
基于本地化数据空间集中调度的海量数据平台优化策略
2019-10-18 11:48:08温立辉
深圳职业技术学院学报 2019年5期
温立辉
基于本地化数据空间集中调度的海量数据平台优化策略
温立辉
(河源职业技术学院 电子与信息工程学院,广东 河源 517000)
针对海量数据在传统数据集成方式中性能不佳、效率低下问题,提出了一种集中式基于数据空间的优化方案.首先,把平台数据归类为静态数据与动态数据,以解决传统集成方式中数据量过大、数据种类混乱,不利平台的实时响应;其次,通过主/从分离的读写方式有效降低静态数据机器上的节点负载,有效提升读写能力;再次,集群分片存储方式极大改善了平台对动态数据处理能力.与联机事务分析(OLAP)集成方式相比,本方案依托数据切片、配置式数据源管理,更加灵活、轻巧,能更好地适应复杂的数据环境,适合中小企业对海量数据运维的需求.
大数据;水平切片;时间维度;主/从;读写分离;连接工厂
随着互联网、云计算发展,信息数据快速增长,数据的价值越来越吸引人们的视线,成为当下主流、火热的主题[1].海量数据时代的到来对企业来说既是一个挑战也是一个机遇,大数据的规模效应给数据存储、管理以及数据分析带来了极大的挑战[2,3].海量据时代,人们能从数据中获得可转化为推动人类生活方式变革的有价值知识,它将成为下一个科技创新、市场竞争与生产力提高的前沿[4].传统的OLAP数据集成方式采用的是数据仓库模式,分为4层:数据源、数据集市、分析服务、前端展现,数据源的数据通过ETL工具转换到数据仓库中, 然后分析工具从数据仓库中读取数据, 生成数据立方体(MOLAP)供前端进行多种形式的数据展现[5].这种集成方式周期长,且不灵活,不利于行业的变化发展.
利用云计算平台搭建Hadoop计算框架是当前集成大数据平台的主要方式步[6],然而以此种方式搭建起来的数据平台仍有如下几大方面的问题:1)整个框架结构特别臃肿,不利于日后平台的维护与扩充;2)成本过于高昂,无法满足中小企业对大数据建模的要求;3)由于云计算的开放式与Hadoop应用的分布式特性,不可避免的带来平台运营上的安全风险[6];4)对于敏感数据,运营于开放平台上,容易遭受黑客攻击,而泄露用户隐私[7].针对以上海量数据平台的集成问题,本文探讨一种安全、高效、灵活的集成、运维大数据平台架构方式,特别适合于中小企业对大数据的建模、运维的要求.
1 整体架构
海量数据的核心作用是统计分析,统计分析的关键步骤则在于数据建模[8],而建模过程直接跟平台集成架构方式相耦合[9],因而平台的架构方式合理与否直接影响到大数据的功能价值.海量数据平台的架构要考虑的因素有多方面,其中一个很重要的方面是数据负载[10].大数据平台的重要特征就是海量数据,且数据类型有:结构化、半结构化、非结构化等形式[11],因此数据负载是大数据架构的核心要点.
传统海量数据集成采用分布的结构[12],本数据集成架构方式则采用集中式中央处理,如图1所示,整个平台简单的划分为3层,分别为:Web应用层、数据库接口层、数据层.Web应用层为APP应用,由Java或其他面向对象语言编写的B/S服务,本层与业务相关并非我们的关注点,我们重点关注数据库接口层与数据层.
1.1 数据库接口层
数据库接口层有两台服务器组成,一台为接口服务主机,负责响应Web层的数据业务请求,另一台为接口服务热备主机,通过心跳检测的方式相连,当服务主机出现故障时,热备主机能自动检测到,并自动替代服务主机提供相应的接口服务,Web应用层与此层之间是REST方式:http+json进行接口通信.REST是一种与WebService相似的通信方式,其复杂度比WebService要小,灵活性与扩展性比WebService更强大,实现方式更简单,很多插件都提供对REST的完美支持,如Java语言的Spring框架.
1.2 数据层
数据层由若干台数据库服务器主机与备份机组成,主机与备份机之间通过心跳检测方式相连.在本层中数据库服务器分成2组,一组处理平台业务数据,一组处理平台系统数据.因应用数据具有动态性强,数据量大的特征,处理平台应用数据的服务器应该占绝大多数,平台系统数据是系统的管理数据,如系统的组织结构数据、系统用户数据、系统配置数据等,此类数据具有相对稳定、数据量相对较小等特征,因而这一组应该占用相对少的数据库服务器即可.应用数据组的数据库服务器按某一维度进行水平切片,一般是按时间顺序维度进行分片,方便数据的管理,同时对每一台服务主机配备一台备份机,用心跳的方式进行相连.平台系统数据组的数据库服务器采用主/从(Master/Slaver)方式进行连接,读/写实行分离的方式进行运作,以提高读/写的响应速度,当DB接口层有基础数据写操作的请求时,直接把数据写入Master主机,后台再异步把数据同步到Slaver从机,同步过程视服务器的忙碌程度会有一定的时间滞后,一般很短,DB接口层有基础数据的读请求时,直接从Slaver从机中读取相关数据,从而实现读/写操作的分离,减轻服务器负载,加快了响应的速度.由于平台的基础数据相对稳定,动态变化程度相对较小,因而主/从数据同步的滞后时间对其的影响可以忽略.

图1 大数据整体架构
2 实现原理
海量数据处理是利用强大的支持平台,分析数据的潜在价值[13].海量数据在实际应用中,包含多个环节的处理,最终形成监控运行状态、支撑方案决策的数据应用,在数据分析的全链条中,比较关键的2个环节是数据存储和数据计算[14],与本文所讨论的架构体系相对应即为:数据层与数据库接口层.
2.1 主从双机热备
在主从模式工作中,数据库接口层两台主备服务器以同一个虚拟IP响应对外服务,WEB应用层请求发送给主服务器,备份服务器通过心跳线侦测主服务器的运行状态,若主服务器因硬件、软件、资源等方面的原因出现故障而不能正常响应外部服务,备份服务器感知到后迅速启动本机上的服务资源,接管主机上的服务,从而完成从备份服务器到主服务器的角色转换,如图2所示.因为原主服务器与原备份服务器两台服务器使用的是同一套APP,所以主备服务器切换后不影响原来的功能服务.
2.2 数据计算
数据库接口层结构如图3所示,其由两功能模块组成,为:DAO持久化模块、连接工厂模块.持久化模块负责数据表的增、删、改、查等持久化操作的业务实现,接口向Web应用层暴露,接口层用REST的方式架构,以Http超文本传输协议进行通讯,以Json作为报文格式,通信非常简单、灵活、轻巧.连接工厂模块只负责生产对应的数据层的数据库连接(Connection),每一个连接为APP操作数据库的桥梁,供持久化模块调用,当持久化模块进行DAO的业务操作时,首先应该通过连接工厂取得DB节点的连接,进而才能进行CRUD:Create、Retrieve、Update、Delete操作.
数据层有众多的DB节点,连接工厂能通过数据库接口层中的专门的配置文件(Excel格式)准确的创建对应业务所需的DB节点数据源,在整个连接工厂中有三种类型的数据配置文件,分别是:数据源参数配置文件、读写分离配置文件、时间维度配置文件.
连接工厂的数据源参数配置文件为Excel配置文件,具体格式及配置参数见表1.其中,“实例号”为每个数据源实例的唯一标识,“文件路径”为每一个数据库节点的连接配置文件(配置:访问帐号、密码、连接池等相关资源信息)所在的位置,“主机节点”为每台数据库服务器的IP地址.每一行代表一个数据源实例,Excel配置文件中可以无限扩展数据源实例.
在平台服务启动时,接口层会从Excel配置文件读取每一行的参数信息并事先建好对应的数据源实例,存储在缓存中,在需要用到相关实例时直接从缓存中取得相关实例.
连接工厂的读写分离参数配置信息同样存储到Excel文件中,具体格式及配置参数见表2.其中,“数据表”是指数据库中的某一张系统表,“读/写操作”表示请求的性质是读操作还是写操作,“实例号”就是数据源号,与表1相对应.

图2 双机热备模式

图3 数据库接口层内部结构及交互原理

表1 数据源参数配置

表2 读写分离参数配置
当Web节点层向DB接口请求平台中的系统数据时,连接工厂会根据此表的配置信息找到对应相匹配的数据源.首先,根据操作请求的表名,找到对应的数据行,然后再根据操作性质确定唯一的数据源实例号.如,请求操作要查询日志表的日志信息,则根据表名“sys_log”,操作性质“read”,可以在此配置表中确定“DS_001”数据源实例,然后再与表1相匹配,找到已经在缓存中创建好的数据源实例,再通过数据源实例可构建出相应的数据库连接,响应Web节点查询日志的请求.如果是写日志的请求操作,则会在些配置表中找到“DS_002”的数据源,即实现了读与写操作服务器节点相分离,达到减轻服务器负载,加快响应的速度的目的.
连接工厂的时间维度参数配置信息也是存储在Excel文件中,具体格式及配置参数见表3.其中,“数据表”是指数据库中的某一张业务表,“起始日期”业务数据发生的开始日期,“结束日期”业务数据发生的结束日期,“实例号”就是数据源号,与表1相对应.

表3 时间维度参数配置
当Web节点层向DB接口请求平台中的业务数据时,连接工厂会根据此表的配置信息找到对应相匹配的数据源.首先与业务表匹配,再与开始、结束时间相匹配,最后确定唯一的数据源实例号.如,Web节点层要请求查询2018年6到8月的订单数据时,根据业务表名“order”,开始时间“2018年6月”,结束时间“2018年8月”可确定唯一的数据源实例号“DS_005”,再与表1相关联找到对应的数据源,这样就避免了在所有服务器节点上扫描订单数据,只需在“DS_005”数据源对应的服务器节点上检索相关的订单数据即可.
2.3 数据存储
数据层由若干台服务器主机集群组成,其中集群机器分成2大片,一组主机处理平台的系统数据,另一组集群主机处理平台的应用数据.
2.3.1 基础数据存储
2.3.1.1 主从结构
系统数据方面,原理结构如图4所示,服务主机采取主/从结构的形式搭配,由Master主机处理写操作,Slaver从机处理读操作,从而实现读/写相分离的模式.Master与Slaver间数据的同步,直接使用数据库系统的主/从同步功能,目前绝大多数据库管理系统都支持这一功能,即使是功能相对弱小的MySQL开源数据库也已经对这一块有很好的支持,由于Slaver为读(read)操作机器,因而其数据不会直接改变,因业务而发生变化的数据只需从Master写(write)操作机器同步过来即可.

图4 基础数据主/从结构
2.3.1.2 主从数据同步
在主服务节点与从服务节点之间的数据同步过程由三个进程来实现,其中从服务节点包含两个工作进程:文件转换进程、Socket通信进程,以及主服务节点的Socket通信进程.同步原理图5所示,步骤如下:
1)从服务节点的Socket通信进程向主服务节点进程请求读取数据库二进制日志文件内容.
2)主服务节点接收到从服务节点的TCP通信请求后,通过IO流把日志文件变化的数据信息返回给从服务节点,以响应其TCP通信请求.
3)从服务节点的Socket通信进程接收到信息后,将接收到的数据写入中继日志文件的末端,并记录其它相关信息,为下一次操作能快速响应.
4)从服务节点的文件转换进程定时侦测中继日志文件,如果发现日志文件中新追加了新的数据内容,会即时解析该日志文件中的内容变成可执行的SQL语句,同时在本服务器端执行相应的SQL语句,以两端的数据一致、同步.
2.3.2 业务数据存储
2.3.2.1 分片结构
应用数据方面,原理结构如图6所示,服务主机从某一维度对数据作切片,最常见的是对时间维度进行统一分片,也就是说,每一台服务主机上的表结构是一样的,但是不同节点上的具体的业务数据是不同的,按时间进行分片存储,例如按日历年来进行分片,可考虑每个节点的主机上存储某年的数据,也可以一台主机节点存储多年的业务数据,根据实际情况来进行切片,但要确保切片在每个节点上不重复,且要保证切片的连贯性与完整性,不能有分片被遗漏.同时,可根据实际需要为每一个主节点添加一个备份节点,主/备服务器上的所有数据完全一样,当主节点发生故障时,由备份节点替代主节点继续工作.此处每一个主节点对时间维度配置一个数据源实例节点,可根据实际无限的增加主节点.
主/备节点间可考虑使用主/从原理同步数据,也可以自己编写一个数据同步脚本,然后由系统定时器周期性的调度此同步脚本,达到数据同步的目的.当主节点发生故障时,接口层的连接工厂无法构建节点上的数据库连接,此时,连接工厂自动查找备份节点的数据源实例来构建新的连接.
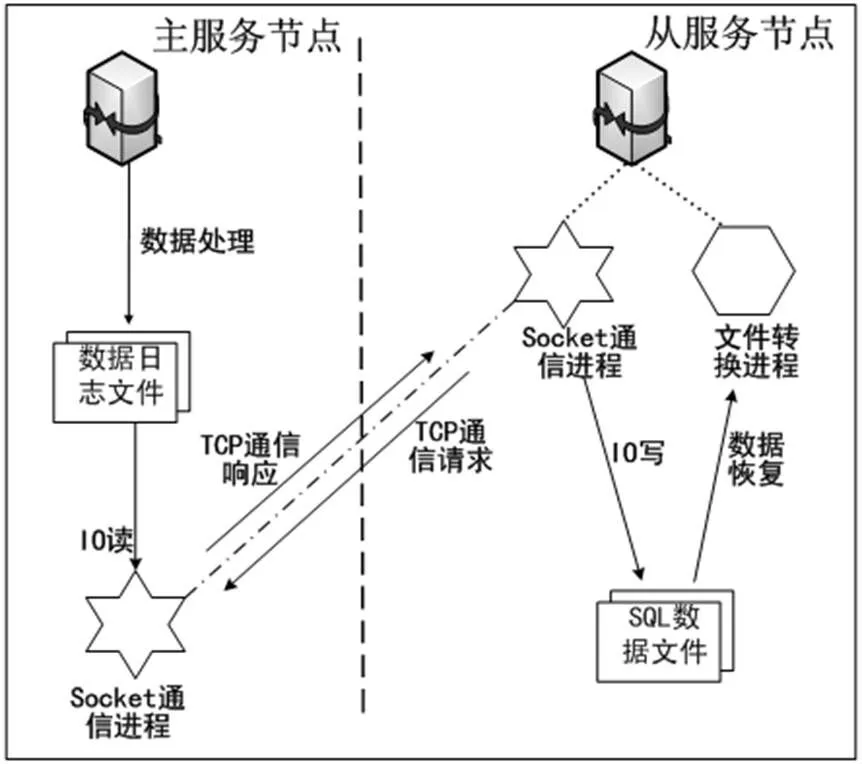
图5 主从复制原理
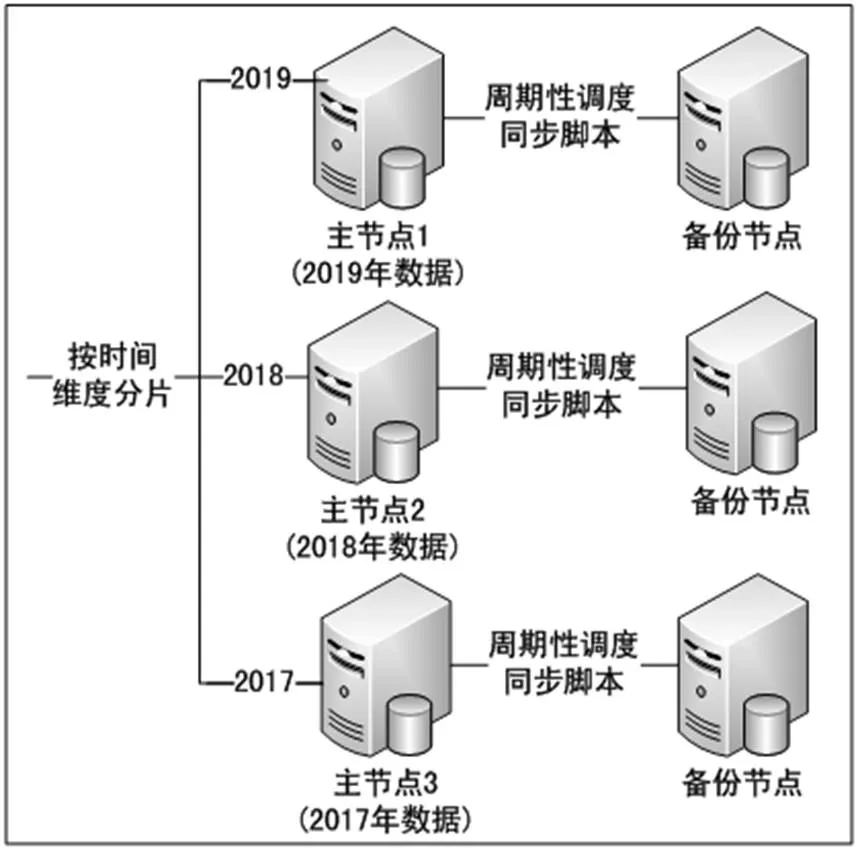
图6 按时间维度分片结构
2.3.2.2 分片原则
对于海量平台数据,首先面临的问题就是如何将数据平均的分配到不同的服务器上,使每台机器尽可能负载均衡.对于非关联数据来说,这个问题解决起来比较容易,只要平台数据尽可能的平均分布在各台主机上即可.对于关联数据来说,由于数据之间的强耦合性,如果数据分片不合理,不仅会造成机器之间负载不均衡,还会大量增加机器之间的网络通信,反而造成性能不佳,所以合理切分关联数据对于提高平台数据的运行效率非常重要[15].如图7两种分片方式中,方案1的分片方式其网络通信总量要远小于方案2的分片方式所对应的网络通信量.
衡量关联数据切片是否合理主要考虑2个因素:机器负载均衡以及网络通信成本.如果单独考虑机器负载均衡,那么最好是将数据尽可能平均地分配到各个服务器上,但是这样不能保证网络通信总量是尽可能少的;如果单独考虑网络通信,那么可以将密集交互的数据节点尽可能放到同一台机器上,这样就有效地减少了网络通信量,但是这样很难做到机器之间的负载均衡,某个较大的密集的子节点会导致某台机器高负载.所以,合理的切片方式需要在这两个因素之间找到一个较稳妥的均衡点,以期系统整体性能最优[15].

图7 不同分片方式差异
3 结 论
本海量数据架构方案不同与传统的数据集群,关系型数据库服务主节点的业务数据不需要在各个主节点间进行同步,进一步节省了数据的存储空间,具有以下几大优点:1)可扩展性好,在水平切片维度,可以根据实际需要任意扩展.如按时间维度进行切片时,可以在未来与过去的轴线上进行无缝的扩充;2)对原有业务数据兼容性好,可以在不改变、不迁移原有数据服务节点的情况完美对接现有业务数据;3)能适应各种复杂的数据环境,本方案与数据平台无关,可完全兼容各种类型的关系数据库,各种类型的关系数据库只需在各自服务节点的配置文件中配置好即可,不需要作复杂的整合.
同时本方案也还存在不足的地方,如数据分片存储后增加了不同机器上关联数据的网络开销,一定程度降低了数据分片存储的性能,寻找一种合理的分片算法来减少不同机器节点上的通信开销是下一步的研究重点.
[1] 孙峻岭,假露,刘其军,等.基于Web集群的海量影像显示技术研究[J].计算机系统应用,2019,28(4):76-82.
[2] 赵会群,刘金銮.基于贝叶斯网络的复杂事件大数据处理系统测试数据生成方法研究[J].计算机应用研究,2018,35(8):2389-2392,2396.
[3] 朝乐门,邢春晓,张勇.数据科学研究的现状与趋势[J].计算机科学,2018,45(1):1-13.
[4] 毕娅,原惠群,初叶萍,等.大数据环境下基于公共服务平台的资源多级智能寻租与匹配策略和价值创造[J].计算机科学,2019,46(2):42-49.
[5] 李志国,钟将.数据科学在国内管理学研究中的应用综述[J].计算机科学,2018,45(9):38-45.
[6] 温振蕙,樊永生,余红英.基于Thrift的HBase数据存储机制优化[J].科学技术与工程,2019,19(6):185-189.
[7] PANG Qian, YU Zhongqing, WANG Haiya. Data Resource Management Platform of Paper-making Mill Equipment Operation based on Hadoop[J]. International Journal of Plant Engineering and Management, 2019,24(1):44-51.
[8] Dawei Zhao, Gang Chen. Construction of Implicit Semantic Multi-label Text Fast Clustering Model based on Big Data[C]/Computer Science and Electronic Technology International Society, 2018:159-162.
[9] Zhang Xiaohui. Construction of Personalized English Teaching Model Driven by Big Data[C]/Computer Science and Electronic Technology International Society, 2019:371-375.
[10] 周岳,陈庆奎.面向大规模数据接入系统的负载平衡机制[J].计算机应用,2018,38(1):50-55.
[11] 史开泉.大数据结构-逻辑特征与大数据规律[J].山东大学学报(理学版),2019,54(2):1-29.
[12] QU Huan. Spatial Distribution Patterns of Cultural Facilities in Shenzhen Based on GIS and Big Data[J]., 2018,10(4):48-54.
[13] 田亚明.大数据挖掘在电商市场中分析与决策的应用[J].电子技术与软件工程,2019(7):167-168.
[14] 聂璐,郑吉洲,王丽娜,等.基于国产化服务器集群的海量数据处理负载均衡技术[J].航天控制,2019,37(1):51-56.
[15] 张俊林.大数据日知录:架构与算法[M].北京:电子工业出版社,2014:271-310.
Optimizing Strategy of Massive Data Platform Based on Localized Data and Space Centralized Scheduling
WEN Lihui
()
In view of the poor performance and low efficiency of mass data in traditional data integration, an optimum scheme based on centralized data space is proposed. First of all, the platform data is classified as either static or dynamic, so as to solve the problems that traditional integration method have, such as too large amount of data, data types confusion, and real-time response to adverse platform. Secondly, the ability of reading and writing can be enhanced and the node static data on the machine load can be reduced effectively through a master/slave separation. Thirdly, the dynamic data processing ability of the platform can be greatly improved by cluster slicing storage way. Compared with the online transaction processing (OLTP), this scheme is based on data slicing and configuration data source management. Therefore, it is more flexible and agile, better adapted to complex data environment, and more suitable to meet small and medium-sized enterprises’ demand for large data operation.
massive data; horizontal slicing; time dimension; master/slave; reading and writing separation; factory connection
10.13899/j.cnki.szptxb.2019.05.005
2019-03-27
温立辉(1979-),男,广东河源人,汉族,高级工程师,主要从事大数据、云平台、系统架构研究.
TP311.13
A
1672-0318(2019)05-0023-06
猜你喜欢
词学(2022年1期)2022-10-27 08:06:12
北京航空航天大学学报(2022年8期)2022-08-31 08:58:18
数学物理学报(2020年5期)2020-11-26 06:06:48
广东通信技术(2020年10期)2020-10-26 06:36:52
当代陕西(2019年14期)2019-08-26 09:42:00
火控雷达技术(2018年4期)2019-01-15 05:07:22
计算机与生活(2018年3期)2018-03-12 08:38:11
中国科技期刊研究(2017年2期)2017-05-14 06:16:26
中学数学杂志(初中版)(2016年5期)2016-11-01 09:00:33
浙江大学学报(工学版)(2015年2期)2015-05-30 07:05:04
