
基于研究兴趣相似性网络的我国图书馆学研究社群分析
2019-10-06 02:40江文华徐健李纲李阳
现代情报 2019年9期
关键词:图书馆学
江文华 徐健 李纲 李阳
摘 要:[目的/意义]从学者研究兴趣视角出发,探究图书馆领域研究现状,分析该领域社群结构。[方法/过程]从CSSCI数据库中下载“中图分类号=G250”的所有论文,通过Java程序处理数据,利用“机器+人工”进行作者消歧。使用普莱斯定理识别图书馆领域核心作者,利用学者科研成果提取作者的研究兴趣,构建该领域核心作者研究兴趣相似性网络,使用Louvain方法对该领域研究者进行社群划分。计算各社群研究兴趣模型,并计算各个社群间的研究兴趣相似性。[结果/结论]研究发现:1)图书馆学作者发文频次与核心作者研究兴趣相似性服从幂律分布;2)图书馆学领域核心作者按研究兴趣可分为6个社群;3)C1-C2、C2-C3、C3-C4社群间存在强相似性,C6社群与其他社群相似性较低。
关键词:研究兴趣;相似性网络;图书馆学;研究社群
DOI:10.3969/j.issn.1008-0821.2019.09.003
〔中图分类号〕G250.1 〔文献标识码〕A 〔文章编号〕1008-0821(2019)09-0021-07
Abstract:[Purpose/Significance]From the perspective of scholars' research interests,this paper explored the research status of the library science and analyzes the community structure in this field.[Method/Process]This paper firstly downloaded all the papers of“CLC=G250”from the CSSCI database,processed the data using Java program,and used“machine & manual”method for author disambiguation.Using the Price Law to identify the core authors in the library field,using the scholars' scientific research outputs to extract the author's research interest,construct the core interest research similarity network in this field,and use the Louvain method to divide the researchers into the community.Then,this paper calculated the interest model of each community research and the similarity of research interests among different communities.[Result/Conclusion]The study found that(1)the frequency of anthor with different output level and the similarity of research interest between co-authors in library science obeyed power law distribution;(2)the core authors of the library science could be divided into 6 communities according to their research interests;(3)C1-C2,C2- C3 and C3-C4 community dyads were more similar than other dyads,and the C6 community was little similar with other communities.
Key words:research interest;network of similarity;library science;research community
圖书馆作为搜集、加工、存储图书资料的文化机构,具有保存与分享知识与文化的职能,对人类科技发展与社会进步具有重要的作用。图书馆学(Library Science)是研究图书馆的发生发展、组织管理,以及图书馆工作规律的科学,其研究成果对图书馆未来进一步发展具有重要的指导作用。图书馆学研究领域的知识结构与社群分布是广大图书馆研究人员普遍关注的问题,对于其学科认知、研究问题与方法的寻找、研究现状的掌握等都具有重要的意义。直观来看,领域专家的研究兴趣对其研究内容和方向具有重要影响。因此,从研究兴趣视角出发,对图书馆学领域核心作者进行社群划分,可以把握其领域分布、知识结构及未来发展方向,对该领域科研活动的管理、组织与协调都具有重要意义。
本文首先从CSSCI数据库中下载中图分类号为G250所有的论文,使用程序对这些数据进行字段提取处理,利用普莱斯定律识别出该领域的核心作者。在此基础上,构建核心作者研究兴趣表示模型,并计算任意两位作者之间相似性,据此构建图书馆学领域核心作者研究兴趣相似性网络。在此基础上,使用社群识别方法分析该领域作者的社群结构,并对社群间关系进行分析。希望通过上述研究为相关研究提供借鉴与参考。
1 相关研究
1.1 图书馆学领域结构研究
关于图书馆领域结构的研究存在两种思路:定性归纳和定量研究。前者依靠领域专家对学科整体研究情况的把握,重点关注学科发展历史[1-2]、理论体系[3]、图书馆精神[4]等学科问题,这类研究多依靠专家经验形成观点,往往缺乏实证支持。后者则更多利用文献计量、社会网络分析等方法挖掘图书馆学学科领域结构与社群关系,使用可视化、直观的方式进行结果解读。例如,张蔓蒂等[5]使用同被引分析方法对图书馆学情报学进行聚类、多维尺度和因子分析,将这些杂志分为4类。刘涛等[6]使用共词分析的方法将图书馆学研究内容分为数字图书馆建设、著作权问题、图书馆创新服务、知识管理与服务、元数据等10个研究领域。程大帅[7]利用共词知识图谱的方式将图书馆领域的研究热点分为信息资源建设、古籍保护、信息检索与组织、图书馆法律法规、图书馆用户需求与服务5类。伍若梅[8]利用作者共被引的方式对图书馆学领域的核心作者进行社群识别,将其划分为图书馆和图书馆学理论、图书馆建设、信息资源管理、目录学与文献学和文献标引与编目五大流派。
上述研究多使用专家经验、计量学等方法来分析图书馆领域结构,多利用共词网络、合著网络、共被引网络等从学科整体层面识别社群与研究主题。较少有从研究兴趣角度出发开展领域结构识别的研究,更鲜有研究分析各社群间的关联关系。
1.2 研究兴趣及其度量研究
兴趣是一类心理现象,对人们实践与认知均有重要的影響。在学术活动中,学者的研究兴趣会影响其领域和课题的选择。因此,从整体层面分析作者研究兴趣的分布有助于把握学科领域研究现状与未来发展方向。当前研究兴趣有关的研究主要可分为研究兴趣现象、研究兴趣表示与相似性计算两方面。
在研究兴趣现象研究方面,Jia T等[9]利用海滩游走(Seashore Walk)模型解释作者研究兴趣演化的内在规律与演化特性,研究提出作者研究兴趣演化的异质性、新近效应、主题相似性。关鹏等[10]对锂电池领域作者研究兴趣演化模式进行分析,发现作者研究兴趣与相应主题在演化过程中如能取得一致性,则能够引领该主题的发展。徐健等[11]对学者研究兴趣的模糊隶属问题进行研究,发现各社群作者对各自所述的社群隶属度与其他社群隶属度均处于0.5~0.6和0.1~0.2之间,各社群作者在社群模糊隶属上差异较小。李纲等[12]分析研究兴趣相似性与作者合著的关系,描绘了合著作者对研究兴趣相似性频率分布模式,发现不同学科间研究兴趣频率分布模式具有相似性。
在研究兴趣表示与相似性计算方法方面,Steyvers等[13]对原始主题模型进行修改,提出作者主题模型(Author Topic)用于揭示作者研究兴趣,并探索该模型在主题演变趋势分析、作者主题关联分析、作者异常论文检测等方面的应用。李树青等[14]以VSM为学者兴趣表达模型,并使用时间片震荡算法发现学者的主要研究兴趣,以此开展便携式个性化服务研究。刘萍等[15]通过向量空间模型计算关键词间关联,并利用P-Rank算法计算两个作者关键词网络的结构相似度。李纲等[16]使用词袋模型表示作者研究兴趣,使用Jaccard和Cosine等方式计算两个作者之间研究兴趣的相似性。巴志超等[17]引入Word2vec模型对作者关键词矩阵进行语义建模,计算两个作者研究兴趣矩阵的JS距离作为其兴趣的相似性。
当前多数研究集中在学者研究兴趣表示模型和相似性计算上,相关研究为本文提供了理论基础和重要借鉴,较少有学者选择一个学科领域对其核心作者研究兴趣相似性网络的特性进行探究。
2 研究方法
2.1 研究过程
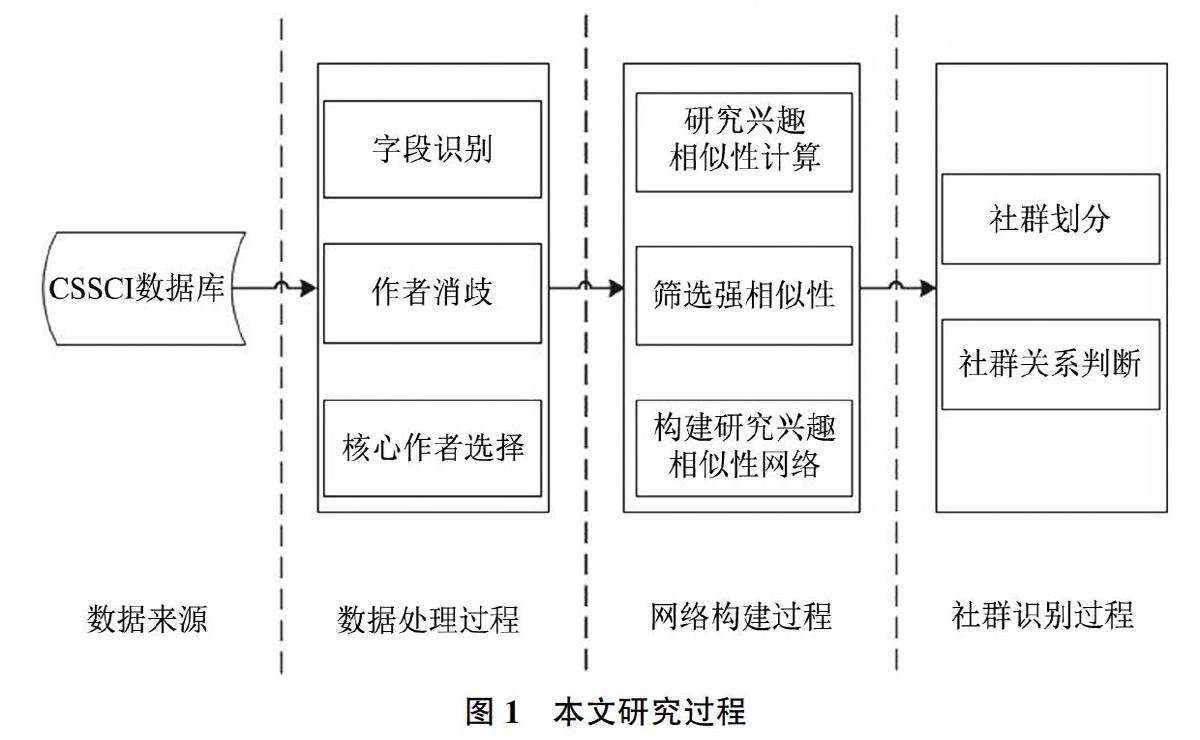
本文研究过程如图1所示,包括数据来源、数据处理、网络构建、社群识别4个过程。
其中本文选择的数据来源是CSSCI数据库,检索条件为G=250,检索日期为2018年12月9日,共包含1998-2018年图书馆学领域文献21 417篇。下载这些题录数据,并使用Java程序对这些数据进行解析,存储在MySQL数据库中。
为保证数据分析的准确性,本文使用“机器+人工”消歧的方式对同名作者进行消歧。首先,根据“作者+一级单位”的方式对每一个赋予不同的ID号码。对相同姓名不同ID的作者结合实际情况进行合并。由于本文后期只关注核心作者的研究兴趣,而且对发文一次的ID进行考虑会使得作者消歧工作比较繁重,本文选择了发文量大于3的ID进行同名消歧,共消除80对同名不同单位的作者。在消歧过程中,本文发现机构名称变更、作者单位更换是导致前文“作者+一级单位”方法未能正确消歧的两种情况。需要说明的是,针对同单位同姓名却不同人的情况,本文使用的方法无法有效识别出不同作者。该定律衡量了各个学科领域文献作者分布规律,常被用于选择学科领域的核心作者,本文亦采用该方法。
2.2 核心作者研究兴趣相似性网络构建
核心作者研究兴趣相似性网络构建主要包括研究兴趣相似性计算、相似性筛选、研究兴趣相似性网络构建3步。本文使用“词袋模型”(如公式所示)作为作者研究兴趣表示方法,各个词项的权重使用TF-IDF方法计算,其中IDF计算方法如公式所示。
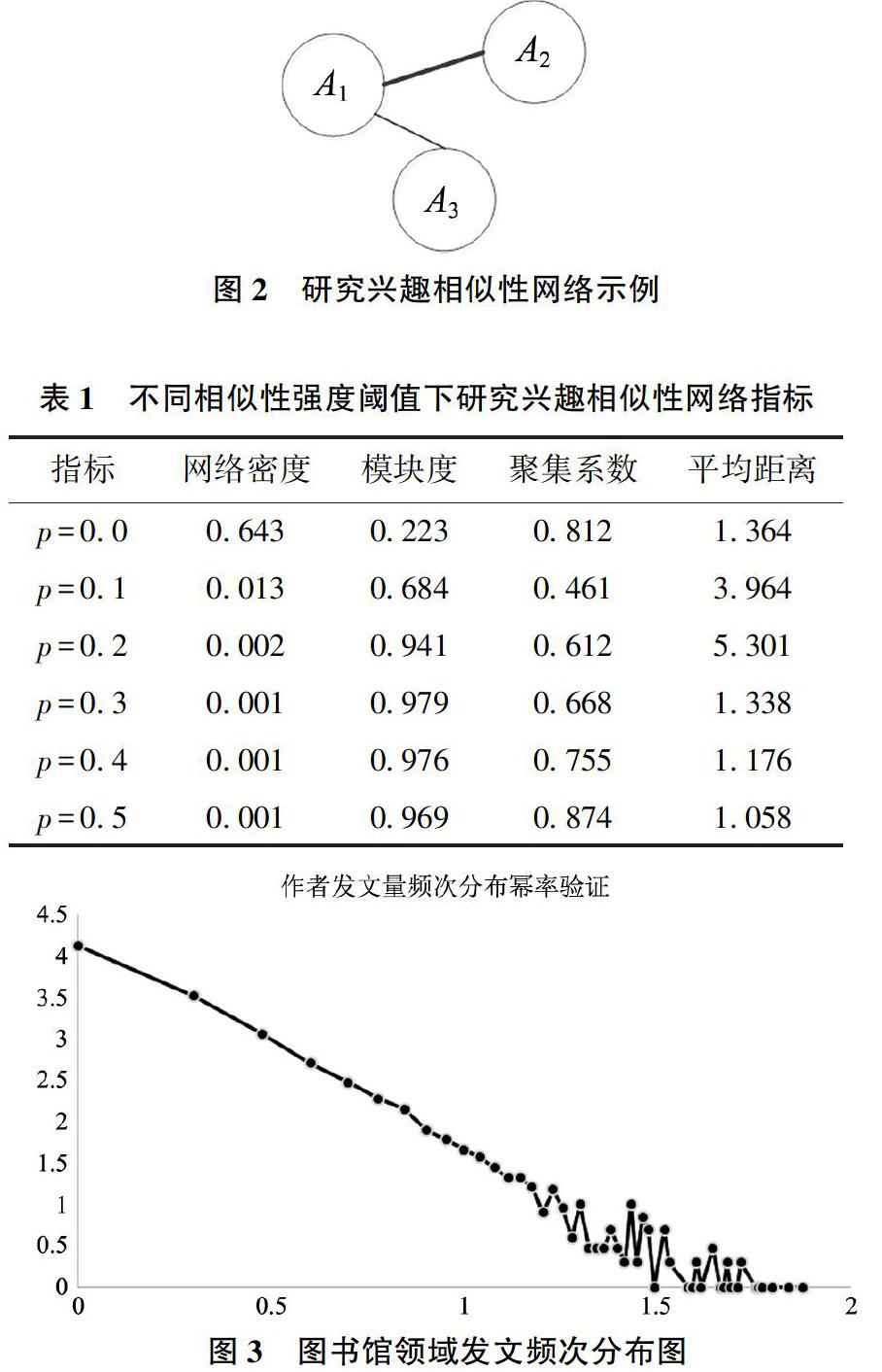
本文使用两个词袋之间的余弦相似度来衡量作者研究兴趣之间的相似性。核心作者研究兴趣相似性网络是一种以某领域核心作者为节点,研究兴趣相似性数值为边权重的网络。若两作者间研究兴趣相似性大于0,则两节点间存在1条边,相似性越高,则边越粗。否则,若相似性为0,则两节点间不存在边。
上述过程生成的网络有可能存在过于稠密的情况,导致网络社群结构不是很明显。本文使用的相似性计算指标是依据关键词计算的,取值为0~1之间。只有两个作者从未使用过同一个关键词,相似性取值才会为0。因此,在实际社群划分前,需要剪除权重较低的边,仅保留相似性较强的边。
2.3 领域社群划分与社群关系计算
社群结构是复杂网络的普遍特征,社群内部节点与节点间连接紧密,而社群间连接比较稀疏。社群划分主要用于发现网络中的社群结构,可以看作一种聚类算法。总体来说,社群划分算法可分为凝聚算法和分裂算法两类算法,本文使用Louvain算法[18]进行图书馆领域核心作者研究兴趣相似性指标划分。该方法是一种基于模块度增益计算的方法,具有快速和非监督的特点,比较适合有权网络社群划分。在社群划分完成后,可对归属于该社群的作者的研究兴趣进行累积,生成社群层面的研究兴趣表示模型。此时,可通过计算两个社群研究兴趣间的相似性来表征两个社群间的相关关系。
3 研究结果
3.1 基础数据表示与核心作者识别
经统计,文本所搜集的数据集共包含文献21 108,累计作者频次35 288,篇均作者1.67位。
经上文作者消歧步骤后,共识别出图书馆学领域作者19 198位。对这些作者发文量进行统计,图3对发文量和作者数目都进行了对数处理,发现其大致呈直线分布。说明本领域发文频次的作者数目同样符合冥率分布。在本数据集中,发文量最多的是中国科学院文献情报中心的张晓林教授,在该领域共计发文75篇。按照普莱斯定律(如公式所示),核心作者为该数据集中发文量大于7的作者,图书馆学领域共有567位作者被选择为本研究的目标群体。
3.2 研究兴趣相似性网络指标与边权重分布
本文构建的研究兴趣相似性网络节点数目为567,边数目为103 014。此时网络密度高达0.643,此时整体网络为混沌的一体,模块度为0.223。一般认为,模块度在0.3~0.7之间的极大值具有较明晰的模块结构[19]。因此,本文考虑剪除相似性较弱的边,也就是给定一个阈值剪除所有小于该数值的边。表1列出了选择不同相似性强度阈值时,研究兴趣相似性网络的网络指标。从表1可以发现,当阈值为0.0时,也就是未删减任何边的情况下,网络的模块度为0.223,此时网络的社群结构不明显。而当阈值为0.2及以上时,网络的模块度均大于0.94。此时,网络是由较多独立节点构成,最大联通图的规模也较小。
图4是图书馆学领域核心作者研究兴趣相似性网络边权重的频率分布图。理论上,相似性取值是0~1之间的连续值,因此要对该数值进行离散化操作,本文将相似性取值从0~1划分为100组,组距为0.01。在图书馆学领域,研究兴趣相似性最高的两位作者是南开大学的李超和董洁两位学者,两位学者均侧重于研究图书馆员工作行为。
在此,本文采用二八定律,仅保留权重前20%的边,也就是保留103 014条边中权值较大的20%条边。经过排序,选取权重倒序前20%的边,形成最终的研究兴趣相似性网络。
3.3 图书馆学领域社群划分结果
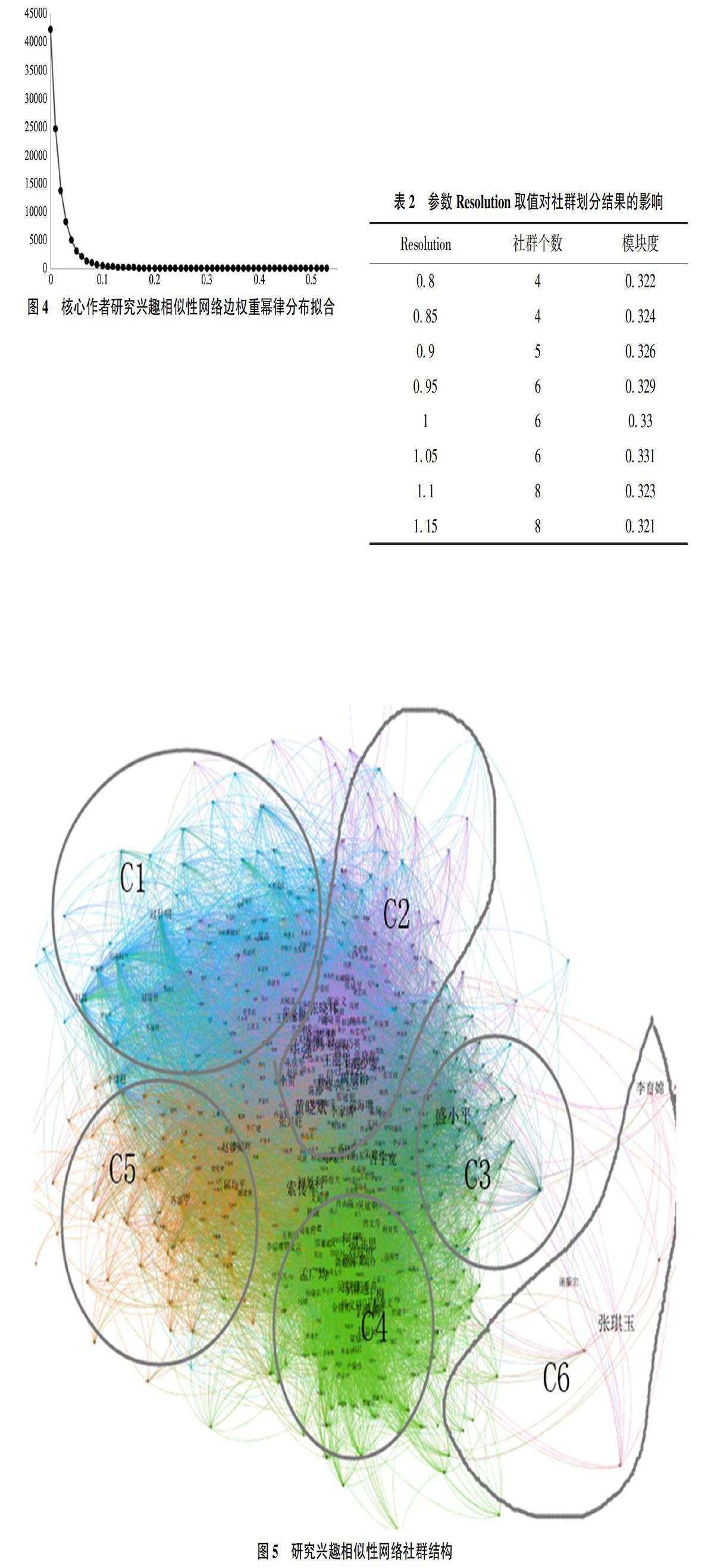
本文使用Gephi软件对剪枝后的图书馆学领域核心作者研究兴趣相似性网络进行社群划分,模块度为0.329,从文献[19]中可知,模块度在0.3~0.7时会出现较清晰的社群结构。调整参数Resolution取值,观察其不同取值时社群数目与模块度,具体见表2。从中可以看出,当参数设置为1.05时,社群划分结果的模块度取得最大值,使用该参数值对网络进行社群划分,划分结果如图5所示。
3.4 图书馆学领域各社群间关联分析
为进一步探究各社群作者的兴趣特征,本文分别绘制6个社群高频关键词共词网络,如图6所示:
从图6中可以看出,各部分研究并非完全孤立,截然分开的,相互之间存在重叠与交叉部分。笔者认为,这主要是两方面原因:首先,图书馆学领域内各研究主体彼此关联,存在领域间交叉的灰色领域;其次,学者研究兴趣具有多样性和演化性,在某领域学者的研究生涯中,其关注点并不局限于某单个领域,而是随着时代和学科发展也会有所变化。
各社群研究主题虽有联系与相似之处,却各自有各自的研究侧重点。C1社群作者研究各类图书馆,包括高校图书馆、移动图书馆、数字图书馆等。该领域共有作者93人,代表作者有祝忠明,李书宁等。C2社群研究图书馆领域内的信息组织与存储问题,包括元数据、关联数据、互操作等主题,代表作者有张晓林、毕强等,该社群是图书馆领域规模最大的社群,共有156位研究学者,是图书馆领域的主流研究群体。C3社群主要研究信息资源问题,包括数据库构建、馆藏建设和资源建设等,共有作者68人,代表作者有盛小平、索传军等。C4社群以整体图书馆学为研究对象,重点研究图书馆领域理论、教育与历史等宏观整体问题,代表作者有肖希明、王知津等,该社群也是图书馆学领域的较大社群,约占核心作者总数的27%。C5社群主要采用文献计量、社会网络分析的方法研究图书馆学各类研究状况,代表作者有邱均平、赵蓉英等。C6社群是图书馆学领域规模最小的社群,仅有8人,该社群主要研究主题标引、文献编目和信息检索等问题,该社群研究内容属于图书馆学与情报学交叉的部分,代表作者有张琪玉、侯汉清等。上文得到的社群结构间并非完全隔绝与孤立,本文进一步计算各社群研究主题之间的相似性。表3给出了各社群研究社群相似性的取值,从中可以看出,各社群间相似性居于0.021~0.363之间。从表中可以看出,C1-C2、C2-C3、C3-C4社群之间存在较强的相似关系,C6社群与其他社群相似性都较低,这与图5中各社群间的亲疏关系比较吻合。
4 结 论
本文从图书馆学的学者研究兴趣视角出发,探究图书馆领域社群结构。首先从CSSCI数据库中以“中图分类号=G250”为检索条件,通过作者消歧基于普莱斯定律选择本领域核心作者。对这些学者研究兴趣进行建模,并计算两两之间的相似性构建初始研究兴趣相似性网络。剪除80%权重较低的边,对最终的网络进行社群结构划分,识别各社群研究兴趣并对社群间关系进行计算。研究发现:1)图书馆学作者发文频次与核心作者研究兴趣相似性服从幂率分布;2)图书馆学领域核心作者按研究兴趣可分为6个社群;3)C1-C2、C2-C3、C3-C4社群间存在强相似性,C6社群与其他社群相似性较低。
需要注意的是,本文研究受制于CSSCI数据收录的局限,未收集到1998年前的数据。同时,作者消歧与社群划分方法也存在一定不足。未来将朝以下方向继续开展研究:1)现有研究兴趣表示方法改进,本文使用的方法并未考虑词汇之间语义关联,未对近义词等语言现象做处理,同时探索作者的多源研究兴趣表示;2)探索更加准确的社群识别方法,本文使用的相似性权值筛选方法缺乏方法论根据;3)将时间因素考虑到研究兴趣的表示中,在微观层面分析图书馆学领域作者研究兴趣的演化问题。
參考文献
[1]韩永进.关于中国图书馆史研究的几点思考[J].中国图书馆学报,2015,41(4):4-13.
[2]杨文祥.21世纪理论图书馆学的理论起点、历史任务和研究思路[J].中国图书馆学报,2003,29(2):26-30.
[3]叶鹰.图书馆学基础理论的抽象建构[J].中国图书馆学报,1998,24(3):86-88.
[4]程焕文.实在的图书馆精神与图书馆精神的实在——《图书馆精神》自序[J].大学图书馆学报,2006,(4):2-14.
[5]张蔓蒂,胡吉明.基于同被引分析的我国图书馆学情报学期刊关系与结构研究[J].情报理论与实践,2011,34(1):31-33,38.
[6]刘涛,刘玉英,杜亮.近5年图书馆学研究热点分析——基于共词分析视角[J].图书馆学刊,2012,34(10):122-125.
[7]程大帅.基于共词知识图谱的我国图书馆学研究热点及趋势分析[J].图书馆学刊,2017,39(1):136-142.
[8]伍若梅.基于作者共被引和元分析的我国图书馆学范式研究[D].长春:东北师范大学,2010.
[9]Jia T,Wang D,Szymanski B K.Quantifying Patterns of Research-interest Evolution[J].Nature Human Behaviour,2017,1(4):0078.
[10]关鹏,王曰芬.学科领域生命周期中作者研究兴趣演化分析[J].图书情报工作,2016,60(19):116-124.
[11]徐健,毛进,叶光辉,等.基于核心作者研究兴趣相似性网络的社群隶属研究——以国内情报学领域为例[J].图书情报工作,2018,62(12):57-64.
[12]李纲,徐健,毛进,等.合著作者研究兴趣相似性分布研究[J].图书情报工作,2017,61(6):92-98.
[13]Steyvers M,Smyth P,Rosen M,et al.Probabilistic Author-topic Models for Information Discovery[C]//Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data mining.New York:ACM,2004:306-315.
[14]李树青,孙颖.一种基于Web请求访问模式和时间片震荡算法的便携式个性化服务框架[J].情报学报,2014,33(3):228-238.
[15]刘萍,郭月培,郭怡婷.利用作者关键词网络探测作者相似性[J].現代图书情报技术,2013,29(12):62-69.
[16]李纲,李岚凤,毛进.作者合著网络中研究兴趣相似性实证研究[J].图书情报工作,2015,59(2):75-81.
[17]巴志超,李纲,朱世伟.基于语义网络的研究兴趣相似性度量方法[J].现代图书情报技术,2016,32(4):81-90.
[18]Blondel V D,Guillaume J L,Lambiotte R,et al.Fast Unfolding of Communities in Large Networks[J].Journal of Statistical Mechanics:Theory and Experiment,2008,2008(10):0-12.
[19]唐磊,刘欢,文益民,等.社会计算:社区发现和社会媒体挖掘[M].北京:机械工业出版社,2012.
(责任编辑:郭沫含)
猜你喜欢
国家图书馆学刊(2022年2期)2022-06-17
甘肃科技(2020年21期)2020-04-13
经济技术协作信息(2018年7期)2019-01-14
上海高校图书情报工作研究(2017年2期)2017-07-24
图书馆论坛(2015年4期)2015-02-13
图书馆论坛(2014年9期)2014-03-11
图书馆论坛(2014年9期)2014-03-11
图书馆论坛(2014年8期)2014-03-11
图书馆(2014年6期)2014-02-12
图书馆界(2013年6期)2013-03-11
