
大数据时代数字资源整合方法研究:模型设计和实验分析
2019-10-06 02:40王战平冯扬文朱宸良
现代情报 2019年9期
王战平 冯扬文 朱宸良


摘 要:[目的/意义]针对目前大数据时代数字资源的非结构化、海量、多类型等问题,设计一套数字资源整合的模型和方法,以满足信息用户的实际需求。[方法/过程]以物流行业中的航运信息服务产品集装箱运价指数为例,提出基于大数据的指数编制思路,以数据仓库模型为目标数据模式,构建面向海量多源异构信息的数字资源集成模型,设计Web类数字资源获取和集成流程以及增量数据的处理方法,通过具体实证研究检验模型和流程的运行效果。[结果/结论]实证结果显示,本文提出的数字资源整合模型和处理流程能有效地实现多源异构数字资源的整合,支持基于海量數据对的指数编制模式,为全世界各类指数编制的改变提供理论和技术方面的探索,也为数字资源整合在其他领域的应用提供有益参考。
关键词:数字资源整合;多源异构信息;集装箱运价指数;数据仓库;模型;方法;技术;物流行业
DOI:10.3969/j.issn.1008-0821.2019.09.010
〔中图分类号〕G203 〔文献标识码〕A 〔文章编号〕1008-0821(2019)09-0092-09
Abstract:[Purpose/Significance]Aiming at the unstructured,massive and multi-source of digital resources,a set of digital resource integration models and methods were designed to meet the actual needs of information users.[Method/Process]Taking the shipping information service product - container freight index in the logistics industry as an example,this paper proposed formulation methods of container freight index based on big data,designed a set of oriented container freight index multi-sources heterogeneous information integration model and the Web information gathering and integration process.[Result/Conclusion]The model and process supported multi-sources heterogeneous digital information integration,and index formulation based on massive data.The study presented theoretical and technological exploration on different indexes formulation,and also provided a useful reference for the application of digital resources integration in other fields.
Key words:digital resources integration;multi-sources heterogeneous digital information;containerized freight index;data warehouse;model;method;technique;the logistics industry
数字资源整合是指将原本多元异构的、离散的、分布的数字资源通过逻辑或者物理的方式[1],依据不同的模式、策略,对于数字资源系统中的数据对象、功能结构及其互动关系进行融合、类聚和重组,重新结合为一个新的有机整体,形成一个效能更好、效率更高的新的数字资源体系[2]。
数字资源整合的起因是由数字资源的现状与信息用户的需求之间的差异造成的。从技术层面来看,不同的数字资源系统的数据结构和语义表达不一样,不同的系统开发者使用不一样的数据描述和数据组织标准,数据检索的方式和方法也不同;从数量上来看,随着大数据时代的到来,数据资源的种类越来越多,除了电子文档之外,Web、报文、视频、音频、图形和图像等类型的数字资源随着互联网发展,数字资源的数量呈指数增加的趋势;从内容上来看,数字资源存在大量冗余信息,内容交叉重复,数字资源之间知识关联程度很低,真正的数字资源分布在不同的组织等问题[3],这些数字资源的价值密度较低,需要经过整合和处理之后,方能满足信息用户的使用需求。
1 数字资源整合研究现状
关于数字资源整合的研究在国内主要集中在图书情报领域,通常认为开始于21世纪初,毛玉萃针对企业内部信息和企业电子商务信息的信息整合揭开了数字资源整合研究的序幕[4],此后该领域的研究持续升温,主要集中在五大方面:一是模式研究,如跨库检索[5]、系统和数据整合模式比较[6]等;二是方案策略和方法研究,如目标研究[7]、原则研究[8]、基于本体[9]、基于知识链[10]等;三是影响因素研究,如政治、经济、技术[11]和资源本身的属性等;四是标准和协议研究,如Web Service[12]等;五是服务研究,如数据库、检索平台[13]等。
数字资源整合中的数据整合技术经历了30多年的发展,不同的阶段,针对的数据对象不同,采用的技术方法和体系结构也不同,一般来说分为物理整合和逻辑整合。
1.1 联邦数据库
20世纪80年代,数据整合的对象主要是异构数据库,多采用联邦数据库集成框架和多数据库语言方法集成架构等技术,联邦数据库管理系统通过执行控制和协调来实现对组件数据库中数据的集成[14]。前期采用紧密耦合的方式,但由于这种方式太脆弱,后期渐渐采用松散耦合的方式[15]。
1.2 数据仓库
联邦数据库模式对于数据的集成是逻辑上的,随着信息用户对于决策支持的需要,物化方法(Materialized)开始出现,最常见的就是数据仓库方法,数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策[16]。数据仓库的特点主要体现在以下3个方面:实现了分析数据与生产线数据的分离;实现多个异构数据源的集成;数据处理和分析能力强。
1.3 Wrapper-Mediator方法
20世纪90年代,随着面向对象和分布式网络技术的发展,针对异构数据库的数据整合研究主要集中在Wrapper-mediator体系结构方面[17]。Wrapper-Mediator方法又被称为中间件集成法[18],本质上是一种逻辑集成或者模式集成[19]。模式集成方法可以弥补物化方式在数据实时性上的一些不足,同时具备在网络延时小和参与运算的数据规模小的情况下计算速度更快、支持应用系统的应用模式经常变化、适用于某些特殊的数据源(如保密数据)等优势。该方法的弱点一是会对数据源所在的系统产生负担;二是应用系统的效率和结构在很大程度上依赖网络状况。
联邦数据库方法目前已很少被采用,模式集成的方法适用于数据源所在的系统庞大、数据更新频率高、目标数据所服务的系统要求数据实时性高且数据应用模式不固定的情况,数据仓库的方式适用于数据源分布广且网络延时较大、数据应用模式变化不多、应用对于数据的实时性要求不高但对系统响应时间要求短等情况,随着大数据时代的到来、硬件成本的不断下降以及分布式存储和计算技术的发展,越来越多的基于大数据的应用倾向于使用数据仓库的方式;当然也有学者提出了基于上述两种方法的综合方案[20]。
本文综合比较各种方法,在分析物理整合和逻辑整合的基础上,结合数据仓库的运价信息提出了新的方法。
2 基于数据仓库的运价信息集成模型
随着世界贸易格局的变化和标准化进程的加快,集装箱船运输方式在国际海运中所占的比重在逐渐增加,集装箱运价的变化也一直受到业内人士的关注,研究国际集装箱运价指数的科学编制体系,及时准确地反映国际集装箱运价波动的程度和趋势,提高集装箱运价预测的能力,成为全球业内人士的共识。按照目前普遍的模式,运价样本信息的采集是按照如下准则来操作的:由指数编制机构指定若干企业或组织作为信息源提供者,提供者根据指数编制机构给出的信息标准和要求定期向指数编制机构单独报送信息,编制机构先对信息进行预处理,然后按照既定的算法得出某周期的航运运价指数[21];现行编制体系在理论层面具备科学性,可操作性强,所以被世界范围内的航运运价指数包括集装箱运价指数广泛采用,但其缺陷也长期存在,主要体现在以下两个方面:
1)运价信息的属性
目前集装箱运价指数编制所用的运价信息采集自班轮公司和代理机构,且主要来自班轮公司的报送运价信息,该运价信息并非自由竞争市场的价格。这正是包括波罗的海交易所在内的诸多航运运价指数编制机构一直致力于找到实际市场价格来编制航运运价指数的原因。
2)运价信息的及时性和广泛性
班轮公司报送的运价信息变化周期长,反映集装箱市场变化的及时性不够,在实际操作中容易受到人为因素而影响运价信息的准确性;而且运价信息的来源不够广泛[21]。
互联网和电子商务的浪潮席卷全球,同样也在深深影响着航运业,全世界范围内出现了大量航运电子商务平台,这些平台将航运服务资源如集装箱船的舱位作为商品,基于互联网实现全流程在线交易;随着这些平台的运营和发展,越来越多的行业用户选择使用在线交易方式代替传统的纸面交易模式。这种模式表现出业务信息高度集中、实时性强、准确率高以及易于存储、传输和使用等优点。本文认为,集装箱运价指数编制的信息源完全可以从传统的使用采样数据的方法转变到以从事国际集装箱舱位交易电商平台和信息化系统上沉淀的运价信息为基础,运用信息集成技术整合多个平台和系统的运价数据,为集装箱运价指数的编制提供实时的、海量的、真实成交的运价信息[23]。
2.1 运价信息集成模型的基本框架
集装箱运价指数编制的运价数据分布在处于异构环境中的不同航运电商平台或系统上,所以运价数据必然是异构的,需要找到一种有效的方法,根据集装箱运价指數编制的要求对运价这些数字资源进行整合,数据的整合不但要遵循完整性、针对性和动态性等原则[24],且整合后的结果能根据指数编制的模型进行组织和序化,能够针对指数分析的需求进一步进行多维度、多粒度融合和分析[25]。编制集装箱运价指数所需要的运价信息是历史数据,根据集装箱海运业务的惯例,数据采集的最高频率为每日1次即可;为了实现运价指数编制的高效,必须实现对异构数字资源的物理集成,通过序化使得结果数据的结构统一,同时为了保证指数结果的可回溯性,必须将运价信息与原业务系统分离,本文设计的基于数据仓库方法的数字资源整合模型如图1所示。
其基本思想是:按照指数编制的需求,定义基于数据仓库的目标数据模式,针对3类异构信息,通过连接或解析或提取等手段操作信息源,再依照规则库和元数据模型对数据进行映射、抽取、清洗和转换,然后根据目标数据模式定义的格式将数据装载到数据仓库中,作为指数编制和指数服务等应用程序的信息处理对象,设置中间数据作为数据装载的写入缓冲。
2.2 实现运价信息集成的关键技术
根据图1,基于数据仓库的运价数据整合模型要正常运转,其实现的关键技术有3个方面。
1)定义数据仓库模型
定义多维的、有冗余的数据模型,方便使用上卷、下钻和切片等方法进行多层次多角度的分析,集装箱运价指数编制和分析的雪花模型如图2所示,这些信息以事实表和维表的方式存放在数据仓库中。
2)整合异构数字资源
异构数字资源的整合首先要建立元数据库和规则库。事实表和维表确定元数据库的属性,根据指数编制的需求来确定属性的值域、格式和描述等内容。
在预处理环节,对于不同来源的数字资源采用不同的方法,在本文的研究中,运价数据的主要来源是结构化和半结构化信息,非结构化信息主要用作本体库和知识库的完善和扩展;本体库主要包含与集装箱海运运价相关的概念以及这些概念之间的关系,随着数据的不断增加本体库将不断被完善,为了提高准确率,本体库的更新过程需要行业专家的人工介入,本体库为知识库的建立和完善提供概念和关系方面的支持。
在本文的研究中,知识库采用产生式知识表示方法,采用三元组或四元组的形式表示,根据概念、关系的不同分别采用(关系、概念1、概念2…)或(对象、属性、值)等表示形式,如(相等、起运港、装货港、POL)、(出错、20GP运价、小于0),知识库中存放的一条一条的规则,且规则之间不能相互调用[26],在本体库和知识库的基础上,建设和维护规则库,以形成计算机可执行的指令。
本文讨论的结构化数据主要针对关系型数据库。通过ODBC与原运价数据库建立数据连接,基于运价表或其他相关数据表创建本地数据副本;也可采用数据库工具或编写脚本将运价数据转换为易于识别的数据模式(如报文等),同时针对属性设计校验,对存在明显错误的运价数据记录实施过滤,以提高运价数据的使用效率。
本文讨论的半结构化数据特指Web信息。因运价信息分布在互联网的各个平台和系统上,先确定这些数字资源的获取范围,获取后将Web信息存储在临时存储区,然后进行解析[27]。对于以Html、XML、Json等格式存储在临时存储区的运价数据,可采用两种方式。第一种方式是将文件视为字符流,读取运价文件的同时读取知识库,若文件中有字符内容与知识库相符,采用堆栈技术,根据特殊字符判断属性和内容,并抽取运价内容,读取规则库对属性的数据实施转换并插入目标数据仓库,若不相符,则根据特殊字符结合属性和内容推测,并向用户提示人工介入,判断抽取或舍弃该部分数据,同时更新知识库;第二种方式是采用文档对象模型(DOM),将XML文件中的运价信息内容解析为文档树,读取文档树中的子结点信息即可抽取出运价相关的属性和值。这两种方法在实际运用中都可调用开源的API。前者解析速度快,占用内存少,但开发较复杂,后者易于实现,但不适合大型文件的操作,也可以采用JDOM方法实现二者的结合。
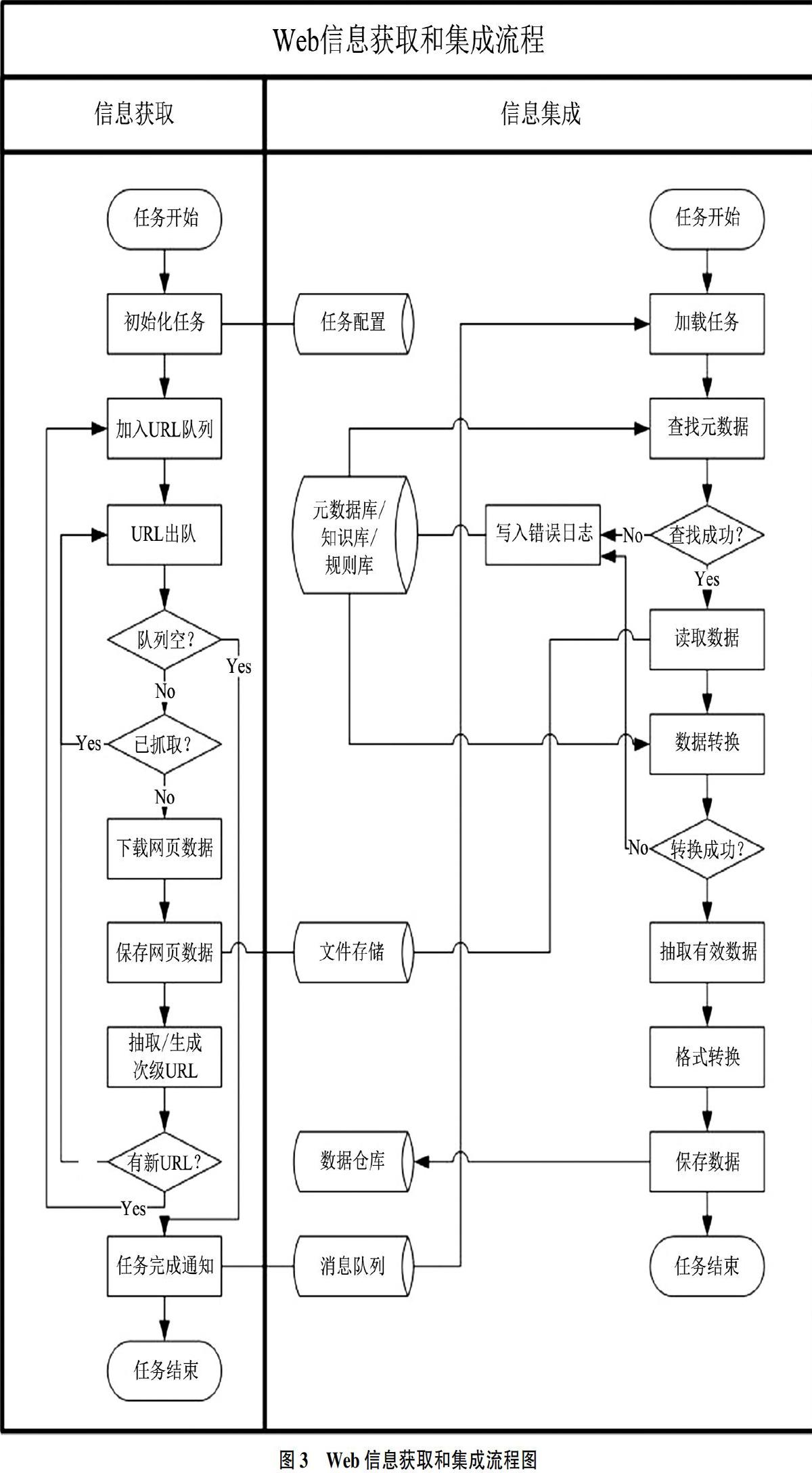
Web信息获取和集成流程如图3所示。
流程简要描述如下:
①根据配置好的任务定向获取运价Web信息,策略为先广度再深度,直到指定的Web信息源获取完成;
②以文件形式存储运价Web信息至临时存储区;
③读取元数据库、转换规则库和知识库;
④采用相应的方法解析Web信息并抽取需要的运价相关信息以数据仓库的方式存储;
⑤错误日志在行业专家的介入下更新知识库和规则库。
3)处理增量信息
必须设置周期性触发的定时任务以获取增量运价信息。对于结构化数据,定时任务自动扫描预定的所有数据库,若运价数据库中有Creattime属性,则直接采用时间戳判断增量数据,若无时间戳或无法获取到时间戳字段,则利用数据库主键值判断新增运价信息,对于分布式数据库(如RAC),数据库主键可能产生顺序混乱而导致增量运价数据无法完整采集的情况,则采取数据对比判断的方法,根据数据对比后的结果调用任务(Job),实施增量更新。
运价采集程序读取目标URL,对比URL模式表,如可变化参数部分的内容与目标库中已有的URL完全一致,则判断该Web为已存在信息,则放弃,反之则判断其为增量运价信息;若URL是静态的,但运价信息持续更新,则提取Homepage或者Startpage中输入下拉菜单列表中的内容,针对这些内容进行深度和广度遍历,获取所有运价Web,将获取的信息输入已定义好的Hash表达式计算得新获取Web信息的Hash值,将结果与目标库中已有的URL的Hash值对比,值相同,则舍弃,反之则判断其为增量运价信息。
非结构化信息通常以文件形式存储在既定的目录中,定时任务扫描文件根目录,按照文件系统的规则确定新文件,只读取和发送新文件。
3 实证研究
3.1 数据来源与处理
使用某市集装箱舱位订舱平台的后台运价数据库信息与某几个集装箱舱位订舱网站的Web运价信息对本文提出的数字资源整合模型进行检验。其中该订舱平台运价数据库(如图4所示)共包含379 314条运价信息,包括起运港、中转港、目的港、船公司、货代公司、发布日期、有效日期(有效期起和有效期止)和各箱型运价(4种箱型:20GP、40GP、40HC和45HQ)等13个属性字段;配置Web信息获取任务,从多个网站获取运价信息,各个网站运价数据的属性都不尽相同,样例见图2;在行业专家的协助下建立知识库和转换规则库,经过数据预处理之后,利用数字资源整合模型对这些数据实施抽取、转换,最后将数据存储在数据仓库中,整合后的数据仓库样例见图6。
3.2 数字资源整合的效果
将结构化数据、半结构化数据以及非结构化数据按照上述模型进行整合,作为集装箱运价指数编制的基础信息,指数编制系统根据实际业务情况执行数据清洗和运算之后,得出运价指数结果,如图7所示;指数分析系统从不同的维度和粒度进行数据挖掘,以支撑指数报告等其他服务。
4 结 语
在我国,数字资源整合研究较为关注医学、图书馆、档案和博物馆等领域[28],在物流领域,国外有学者探讨了在供應链中生产信息整合对企业发展的作用[29],而在针对航运运价指数领域中,大多数学者进行的是航运运价指数编制模型和应用层面的研究,很少涉及用于编制航运运价指数的基础信息来源和信息集成的研究。本文从大数据背景出发,面向集装箱运价指数编制的需要,设计数字资源整合模型,探讨其原理和实现技术,并进行了实证研究,结果说明将分散在各航运电商平台和系统上的运价通过数字资源整合作为集装箱运价指数编制的可行性,今后研究的重点在于进一步完善针对半结构和非结构化数据的集成模型和算法,以提高其准确度、自动化程度和集成效率。
参考文献
[1]邢荣华,朱玉珍,韩依辰,等.面向高校利用者的数字资源整合系统设计[J].现代情报,2017,37(2):68-74.
[2]马文峰.数字资源整合研究[J].中国图书馆学报,2002,28(4):63-66.
[3]赵建平.数字信息资源整合方式比较研究[J].情报科学,2008,26(12):1787-1791.
[4]毛玉萃.试论企业电子商务与企业内信息系统的整合[J].管理信息系统,2001,(5):43-45.
[5]谢宝义.高校图书馆数字资源整合模式研究与实践——以石家庄铁道大学图书馆为例[J].图书馆建设,2011,(2):33-35.
[6]张巧娜.海峡两岸高校图书馆数字资源整合的比较研究[J].图书情报工作,2012,56(19):43-47.
[7]李红霞.图书馆馆藏数字资源整合方案研究[J].现代情报,2006,26(8):144-145.
[8]赵荣.浅谈图书馆服务工作如何应对数字化阅读的挑战[J].图书馆工作与研究,2011,(7):99-101.
[9]郝欣,刘英涛.基于本体集成的数字资源整合研究[J].图书馆学研究,2011,(20):55-59.
[10]崔伟,徐恺英,王宁.基于知识链的数字资源整合研究[J].图书馆学研究,2010,(15):32-35.
[11]袁村平.图书馆与出版企业数字资源共享影响因素分析[D].湘潭:湘潭大学,2013.
[12]杨晨.基于Web Services的高职院校教务平台的设计与实现[D].成都:电子科技大学,2014.
[13]邱均平,王菲菲.基于共现与耦合的馆藏文献资源深度聚合研究探析[J].中国图书馆学报,2013,39(3):25-33.
[14]陈海敏.异构信息集成系统研究[J].情报科学,2008,(12):1902-1907.
[15]JM Smith,PA Bernstein,U Dayal.Multibase:Integrating Heterogeneous Distributed Database Systems…-American Federation of Information Processing Societies:National Computer Conference,1981:487-499.
[16]W H Inmon.Building the Data Warehouse.Boston:QED Technical Publishing Group,1992
[17]谷岩,冯华.利用数据仓库技术解决异构数据库的集成问题[J].计算机应用与软件,2005,(6):24-26.
[18]Wiederhold G.Mediators in the Architecture of Future Information Systems[J].IEEE Computer,1992,25(3):38-49.
[19]D Florescu,A Levy,A Mendelzon.Database Techniques for the World Wide Web:A Survey[J].SIGMOD,1998.
[20]陈跃国,王京春.数据集成综述[J].计算机科学,2004,(5):48-51.
[21]周甫宾.基于EDI的集装箱运价指数生成与技术分析[J].中国航海,2006,(3):82-86.
[22]Zhao Yifei,Zhang Dali,Tatsuo Yanagita.World Conference on Transport Research WCTR 2016:Container Liner Freight Index Based on Data from E-booking Platforms:Shanghai,2016:10-15.
[23]付东方,赵一飞.集装箱运价指数数据源及算法分析[J].大连海事大学学报,2015,(3):87-92.
[24]马大川,杨红平.信息资源的集成整合研究[J].中国图书馆学报,2004,(3):36-40.
[25]刘平峰,章佩璐,张军,等.面向主题的Web信息融合模型[J].图书情报工作,2011,(8):40-43.
[26]徐宝祥,叶培华.知识表示的方法研究[J].情报科学,2007,(5):690-694.
[27]孟小峰.Web信息集成技术研究[J].计算机应用与软件,2003,(11):32-36,63.
[28]罗书练,郑萍,陈志强.加强数字资源的整合 提供良好信息服务[J].医学信息:上旬刊,2005,18(8):940-941.
[29]Devaraj S,Krajewski L,Wei J C.Impact of eBusiness Technologies on Operational Performance:The Role of Production Information Integration in the Supply Chain[J].Journal of Operations Management,2007,25(6):1199-1216.
(責任编辑:孙国雷)
猜你喜欢
快乐学习报·教师周刊(2022年10期)2022-04-21
内蒙古教育(2021年14期)2021-02-12
中国外汇(2019年19期)2019-11-26
自然资源信息化(2019年4期)2019-03-29
中国交通信息化(2018年2期)2018-06-06
电子制作(2016年15期)2017-01-15
山东工业技术(2016年15期)2016-12-01
中国教育信息化(2015年10期)2015-08-23
