
改进Haar-like特征联合CamShift算法用于车辆跟踪
2019-10-15 06:09张晓青马牧燕燕必希朱立夫
实验室研究与探索 2019年9期
张晓青, 马牧燕, 燕必希, 朱立夫
(北京信息科技大学 仪器科学与光电工程学院,北京 100192)
0 引 言
随着车辆普及,交通系统中车辆的检测和跟踪已经成为交通系统的研究重点[1]。目前道路信息的采集传感器主要有激光雷达、红外线和视觉传感器等[2],而视觉传感器由于其价格低廉、方法简单和信息接收量丰富等优势,广泛应用于交通安全保障系统[3]。
基于视觉的车辆检测方法主要有基于特征的车辆检测[4]、基于运动的车辆检测[5]、基于模型的车辆检测[6]和基于机器学习的车辆检测[7]等方法。而基于机器学习的车辆检测方法鲁棒性好,可以实现遮挡和背景干扰较大情况下的车辆检测,因此受到广泛的关注并且取得很好的成果。李子彦等[8]利用局部HOG特征对运动车辆进行检测,该方法检测效率较高、灵敏度好,但检测的实时性较差,并且对距离较远的车辆较难检测。Roxana等[9]利用一类支持向量机(OC-SVM)分类来检测运动车辆,该方法首先利用自适应混合高斯模型检测车辆区域,提取几何特征并利用卡尔曼估计进行跟踪,同样该方法实时性差,检测效果一般。Daniel等[10]基于Haar-like、LBP和HOG特征联合的图像分类器方法,利用立体模型对运动车辆进行检测,但该方法算法复杂、检测效率较差,仅适用于特定环境。Shaif等[11]利用Haar特征的分类器对车辆进检测,该方法实时性好,但检测效率一般。朱彬等[12]利用Haar特征和LBP特征分区域多分类器法对车辆进行检测,该方法检测效果好、实时性较强,但稳定性一般。余小角等[13]利用Haar特征和AdaBoost算法对车辆进行检测,可以有效检测车辆,但检测效率低。
本文提出一种改进Haar特征结合CamShift算法的特定车辆检测跟踪方法,利用倾斜45°特征与像素和的商计算Haar特征值,其次利用AdaBoost算法训练样本得到分类器,并构建特征样本级联分类器,利用获得的特征级联分类器对视频图像进行检测,最后将检测结果中的特定车辆外切矩形作为CamShift算法的初始窗口,并对该跟踪窗口进行检测,提高了车辆的检测效率和实时性。
1 改进的图像信号Haar特征提取
1.1 改进的Haar-like特征
Haar-like分类器检测目标是利用已知训练样本的特征,与未知图像的特征进行对比,实现目标的检测。该方法经典应用是人脸检测,一般使用两个矩形特征,将白色与黑色区域像素和做差就可满足检测要求。
传统Haar-like特征值有3种类型,即水平、垂直、对角线等特征,而对于车辆等目标具有随机性、灰度图像差值较大、背景灰度差值较小的目标,做差的方法造成弱分类器的检测性能较差,使得强分类器在级联时需要大量的弱分类器。因此,提出利用扩展之后的45°特征,并将黑白区域的像素和做除法,求得改进Haar特征,利用该特征来进行检测,增强弱分类器检测性能。扩展后特征如图1所示。
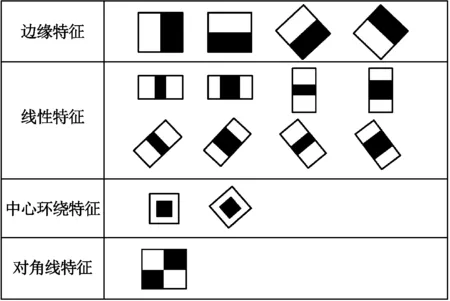
图1 扩展之后的特征
1.2 改进Haar特征的积分图计算
图像中Haar-like特征值数量远超过像素的数量,因此,可利用积分图计算Haar-like特征值,提高图像信号特征的计算效率。车辆的特征可以由一些简单的矩形特征和倾斜45°边缘特征进行描述,如图2所示。车辆的花色区域比纯色区域颜色深,因此可以利用倾斜45°边缘特征检测识别车辆。





图2 车辆Harr-Like特征图
积分图只需要对图像遍历一次就可以求出图像中任意坐标点(x,y)左上角所有像素和,
(1)
式中:ii(x,y)表示积分图;i(x′,y′)为原始图像的灰度值。其积分图的计算模型如图3所示。图中:A(x,y)表示点(x,y)的积分图;s(x,y)表示点(x,y)的y方向所有原始图像像素之和。其表达式如式:
s(x,y)=s(x,y-1)+i(x,y)
(2)
ii(x,y)=ii(x-1,y)+s(x,y)
(3)
点(x,y)的积分图是图3中阴影部分所有元素和的数组,因此对于阴影区域像素和的计算,仅仅作4次数组计算检索,就可以得到图像像素和。
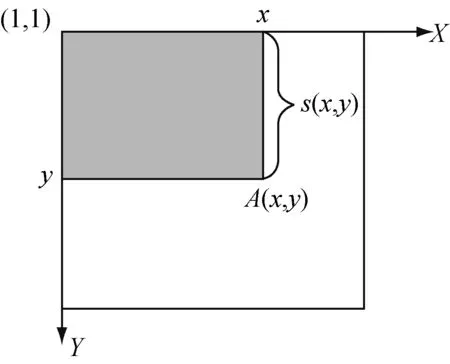
图3 点坐标的积分图
对于任意区域D的像素和的积分图模型如图4所示。图中:A区域的像素和表示为ii(1);A+B区域的像素和表示为ii(2);A+C区域的像素和表示为ii(3);A+B+C+D区域的像素和表示为ii(4)。则得到区域D的像素和为
D=ii(4)-ii(3)-ii(2)+ii(1)
(4)
对于两个区域像素和的差,其矩形特征如图5所示。图中,矩形特征的特征值为A、B区域像素和的差,
A-B=[ii(5)-ii(4)-ii(2)+ii(1)]-
[ii(6)-ii(5)-ii(3)+ii(2)]
(5)

图4 积分图模型
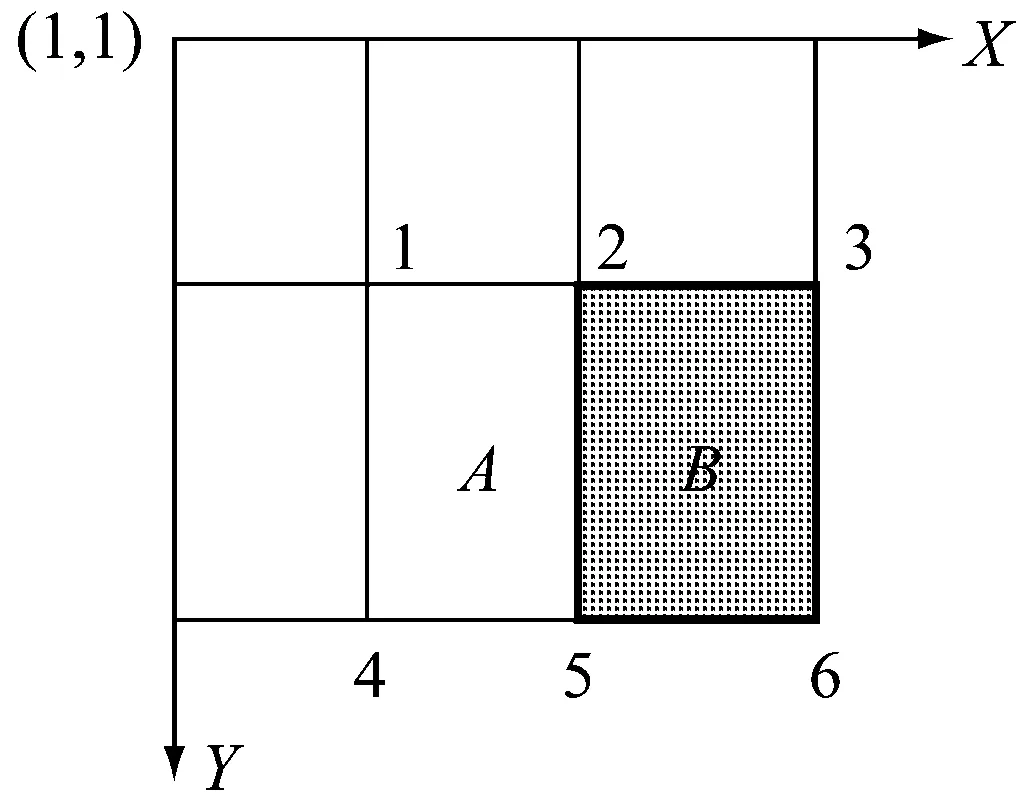
图5 矩形区域特征值
将A、B区域进行45°旋转得到倾斜45°矩形特征,如图6所示。


图6 倾斜45°边缘特征
对于积分图像内一点(x,y),旋转积分图像
对于任意旋转矩阵B(x,y,h,w,45°),假设区域的边缘长度为w,宽度为h,则B内的像素值之和
sum(B)=Rii(x+w,y+w)+Rii(x-h,y+h)-
Rii(x,y)-Rii(x+w-h,y+w+h)
(6)
则倾斜45°特征的像素和的差值
A-B=sum(A)-sum(B)
(7)
倾斜45°特征的像素和的商
A/B=sum(A)/sum(B)
(8)
可以看到,通过对矩形端点积分图的运算,就可求得车辆倾斜45°图像信号的特征值。
2 AdaBoost算法
2.1 信号分类算法原理
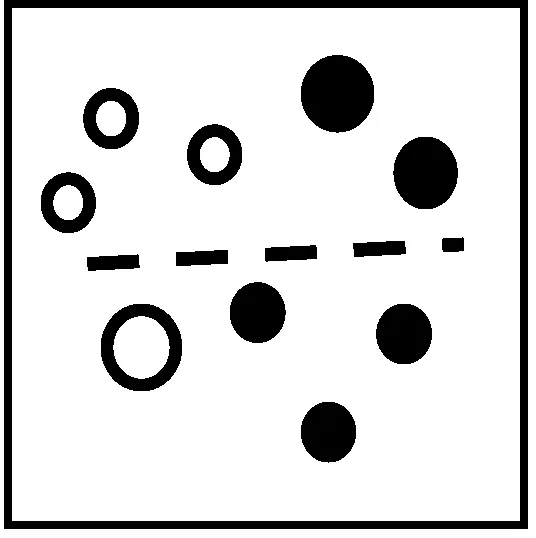
AdaBoost算法本身能够对学习获得的弱分类器进行自适应调整[14],按照一定的权重组合构成最终检测的强分类器。AdaBoost算法主要有两部分[15]:①弱学习算法,该算法的识别效果仅仅略高于随机识别的效果;②强学习算法,该算法可以实现理想的识别效果,并能够在预期时间内完成。该算法利用训练集中样本分类的准确度和整体分类的准确度确定权重,增加或减少分类的样本权重,可以准确划分最终分类结果。AdaBoost算法原理如图7所示,利用AdaBoost算法将白色和黑色进行分类。

(a)
(b)

(c)

(d)

(e)

(f)
图7 AdaBoost分类原理
在图7(a)中存在错误的分类样本,因此,必须增加错误分类中小球的权重,如图7(b)所示;再次分类时,主要针对权重较大的小球类进行分类,如图7(c)所示;同理,图7(d)为增加图7(c)中错误分类小球权重的分类图,图7(e)为重新分类的结果,图7(f)为图7(a)、图7(c)和图7(e)3个弱分类器训练之后的最终的强分类器。
2.2 级联分类器检测
在车辆检测过程中,一般用多尺度的检测窗口进行遍历检测图像,而现实中检测的大部分窗口都是非车辆,造成检测耗时,因此通过级联分类器使得检测窗口尽量包含车辆检测区域,提高检测效率。级联分类器就是将若干强分类器按照复杂度排列成顺序结构,对其中某一个分类器后续的训练样本,通过和其之前所有分类器分类的样本进行比较,最后形成级联分类器。车辆级联分类器的级联过程如图8所示。
图8中,强分类器1~N体现了级联分类器的结构,提取所有检测窗口,对每层强分类进行比较,当满足参数要求即为检测目标并进行下一步检测;如果不满足则为负样本,通过调节样本的检测度参数,使其对车辆具有较高的检测精度,同时确保正样本车辆继续到下一级分类器中继续判断。最后经过设定层数,判断每层强分类器,最终确定被检测车辆。

图8 车辆分类器级联过程
3 分类器检测的目标跟踪
根据分类器方法检测到运动车辆,由于实际检测中车辆数目和位置的不同,检测图像清晰度和窗口大小的不同,导致分类器跟踪算法难以对特定车辆进行跟踪,并且窗口太大,对视频图像信号的跟踪难以达到实时性要求。利用CamShift算法和上述分类器结合的方法,将分类器检测到的车辆信号作为CamShift算法的初始窗口,然后对后续图像窗口进行跟踪,实现了CamShift自主选择窗口的效果,并在下次分类器检测时只针对此跟踪窗口进行检测,大大提高检测效率。
3.1 色彩反向投影
车辆检测跟踪过程中,随着天气和车辆位置的变化,使得运动车辆在图像中的颜色受到影响,导致检测与跟踪受到严重干扰。RGB颜色空间容易受到环境的影响,因此,将其转换为HSV颜色空间,该空间中利用单通道对图像进行处理将不会受到光照等造成的影响,其中h为色调、s为饱和度、v为明度。其转换公式如下:
v=max
根据HSV颜色模型,对检测到车辆的h分量作直方图,统计不同h分量值像素的概率,并利用其替换像素的值,最终得到颜色概率分布图实现反向投影。
3.2 MeanShift算法
MeanShift算法通过计算目标区和候选区内像素的特征值概率得到目标模型和候选模型;其次利用初始帧模型和当前帧模型的相似性,进行迭代;最终收敛到真实位置,实现目标跟踪。
MeanShift算法于车辆的跟踪分为4个步骤:
(1) 根据被检测到的车辆确定颜色概率分布图,选定车辆的搜索窗口。
(2) 计算该窗口的零阶距
一阶矩
搜索窗口的质心
xc=M10/M00,yc=M01/M00
(4) 移动搜索窗口的位置到质心的位置,如果移动距离大于设定的阈值距离,重复上述操作;如果移动距离小于设定的阈值距离,则停止计算。
3.3 CamShift算法
由于MeanShift算法在跟踪过程中搜索窗口不能调整大小,无法跟踪形变的目标,而CamShift算法是对该算法的一种改进,可以随时改变搜索窗口的大小,实现对目标的跟踪,CamShift算法的具体过程如下:
当MeanShift算法计算第(2)和第(3)步的同时,通过计算二阶矩可求得目标长短轴和方向角:
(9)
令:
则图像目标的长短轴和方向角为:
(10)
式中:l为长轴;w为短轴;θ为方向角。如果第(4)步移动窗口距离小于阈值,则得到目标区域大小(w,l),即为当前帧的位置和大小,并返回第(1)步再次重复搜索。
4 目标检测结果与分析
实验基于VS2010和OpenCV2.4.9实现车辆正、负样本训练集的获取分割、级联分类器的训练和最终的检测试验,实验流程图如图9所示。图中,左边虚线框为离线处理,利用相机采集正样本车辆和负样本公路图像做训练集,然后训练获得分类器;右边虚线框为实时在线处理,利用相机实时获得图像,并进行相同处理,并与离线处理分类器作对比来检测车辆。

图9 车辆检测实验流程图
检测车辆样本获取:Haar特征训练集的制作中,正负样本比例为1∶3,根据车辆在公路和街区中的行驶环境,拍摄车辆图片1 500张,部分图片如图10所示。










图10 车辆部分图
根据拍摄车辆图像构建正样本训练集,并对样本进行归一化处理,调整大小为20×20像素,处理后图像如图11所示。









负样本中,利用不存在正样本的任何图像都可以进行训练集的建立,然而,由于车辆的行驶环境,利用环境背景能更好地体现出训练集的鲁棒性。因此,采用公路和街区环境作为负样本,负样本部分图像如图12所示,尺寸不小于正样本尺寸,数量不低于正样本的3倍,最后进行归一化处理。













图12 负样本部分图
负样本数量是4 500张不包含正样本的环境背景图,归一化为20×20像素大小的训练样本,完成负样本训练集的建立。
用车辆正负样本集对标准Haar-like分类器算法和改进的Haar-like分类器算法分别进行实验。为了验证改进的Haar-like算法的有效性,对同一识别场景中,早晨、中午和傍晚3种不同环境的交通视频进行检测测试,然后对其实验结果进行对比,对比结果如图13所示。

图13 检测对比图
图13中,第1行为标准Haar-like分类器算法,第2行为改进的Haar-like分类器算法。从图中可以看到,相对于标准Haar-like分类器算法,使用改进的Haar-like分类器算法能更好地检测运动车辆,并且每天3个时刻,改进后的算法检测具有良好的检测效果。
为了对实验结果中识别率和误识别率进行对比,采用识别率TR(True Rate)和误识别率FR(False Rate)对检测结果进行评价,
(11)
式中:TD表示正确检测到车辆的个数;FD表示将非车辆检测为车辆的个数;FN表示未检测到的车辆个数。对生活场景中1 000幅960×720的像素车辆图像进行检,每幅图像检测时间约为24 ms,并对标准Haar分类器法和改进Haar分类器法的检测率进行对比,对比结果如表1所示。
由表1可见,早晨和中午时,车辆检测效率较高,傍晚时刻由于光照等条件的影响,检测效率略低。与标准的Haar-like分类器算法相比,改进的Haar-like分类器算法正确检测车辆数目更多,而且对于不同时间的检测,本文提出的算法识别效果也更为出色。
其次在检测到的车辆窗口中,选择目标车辆作为初始窗口,然后利用CamShift算法对该车辆进行跟踪,并在后续跟踪窗口对车辆进行检测,其跟踪检测效果如图14所示。

表1 车辆检测识别率和误识别率检测对比 %

图14 改进Haar-like分类器联合CamShift算法车辆跟踪图
图14中,首先利用改进Haar-like分类器对视频中车辆进行识别,当在视频第274帧时,选择其中的某一特定车辆作为被跟踪对象,如图中第288帧所示。然后对该车辆利用CamShift算法进行后续跟踪,最后对跟踪窗口进行车辆检测,如图中第323帧、第338帧和第354帧所示,直到车辆继续前行到达第372帧,目标距离较远时,依然能够继续跟踪车辆,并且检测时间只有15 ms,大大提高检测效率。
因此,利用信号的改进Haar-like特征和AdaBoost算法,能够对车辆进行有效检测;利用CamShift算法跟踪车辆,对后续跟踪窗口进行车辆检测,可以有效地减少车辆检测搜索窗口,提高检测效率。
5 结 语
首先利用车辆信号改进的Haar-like特征和AdaBoost算法,对交通车辆进行检测并与标准Haar-like分类器算法进行对比,结果表明改进算法对车辆在早晨、中午和傍晚的识别率分别为91.77%、91.99%和87.93%,体现出算法对车辆检测的优越性。最后利用CamShift算法对特定车辆进行跟踪,并对后续图像中CamShift算法跟踪窗口进行检测,实现特定车辆检测与跟踪,体现了Haar-like分类器算法结合CamShift算法的实时性,证明了研究方法的正确性。
猜你喜欢
核安全(2022年3期)2022-06-29
小哥白尼(军事科学)(2022年2期)2022-05-25
红领巾·萌芽(2019年8期)2019-08-27
—— “T”级联
同位素(2019年1期)2019-03-14
中国与非洲(法文版)(2017年10期)2017-11-23
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
CHIP新电脑(2016年3期)2016-03-10
原子能科学技术(2015年12期)2015-07-07
原子能科学技术(2015年1期)2015-05-25
