
基于重点变异区域智能识别的模糊测试技术
2019-09-28 01:25董雨良秦晓军甘水滔
计算机技术与发展 2019年9期
董雨良,董 博,秦晓军,甘水滔
(数学工程与先进计算国家重点实验室,江苏 无锡 214125)
0 引 言
当前,主流的软件脆弱性自动化检测技术包括静态分析、符号执行、污点分析[1]及模糊测试[2-3],每种方法都存在各自的优缺点。例如,静态分析分析速度快,能适应于大规模代码,但误报率高,无法动态验证脆弱性的正确性;符号执行和污点分析精度高,但受限于代码规模和环境,对于绝大部分的软件对象无法发挥效用;模糊测试是当前使用最广泛和有效的方法,可以适应各种类型和规模的软件,但代码覆盖和输入覆盖能力较弱。从多个主流的公开漏洞数据库中可以得知,利用自动化方法发现和披露的脆弱性中,绝大部分来源于模糊测试(Fuzzing)方法。因此,模糊测试方法一直是最受关注的软件安全自动化测试技术之一。
模糊测试方法的核心思想是针对被测程序,自动或半自动地生成随机测试用例作为输入,监视程序执行情况,筛选出其中能够触发程序崩溃或断言失败异常的测试例。传统模糊测试存在用例生成过于简单随机,测试效率低下;无明确的变异指导方法,变异过于盲目,难以发现深度脆弱点等问题,使得传统Fuzzing测试效果不尽如人意。为提升模糊测试效率,研究人员尝试将符号执行[4-5]、遗传算法[6]、动态污点分析[7]、神经网络[8]等各种技术引入测试过程。这些方法虽然都取得了一定的效果,但问题仍未完全解决,有待进一步研究。
文中提出了基于重点变异区域智能识别的模糊测试技术,通过深度学习方法训练预测模型,指导种子文件有针对性地变异,减少无效测试用例的生成,从而提升模糊测试性能。
1 背景及相关工作
AFL是一款由谷歌公司开发的反馈式模糊测试框架,以算法简洁、高效著称。其核心思想是变异合法输入文件,生成测试用例,通过插桩指令监测测试用例对被测程序执行路径的影响,记录路径覆盖变化情况,若被测程序执行到了新的路径,则将此测试用例加入种子集合中,等待进一步变异。如此迭代,以求覆盖最多的执行路径,尽可能多地触发程序执行异常。
AFL的测试策略简洁、高效,取得了很好的测试效果,但依然存在不足,如路径冲突、变异策略和种子选择策略随机性太强等。研究人员基于AFL框架做了众多改进,取得了十分明显的效果。CollAFL[9]重新设计路径边ID的分配策略,实现边的编号的唯一性,从而解决了AFL路径冲突问题。在种子选择策略上,AFLFast[10]将种子变异引起路径相应变化的概率建模成马尔可夫模型,设计多种种子选择策略,增加低频路径对应种子的变异机会,此外,不同于AFL所有种子每次变异的次数一定的策略,AFLFast通过指数提高变异次数的方式,尽量减少无效测试用例的数量,从而提升测试效率;Vuzzer[11]基于轻量级的静态分析和动态分析,利用控制流特征调整种子文件优先级,使深层路径对应的种子优先变异,频繁路径对应种子优先级降低;CollAFL提出了三种种子选择策略,分别以未访问的邻近分支数量、未访问的邻近子孙数量及内存操作数量的大小来确定种子的优先级,大幅提升了测试效果。
目前缺乏针对AFL变异策略的高效优化方案,Vuzzer利用污点分析提取数据流特征确定变异位置及方式,从而能更精准地生成测试用例,但由于污点分析的高开销,在实际软件对象测试中很难带来效果,缺乏实用性。微软研究人员提出采用深度学习来预测不同种子的重点变异区域,从实验结果上看,获得了少量的性能提升,但该工作存在以下不足:训练样本的采集模型粗糙,没有针对生成训练样本的种子选择模型,减少了训练样本的有效信息总量;采样过程引入了过多无效信息,对预测结果造成干扰,且时间开销巨大;预测结果的使用方式过于简单,没有针对性且效率较低;无法适应于二进制程序对象的测试。
针对以上变异策略的不足,文中设计了一个具备重点变异区域智能识别能力的二进制程序模糊测试系统:基于AFL实现了并行训练样本采集模型Sampling-AFL;通过深度学习预测模型智能识别不同种子的重点变异区域,并基于此实现了模糊测试工具DL-AFL。
2 基于重点变异区域智能识别的二进制程序模糊测试技术
2.1 总体思路
为便于描述,将模糊测试过程中能够引起被测程序执行变化的变异位置定义为有效变异位置。有效变异位置可能是种子文件中的某1位、2位、3位……甚至是几个不同位置的组合。将所有有效变异位置中涉及的种子文件的位置的集合定义为有效变异位图。假设种子文件x的有效变异位置集合S为{(a),(a,b),(b,c,d)},则其有效变异位图S'为{a,b,c,d}。
一般来说,每个种子文件都与一个确定的有限有效变异位置集合相对应。则可将这种对应关系抽象为函数关系:
f:x→S
(1)
其中,x表示种子文件;S表示文件x的有效变异位置集合。
若能够通过某种方式掌握这种函数关系,则对于任意种子可直接通过函数求得有效变异位置集合,然后测试所有有效变异位置即可完成程序测试。而目前的技术还无法准确得出此函数关系,但若能近似地预测出此关系,以较高的概率按预测结果变异,也能有效地提升变异准确率和测试效率。基于以上思路,将函数1近似转化为:
g:x→S'
(2)
其中,x表示种子文件;S'表示文件x的有效变异位图。尽管转化为函数2,但仍然无法得到函数g的准确表示。
深度学习具有强大的拟合能力,可以实现对复杂函数的逼近。此时,假如有大量的<种子文件,有效变异位图>数据,就可以借助深度学习强大的学习能力,近似地学习出函数g,从而能够大致地预测出种子文件对应的有效变异位图。
基于上述分析,文中设计了重点变异区域智能识别的二进制程序模糊测试方案,整体框架包括数据采样、模型训练、位图预测、模糊测试四部分。数据采样模块采用分布式结构获取大量<种子文件,有效变异位图>数据对,提供给模型训练模块作为训练数据;模型训练模块通过深度学习训练能够预测种子对应的有效变异位图的预测模型;最后,在模糊测试过程中,基于预测结果,重点变异位图标识区域,减少未标识区的变异,提升测试用例的有效性。
2.2 Sampling-AFL:训练数据采样模型
深度学习是基于对数据进行表征学习的方法,训练效果在很大程度上依赖于训练样本的质量。一个好的训练样本集首先要能够很好地反映出实际的数据分布情况,其次要有足够的数据量。基于这两点考虑,制定如图1所示的训练数据采样模型。
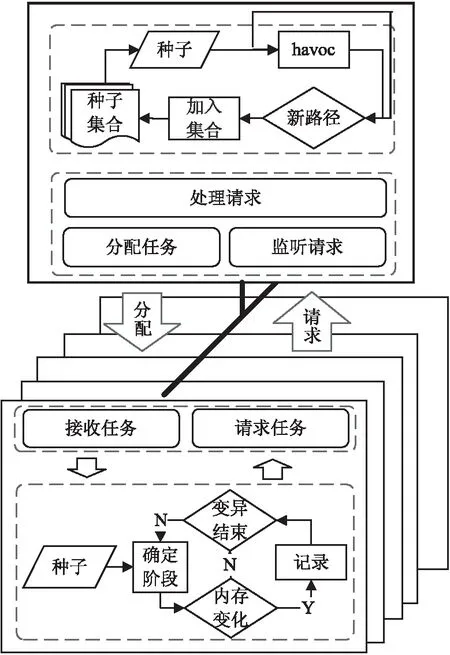
图1 采样模型
文中所需样本为<种子文件,有效变异位图>数据对,单个样本生成时间较长,采用单个服务器采样无法满足数据量需求。通过分布式结构提升取样速度,主节点分为种子生成及任务管理两个模块,分别负责种子文件的生成与任务分发控制,从节点同样分为两模块,负责样本生成和任务请求与接收。采样开始时,主节点向所有从节点分发不同的种子文件进行采样,同时开始生成新的种子文件。当子节点完成分配的任务后,主动向主节点请求任务,主节点收到任务请求后,从种子集合中选择未采样的种子,将其分发给从节点。依此进行下去,直至取得所需数量。采用分布式结构不仅可以协同多个节点同时工作,还可以使不同类型节点的任务更加单一,免去大量不必要的操作,提高数据采样效率。
为确保训练样本的差异性与多样性,必须保证种子文件之间的差异性。AFL随机变异阶段测试用例由多种变异方式组合变异而成,主节点基于此阶段生成备选种子,从而确保了不同种子之间的差异性。此外,通过不同执行路径作为加入种子集合的依据,确保不会产生过多的非法种子,从而降低训练数据噪声。
对于一个正常的种子而言,由于其变异空间过大,以目前的计算能力无法短时间获取完整的有效变异位图。因此,文中以AFL确定性阶段变异方式为基础,采取一种近似代替方式,获取有效变异位图的近似值。由于非确定性阶段的变异存在较大的随机性,且变异结果是多种变异的组合并存在删除、插入等引起整个文件巨大变动的变异方式,无法准确判断实际有效变异位。因此,从节点只记录确定性阶段的有效变异的位置。由于内存操作变化必然引起执行路径变化,针加对内存操作相关位置的变异也有助于测试过程中新路径的发现。文中用能引起内存写操作变化的位置近似代替有效变异位图。从节点数据采样过程中,种子文件变异前,保存初始内存写操作数,种子文件按照相应的变异规则变异后,对比初始内存写操作数据,若发生变化则记录下变异位置信息,反之进入下一轮变异。
2.3 深度学习模型
根据数据样本的特征,选取合适的网络组件构建深度学习模型。数据样本为<种子文件,有效变异位图>数据对。首先,种子文件长短不一,是变长数据;其次,可将通过种子文件预测位图的过程视为序列翻译过程,且序列中的元素是上下文相关的。基于此,循环神经网络(RNN)是较为合适的选择。循环神经网络是一种深度学习框架,它的提出主要是为了解决序列数据元素之间相互依赖的问题。一个简单的循环神经网络具有重复神经网络模块结构,且上一轮的输出会作为本轮的输入,从而网络具有“记忆”功能。假设网络初始状态为h0,上一轮状态为ht-1,本轮输入为xt,则本轮的输出为:ht=f(Wxt+Uht-1+b),其中W,U表示权重。RNN在语音识别、机器翻译、图片识别等领域取得了一定的成功,但单纯RNN在处理长期依赖时存在梯度消失和梯度爆炸问题,会使RNN的长时记忆失效。长短期记忆网络(LSTM)的出现很好地解决了该问题。LSTM[12]是一种特殊的RNN,其重复模块结构及各门对应数学表达如图2中LSTM所示,其中σ表示sigmoid激活函数,W*表示权重向量,b*表示偏移向量,ft,it,Ot分别为遗忘门、输入门、输出门,分别控制信息的丢弃、更新、输出,创建新的候选值向量。GRU是LSTM的一种变体,它保持了LSTM的效果,但结构更加简单,如图2中GRU所示。GRU只有更新门zt和重置门rt两个门,分别用于控制前一时刻信息保留和忽略的程度。
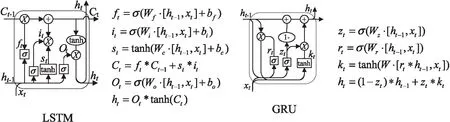
图2 LSTM与GRU细胞单元结构及数学表达
文中基于Tensorflow开源机器学习框架,分别采用LSTM及GRU来构建两层循环神经网络作为深度学习模型,以<种子文件,有效变异位图>数据对作为训练数据,进行有监督学习,训练预测模型。由于种子文件中数据并不总是以字节为最小有意义单位,常常出现按位来标识文件状态的情况,因此,将种子文件转换为0、1序列作为训练模型的输入向量。由于训练数据规模较大以及计算资源有限,无法采用批量优化,因此选用小批量优化。综合考虑实验计算资源、训练样本大小以及深度学习模型参数数量决定每批次训练样本数量(batch_size),训练样本的最大长度(max_length)进行预测模型的训练。训练样本为变长数据,通过dynamic_rnn构建神经网络实现自动对长度不足最大长度的训练数据的部分进行padding。此时每批次输入的数据都为batch_size×max_length的矩阵,每训练完一个批次,计算一次梯度,并更新网络参数值。设置keep_prob控制保留节点数,防止发生过拟合,采用指数衰减的学习率,选用均方误差作为损失函数,优化器采用Adam。
2.4 DL-AFL:具备重点变异区域预测能力的模糊测试模型
在AFL基础上,设计基于重点变异区域智能识别的模糊测试模型,如图3所示。种子文件变异之前,进行预测及预处理,如图3虚线框中所示,通过预测模型预测出有效位图,将有效位图转换为关系数组,变异过程中依据关系数组有选择地进行变异。
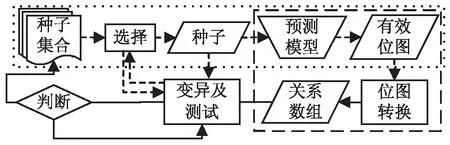
图3 DL-AFL测试模型
由于有效变异位图并非仅仅表示单比特变异有效位集合,也包含了多种其他变异方式,同时,有效变异位图不便于直接指导Fuzzing测试的变异过程,因此,需对预测出的有效变异位图做相应处理。结合AFL测试变异特点,文中将位图转换成两种变异位置与变异长度的关系数组。第一种关系数组用于确定性阶段,转换规则为:将位图中的位置作为数组下标,以0/1/3/7/15/31/63为数组的值分别对应自该位起连续0/1/2/4/8/16/32位标记为1的情况。第二种关系数组用于非确定性阶段,转换规则为:将位图中所有标记为1的位置与自该位起连续标记为1的位数(1/2/4/8/16/32位)的关系分别保存在结构体数组中。
在获取变异位置与变异长度关系数组的基础上,改进AFL种子变异过程,用关系数组指导种子变异。在确定性阶段变异过程中,若当前变异位置及变异长度在关系数组中标记为1,则进行变异;反之,则以一定概率进行变异。在非确定性阶段变异过程中,以较大的概率选择关系数组中标记为1的位置进行组合变异。
此外,通过预测结果指导变异之前必须先进行有效变异位图预测,而预测过程需要耗费一定时间,可能造成测试过程等待时间较长。为减少测试过程的等待时间,对模糊测试过程与有效变异位图预测过程(图3点线框所示)进行并行化处理。除测试选取第一个种子之外,将选取下一个种子的操作从下一轮测试开始,提前至本轮确定性阶段结束后,不确定性阶段开始前,即当前种子A完成确定性阶段变异后,立即选择下一个种子B。选定下一个种子后,继续之后的变异测试,预测模块开始预测选定种子的有效变异位图,从而减少等待时间。
3 实验与分析
基于以上思路,实现分布式采样工具Sampling-AFL、深度学习模型及基于重点变异区域识别的模糊测试工具DL-AFL,并针对nm、objdump、readelf、bmp2tiff、tiff2pdf、tiff2ps等二进制程序,基于二进制插桩平台Dyninst[13](开销远低于pin[14]、dynamoRIO[15]、valgrind[16]、qemu binary translator[17]等动态插桩框架)实现程序静态插桩,以样本生成、路径覆盖、代码覆盖率及bug发现能力为指标,进行模型性能的对比评估测试。
采用1个主节点,10个从节点构建Sampling-AFL,节点配置为:Intel(R) Core(TM) i7-2600 CPU @ 3.40 GHz CPU,2 G内存,Ubuntu 16.04.1 64位操作系统,随机选择100个初始种子文件,采集10万个样本。基于Tensorflow 1.7.0机器学习框架,分别使用LSTM和GRU构建了2层循环神经网络,初始学习率为0.000 05,隐藏层节点数64,batch_size为16,训练10轮次。模型训练环境为:Intel(R) Core(TM) i7-2600 CPU @ 3.40 GHz CPU,32 G内存,Ubuntu 16.04.1 64位操作系统。
DL-AFL确定性阶段以50%的概率跳过不在关系数组中的位置,非确定性阶段以70%的概率在关系数组中选择变异位置及变异长度。随机选择初始种子,分别用AFL和DL-AFL测试24小时,测试环境主机配置与训练环境相同。下面从四个方面对比测试结果。
3.1 训练样本生成能力
为测试Sampling-AFL取样速度,分别以2个节点,4个节点,8个节点,10个节点构建分布式取样模型,以bmp2tiff为被测对象,与相应数量的独立节点进行24小时取样速度对比,对比结果如图4所示。可以看出,两种模式取样总数都与节点数成正比;而分布式取样由于进行了统一调配,减少了各个节点独立维护队列及随机变异阶段的变异,其单个节点的速度快于独立节点。随着总节点数的增多,分布式取样模型的优势也愈加突出。
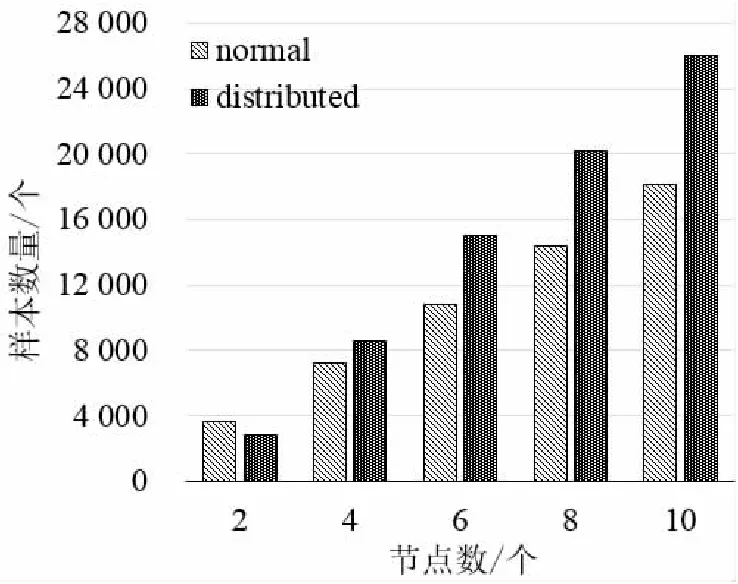
图4 取样速度对比
3.2 路径数量提升
在相同测试环境下,用DL-AFL与AFL对相同的程序对象进行测试,执行路径数量变化情况对比如图5所示。
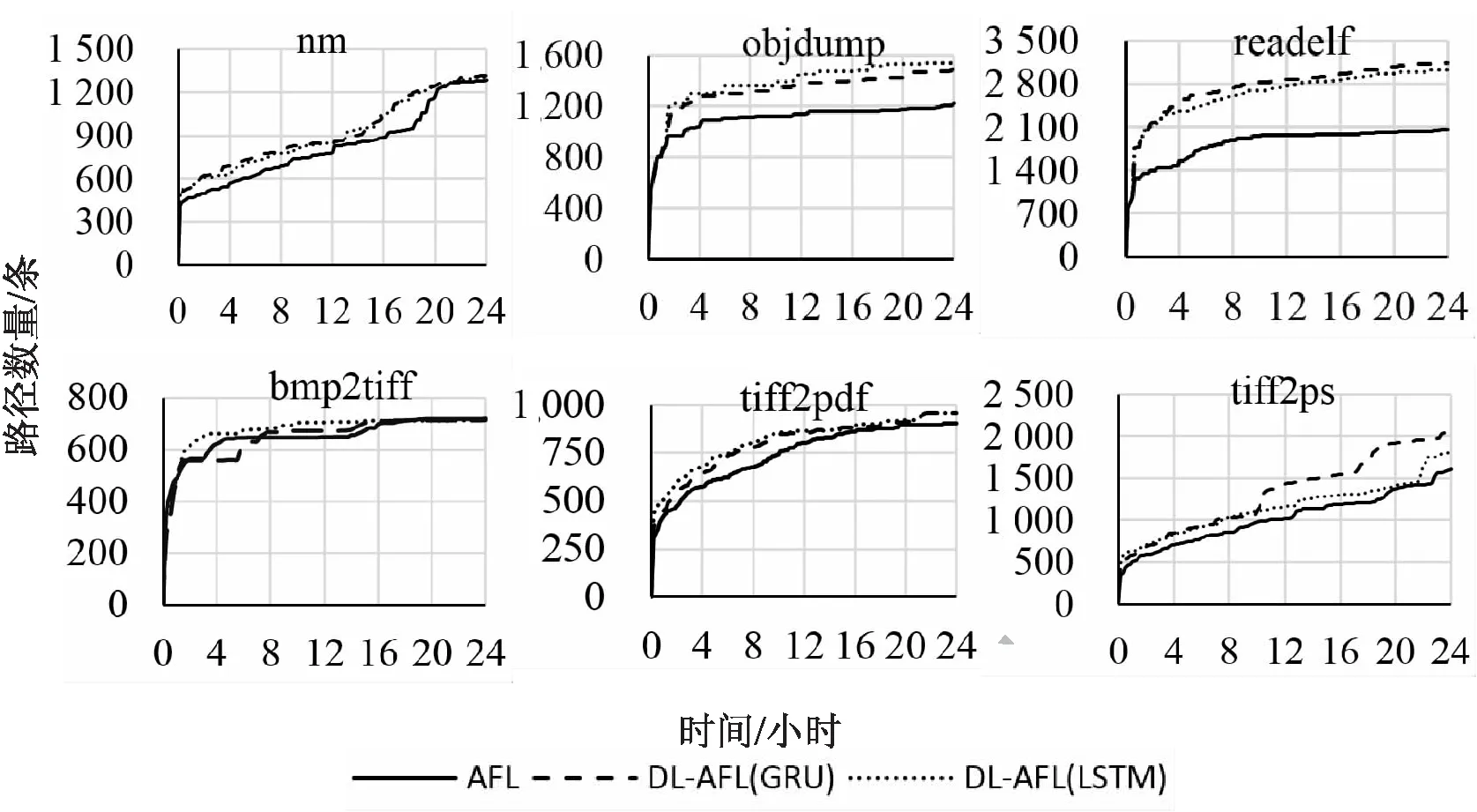
图5 路径数量对比
可以看出,所有被测程序在24小时内,测试效果都有不同程度的提升。其中对于nm、readelf、objdump、tiff2pdf和tiff2ps等5个被测程序,DL-AFL测试发现的路径总数及路径发现速度相比AFL都有较明显的提升,尤其是objdump、readelf及tiff2ps提升极为显著,分别提升25%、50%和15%以上;nm、tiff2pdf有略微提升,分别提升了4%和5%以上,而bmp2tiff只在测试速度上有一定的提升,但在路径总数上却略微低于AFL,原因可能是nm、tiff2pdf、bmp2tiff程序结构相对简单,程序复杂执行路径较少,通过正常AFL变异过程便足以覆盖大多数路径。此外,测试时所用种子文件较小,变异空间小,此时大概率地针对预测区域变异,会导致某些不在预测区域位置的有效位置被变异的概率减小,从而影响测试效果。
3.3 边覆盖率提升
代码覆盖率是衡量测试过程中被执行过的不同边的数量的指标,是反映测试效果的重要指标之一。DL-AFL与AFL测试代码覆盖率情况对比如表1所示。DL-AFL和AFL在代码覆盖率上的表现与路径数量上的表现基本一致,前者均略高于后者。唯一不同的是在bmp2tiff的测试结果中,虽然AFL测试发现总路径数多于DL-AFL(LSTM),但覆盖率却低于后者。
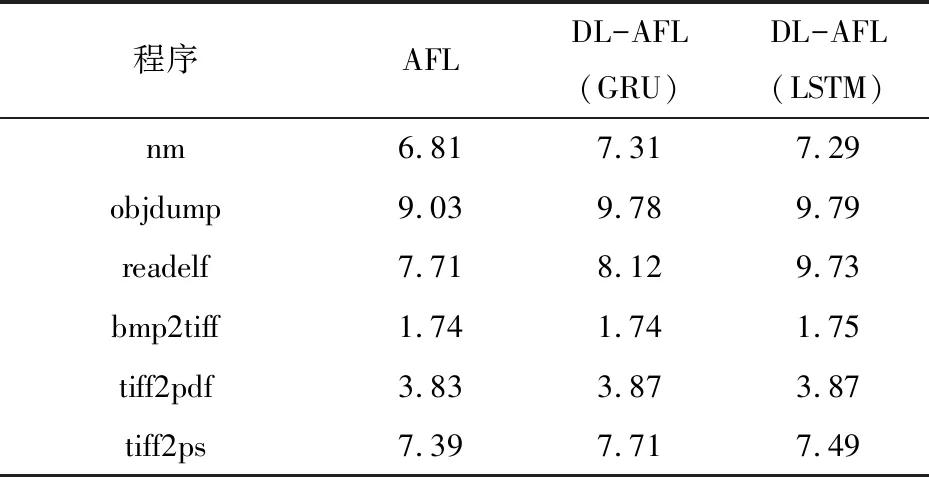
表1 代码覆盖率对比 %
3.4 bug发现能力提升
测试过程中发生崩溃往往预示程序可能存在错误,因此,测试过程中出现的崩溃数量是Fuzzing测试的关键指标之一。
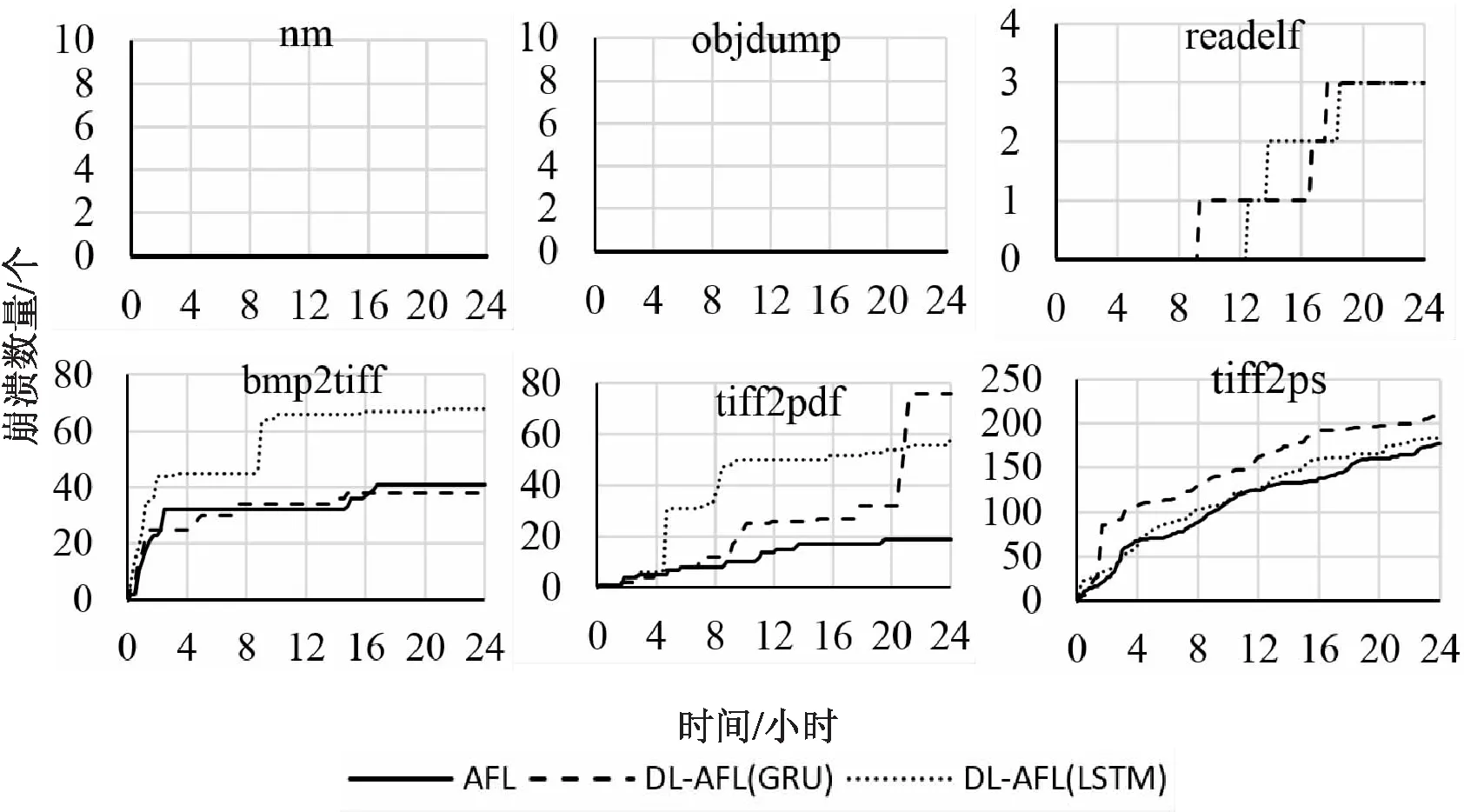
图6 崩溃数量对比
图6为DL-AFL与AFL在相同测试环境下,6个被测程序24小时发生崩溃的数量变化对比。可以看出,在nm、objdump测试过程中均未发生崩溃,readelf、tiff2pdf、tiff2ps三个程序测试结果显示,DL-AFL相对于AFL,检测出的崩溃均有较明显的提升。在bmp2tiff的测试中,DL-AFL(LSTM)检测出的崩溃数量明显高出其他二者,DL-AFL(GRU)略低于AFL。
表2为AFL、Vuzzer及DL-AFL在相同测试环境下,24小时内检测出的bug数量对比。可直观地看出DL-AFL检测出的bug数量多于AFL与Vuzzer。
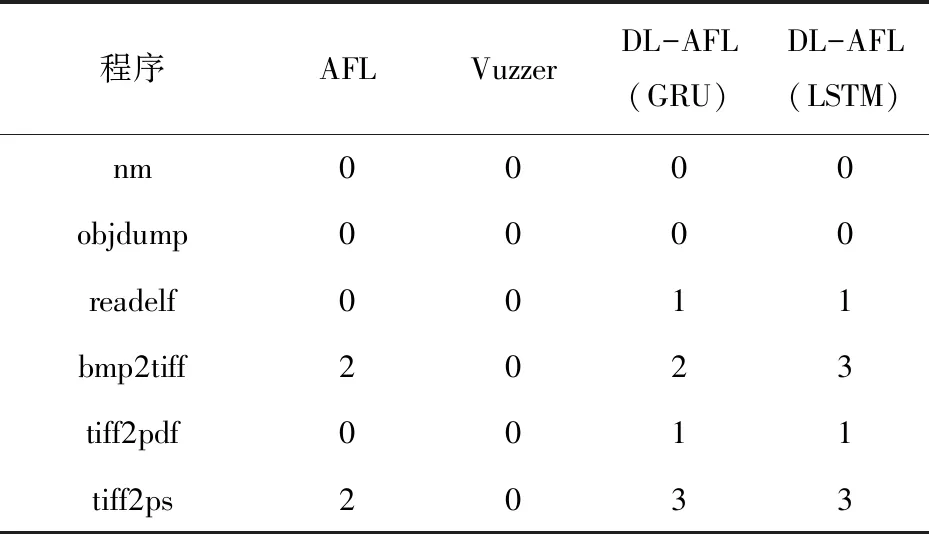
表2 bug数量对比
综合以上对比数据可以看出,通过深度学习方法预测指导的DL-AFL相较AFL测试效率普遍有所提升,从而表明文中提出的方法可以有效提升Fuzzing测试变异的准确率及测试效率。
4 结束语
针对模糊测试过程中测试用例生成过于随机而严重影响测试效率的问题,在AFL模糊测试框架的基础上,提出了基于重点变异区域智能识别的二进制程序模糊测试技术。利用历史测试数据通过深度学习方法训练重点变异区域预测模型,并将预测模型与模糊测试相结合构建模糊测试框架DL-AFL,以预测结果指导种子变异过程,减少无效测试用例生成,从而提升测试效率。通过与AFL在多个通用程序上的实验对比,证明该技术能有效提升模糊测试效率。下一步计划从提升并行规模、缩短采样及训练时间、提升重点变异区域智能识别模型的通用性,以及通过反馈式迭代训练以进一步持续提升变异区域识别精准度等方面开展深入研究。
猜你喜欢
计算机应用与软件(2021年10期)2021-10-15
支部建设(2020年15期)2020-07-08
小型微型计算机系统(2020年5期)2020-05-14
计算机与生活(2020年5期)2020-05-13
火力与指挥控制(2020年1期)2020-03-27
科技创新与应用(2020年6期)2020-02-29
现代电子技术(2016年23期)2017-01-12
百科知识(2015年18期)2015-09-10
小星星·阅读100分(高年级)(2015年4期)2015-05-26
雕塑(1996年4期)1996-07-12
