
基于校园一卡通的数据挖掘应用研究
2019-09-26 05:55钮永莉冯胜安贾红雯
信阳农林学院学报 2019年3期
钮永莉,冯胜安,贾红雯
(滁州职业技术学院 信息工程系,安徽 滁州 239000)
随着高校信息化建设的发展,校园一卡通系统应运而生并应用于校园管理的各个领域,包括饮食消费、图书借阅、超市、洗浴、用水用电等。其中,食堂消费数据是最为稳定和准确的,能够很好地反映出大学生在校的消费行为[1]。 对一卡通数据的挖掘,有助于学生管理和学校的管理决策,如对困难学生和助学金的辅助认定,对学生食堂的智能管理等。
虽然困难学生认定和国家助学金评定体系日益完善,但依然存在一些不尽如人意的地方,如认定过程不够科学,客观性不够等[2]。因为目前学校认定困难学生和发放助学金主要依赖困难家庭调查表和同学评价,考虑到人为因素,有时难免会发生一些不公平现象,造成部分需要受资助的贫困学生未得到资助,而少数不需要资助的学生得到补助。因此,如何更好地完成精准资助就成为亟待解决的问题。使用学生一卡通消费信息的挖掘,可以及时掌握学生在校消费情况,为贫困生认定和助学金发放提供辅助决策。
1 数据挖掘
数据挖掘(Data mining)是一门新兴的交叉学科,是指从大量的、有噪声的、模糊的数据中通过算法提取隐含在其中的信息的过程。按照挖掘的知识类型分类,数据挖掘可分为特征规则挖掘、聚类规则挖掘、关联规则挖掘等。对于校园一卡通数据,使用聚类挖掘方法较为适合。数据挖掘的基本过程通常包括定义目标、数据收集、数据预处理(数据清洗-去掉脏数据、数据集成-集中、数据变换-规范化、数据规约-精简)、挖掘建模(分类、聚类、关联、预测)、模型评价与发布等[3]。
2 聚类分析
聚类分析作为数据挖掘技术中的重要方法,是一个无监督的学习过程,聚类方法有很多,其中模糊聚类是将模糊数学和聚类方法相结合的算法,被广泛使用在社会生活的各个领域,特别适用于具有模糊特征的数据分类中。对校园一卡通数据的使用刷卡次数和刷卡金额等属性进行分类时具有明显的模糊特性,即数据对象的亦此亦彼的特点,因此我们使用模糊聚类方法对学生样本进行分类。模糊聚类中最经典的是模糊C均值算法(FCM),但传统的FCM算法有对噪声数据敏感且易陷入局部极小值缺点[4]。因此,本文对FCM算法进行改进,使之更加适合校园一卡通这类样本量较大的数据挖掘问题。
2.1 FCM算法
模糊C均值(FCM)算法是在普通聚类的基础上,由Dunn提出并由J.C.Bezdek推广发展的一种聚类算法,它通过优化目标函数得到每个样本点对所有类中心的隶属度,从而决定样本点的归类[5-6]。假设一个给定的样本集合为X={xi,i=1,2Λn},n为样本总数,xi为k维向量,将样本集X划分为c×n的矩阵U={μij},μij是第j个样本对第i类的隶属度。
(1)

(2)
假设V={vi}是聚类中心,其计算方法如下:
(3)
其中,dij=‖xj-vi‖为样本与聚类中心之间的距离,一般为欧式距离;m为模糊加权指数,且m>1,用来控制分类矩阵U的模糊程度。
(4)
FCM算法采用误差平方和函数J(u,v)作为目标函数,通过式(2)和式(3)的迭代计算隶属度矩阵U和聚类中心V,使目标函数J(u,v)的差值不断减少直至达到一个事先约定的误差ε,则循环停止,获得最终的隶属度矩阵和聚类中心,即聚类结果。
2.2 改进的FCM算法(DWFCM)

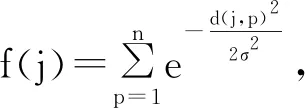
(5)
为使该目标函数达到最小值,构造拉格朗日函数如下:
(6)

公式(7)
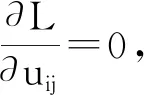
2.2.2 算法步骤 改进后的算法(DWFCM)其主要步骤为:
步骤1:参数初始化,包括类别数c,参数m,迭代终止条件(最大循环次数K,允许误差ε),初始聚类中心等[7];
步骤3:用值在[0,1]之间的随机数初始化隶属度矩阵U并满足公式(2);
步骤4:根据公式(7)计算聚类中心vi;
步骤5:根据公式(5)计算目标函数的差值;此时如果差值小于事先给定的误差值ε或迭代次数大于K,则结束循环;
步骤6:否则根据公式(1)计算出新的隶属度矩阵,并转步骤4。
3 一卡通数据应用
本文的数据挖掘处理过程如图1所示:先获取学校的一卡通消费数据,再进行数据预处理,然后使用改进的FCM算法(DWFCM)进行聚类,最后结合学校的困难学生认定政策,给出困难学生参考名单,为助学金和其他奖金发放提供理论支持。
图1一卡通数据挖掘与分析过程
3.1 数据获取
本文数据采集于我校校园一卡通系统数据库,包括新校区所有在校学生的一卡通消费信息,时间:2017.9.1~2018.6.30。因涉及到学生隐私问题,因此只采集并保留数据挖掘所需的必要字段,如学生的学号、所在系、专业、刷卡日期、刷卡时间、刷卡地点、刷卡金额、圈存信息等。
3.2 对学生消费数据的预处理
原始提取的信息可能存在噪声、冗余等,因此要进行后续的分析和挖掘工作就必须对数据进行预处理。数据预处理的方法主要包括数据清洗、数据集成、数据变换和数据规约等。
3.2.1 数据清洗 数据清理的方法主要包括对缺失值的处理、噪声数据的处理等。首先一卡通中包含了教职工、学生等各种人员的数据,应只保留学生数据;对于服兵役、休学、退学、开除等原因引起的缺失数据样本也应删除;而一卡通消费中的开水消费和洗浴消费由于对困难家庭认定意义不大,因此也一并去除。因学校助学金发放是按照不同年级遵循一定比例,因此我们以2017级学生为例进行研究,可以为2018-2019学年的困难学生认定和发放国家助学金提供辅助意见。其他年级方法相同。
3.2.2 数据集成 不同系统或数据表中的数据应根据需要进行集成,保持数据格式和内容的一致性[8]。由于本文用到的数据来源于不同的数据库表,因此需要将不同数据表的数据整合到一起,方便研究。如消费表中只有学工号而非学号,因此需要在学号表中找到学工号和学生真实学号的对应关系,便于将聚类结果对应到学生学号。
3.2.3 数据变换 为了提高挖掘的效率和维度,让数据分析更容易实现,对学生消费记录中的就餐时间格式进行分析后拆分,使之转换为刷卡的月份、日期、时间等详细属性。
3.2.4 数据规约 针对本次数据挖掘的目标,对那些与挖掘目标无相关性或弱关联的属性,应选择放弃,如学生的身份证号、电话、家庭住址以及卡号、余额等。由于数据库中的消费数据是每次刷卡记录,为了更加贴近学生的真实消费水平,本文对学生的月均消费情况进行挖掘分析。根据数据变换的结果整理出每位学生的总刷卡次数和总的消费金额,根据学生的在校情况,用均值方式得出月均刷卡数和月均消费额,从而大大缩小数据量,提高挖掘的效率。
通过以上数据预处理过程,可以使待挖掘的数据合乎规范且精简,为以后的数据分析和挖掘建模奠定良好的数据基础。
4 挖掘建模及决策建议
为研究学生在校消费水平,本文使用FCM和改进的FCM算法(DWFCM)分别对数据进行聚类并进行比较,数据集包括的属性有学号、月均消费金额和月均刷卡次数。实验软件采用Python3.7,编程环境是PyCharm 2018.3.4 Community Edition。参数设置为:模糊指数m=2.0, =0.0001,最大迭代次数K=50,分别取分类c=3,4,5进行多次试验,对得到的聚类结果进行比较发现:当分为5类时,能更好的区分两类极端群体,因此类别取5类。FCM算法对初值的依赖很强,当初值选定不理想时,可能会导致聚类效果不佳,得到的最终聚类中心与实际有一定差距。而DWFCM算法使得密集区域内的样本点权重高于稀疏区域的样本点,并更新了目标函数,这样不但有利于找到更合适的聚类中心,还可加快聚类中心迭代的速度,取得更好的聚类效果,优化算法的性能。
FCM算法和DWFCM算法的聚类中心和分类结果分别如图2和图3所示。当学生的月刷卡数较高且月消费额较低时,属于困难家庭学生的几率比较大。图2的五个聚类均不符合这一要求,而图3中的第0个聚类应属困难家庭学生簇;其聚类中心为(82.2393,401.2936),即月刷卡次数82次,月消费额401元,符合上述特点;且23.4%的比率也较为符合我校助学金发放现状。对这些学生在进行困难家庭认定时应着重注意,避免漏选;而对于那些虽然有困难家庭调查表但在校消费较高的同学(第4簇)也应着重调查,避免错选。
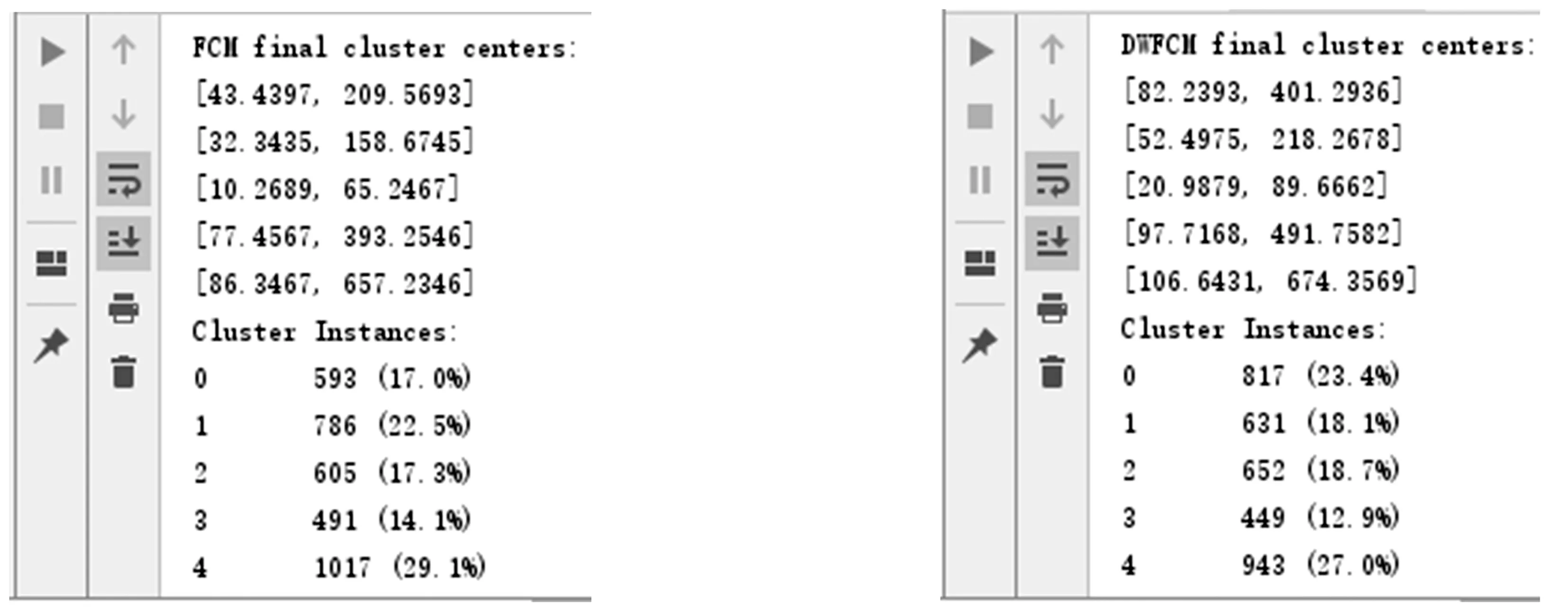
图2 FCM算法聚类中心与结果 图3 DWFCM算法聚类中心与结果
由图可见,改进后的DWFCM算法无论是聚类中心还是聚类结果都比FCM算法更优,更符合学校困难学生认定现状。将该模型与学校现有的贫困生认定方法相结合,可以提高贫困生认定覆盖率,最终达到精准资助的目的。
5 结语
本文针对一卡通食堂消费数据挖掘提出了一种改进的模糊C均值算法(DWFCM算法),可以为贫困生认定和助学金发放提供客观数据支持。依据一卡通食堂消费数据,还可以研究消费高峰期与食堂开放窗口数量的关系,从而及时调整食堂管理措施。除此之外,一卡通系统中包含的用水信息、洗澡信息等还有助于学校的水房管理、浴室管理,这些都有待于今后进一步的研究。
猜你喜欢
电子制作(2016年19期)2016-08-24
小学生·新读写(2016年5期)2016-05-14
新高考·高一物理(2015年5期)2015-08-18
奥秘(2014年8期)2014-08-30
疯狂英语·口语版(2013年9期)2013-10-12
物流科技(2010年2期)2010-12-31
故事作文·低年级(2009年7期)2009-11-23
