
基于Apriori算法的拆零货架储位优化分析
2019-09-27 13:35:15李晓柯梁玥杨陨菽
中国市场 2019年27期
李晓柯 梁玥 杨陨菽


[摘 要]现代电商物流中心虽然引进了各类智能设备,但传统的储位设计有待更新,智能设备与传统储位布局之间的冲突使得仓储作业效率低下、成本高昂。基于Apriori算法对现代电商物流中心的储位优化构建了简单的关联模型,通过挖掘的关联规则对商品储位进行优化,以提高仓储中心的运作效率。
[关键词]储位优化;关联分析;Apriori算法
[DOI]10.13939/j.cnki.zgsc.2019.27.181
1 引 言
在电子商务行业高速发展的大趋势下,消费者的需求日益凸显出“小批量、多品种、高频次”的特点,由此对物流行业提出了更高的要求。为了满足消费者个性化需求,促进电子商务的发展,在互联网和人工智能技术的支持下,电商仓储中心日趋“智慧化”——分拣机器人、自动导引车等先进设备的引进与使用都为仓储作业的效率带来了极大的提升。本文主要就电商仓储中心拆零货架区智能搬运机器人“货到人”的拣选模式进行讨论。在原有的储位设计条件下,智能搬运机器人行走的路线多重复耗时,且搬运频次较高,进而增加了仓储作业成本。利用关联分析可优化该区域的储位设计,进一步提高仓储作业的效率,降低仓储作业成本,同时有利于提高消费者响应速度。
2 方法介绍
2.1 关联规则
关联规则是形如X→Y的蕴含式,是在同一件事物出现不同项的一种关系。
定义1:设I=(i1,i2…,ik),是项目集合,D=(t1,t2,…,tk)为事物数据库,其中每个事物(Transaction)t是I的非空子集,即tI,且每一个事物都与一个唯一的标识符TID(Transaction ID)对应。因此关联规则可以表示为X→Y的逻辑蕴涵式,其中XI,YI,且X∩Y=。
定义2:关联规则X→Y支持度(Support)是事物数据库中包含X∪Y的事物占事物数据库D的百分比,即P(X∪Y);关联规则X→Y置信度(Confidence)是事物数据库中包含X事物同时包含Y事物占事物数据库的百分比,即P(Y∣X)。即
Support(X→Y)=P(X∪Y)
Confidence(X→Y)=P(Y∣X)
支持度代表了规则的出现频次,而置信度代表了规则是否重要的可靠程度。在挖掘关联规则时通常会设定支持度和置信度的阈值,即最小支持度(min_support)和最小置信度(min_confidence),当同时满足支持度和置信度的阈值时,则称该关联规则为强关联规则,即该关联规则是有价值的。
2.2 关联规则挖掘
2.2.1 高频项目组
高频项目组指某一项目组发生的频率在事物数据库中达到某一水平,即满足最小支持度。满足最小支持度的称为高频k-项目组。算法将从高频k-项目组中再产生(k+1)-项目组,直到无法再找到更长的高频项目组为止。
2.2.2 产生关联规则
在高频k-项目组的基础之上产生关联规则,若一个规则达到置信度阈值,即满足最小置信度,则称此规则为关联规则。
2.3 Apriori原理
Apriori(拉丁语“来自以前”)算法是典型用于挖掘关联规则的频繁项集算法,是由R Agrawal和R Srikant于1994年提出的为布尔关联规则挖掘频繁项集的原创性算法。
Apriori算法的核心思想是利用频繁项集的先验性质(Prior Knowledge)或称频繁项集的反单调性,即频繁项集的非空子集一定是频繁的,通过逐层搜索的迭代方法寻找频繁项集,即将k-项集用于探索(k+1)-项集,以此穷尽数据集中的所有频繁项集。首先计算1-项集中的候选集C1,即候选1-项集,从C1中找出频繁1-项集L1;根据频繁1-项集计算候选2-项集C2,从C2中找出频繁2-项集L2,…,依次迭代,直到某个k值使得频繁k-项集为空时停止。每找一个频繁项集LK都需要扫描一次数据库,Apriori算法通过前述的先验性质来减缓搜索的速度。
2.4 Apriori算法伪代码
整个Apriori算法的伪代码如下:
当集合中项的个数大于0时
构建一个k个项目组成的候选项集列表
檢查数据以确认每个项目都是频繁的
保留频繁项集并构建k+1项组成的候选项集列表
数据集扫描的伪代码如下:
对数据集中的每条交易记录tran
对每个候选项集can
检查一下can是否是tran的子集:
如果是,则增加can的计数值
对每个候选项集:
如果其支持度不低于最小值,则保留该项集
返回所有频繁项集列表
3 算例分析
本算例主要用于优化在小件拆零拣选区中的储位设计,利用Apriori算法对订单进行相关分析,挖掘其中蕴含的关联规则,从而对商品储位进行优化。为简化算例过程,此处仅分析两种商品之间的关联关系。
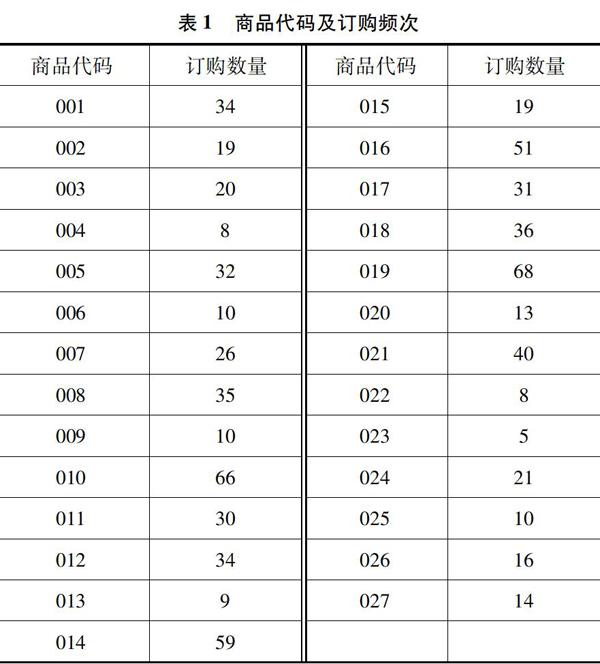
某电商物流中心一周内的历史有效订单共3344条,其中包括8种品类。本算例选取其中的休闲食品为代表展开相关分析。
如表1所示,在休闲食品品类中的27种商品一周内的有效订单情况,此处设置最小支持度(min_supprot)=0.03,最小置信度(min_confidence)=0.4,同时为了简化计算演示过程,此处只讨论频繁2-项集情况。由于考虑到数据较为复杂,数据量较大,这里借助Python语言环境实现对关联规则的挖掘。
在最小支持度为0.03的条件下,得到表2中13种满足要求的商品,即频繁1-项集(L1)。又对这些商品重新命名为X1,X2,…,X13,生成候选2-项集(C2),在此基础之上产生频繁2-项集(L2)。
由此根据算法结果分析应把表3所述的几种商品存储在同一小件拆零货架,以此减少智能搬运机器人行走路线重复的概率,提升分拣搬运效率,降低仓储作业成本。
有时某些商品尽管被订购的频率较高,但数量很少,还应对关联分析模型进行优化,即加入数量权重,使挖掘出的关联规则更有价值。但此处为简化讨论,暂不将数量权重考虑其中,仅讨论简单关联规则下对储位进行优化的策略。
4 结 论
本文基于Apriori算法对电商物流中心小件拆零区的储位进行优化设计,以此配合智能设备的高效运作。根据商品的关联规则,重新安排储位,提高仓储作业的效率,降低运营成本,更能提高对于消费者需求的响应速度。本文所构建的模型较为简单,虽然在Python构建了Apriori算法,但由于数据量较大,程序运行速度较慢,后期还可以改进为使用FP-growth算法来提升寻找频繁项集的效率,处理更大的数据量。同时优化模型加入数量权重,使得简单的关联规则更有现实意义和价值。
参考文献:
[1]崔妍,包志强.关联规则挖掘综述[J].计算机应用研究,2016,33(2):330-334.
[2]段玉晓.基于Apriori关联规则的信息技术相关股票数据分析[J].科技经济导刊,2018,26(31).
[3]张志勇,张新辉,刘杰.基于Apriori算法的关联规则挖掘在配送中心储位规划中的应用[J].物流工程与管理,2012,34(4):56-59.
猜你喜欢
江苏农业科学(2016年8期)2017-02-15 19:19:29
江苏农业科学(2016年8期)2017-02-15 19:19:15
计算机应用(2016年12期)2017-01-13 20:09:35
计算机应用(2016年12期)2017-01-13 20:03:15
电子技术与软件工程(2016年22期)2016-12-26 12:55:09
软件导刊(2016年11期)2016-12-22 21:58:16
电子技术与软件工程(2016年20期)2016-12-21 11:19:58
中国市场(2016年36期)2016-10-19 04:10:44
科技视界(2016年15期)2016-06-30 12:43:00
电脑知识与技术(2016年4期)2016-04-11 13:35:23
