
基于短时自相关的语音感知哈希认证算法
2019-10-11 07:26张永兵米保全
无线电工程 2019年10期
张永兵,米保全,周 亮,张 涛
(1.甘肃机电职业技术学院,甘肃 天水 741001; 2.兰州理工大学 计算机与通信学院,甘肃 兰州 730050)
0 引言
多媒体语音作为传递信息最为直接和方便的多媒体应用之一,在一些特定的环境下包含有重要和敏感的机密内容,如金融会议、法庭证据、军事指令和通信录音等。与此同时,现代音频处理工具的多样化以及无线和网络等通信信道的开放性,使得对于语音的改动变得非常容易。在即时通信领域内,如何在确保语音通信的安全性、真实性以及完整性的前提下,进行安全通信的传输认证操作,具有十分重要的研究意义[1-2]。
语音的感知特征作为语音信号的重要参数,感知哈希技术是通过提取语音信号中的感知特征并映射成一段唯一的摘要,通过数学距离进行度量,可以建立一种有效机制来比较2个语音片段的听觉质量,并为语音内容的认证、检索以及拷贝威慑等信息服务方式提供安全可靠的途径[3-5]。通常,在录制语音时,会对语音进行压缩、采样和剪切等操作,并且难以避免地会引入一定的环境噪声,这些操作对感知哈希系统的性能会产生很大影响[6-7],如何降低这些操作对认证性能的影响是研究中首要关注的问题。
目前,在文献[8]中由Kalker T等提出的语音感知哈希算法得到了广泛应用。通过利用感知哈希技术来进行验证多媒体音频信息的内容完整性和真实性,以此来达到保护多媒体信息的目的。针对语音信息的独特特性,选取感知哈希技术作为支持,生成由语音内容感知特性映射得到的感知哈希特征值,可以对语音、音频以及宽带音频信号进行认证。近年来,国内外研究学者对语音感知哈希认证算法做了大量研究,对特征的提取和处理方法众多,其基本思路是研究如何利用语音信息的时频特性[9-11]、梅尔频率倒谱系数[12]、多重分形特征[13]等,或几种特征相结合的特征构造感知哈希值。Huang等人[14]在文献中提出了一种语音自适应梅尔频率倒谱系数和线性预测倒谱系数融合的语音感知哈希算法,该算法通过由语音生成的感知哈希串来进行哈希匹配,以此来实现语音信号的认证。此算法有效提高了哈希认证的鲁棒性,并且可以实现语音内容小范围篡改的检测,但是此算法的区分性和鲁棒性表现一般。Chen等[15]提出一种线性预测结合非负矩阵语音感知哈希算法,该算法在认证效率上有较好的表现,但是算法的区分性和鲁棒性效果不佳。
针对上述文献中遇到的问题,为了进一步权衡语音感知哈希算法在语音内容保持操作鲁棒性和区分性折中的平衡性,获得较好的鲁棒性和区分性,以及可以满足现有环境下语音通信的语音内容认证算法复杂度低和认证精度高的要求,提出了一种基于自相关的语音感知哈希认证算法。设计了一种基于短时互相关系数的语音感知哈希算法,并通过得到的感知哈希序列对语音数据进行内容认证。通过利用语音数据的短时互相关特征,并结合非负矩阵分解得到的特征参数矩阵所构造的感知哈希序列具有较好的鲁棒性和区分性,能够满足对语音内容完整性认证的需求。
1 相关理论
1.1 短时自相关
语音信号在短时范围内可以认为是稳态、时不变的,故在语音信号相关性分析时采用短时分析技术。在短时分析中,通过对语音分帧来分析每帧语音的特征参数,对整体的语音信号来讲,每一帧特征参数构成了其特征参数序列。设语音信号为s(n),通过加窗函数分帧处理后得到第i帧的语音信号为si(m),可定义为:
si(m)=ω(m)×s((i-1)×inc+m),
1≤m≤L,1≤i≤fm,
(1)
式中,ω(m)为窗函数;si(m)为第i帧的数值,m=1,2,…,L,i=1,2,…,fm,L为帧长;inc为帧移长度;fm为分帧后的总帧数。
自相关函数用于衡量信号自身时间波形的相似性。语音信号s(n)按式(1)分帧后为si(m),i表示第i帧(i=1,2,…,fm)。每帧数据的短时自相关函数定义为:
(2)
式中,L为语音分帧后每帧的长度;k为延迟量;m为帧内样点,m=1,2,…,L。
在信号分析理论中,自相关函数能够用来确定输出信号有多大程度来自输入信号,是在噪声背景下提取有用信息的重要方法,广泛应用于语音、图像处理等信号分析中。对于语音信号来说,短时自相关分析是一个重要的方法,能够用来求解浊音的基音周期,以及语音识别中的特征参数等[16]。本文将提取语音信号的短时自相关系数来构造用于认证的语音感知哈希序列。
2 基于短时自相关的语音感知哈希认证算法
基于短时自相关的语音感知哈希认证算法流程如图1所示。
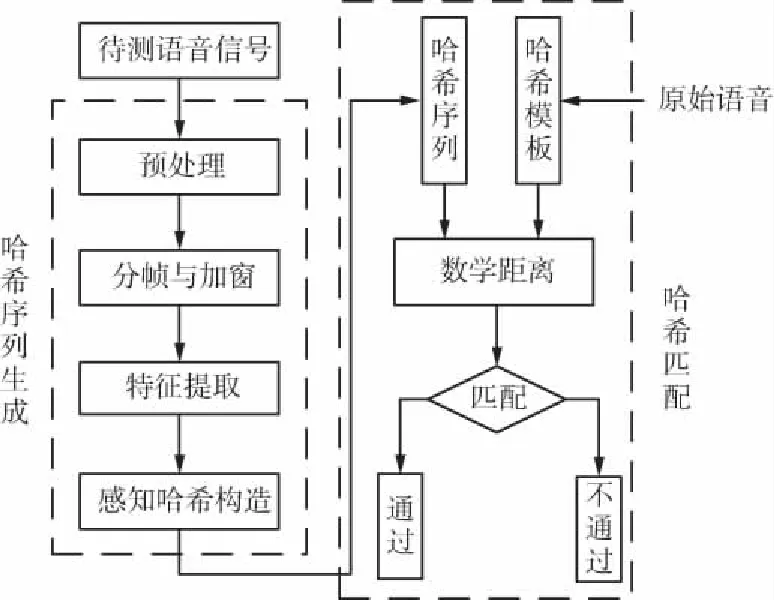
图1 语音感知哈希认证算法流程
语音信号经过预处理和分帧与加窗后,采用短时自相关分析求得自相关系数矩阵,并将其构造为用于认证的感知哈希序列。对语音信号进行感知哈希构造和匹配的详细处理步骤如下:
步骤1:预处理。
设输入的语音信号为s(n),通过数字滤波器预加重处理后的语音为s′(n),其目的是对语音的高频部分进行预加重处理,去除杂音的影响,并增加语音的高频分辨率,以便于更好地提取语音的感知特征。
步骤2:分帧与加窗。
语音信号在短时范围内可以认为是稳态、时不变的,故通常对语音进行分帧处理来分析每帧的特征参数,对s′(n)利用式(1)可得到通过加窗函数w(m)分帧处理后的第i帧语音信号si(m)。
步骤3:特征提取。
根据式(2)首先计算每帧语音信号si(m)的自相关系数,得到自相关系数矩阵X(fm,B),其中B为计算每个语音帧所得到的自相关系数的长度,为2L-1;然后对互相关系数矩阵X(fm,B)的每一条行向量[g(1,Bj),g(2,Bj), …,g(fm,Bj)]′中的数值进行降序排列,其中j=1,2,…,2L-1,并由每一行中数值较大的值构成最终的自相关系数矩阵G(fm,,D),其中D为每一行中数值较大的系数个数,即相关性较大的数值个数,综合考虑算法的效率和感知哈希的性质,本文方法中D的取值为24;最后,对矩阵G(fm,,D)利用非负矩阵分解进行降维处理,生成最终的特征参数矩阵H1(fm,1)。
步骤4:感知哈希构造。
对特征参数矩阵H1(fm,1)进行二进制哈希构造,则语音信号s(n)的感知哈希序列为H。计算H1(fm,1)矩阵的中值hm,并把其放到该矩阵最后新增一列,则H1(fm,1)矩阵变为H1(fm,hm)。二进制哈希构造方法为:用参数矩阵中的上一行数据减下一行数据,若大于0,则该行数据变为1,否则为0。即
(3)
步骤5:哈希匹配。
对于2个语音片段s1,s2,H1记为语音信号x1的感知哈希值,H2记为语音信号x2的感知哈希值,研究采用归一化汉明距离来度量2段语音信号的相似性。D记为H1,H2的归一化汉明距离D(:,:),即比特误码率(Bit Error Rate,BER),表示感知哈希序列错误比特数与总比特数的比值,计算公式为:
(4)
式中,N为感知哈希序列的总长度;i=1,2,…,fm。对语音感知哈希系统的性能进行评价,可以用以下的假设性检验来描述:
P0:若s1,s2感知相同,则D(H1,H2)≤τ;
P1:若s1,s2感知不同,则D(H1,H2)>τ,
τ为感知认证阈值,通过设置匹配阈值τ的大小,比较语音段s1,s2的感知哈希序列的数学距离。若2条语音段的数学距离D(H1,H2)≤τ,则认为2个语音段s1,s2的感知内容相同,认证通过;否则,认证不通过。
3 实验结果及分析
实验中所用的语音数据库是TTS(Text to Speech)和TIMIT(Texas Instruments and Massachusetts Institute of Technology)中的语音,由英文男女、中文男女录制的不同内容语音所组成,采样精度为16 bit、采样频率为16 kHz,长度为4 s的wav格式语音段,共1 280段,单声道。其中英文600段,中文680段。实验硬件平台为:Intel(R) Core(TM) i5-3337U CPU,1.80 GHz,内存4 G。软件环境是Win7下的Matlab R2014a。
3.1 区分性分析
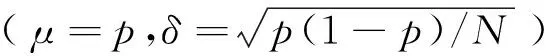
通过对1 280条语音段进行感知哈希值的两两匹配,得到818 560个BER数据。这些BER数据之间的分布规律如图2所示。可以看出,不同语音的BER值的概率分布与标准正态分布的概率曲线几乎在同一条直线上,所以本文提出的算法所计算得到的感知哈希的数学距离值近似服从正态分布。
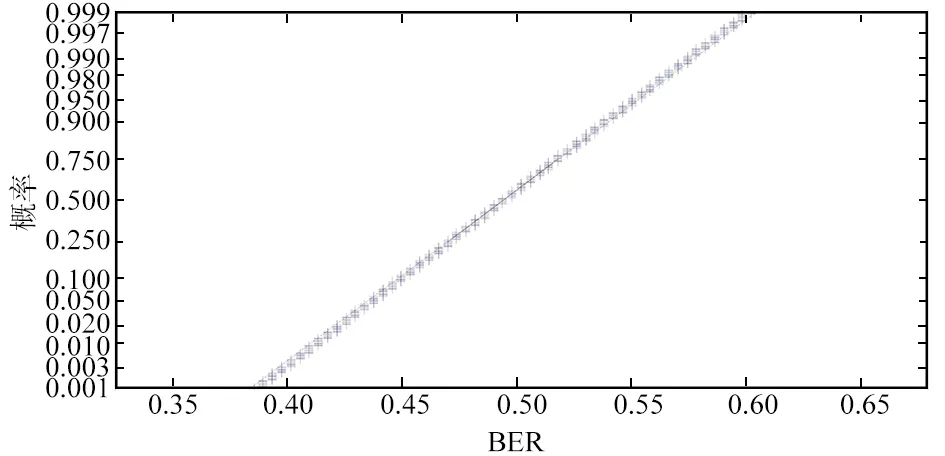
图2 BER分布规律
为了进一步验证实验的正确性,计算了算法的误识率(False Accept Rate,FAR):
(5)
式中,τ为感知认证阈值;μ为BER均值;δ为BER方差;x为误识率。不同算法在不同阈值下的FAR值如表1所示。
表1 不同阈值下的FAR值

τ文献[17]文献[18]本文算法0.102.94×10-211.48×10-223.19×10-300.151.14×10-161.05×10-171.67×10-230.201.11×10-121.73×10-131.11×10-170.252.75×10-096.75×10-109.56×10-130.301.68×10-066.25×10-071.08×10-8
感知哈希算法的FAR值越低,说明感知哈希算法的区分性越好。从表1可以看出,本文提出的语音感知哈希认证算法FAR好于文献[17-18],主要是因为所提取的语音短时自相关感知特征更能表征语音信号。当设置匹配阈值τ=0.3时,每108个语音片段大约有1个被误识,表明本文算法具有较强的抗碰撞能力,即具有良好的区分性,能够满足语音内容的认证要求。
3.2 鲁棒性分析
通常,音频信号经过一些增加减小音量、滤波、压缩和重采样等操作处理后,其在音频信号中的数字表示所产生的特定改变不影响内容表达。感知哈希的鲁棒性是指原始语音数据与其通过内容保持操作处理后的语音之间的BER小于预设阈值,鲁棒性实验需要对原始语音段和其内容保持操作之间的BER进行分析,所用的内容保持操作类型共有9种,具体如表2示。
表2 内容保持操作种类
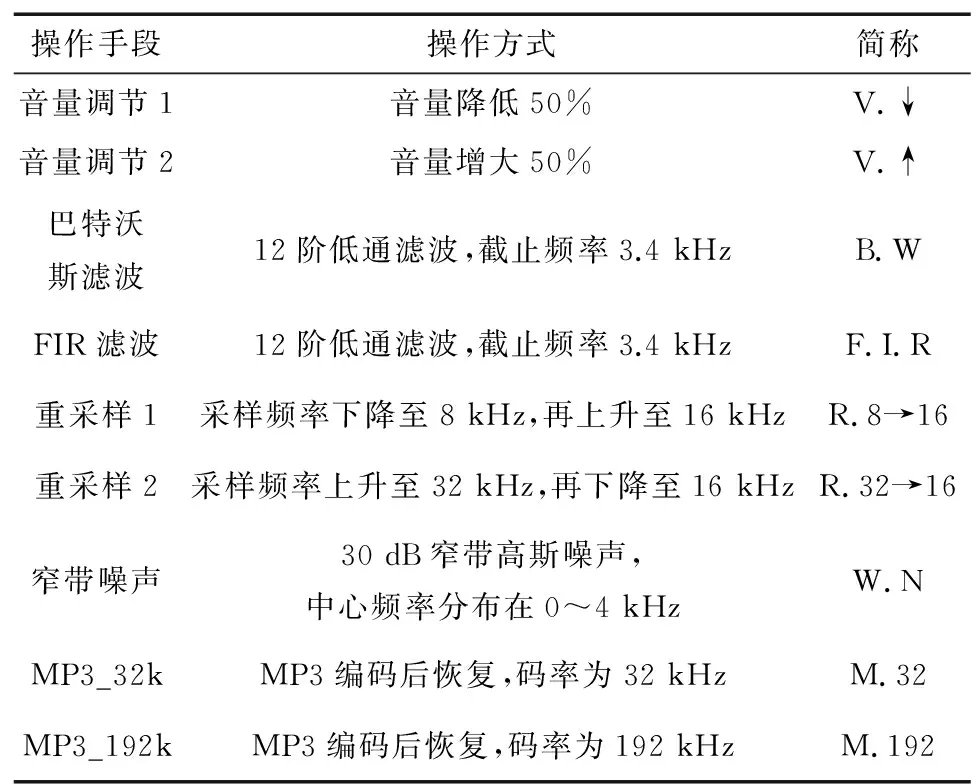
操作手段操作方式简称音量调节1音量降低50%V.↓音量调节2音量增大50%V.↑巴特沃斯滤波12阶低通滤波,截止频率3.4 kHzB.WFIR滤波12阶低通滤波,截止频率3.4 kHzF.I.R重采样1采样频率下降至8 kHz,再上升至16 kHzR.8→16重采样2采样频率上升至32 kHz,再下降至16 kHzR.32→16窄带噪声30 dB窄带高斯噪声,中心频率分布在0~4 kHzW.NMP3_32kMP3编码后恢复,码率为32 kHzM.32MP3_192kMP3编码后恢复,码率为192 kHzM.192
本文提出的基于短时自相关的语音感知哈希认证算法与文献[17-18]中提出的方法,经过表2所列出的内容保持操作后的1 280条语音片段的感知哈希值与原始数据的感知哈希值进行数学距离计算,在执行每个内容保持操作实验时计算平均BER,对比结果如表3所示。
表3 平均比特误码率比较
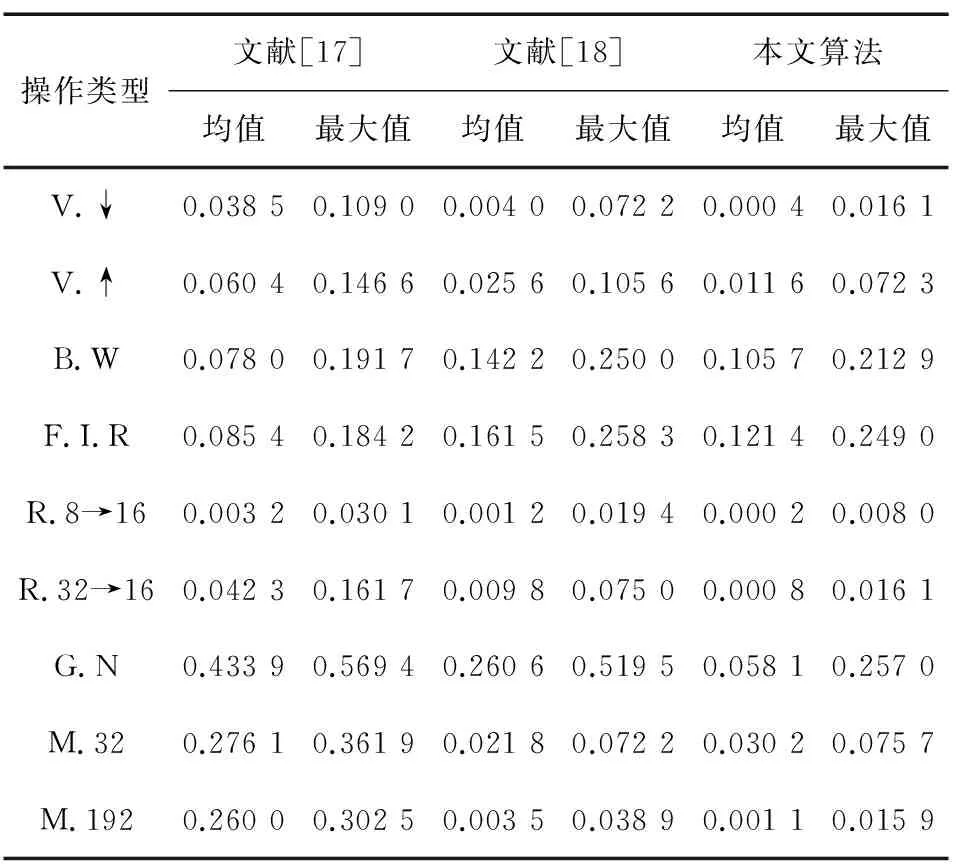
操作类型文献[17]文献[18]本文算法均值最大值均值最大值均值最大值V.↓0.038 50.109 00.004 00.072 20.000 40.016 1V.↑0.060 40.146 60.025 60.105 60.011 60.072 3B.W0.078 00.191 70.142 20.250 00.105 70.212 9F.I.R0.085 40.184 20.161 50.258 30.121 40.249 0R.8→160.003 20.030 10.001 20.019 40.000 20.008 0R.32→160.042 30.161 70.009 80.075 00.000 80.016 1G.N0.433 90.569 40.260 60.519 50.058 10.257 0M.320.276 10.361 90.021 80.072 20.030 20.075 7M.1920.260 00.302 50.003 50.038 90.001 10.015 9
从表3可以看出,本文提出的语音感知哈希认证算法对9种内容操作手段的鲁棒性整体好于文献[17-18],并且本文算法的BER均值都较小,鲁棒性很强,能够较好地满足认证需求。
和区分性分析类似,语音认证系统常用误拒率(False Reject Rate,FRR)用来评价感知哈希算法的鲁棒性,它表示感知相同的语音内容被系统判定为感知不同的概率,计算公式如式(6)所示,其中μ表示BER的均值,δ表示BER的标准差,τ表示BER阈值:
(6)
为了对算法整体的鲁棒性和区分性进行说明,绘制了FAR-FRR曲线进行进一步说明,对1 280个语音段进行感知哈希值的两两对比,得到了818 560个BER数据,再根据表2所述内容保持操作得到BER,获得FAR和误拒率(False Reject Rate,FRR),绘制出FAR-FRR曲线,对比文献[18]FAR-FRR曲线的结果如图3所示。

图3 本文算法与文献[11]的FAR-FRR曲线比较
从图3(a)可以看出,影响区分性的FAR和鲁棒性的FRR的值有明显的判决空间,说明本文算法同时具有良好的区分性和鲁棒性,能够准确地识别经过内容保持操作的语音和不同内容的语音,很好地平衡了算法的区分性和鲁棒性。对比图3(b),文献[18]在图中发生了交叉,表明文献[18]算法不能很好地解决区分性和鲁棒性之间的平衡,这是由于文献[18]所提算法对添加窄带高斯白噪声操作的鲁棒性较差,并且由于本文FAR-FRR曲线没有明显的判决空间,设置一定的阈值就能很好地将这2种操作区分开。
4 结束语
本文提出了一种基于短时自相关的语音感知哈希认证算法,该算法提取了语音信号的短时自相关特征作为感知特征来构造哈希值,通过计算哈希值之间的数学距离,对语音内容进行认证,并着重分析了算法的鲁棒性和区分性,通过实验分析可知,本文算法具有较强的区分性,能够较好地对不同内容语音进行认证,同时本文算法的鲁棒性表现也非常突出,并且本文算法的FAR-FRR曲线之间有明显的判决区间,很好地平衡了算法的区分性和鲁棒性,可以满足语音在实时通信环境下语音认证要求。但缺点是认证效率一般,接下来需要进一步提升认证效率。
猜你喜欢
小学生学习指导(高年级)(2022年10期)2022-11-04
大数据(2021年6期)2021-11-22
电脑爱好者(2021年8期)2021-04-21
科技研究·理论版(2021年22期)2021-04-18
电脑爱好者(2020年20期)2020-10-22
——日晕
奥秘(创新大赛)(2019年4期)2019-04-15
奥秘(创新大赛)(2019年3期)2019-03-13
作文评点报·低幼版(2018年17期)2018-07-12
电脑知识与技术(2016年28期)2016-12-21
汽车科技(2016年5期)2016-11-14
