
基于声谱图纹理特征的蛋鸡发声分类识别
2019-10-10 02:45:28杜晓冬滕光辉TOMASNorton王朝元刘慕霖
农业机械学报 2019年9期
杜晓冬 滕光辉 TOMAS Norton 王朝元 刘慕霖
(1.中国农业大学水利与土木工程学院, 北京 100083; 2.鲁汶大学生物科学工程学院, 鲁汶 3001)
0 引言
畜禽动物的发声可以反映其个体的健康状况以及个体需求,可作为评价动物福利、动物舒适度的一种辅助方法[1-2]。国内外学者对畜禽动物发声进行了一系列研究,例如:羊咳嗽声监测[3]、羊采食声音识别[4-5]、蛋鸡发声检测和分类识别[6-8]、肉鸡啄食声监测[9-11]、牛呼吸道疾病监测[12-13]、猪咳嗽声监测[14-16]等研究。
动物声音特征的选取大多是沿用传统语音信号处理的方法,例如:对声音信号分帧、加窗,提取每帧信号的特征值(持续时间、共振峰、功率谱估计、能量谱包络、线性预测倒谱系数等特征参数)。除上述传统方法之外,基于声谱图的声音分类识别方法是近年来研究热点之一。声谱图可以将声音的一维特征序列转变为二维特征序列来可视化地呈现,相比于传统方法而言,它可以同时体现声音信号的时域和频域内容,直观性强,且能保留声音信号的更多细节信息。动物发声分类识别本质是辨识不同类型声音的音色特点,而音色本身是一种主观感受,目前尚未有对应的客观指标[17]。美国国家标准学会针对音色的定义给出了解释,认为音色与频谱形状和时域特征均有重要关系[18]。据观察,蛋鸡发声声谱图的时频结构在方向和局部细微程度上有显著的不同。此外,养殖环境中存在的背景噪声大多为机械噪声,其声谱图的时频结构变化单一,声谱图中声纹分布较均匀。
本文拟将图像处理和声音处理技术相结合,对蛋鸡声音中的时域和频域信息进行可视化,进而分析其声谱图中所呈现的声纹特征,来实现海兰褐蛋鸡发声的分类识别,并为后期研究蛋鸡福利的评价系统提供理论基础和可行方案。
1 声音信号处理方法
1.1 声谱图
声音信号有着类似指纹的属性,1962年,美国Bell实验室首次提出了“声纹”(Voiceprint)的概念,利用语谱图,验证了以语音识别说话人的可行性,且声纹具备稳定性和特异性[19]。声纹是表现在声谱图中各种纹路构成的时频结构。声谱图是描述声音信号的一种三维感知图,由时间、幅值和频率3个维度信息构成,信号中不同频率分量大小(振幅或功率)在图像中一般用不同灰度和颜色来表示,声音信号的不同频率分量在任一给定时刻用声谱图中的不同灰度和颜色来表示。
对于经过预处理的蛋鸡声音信号从时域波形转换到时频域的声谱图时,需要对声音信号进行短时傅里叶变换(Short-time Fourier transform, STFT),算法借鉴Matlab软件中的Spectrogram函数[20]。此外,为了减少边缘效应和频谱泄漏,需要为测量的声音信号增加滑动窗,本文选取汉明窗(Hamming)进行分帧,帧长为512个采样点,滑动窗步长为256个采样点,相邻帧之间的重叠率为50%[6]。
1.2 纹理特征
Gabor函数可以在时域和频域获取信号的最佳局部信息,多用于图像纹理识别研究。图像中纹理是其灰度或色彩在空间上的变化或重复,声谱图中声纹的纹理特征可以借鉴Gabor滤波器来提取[21]。多尺度、多方向的2D-Gabor特征描述得到越来越多的关注,同时,Gabor特征在指纹识别、人脸识别等研究中已经得到了广泛应用[22-23]。本研究选用2D-Gabor滤波器对蛋鸡发声的声谱图中声纹特征进行提取,Gabor函数调用Matlab软件扩展函数库中的gaborKernel2d函数,并在原函数基础上进行二次开发,将其嵌入LabVIEW声谱图功能模块中进行特征分析[24]。gaborKernel2d函数参数计算公式为
(1)
x′=xcosθ+ysinθ
(2)
y′=-xsinθ+ycosθ
(3)
(4)
(5)
式中λ——余弦函数的波长,λ>2
δ——核函数中高斯函数的标准差
b——半响应空间频率带宽
θ——核函数中平行条带方向,0°<θ<360°
φ——余弦函数的相位角,-180°<φ<180°
γ——核函数的椭圆度
x、y——图像像素点的坐标值
本文研究选取的各参数值为theta(θ)=[0 π/4 π/2 3π/4],lambda(λ)=4,phi(φ)=0,gamma(γ)=1,bandwidth(b)=[0.5 0.75 1 1.25],生成的相应2D-Gabor滤波器如图1所示。

图1 2D-Gabor滤波器模板Fig.1 2D-Gabor filter template
1.3 分类模型
采用反向传播神经网络(Back propagation neural network,BPNN)建立特征输入的分类识别模型,选取各类别的声音样本片段合计1 500个,每个片段时长截取为1 s,统一声谱图的尺寸(628像素×371像素),其中随机选取50%的样本片段作为训练集建立分类模型,其余50%的样本片段作为测试集,用于验证该模型的识别率。
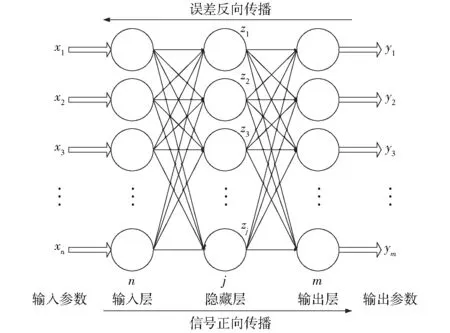
图2 反向传播神经网络示意图Fig.2 Schematic of BPNN
图2所示的神经网络结构主要由3部分组成:①输入层,提取特征创建输入向量,输入至输入层。②隐藏层,根据经验预先设定隐藏层的数目,通常由试验和误差决定,并进一步对具体问题进行优化。③输出层,输出训练集中设定的不同类别。
BPNN算法的基本原理是:学习过程由两个步骤组成,即信号正向传播和误差反向传播。当信号正向传播时,输入样本通过输入层传递至网络中,经过每个隐藏层后传输到输出层。如果实际输出与预期的输出不匹配,则进入误差反向传播阶段。反向传播时,将输出以某种形式通过隐藏层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。误差函数的定义是期望输出和实际输出之差的平方和,计算公式为[25]
(6)
式中e——误差函数
yp——实际输出参数值
qp——期望输出参数值
p——输出向量的索引值
m——输出向量的数量
训练数据集用来优化分类,使预测分类和真实类别之间的误差最小化。采用梯度下降函数和自适应学习速率对权重进行调整[26]。本文设置最大迭代次数为1 000和最小步长为0.001。
1.4 评价方法
蛋鸡发声分类识别性能采用灵敏度S(Sensitivity)和精确度P(Precision)两个指标来评价,计算公式为[12]
(7)
(8)
式中TP——被模型预测为正的正样本数
FP——被模型预测为正的负样本数
FN——被模型预测为负的负样本数
2 试验设计
试验于2016年10—11月,在中国农业大学上庄实验站模拟鸡舍进行。研究对象为六羽海兰褐蛋鸡,35~36周龄,饲养模式为网上平养,饲养空间为1.50 m(长)×1.35 m(宽)×1.80 m(高)。试验平台如图3所示,包括饮水线、产蛋箱以及料槽等,鸡只随意采食和饮水,光周期由光照控制器控制。试验阶段光期为06:00—22:00,模拟鸡舍的环境温度处于15.0~18.0℃之间。
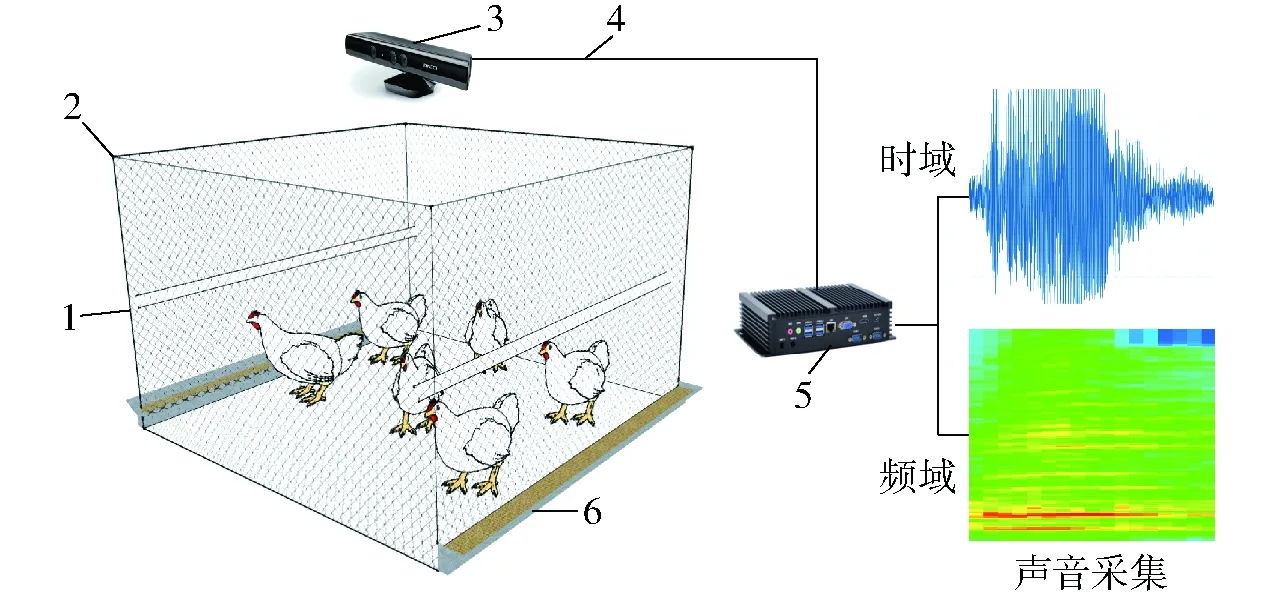
图3 试验平台示意图Fig.3 Schematic of test platform1.饮水线 2.尼龙网 3.Kinect设备 4.USB数据线 5.工控机 6.料槽
声音数据采集平台选用美国微软公司的Kinect for Windows V1型嵌入式麦克风阵列(4通道同步采集、32位分辨率、16 kS/s采样频率),Kinect设备安装在饲养区域正上方高1.8 m处,录音软件采用美国国家仪器公司(National Instruments, NI)的LabVIEW 虚拟仪器平台进行编写,利用LabVIEW 2015软件中的扩展声音工具包模块(Sound and vibration toolkit 2015, SVM)和Kinect for Windows SDK 1.8编写音频采集程序,单声道音频连续采样,采样频率为16 kHz,32位,单个音频文件时长为55 s,数据以.wav格式存储,连续采集音频片段合计308 h(约67.68 GB)。Kinect设备是通过USB数据线与小型工控机进行数据传输,大量数据存储需外接2 TB USB 3.0移动硬盘。各类型声音采用人工方式进行标记,标记方法参照文献[12],音频数据利用LabVIEW软件提供的声音与振动工具包(SVM toolkit)、高级信号处理工具包(Advanced signal processing toolkit 2015, ASP)进行声音信号预处理、特征提取和分类识别。
3 试验结果分析
基于声谱图纹理特征检测海兰褐蛋鸡发声,表1和图4分别描述了不同声音类型的定义及其对应声谱图,从声谱图中可直观地看出各声音类型的特点和不同声音之间的差异。

表1 不同类型声音的定义Tab.1 Definition of different types of sound
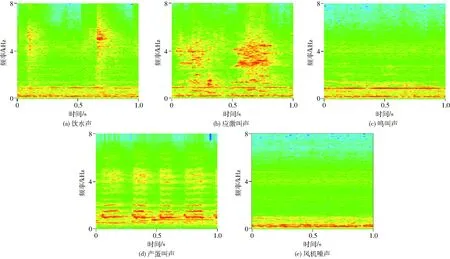
图4 各类型声音的声谱图Fig.4 Spectrogram of different types of sound
蛋鸡饮水声在声谱图上清晰可见,呈现能量较强的冲直纹,具有瞬时峰值高、持续时间短的特点,且能量集中在前半部分,后半部分能量快速衰减(图4a);应激叫声在声谱图上也清晰可见,呈现出较不规则的横纹结构,具有较强的能量值,持续时间长,且能量在频率带中分布较均匀(图4b);鸣叫声在声谱图上较不清晰,呈现出能量较弱的条纹结构,持续时间长,不易在背景噪声中辨别出来(图4c);产蛋叫声在声谱图上清晰可见,呈现出有规律的周期性水平横纹,能量集中在低频部分,持续时间短(图4d);风机噪声在声谱图上清晰可见,呈现出规则的横纹结构,较强的能量集中在风机振动的基频部分,即低频部分,持续时间最长(图4e)。图5呈现了声谱图经2D-Gabor滤波器滤波后的各类型声音的声纹特点,选取theta(θ)=π/2时清晰的纹理特征图,对特征图像中各行像素求平均值和归一化处理,最终获得371维特征向量,作为单个声音样本的特征输入参数。

图5 各类型声音的纹理特征图Fig.5 Textual maps of different types of sound
不同声音类型的分类识别结果见表2,风机噪声的灵敏度最高,为99.3%,鸣叫声的灵敏度最低,为76.0%,分析原因可能是机械噪声的振动发声机理与动物发声机理相比有较大差异,且前者声谱图中声纹变化单一,比较容易区分[27]。在机器学习中尤其是统计分类中,混淆矩阵(Confusion matrix,也称为错误矩阵(Error matrix))对角线位置数值为TP声音样本数量,矩阵的每一列表示BPNN分类器对于声音样本的类别预测(对角线之外的数值为FP声音样本数量),每一行则表示声音样本的真实类别(对角线之外的数值为FN声音样本数量),从表3的混淆矩阵来看,33个鸣叫声被错误地分类成应激叫声,导致应激叫声和鸣叫声的灵敏度较低,分析原因可能是同这两类声音的界定和标记音频时人为的主观判断有一定关联。此外,产蛋叫声、风机噪声和饮水声的精确度较高,分别为98.6%、98.7%和97.4%,而应激叫声和鸣叫声的精确度较低,分别为78.9%和87.7%,导致该分类结果的原因可能是产蛋叫声、风机噪声和饮水声同其他类型声音的界定清晰,较容易实现快速、准确的音频标记;而应激叫声和鸣叫声则不容易实现准确的人工标记操作,部分鸣叫声和应激叫声之间存在混淆。
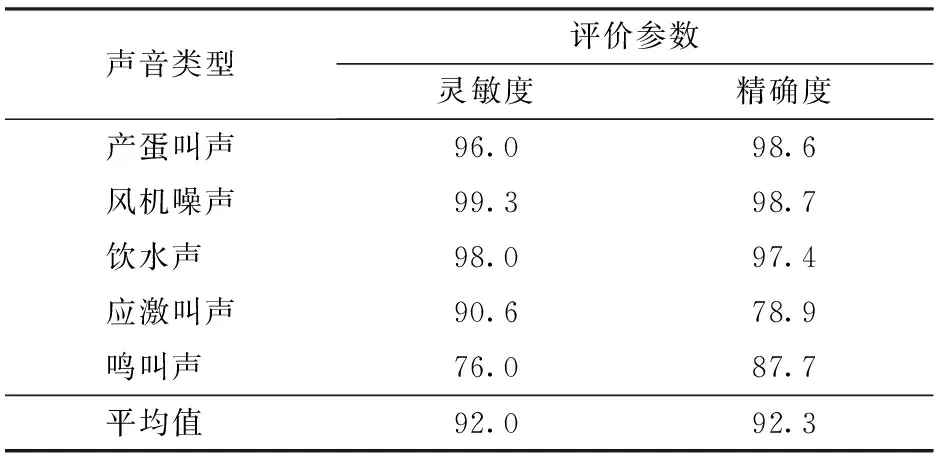
表2 不同声音类型的分类结果Tab.2 Classification result of different types of sound %
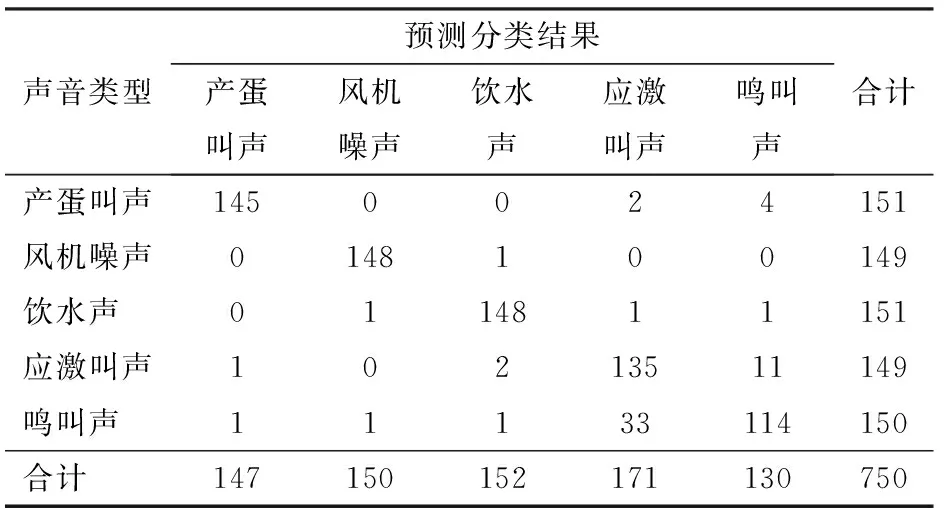
表3 不同声音类型的分类混淆矩阵Tab.3 Confusion matrix of different types of sound
结果表明,本文的方法可用于蛋鸡发声分类识别研究,且具有较高的分类识别率,平均灵敏度可达92.0%,平均精确度可达92.3%。与国内外学者研究动物发声识别结果相比具有较高的识别率,其他研究方法识别率为73%~98%[28]、66%~98%[29]、89.1%~92.5%[30]、84%[31]、41.4%~94.2%[12]。此外,神经网络模型隐藏层的个数是影响识别准确率的关键因素,然而,理论上估计隐藏层数相当困难,往往根据算法多次的参数优化再确定,本文采用的隐藏层为5个[26]。
4 结束语
提出一种基于声谱图纹理特征检测蛋鸡发声的方法,将图像处理和声音处理技术相结合,将蛋鸡声音中的时域和频域信息进行可视化,进而分析其声谱图中所呈现的声纹特征,利用2D-Gabor滤波器提取声谱图中纹理特征进行分类识别,平均灵敏度和平均精确度不低于92.0%;风机噪声识别灵敏度最高,为99.3%;鸣叫声识别灵敏度最低,为76.0%。该方法具有可视化、非侵入式等优点,在动物行为、动物福利评价研究方面具有很大的潜力。
猜你喜欢
都市(2023年9期)2023-12-16 12:34:55
软件(2020年3期)2020-04-20 01:45:18
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:00
通信产业报(2018年32期)2018-11-24 10:37:58
百科知识(2017年17期)2017-09-25 00:00:24
Coco薇(2017年8期)2017-08-03 15:23:38
青春(2017年5期)2017-05-22 11:58:11
Coco薇(2015年5期)2016-03-29 23:22:15
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:11
祝您健康(2009年4期)2009-04-08 09:36:06
