
基于GLU-CNN和Attention-BiLSTM的神经网络情感倾向性分析
2019-10-08 08:34孙承爱丁宇田刚
软件 2019年7期
关键词:情感分析
孙承爱 丁宇 田刚
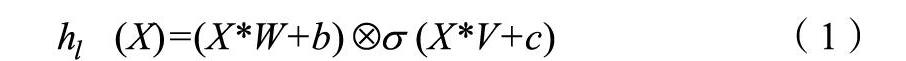

摘 要: 情感分析是自然语言处理领域(NLP)中重要的语义处理任务,目前处理NLP任务的两大主流模型是卷积神经网络(CNN)和循环神经网络(RNN)以及他们的变体。由于自然语言在结构上存在依赖关系,且重要信息可能出现在句子的任何位置。RNN可能会忽略为了解决这些问题,我们提出了一种新的模型ABGC,将Attention机制加入到BiLSTM中,可以更好捕获句子中最重要的局部信息,同时融合添加GLU(非线性单元)的卷积神经网络(CNN),可以更好捕捉文本的全局信息,然后将两种模型提取到的特征融合,既有效避免了LSTM的梯度消失问题,又解决了CNN忽略上下文语义的问题。我们在两种数据集上进行对比实验,实验结果表明ABGC模型可以有效提高文本分类准确率,同时减少运行时间。
关键词: Attention;BiLSTM;GLU;CNN;情感分析
中图分类号: TP391.1 文献标识码: A DOI:10.3969/j.issn.1003-6970.2019.07.011
【Abstract】: Sentiment analysis is an important semantic processing task in the field of natural language processing (NLP), The two mainstream models currently dealing with NLP tasks are Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN) and their variants. Because natural language has structural dependencies, important information may appear anywhere in the sentence. RNN may ignore these informations. In order to solve these problems, We propose a new model ABGC, the model adds the Attention mechanism to BiLSTM, which can capture the most important local information in the sentence better, and fuse the convolutional neural network (CNN) with GLU (non-linear unit). It is good to capture the global information of the text, and then fuse the features extracted by the two models, which not only avoids the LSTM gradient disappearance problem, but also solves the problem that CNN ignores the context semantics. We conducted comparative experiments on two data sets. The experimental results show that the ABGC model can effectively improve the accuracy of text classification and reduce the running time.
【Key words】: Attention; BiLSTM; GLU; CNN; Sentiment analysis
0 引言
情感分析或意見挖掘[1]是对人们的观点、情感,对产品、服务等的评价、态度等的计算研究。近些年来,情感分析已成为自然语言处理(NLP)中最活跃的研究领域之一。情感分析可以被视为一种利用一些情感得分指标来量化定性数据的方法。尽管情绪在很大程度上是主观的,但是情感量化分析[2]可以有很多有用的实践,比如企业分析消费者对 产品的反馈信息,或者检测在线评论中的差评信 息等。
现阶段关于情感分析方法主要有两类:
(1)基于词典的方法[3];基于词典的方法主要通过制定一系列的情感词典和规则,对文本进行拆句、分析及匹配词典(一般有词性分析,句法依存分析),计算情感值,最后通过计算情感值来作为文本的情感倾向判断的依据。如果是对篇章或者段落级别的情感分析任务,按照具体的情况,可以以对每个句子进行单一情感分析并融合的形式进行,也可以先抽取情感主题句后进行句子情感分析,得到最终情感分析结果。
(2)基于机器学习[4]的方法;情感词典准确率高,但存在召回率比较低的情况。对于不同的领域,构建情感词典的难度是不一样的,精准构建成本较高。另外一种解决情感分析的思路是使用机器学习的方法,将情感分析作为一个有监督的分类问题。对于情感极性的判断,将目标情感分为三类:正面、中性、负面。对训练文本进行人工标注,然后进行有监督的机器学习过程,并对测试数据用模型来预测结果。
近些年,神经网络[5]已被证明优于经典的n-gram语言模型[6]。这些经典模型存在数据稀疏性,难以表示长文本的上下文,从而产生长期的依赖关系。而神经语言模型通过在神经网络的连续空间中应用词嵌入解决了这一问题,LSTM将门控机制引入RNN[7],使RNN能在细胞状态中添加或删除信息。门控机制通常包括已经通过sigmoid激活单元(生成门控权重)的网络层和乘法运算。门控权重(通常在区间[0,1]内的值(其中0和1分别表示完全丢弃和保留)分别限制了可以通过门的信息量。通过精心设计的门控机制,LSTM可以学习更长距离的依赖性并有效地缓解梯度消失或爆炸问题。但是单向的LSTM往往无法编码从后到前的信息。双向LSTM(BiLSTM)[8]解决了这一问题。本文在BiLSTM基础上引入Attention注意力机制,对相关词给予更大的权重,更好捕捉了文本的局部信息,同时本文中我们还引入了新的门控卷积网络并将其应用于语言模型,可以通过堆叠卷积网络以表示长文本的上下文信息,并在具有更多抽象特征的长文本的上下文中提取分层特征(LeCun和Bengio,1995),引入GLU的CNN可以更好处理文本的全局信息。
1 门控卷积神经网络(GLU)
随着词向量[9]的发展,word2vec,Glove等现有词向量库已经能较好的表达词语的含义。因此,我们用n维词向量就可以度量词语之间的距离。
首先我们可以通过堆叠cnn来识别长文本[10],提取更高层、更抽象的特征,而且相比于LSTM而言,所需要的op更少。(CNN需要O(N/k)个op,而LSTM将文本视为序列需要O(N)个op,其中N为文本长度,k为卷积核宽度)这样可以减少非线性操作,有效降低梯度弥散,使模型收敛和训练更加简单,而本文使用的线性门控单元不仅可以有效降低梯度弥散,还可以保留模型的非线性能力。与RNN相比,模型构建了输入单词的分层表示,使得更容易捕获远程依赖。
如图,我们在卷积层[11]引入门控机制,将卷积层的输出变成了下面的公式(1),该模型为每个单词 ,…, 生成上下文的表示h=[ ,…, ],以预测下个单词P( | )。LSTM通过由输入门和忘记门控制的单元实现长期记忆,相比之下,CNN不会出现如此严重的梯度消失的情况,我们通过实验发现他们不需要忘记门,因此我们的模型只有输出门来控制允许通过的信息。这种门控机制允许模型选择哪些单词或特征与预测下一个单词相关。函数f对输入进行卷积以获得H=f*w,因此没有时间依赖性,更容易与句子里的单个单词进行并行化计算。该过程将根据多个先前单词计算每个上下文。图3说明了模型架构,单词由存储在查找表 的矢量嵌入表示,其中|V|是词汇表中的单词数,e是词嵌入大小。我们模型输入的是一系列单词 ,…, ,由词嵌入E=[ ,…, ]表示。我们通过公式(1)计算隐藏层 ,…,
其中m,n分别是输入和输出的个数,k是卷积核大小,X 是 层的输入(字嵌入或前一层的输出),W ,b ,V ,c 是学习参数, 是sigmoid函数, 是矩阵间的元素点积。我们对序列进行零填充[12],每层的输出是一个线性投影X*W+b,由门 (X*V+c)控制在层中传递的信息。经过门控选择过的信息传入到全连接层。下图为GLU-CNN的模型图。
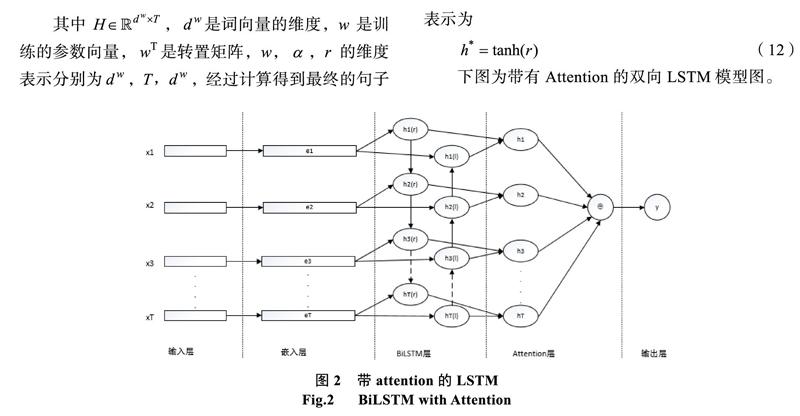
2 Bilstm+Attention
2.1 BiLSTM
LSTM的全称是Long Short-Term Memory,它是RNN的一种。LSTM由于其设计的特点,非常适合用于对时序数据的建模[13],如文本数据。情感分析任务中,将词的表示组合成句子的表示,可以采用相加的方法,即将所有词的表示进行加和,或者取平均等方法,但是这些方法没有考虑到词语在句子中的前后顺序。使用LSTM模型可以更好捕捉到较长距离的依赖關系,因为LSTM通过训练过程可以学到记忆哪些信息和遗忘哪些信息;但是利用LSTM对句子进行建模还存在一个问题:无法编码从后到前的信息。BiLSTM是Bi-directional Long Short-Term Memory的缩写,是由前向的LSTM和后项的LSTM结合而成,两者在自然语言处理任务中都常被用来建模上下文信息。在更细粒度[14]的分类时,更需要注意词语之间的交互,通过BiLSTM可以更好地捕捉双向的语义依赖。
2.3 本文特征融合模型
如图3所示,本文模型ABGC由ATT-BiLSTM和GLU-CNN融合而成,卷积神经网络部分第一层是词嵌入层,嵌入层的句子矩阵作为卷积网络的输入,矩阵的列为词向量的维度,矩阵的行为句子长度。将词向量维度设为100维时,滤波器为3*100,4*100,5*100会取得较好的分类效果[16],本文选用3*100,4*100,5*100的大小滤波器各128个,步长stride大小设为1,进行卷积运算。卷积层的输出经过GLU后提取到文本的关键特征,然后经过Max-pooling层后生成固定维度的特征向量[17],将3个池化操作输出的特征拼接起来,作为第一层全连接层输入的一部分。
BiLSTM部分将嵌入层的句子矩阵作为输入,词向量维度设为100,隐藏层大小设为128,将输入序列分别从两个方向输入模型,经过隐藏层收集两个方向的历史信息和未来信息,然后将两个隐藏层输出部分拼接,得到最后BiLSTM的输出。最后将BiLSTM和CNN的输出进行特征融合。
3 实验分析
3.1 情感分析数据集与模型参数
实验在SEMEval-2010 Task 8数据集(Hendrickx等,2009)和Google Billion Word数据集上进行。SEMEval-2010 Task 8数据集包含9个关系(具有两个方向)和一个无向其他类,有10717个带注释的示例,其中包括8000个用于训练的句子,以及2717个用于测试的句子。我们采用官方评估指标来评估我们的系统,系统是基于9个实体关系的各类别平均F1分数,并考虑了方向性。我们的模型使用了Adadata(Zeiler,2012)进行了训练,学习率为1.0,最小batch为10,模型参数采用 的L2正则化强度进行正则化[18]。经实验验证dropout为0.5时,模型具有较好的性能,模型中的其他参数都是随机初始化。CNN部分我们使用的数据预处理步骤与Kim[19]一致,我们将此模型与6个基线模型进行了比较,并对模型的表现进行了评估:
(1)基于LSTM的模型,如ATT-BLSTM、CNN- BLSTM[20]
(2)基于CNN的模型:如DCNN、CL-CNN、G-CNN
3.2 对比实验与结果分析
我们的模型在Google Billion Word测试集和SemEval-2010 Task 8测试集上与其他几个基线模型相比准确率均得到了提升。
如表2,在运行时间方面,我们的模型也有较好效果。
4 结论
本文提出了一种新的神经网络ABGC用于情感分析,我们的模型利用双向长短期记忆网络(BiLSTM)的神经网络注意力机制可以自动关注对分类具有决定性作用的词,并给予更高的权重,从而可以捕获句子中重要的语义信息,同时网络的另一部分由带有非线性单元(GLU)的卷积神经网络(CNN)组成,CNN可以更好地捕获全局信息,有效降低梯度弥散,同时还可以保留模型的非线性能力,模型运行时间还需要进一步提升。
参考文献
[1] Sangvikar P C. A Survey on Sentiment Analysis and Opinion Mining[J]. Multimedia Tools & Applications, 2018, 5(4): 1-29.
[2] Cambria E, Poria S, Gelbukh A, et al. Sentiment Analysis Is a Big Suitcase[J]. IEEE Intelligent Systems, 2017, 32(6): 74-80.
[3] Hatzivassiloglou V, Mckeown K. Predicting the Semantic Orientation of Adjectives. [J]. Proceedings of the Acl, 1997: 174-181.
[4] Boiy E, Moens M F. A machine learning approach to sentiment analysis in multilingual Web texts[J]. Information Retrieval, 2009, 12(5): 526-558.
[5] Krizhevsky A, Sutskever I, Hinton G. ImageNet Classi-fication with Deep Convolutional Neural Networks[C]// NIPS. Curran Associates Inc. 2012.
[6] Kneser R, Ney H. Improved backing-off for M-gram lan-guage modeling[C]//icassp. IEEE Computer Society, 1995.
[7] Gers F A, Schmidhuber, Jürgen, Cummins F. Learning to Forget: Continual Prediction with LSTM[J]. Neural Com-putation, 2000, 12(10): 2451-2471.
[8] Wigington C, Stewart S, Davis B, et al. Data Augmentation for Recognition of Handwritten Words and Lines Using a CNN-LSTM Network[C]//2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). IEEE Computer Society, 2017.
[9] Chen M, Wang S, Liang P P, et al. Multimodal Sentiment Analysis with Word-Level Fusion and Reinforcement Lear-ning[J]. 2018.
[10] Kalchbrenner N, Grefenstette E, Blunsom P. A Convolutional Neural Network for Modelling Sentences[J]. Eprint Arxiv, 2014, 1.
[11] Dauphin Y N, Fan A, Auli M, et al. Language Modeling with Gated Convolutional Networks[J]. 2016.
[12] Graham B. Spatially-sparse convolutional neural networks[J]. Computer Science, 2014, 34(6): 864-867.
[13] Liu Y, Ji L, Huang R, et al. An Attention-Gated Convo-lutional Neural Network for Sentence Classification[J]. 2018.
[14] Kim Y, Jernite Y, Sontag D, et al. Character-Aware Neural Language Models[J]. Computer Science, 2015.
[15] Gers F A, Schmidhuber E. LSTM recurrent networks learn simple context-free and context-sensitive languages[J]. IEEE Transactions on Neural Networks, 2001, 12(6): 1333-1340.
[16] Chen T, Xu R, He Y, et al. Improving sentiment analysis via sentence type classification using BiLSTM-CRF and CNN[J]. Expert Systems with Applications, 2016: S0957417416?305929.
[17] Yin W, Schütze H, Xiang B, et al. ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs[J]. Computer Science, 2015.
[18] Qian Q, Huang M, Lei J, et al. Linguistically Regularized LSTMs for Sentiment Classification[J]. 2016.
[19] Kim Y. Convolutional Neural Networks for Sentence Classification[J]. Eprint Arxiv, 2014.
[20] 李洋, 董紅斌. 基于CNN和BiLSTM网络特征融合的文本情感分析[J]. 计算机应用, 2018, 38(11): 29-34.
