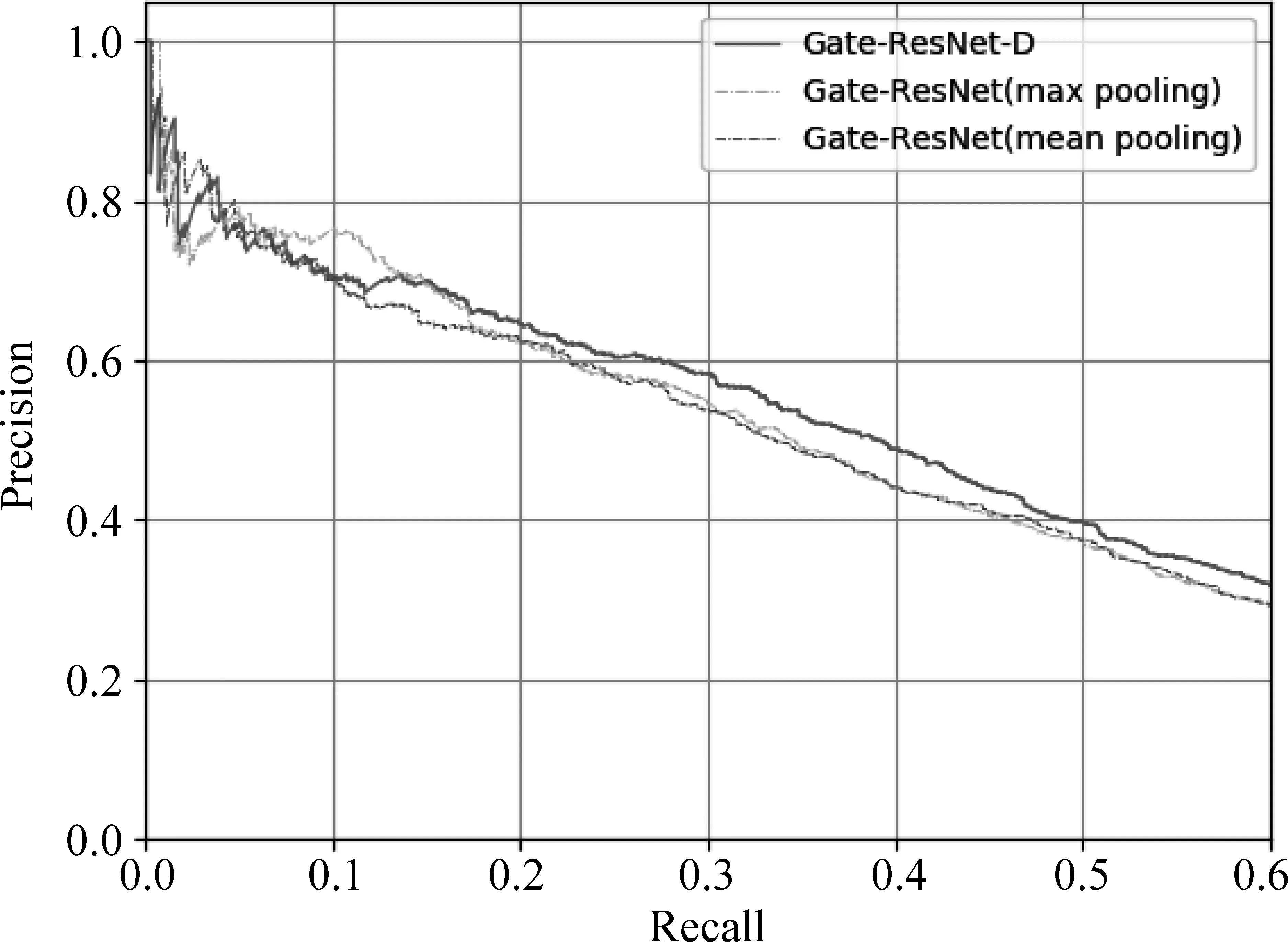
图5 双池化层对模型性能的影响
表2中是本文模型与其他关系提取模型的P@N评价指标的比较结果,本文模型在没有句子级别或是单词级别的注意力机制的情况下,P@N(Mean)效果仍然好于其他基准及变体模型。由此可以看出,其余模型的整体性能与本文模型有一定的差距。值得注意的是,得益于强化学习的训练方式,PE+REINF模型在N=100时,查准率明显高于其他模型,这是值得借鉴的地方,在后续的研究中,本文会深入分析这种方法的优劣性。

表2 不同模型的P@N值

续表
Gate-ResNet-D模型的优势在于三个方面。首先,Gate模块能动态地重新校准各个特征通道的重要性,可以有效地防止深度残差网络的过拟合问题,从而提高了网络对特征的抓取能力。其次,深度残差网络的短路机制以及Gate模块的多尺度特征提取,能更好地提取到句子的隐藏信息、句法和语义特征。最后,和最大池化层相比,双池化层能够更好地保留特征映射之间的位置信息。
4 结论
本文提出了一种基于改进深度残差网络的模型,并在远程监督数据集上做关系提取实验。通过添加本文提出的Gate模块和双池化层方案,使模型性能得到了很大的改善。含有Gate模块和双池化层的深度残差网络具有比其他模型(如卷积神经网络或循环神经网络及其变体)更好的句子编码性能和特征提取性能,这直接决定了在远程监督数据集上能否解决噪声问题。实验结果表明,本文提出的Gate-ResNet-D模型能够有效解决这种噪声问题。之后,本文会继续对网络深度和注意力机制做进一步的研究,探究在更深的网络结构之下和对模型加入注意力机制后能否提取到数据更深层次的特征,进一步提高模型性能。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
新高考·高一数学(2022年3期)2022-04-28
科技创新与应用(2021年23期)2021-08-30
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
北京航空航天大学学报(2020年10期)2020-11-14
无线互联科技(2020年15期)2020-11-10
科技传播(2020年6期)2020-05-25
北京航空航天大学学报(2019年9期)2019-10-26
雷达科学与技术(2018年3期)2018-07-18
