
基于RS-SVM算法的配电网故障诊断方法
2019-10-10 07:05贾志成张智晟刘远龙徐中一
广东电力 2019年9期
贾志成,张智晟,刘远龙,徐中一
(1.青岛大学 电气工程学院,山东 青岛 266071; 2.国网山东省电力公司,山东 济南 250001;3.国网山东省电力公司检修公司,山东 济南 250118)
随着我国经济的高速发展,用电需求快速增长,电力行业进入一个崭新的阶段,建设高效安全、稳定运行的电力系统是新时代社会生产力发展的必要基础。配电网作为电力系统中配电环节的末端基础网络,其结构复杂多变,引起测控对象多、电网拓扑结构复杂、终端使用环境恶劣等问题。
配电网的数据采集与监视控制系统(supervisory control and data acquisition,SCADA)在收集故障数据的过程中,需要处理海量的故障告警信息,其中夹杂着大量多重故障、故障信息缺失、断路器及保护动作的拒动和误动等复杂故障信息,严重降低配电网故障诊断的效率,影响电网运行可靠性和连续性[1-3]。面对这一现状,需要有更加高效准确的故障诊断系统处理配电网运行中出现的各种故障信息,通过数据预处理提取出有效信息,对出现故障的线路或区域进行快速诊断识别,方便调度人员及时切除故障。
目前,国内外大部分有关配电网故障诊断的研究主要基于模糊理论[4-5]、Petri网络[6-7]、人工神经网络[8-9]、最优化技术[10-11]等方法理论。文献[12]提出了一种将模糊理论、专家系统和人工神经网络相结合的故障诊断方法,采用矩阵运算和模糊逻辑数据库进行故障诊断,验证了其在处理信息缺失情况时的准确性和易用性,但该方法仅适用于小规模的配电网;文献[13]基于保护和断路器逻辑动作规则,结合时序关联特征,提出了一种依据正反向搜索推理逻辑改进的贝叶斯Petri网络模型,算例表明该模型对于故障信息缺失情况和组合故障诊断时具有良好的容错率和可靠性,但该方法精确度不高;文献[14]提出了一种利用混沌映射理论与径向基函数(radial basis function,RBF)神经网络结合的处理算法,通过训练学习调整权重和参数,对比BP神经网络,该算法的预测精度和收敛速度更具优势,其缺点在于没有考虑信息缺失状况;文献[15]考虑存在告警信息畸变的情况,根据矩阵判据结果筛选可疑区段,并在此基础上构建最优化模型进行容错判断,有效实现高容错性故障定位,但其时效性有待提高。
针对上述研究现状,为了提高故障诊断效率和容错率,本文提出基于粗糙集算法的故障动作信息属性约简方法,筛选出有效信息;然后结合支持向量机(support vector machine,SVM)算法搭建一种新的故障诊断模型,对发生单次或多重故障时的故障线路或区域进行识别诊断;最后结合算例验证了该模型的准确性和时效性。
1 故障信息的现状与处理
1.1 故障信息的现状
配电网自动化的快速建设推动了智能监控设备在电力系统中的广泛应用,基于SCADA、故障信息系统的监测调度系统建设与优化促进了配电网智能化、数据化的发展[16-22]。配电网故障发生时采集到的故障信息近些年呈指数式增长,以山东省A市配电网为例,故障监测系统从2017年5月至2018年5月共收录到故障告警信号5 762 721条,在夏季用电高峰期(7月、8月),单月最高可收集845 343条告警信号。
故障告警信息中包括多种数据类型,其中夹杂着大量重复、无效的冗余数据,同时配电网的复杂结构也易导致同时出现多重故障的情况,造成故障告警信息更加复杂,也给调度人员快速诊断切除故障提出了难题。直接使用故障告警信息进行故障诊断,一方面数据量过于庞大,严重滞缓诊断时间和效率,另一方面冗余数据和不完备的动作信息会造成诊断结果不够精确,因此需要对故障告警信息先进行数据预处理[23-24]。
1.2 粗糙集理论
粗糙集(rough set,RS)理论作为一种处理不完备、不精确信息和模糊数集的人工智能数据分析方法,能够在保留关键属性数据的同时,根据属性重要度与依赖度进行规则提取,约简掉无用或价值较小的冗余数据,得出简化后的真实最小决策数据和决策规则。
在配电网故障诊断应用场景下,将所有故障发生时收集到的断路器、过流保护动作信息组成的非空有限集合称为一个论域,记为U;A×B的任意一子集称之为从集合A到集合B的一个数据二元关系,记为R,即R⊆A×B。
定义1:基于等价关系R的论域U,记为二元组K=(U,R)是关于论域U上的一个知识库,即数据集合之间的关系就是一种知识。
定义2:对于给定的知识库K=(U,R),若P⊆R,且P≠∅,则∩P仍然为论域U上的一个等价关系,称之为P上的不可分辨关系,记为IND(P),简记为P。依据这个不可分辨规则,可将论域U进行多个划分,记为U/IND(P),简记为U/P。
定义3:若给定一个知识库K=(U,R),且有任意子集X⊆U,等价关系R∈IND(K),则有:
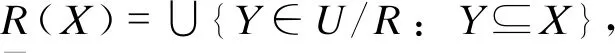
(1)

(2)

在故障原始决策表的约简中,若原始决策的任一子集Q∈P,且P⊆R,如果Q满足
IND(P-{Q})≠IND(P),
(3)
即P的核为P中所有满足上述条件Q的集合。故障信息约简中核属性作为属性约简分类计算的基础是不能被删除的。
1.3 属性依赖度和重要度

(4)
式中POS,B(D)为X的R正域。依赖度即为条件属性子集B所确定的正域集合在论域U中所占的比例。
在RS的决策系统中,属性重要度由各动作信号的原始条件属性对最终决策属性的影响程度决定。给定故障信息决策系统DS=(U,C∪D,V,f),∀B⊆C,若属性a∈B,则条件属性a对D的重要度
S(a,B,D)=γB(D)-γB-{a}(D),
(5)
即为从条件属性B集中删除属性a后,决策属性D对条件属性B依赖度减小的程度。
利用RS处理断路器和过流保护动作信号等大量离散型数据,实现对故障信息的属性约简,能够有效去除无效、重复的故障信息,减少故障诊断时间,有助于快速实现故障切除与供电恢复,保障配电网稳定可靠运行。
2 基于RS-SVM算法的故障诊断模型
2.1 SVM算法
SVM算法是一种基于最小化结构风险的机器统计学习理论,通过间隔最大化的学习策略,最终转化为一个凸二次规划问题的求解。最优分类超平面是指将数据正确分类的同时使得样本数据之间的分类间隔最大化的分类平面,其两边样本分为线性、非线性两种类别,图1为二维两类线性可分最优超平面示意图。
图1中,H1和H2分别为经过两类样本中离分类线H最近的样本且平行于H的直线,2/‖w‖为两类样本的分类间隔。n维空间中,线性可分样本集为(xi,yi),i=1,…,n,x∈Rd,y∈{1,-1},其中w为权重向量,xi为输入变量,yi为输出变量,b为阈值。其分类面方程为
F(x)=w·x+b=0.
(6)

图1 最优分类超平面示意图Fig.1 Schematic diagram of optimal classification hyperplane
最优分类面即使得‖w‖为最小值的分类面,SVM即为得到最优分类面的样本。在实际应用中,绝大多数样本分类问题是非线性不可分的,需要构建非线性SVM对非线性最优超平面进行求解,通过合适的非线性映射变换函数W,将输入样本映射到高维特征空间中,将样本数据转换为r维空间向量,则其最优分类超平面表达式为
(7)
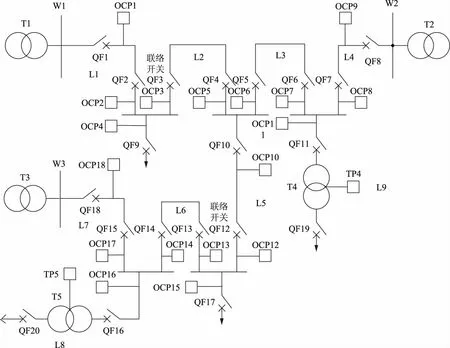
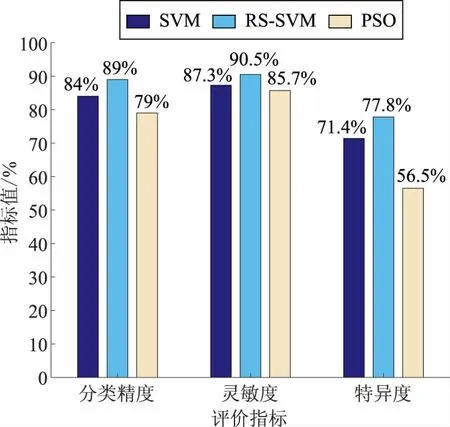
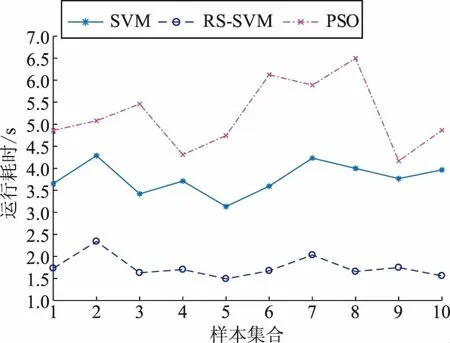
式中:λi^(i=1,2,…,t,且t SVM的核函数主要有4种类型:多项式函数、径向基核函数、线性核函数、Sigmoid核函数。本文采用径向基核函数进行内积运算,其对应的SVM判别函数为 (8) 式中σ为函数的宽度参数。 在该模型中引入惩罚参数c(c>0,也称之为正则化因子)和核函数W(xi·xj),则优化函数转化为 (9) 约束条件为 (10) (11) 式中:λ为Lagrange乘子;e为元素全为1的向量;Q为Hessian矩阵。 本文采用仿真软件平台编写了基于依赖度和重要度的RS属性约简算法,调用MATLAB中的Libsvm工具箱搭建SVM分类模型,实现了先进行数据约简处理,再完成分类诊断的混合故障诊断流程。基于RS-SVM算法的故障诊断具体步骤如下: a)根据SCADA系统采集到的故障信息,经过数据预处理初步筛选后,去除无用信息,保留所需的断路器、过流保护动作信息。 b)对所研究网络中线路、母线以及各断路器、过流保护元件所属拓扑结构和连接关系进行分析,建立原始故障信息决策表:设定条件属性集C={开断路器、过流保护是否动作的1/0逻辑数据};决策属性集D={所研究可能出现故障的线路或区域信息数据};其中各元件动作或出现故障标记为“1”,未动作或未出现故障标记为“0”,信息不完备或信号丢失情况记为“*”,所研究可能故障线路或区域未出现故障记为“NO”。 c)对形成的原始决策表进行依赖度和重要度计算,删除决策表中冗余的属性项或列,并对决策核值进行约简,求得最小约简决策规则,生成约简后的故障信息决策表。 d)利用约简后的决策表作为SVM模型的输入量,对SVM模型进行训练学习,将训练所用样本进行返回测试正确率,直至完成训练学习。 e)将故障测试样本数据输入基于RS-SVM算法的故障诊断模型中,输出量y为故障元件或线路是否发生故障,y取值范围为[-1,1],y=-1表示元件或线路正常,y=1表示元件发生故障,输出判别精度与y值的接近度成正比。 基于RS-SVM算法的故障诊断流程如图2所示。 本文以A市某区域10 kV配电网三端口环网结构(图3)为基础进行算例仿真分析。图3中包括母线(W)3条,变压器(T)5台,变压器保护(TP)2台,断路器(QF)20台,过流保护(OCP)18台,配电线路及区域(L)9个,其中QF3和QF12为联络断路器。 结合配电网拓扑结构和各元件、设备连接关系,假设所研究可能出现故障的各设备、区域出现单次或多重故障。同时针对实际出现误动、拒动、设备元件损坏等信息不完备情况,分为100个单次故障样本和50个多重故障样本,装填各断路器、过流保护动作信息和故障区域信息形成原始决策表(其中*表示信息不完备情况)。共包含动作量数据6 150个,其中不完备数据979个,占比15.9%。每15个样本作为1组样本集合(共10组),每组中随机抽选5个样本作为测试样本,其余10个作为训练样本。 图2 基于RS-SVM算法的故障诊断流程Fig.2 Fault diagnosis process based on RS-SVM 首先,利用本文中的RS属性约简算法进行属性约简,输出约简后的最小决策表,由于篇幅限制,仅展示其中2组样本(x1—x10为单次故障样本;x11—x20为多重故障样本)集合共计20个样本数据约简前后决策表,见表1、表2。 分析表1、表2可知,原始决策表中共有条件属性集40个,20个样本中共包含820个原始决策数据。经RS属性约简后,得到原始决策表的最小决策属性为{OCP1, OCP2, OCP4, OCP5, OCP7, OCP9,OCP11,OCP12,OCP13,OCP16,OCP17,OCP18,TP5},其余均为冗余属性,约简规则即为该最小决策属性中每个样本所对应的各设备动作数据集合。RS属性约简后的决策表共包含390个决策数据,平均约简率为52.44%,显著降低了配电网故障诊断的有效数据量。 对这10组样本集合分别进行属性约简,单次和多重故障的约简率曲线如图4所示。 分析图4可知,这10组训练样本中单次故障样本集合的数据约简率为54%~72%,多重故障样本集合约简率相对较低,为48%~59%,这主要是因为多重故障情况时断路器、过流保护动作更多、更复杂。 图3 配电网环网结构Fig.3 Looped network structure of distribution network 样本QF1QF2QF3QF4QF5…QF9OCP1OCP2OCP3OCP4OCP5…OCP18TP4TP5故障x1100*00100*0000W1x211000011*00000L1x3*01100*0101000L2x40*000000000000L5x500*00000*00000L6x60000*00000*100W3…x17001*1*00101000L2、L3x18110000110*0000L1、L5x190000000*00*101L7、L8x2000000000000000NO 表2 RS属性约简后决策表Tab.2 Decision-making table after attribute reduction of rough set 图4 10组样本约简率曲线Fig.4 Reduction rate curves of 10 groups of samples 将约简后的训练样本集合决策表数据作为输入量,训练SVM模型,并对随机抽取组成的10组测试样本集合分别进行测试。为验证所提出的基于RS-SVM算法的故障诊断模型的诊断精度,本文引入基于数据混淆矩阵的二分类效果评价指标。假设数据集中有2个分类,分别为正类(Positive)和负类(Negative),正类代表诊断元件或设备出现故障,负类代表诊断元件或设备未出现故障。TP和FP分别为正确分类和错误分类的正类样本数量,TN和FN分别为正确分类和错误分类的负类样本数量,见表3。 表3 二分类数据的混淆矩阵Tab.3 Confusion matrix of binary data 针对SVM二分类模型分类精度评价指标定义如下: a)分类精度 (12) b)灵敏度表示正类的分类精度,其值为 (13) c)特异度表示负类的分类精度,其值为 (14) 分类精度、灵敏度、特异度指标分别用来衡量测试数据的总体、正类样本、负类样本的分类精度。通常认为,精度越高,分类效果越好。基于相同算例引入粒子群优化(particle swarm optimization,PSO)算法进行故障诊断,并与SVM算法、RS-SVM算法进行对比分析,结果如图5、6、7所示。 图5 单次故障分类精度对比Fig.5 Comparison of classification accuracy of single faults 图6 多重故障分类精度对比Fig.6 Comparison of classification accuracy of multiple faults 由图5可知,RS-SVM算法故障诊断模型的分类精度指标达到92%,高出SVM算法12%,高出PSO算法14%;灵敏度指标对比,RS-SVM算法高出近10%;特异度指标对比,RS-SVM算法的优势更加明显。多重故障情况下RS-SVM算法分类精度相较于单次故障时稍低,但整体对比SVM算法以及PSO算法呈现出同样优势。因此,基于RS-SVM算法的故障诊断模型在处理包括大量信号丢失、设备元件损坏等不完备信息的故障诊断问题时,能够明显提高系统的容错性,其故障诊断结果明显优于SVM算法和PSO算法。 图7 运行耗时对比Fig.7 Comparison of running time 由图7可知,RS-SVM算法运行耗时远远低于SVM算法与PSO算法,主要原因是经RS属性约简后的样本数据量平均减少近60%,显著缩减了训练和诊断时间,提高了故障诊断的时效性。 针对目前配电网故障诊断中存在大量信号丢失,设备元件误动、拒动、损坏等信息不完备的情况,本文提出一种基于RS-SVM算法的故障诊断技术,能够高效、准确地进行单次或多重故障诊断。利用RS在知识空间表达上的属性约简优势,在保留最小决策数据的同时,基于依赖度和重要度计算求得知识的最小表达,缩减了决策数据量,提高了故障诊断的效率。结合SVM搭建故障诊断模型,有效地解决了针对不完备信息情况下的单次和多重故障诊断精度问题,同时还具有更好的时效性。算例仿真引入二分类评价指标,与SVM算法、PSO算法对比,分析RS-SVM算法的准确性和时效性,验证了本文所提出的故障诊断技术的可行性。2.2 基于RS-SVM算法的故障诊断流程
3 算例分析






4 结束语
猜你喜欢
舰船电子工程(2022年4期)2022-05-11
四川师范大学学报(自然科学版)(2021年6期)2021-11-15
计算机工程与应用(2020年12期)2020-06-18
成都信息工程大学学报(2019年2期)2019-08-28
电子制作(2018年8期)2018-06-26
自动化学报(2018年2期)2018-04-12
智能系统学报(2017年3期)2017-08-01
计算机与数字工程(2016年11期)2016-12-13
电测与仪表(2016年5期)2016-04-22
河南电力(2016年5期)2016-02-06
