
基于群体化的开源软件推荐问题研究
2019-09-24 07:20:40陆国浩
沙洲职业工学院学报 2019年2期
陆国浩
基于群体化的开源软件推荐问题研究
陆国浩
(沙洲职业工学院,江苏 张家港 215600)
利用因子分解机(Factorization Machines,FM)模型,提出了一种在群体参与平台上对开源软件的推荐方法。通过抽取开源软件的文字、代码和标签等特征信息加入模型中训练,以机器学习的结果完成推荐。利用码云网站实例分析开发者对开源软件的行为,建立开发者对开源软件感兴趣评级,并生成使用者与开源软件的关系矩阵作为学习目标。实验表明,与传统的推荐方法协同过滤相比,所提出的方法在平均精确均值(Mean Average Precision, MAP)、召回率(Recall)与F1分数(F1 Score)三个评估下都有较优秀的表现。
开源软件;因子分解机;软件推荐;群体化平台
引言
近年来,推荐系统领域的研究取得了很大程度的进步。目前的推荐方法大多基于使用者间的信任关系与交互活动进行。中小企业在提高自身的信息化能力时,对开源软件有显著的需求。提高开源软件的有效推荐、获得更合适的开源软件对中小企业的信息化发展具有十分重要的意义。
开源软件一般在群体化网络平台上,如:Github、SourceForge、Gitee、OpenHub等,使用者开始在群体化平台上与其他使用者共同实作或是分享想法,以实现共同的工作目标。在码云上,这些共同的目标通常通过共同完成某个开源软件版本来实现。通过提出使用者产生的文档与源码(Source code)中撷取特征[1],并将这些背景特征整合到传统的协同过滤(Collaborative Filtering)和基于内容(Content-based)推荐方法中,完成对开源软件的推荐。
1 推荐系统现状
推荐系统已经被广泛使用在商业中。在推荐模型框架中,协同过滤是最受欢迎的模型之一。协同过滤模型会过滤没有意义且不重要的信息,并保留下相似且有意义的模式来预测使用者行为与喜好。近年来,机器学习的技术提供了有潜力的方式来执行推荐,除了协同过滤与基于内容过滤的方法,还有将两种方法结合的混合式方法。通过因子分解机(Factorization Machines)方法,物品或使用者之间的相似性通常透过物品和使用者表示的特征向量来测量,这种混合式推荐方法更适合于开源软件的推荐[2]。
1.1 推荐系统
1.1.1 协同过滤
协同过滤的方法是收集大量有关使用者的行为,基于类似的使用者去预测其他使用者可能也感兴趣的信息。这种方法基于使用者过去感兴趣或是偏好,去假设未来的使用者在类似事物上的行为表现。许多演算法用于推测推荐系统中使用者与物品之间的关系。例如,k个相近的邻居(k-nearest neighbor)。协同过滤优点在于,即使不了解音乐的内容,依然可以向使用者推荐播放清单。概念是先由群体化平台上,使用者与物品之间的喜好关系建立起社群网络图,再将网络图由使用者与物品的矩阵表示,最后寻找与被推荐使用者拥有相同喜好的使用者,并将此使用者在被推荐对象没有的喜好来进行推荐。
1.1.2 基于内容过滤
基于内容过滤主要是透过物品的内容资讯来进行推荐。基于内容过滤目标,是尝试依照使用者过去感兴趣的物品去推荐使用者也可能感兴趣的新物品,概念类似协同过滤。但在过程中,我们撷取物品中有用且具有参考价值的特征(如:文字信息等),转换成向量空间的特征表示形式。然后,透过对物品的评分来建立出一个经使用者产生的物品列表。通过这些特征向量的信息去寻找有相似特征的物品,将这样的新物品视为使用者可能感兴趣的物品进行推荐。
1.1.3 混合型机器学习算法
基于文字内容过滤的方法是基于使用者或物品个别信息,它缺乏考虑其他使用者过去的使用经验,因此缺乏对于物品质量、风格、观点与类似使用经验使用者的交互影响。另外,它缺少使用者的个性评估。为了解决以上这些缺点,透过结合了协同过滤的方法得到了改善,因而衍生出了混合模式的算法[3]。
实验表明,更进一步探究使用者与使用者(User-User)、物品与物品(Item-Item)甚至是使用者对物品(User-Item)的交互关系,透过协同过滤的方式,建立起使用者与使用者经由物品建立起来的复杂关系,加上基于内容过滤的概念,从中撷取出重要且具有影响力的特征加入模型训练当中,使得最终推荐结果有更卓越的表现。
大多最近的混合模式算法的研究,都是将协同过滤与基于内容过滤的方法相结合。协同过滤的目的是过滤涉及多人和数据源之间的协作的信息或模式(Patterns)。因子分解机是目前最先进的方法之一。该算法已经成为推荐系统中主流的技术,因为它不仅能够模拟协同过滤的方法,且更能够方便地将辅助信息加入模型中学习。
1.2 因子分解机
在分解机器中,有一个是记录使用者与物品之间的类别或级别(在我们的方法中,定义为感兴趣的程度)的关系矩阵。由于大多群体化平台上的数据稀疏导致没有评级。为了克服这个问题,分解机产生一个交互矩阵来表示未知的等级。例如,使用者A听了音乐X,但没有听音乐Y,交互矩阵可以模拟所有使用者和所有物品之间的等级。然后,分解机可以记住使用者A对音乐Y感兴趣。根据这个框架,可以由使用者与物品的关系矩阵来表示社群网络。我们将评级视为使用者和物品之间的关系。例如,如果使用者A喜欢或共享来自使用者B的音乐,则在使用者与物品的关系矩阵中记录。换句话说,这意味着使用者B透过该音乐影响了使用者A,我们认为交互矩阵模拟的价值是在于潜在的影响力。
许多研究试图从各式各样的资讯(例如:位置或天气)来模拟使用者行为。现今有大多数基于矩阵因子分解(Matrix Factorization)的技术,它将使用者对物品的矩阵扩散成张量形式({使用者,物品,上下文}三元组成)用于上下文推荐[4]。本文尝试透过使用者生成的文字信息与在群体参与平台上的互动关系建模。为此,采用基于矩阵因子分解的演算法,分解机器作为学习框架,它可以从异质的来源中提取大量的特征[1]。例如,从群体参与平台上,物品在协作平台上的被定义领域特征和相关文字特征信息。分解机器已被证明是近年来各种推荐任务下最灵活且具有竞争力的模型。
2 开源软件推荐系统的实现方法
2.1 一般的分解机器
分解机器(FM)可以透过各种类的特征来达到一般分解模型的效果。它能够学习特征之间所有的交互权重,一般来说的分解机器可定义为式(1):
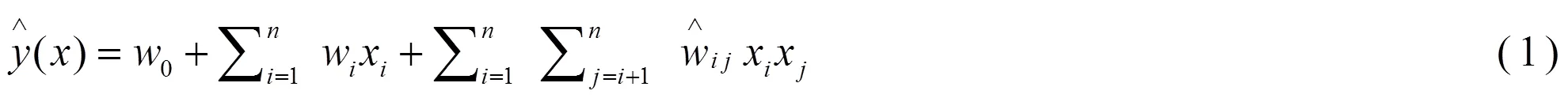
式中为目标函数,为全局偏差,是特征值的权重,模拟每对特征值之间的交互作用。
2.2 群体化平台的推荐框架
协同过滤是推荐系统常被采用的技术。在我们的工作中,保有协同过滤的优势与基于分解模型结合。由于分解机器具有良好的输入特征建模框架,可以直接从使用者和项目中提取出信息,这种方式具有过滤类似的概念,可以容易嵌入到特征向量中。
在开源社区网站码云(Gitee)上,本文通过开源软件(Repository)的信息建立使用者与软件之间的关系矩阵,并将这个关系矩阵当作模型训练时的目标值。在Gitee网站上,选择用于模拟的软件信息,通过四项内容表现。
Star:使用者可以对开源软件进行类似点赞的行为。
Watch:使用者可以对开源软件点击关注。
Fork:使用者可以对开源软件分支到自己的空间进行修改或编辑。
Contribute:使用者可以对开源软件上传自己修改的程序片断,并通过软件原作者认可成为贡献者。
使用者除了点击Star、Fork或是Watch这些较能够表示使用者对物品感兴趣以外,在社群平台上的协作关系也能够表示使用者对物品(Repository)某种程度上的感兴趣,在我们的框架中额外考虑到这种使用者透过物品的协作关系来表达某种程度上的喜好。将这样的资讯加入我们的模型,增加资讯的丰富度,以帮助模型的学习。将使用者感兴趣的程度定义如下:

当F(i,j)为使用者i对j物品的感兴趣程序,s,w,f,c分别为star,watch,fork,contribute的布尔值(对物品j有无此行为),另外β,γ,δ,ε分别为四个类别的权重。使用者与物品的关系如图1。
2.3 基于内容特征
(1)一般的文字特征信息
主要是介绍自己的README.md文件。把这些使用者生成的文字特征加入模型中学习,对软件推荐是有帮助的。但是在gitee网站上的文字信息比较没有规律性。必须要对文件进行前置处理,如采用正规表达式法(Regular Expression)、去除停用字(Stopword)和字根还原(Stemming)等方法。再通过词频(Term Frequency,TF)和逆向文件频率(Inverse Document Frequency,IDF),计算TF-IDF权重来做为单个词的分数,定义为tf(t,d)×idf(t,d)。TF-IDF权重是一种用于信息检索(Information Retrieval)和文本挖掘(Text Mining)中常用的加权技术。TF-IDF权重常被搜索引擎应用,作为文本与使用者之间相关度的评级。
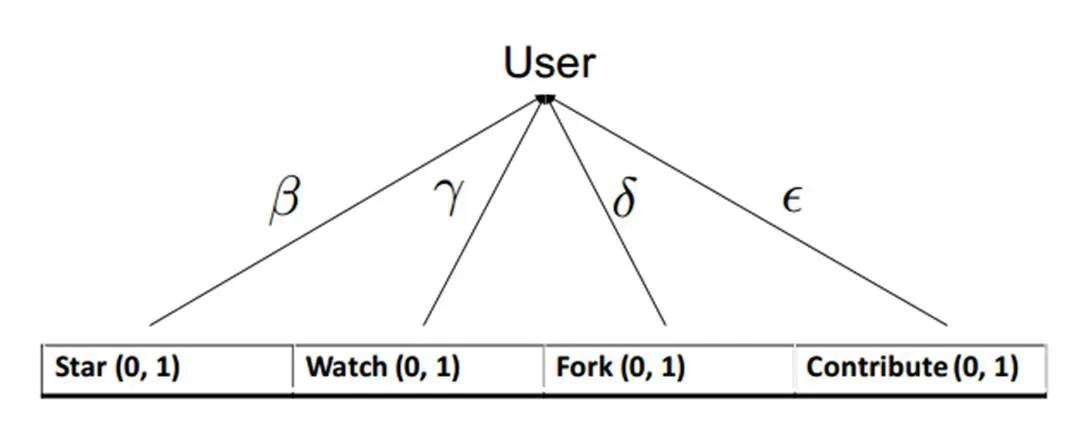
图1 使用者与物品关系图
(2)源代码特征信息
在gitee网站中,主要是分享源代码。源代码也有着标准的格式与限制,相比一般文字来说更为严谨。如,可以分析源代码中引用的函数库片段,作为特征信息。
3 实验结果和评估指标
3.1 评估指标
采用三种常用的评估推荐结果比较的方法。前k个平均精确均值(Mean Average Precision, MAP)、召回率(Recall)和F1分数(F1 score)[6]。对每个开发者,令P(k)为前k个精确度(Precision@k):

当o(p)=i,表示物品i在o列表中被排序在第p个位置,γu i表示开发者u对开源软件产品i是否感兴趣(是为1,否为0)。前k个平均精确均值如式(5):
其中,U表示开发者的集合。k个平均精确均值越高,表示在推荐精度上有更好的表现。
召回率是在评估推荐出来的实例中,是真正属于开发者感兴趣或是喜欢的数量。计算公式如式(6):

高召回率则表示推荐出来的是开发者真实喜欢或感兴趣的实例。
F1分数,是在统计分析中二进制分类(Binary Classification)的精确度测量,通过精确度和召回率来计算得到。它是精确度和召回率的平均值,如式(7):

式中,0≤F1≤1,0为最差,1为最好。
3.2 实验分析
在实验中,通过对矩阵分解时的隐向量维度k来观察不同参数下实验评估分数。初始设定实验的六种参数为2n,当n=1,2, …,6(即k=2,4,8,16,32,64)时,实验对象分别有一般FM、FM+文字特征、FM+源代码、FM+文字特征+源代码的表现。

表1 实验结果
因为在Gitee中,对文字特征部分是没有限制的,可能出现广告或图片等内容,这样使得文字特征部分有很多无效信息,实验结果也说明了只有比较严谨的源代码对软件的推荐才更为有效。
在参数k的敏感度实验中,实验发现随着参数k的增加,对有特性的FM评估结果有所提升。尤其在k=32时,较为明显。MAP、Recall、F1 score评估方法都有类似提升曲线,图2为F1 score评估的关系曲线图。
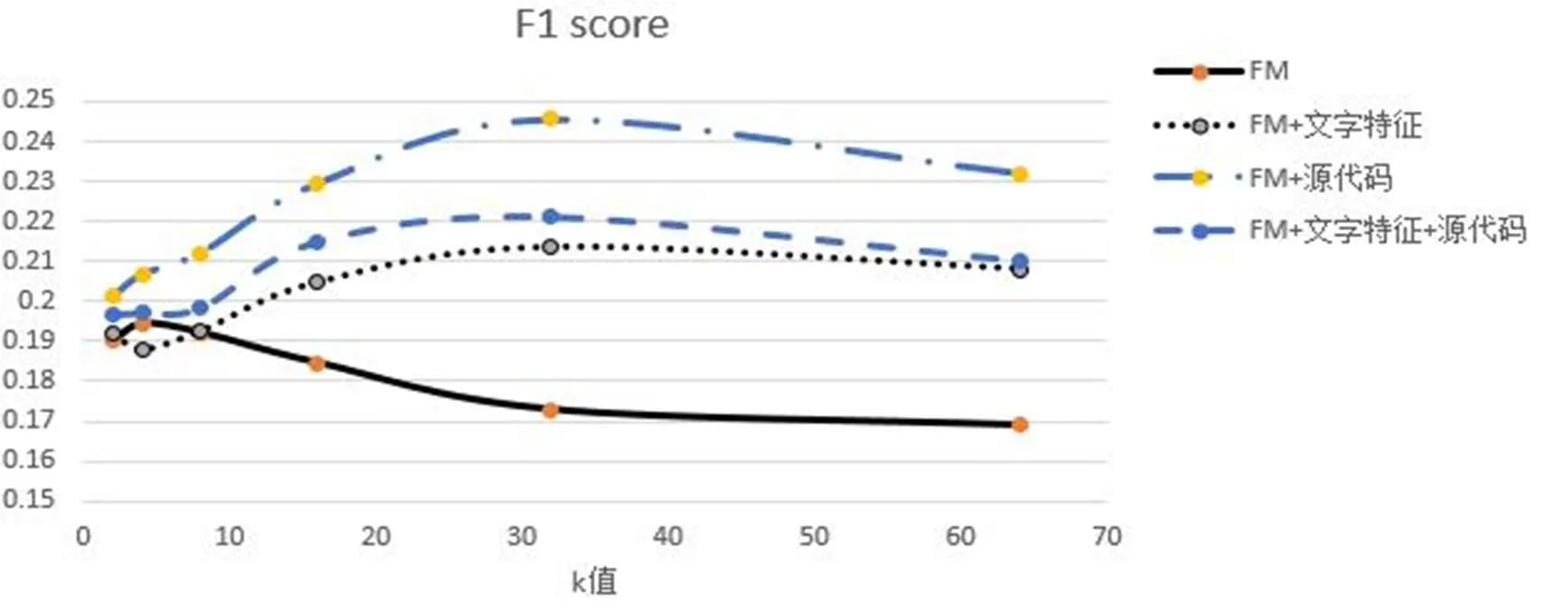
图2 隐向量维度k与F1 score评估曲线图
4 结论
本文提出了一种在群体参与平台上针对开源软件的推荐方法,把协同过滤的优势和基于FM模型相结合。通过文字特性、源代码内容等特征向量,对MAP、Recall、F1 score分析,有利于提升开源软件的推荐结果。这将为开源软件的推广和使用提供借鉴。
[1] Rendle S. Factorization Machines with libFM[J]. ACM Transactions on Intelligent Systems and Technology, 2012, 3 (3):1-22.
[2] Yin G, Wang T, Wang H, et al. OSSEAN: Mining Crowd Wisdom in Open Source Communities[J]. Frontiers of Computer Science, 2018 (10): 923-938.
[3] Llerena L, Rodriguez N, Castro J W, et al. Adapting Usability Techniques for Application in Open Source Software: A Multiple Case Study[J]. Information and Software Technology, 2018 (11): 12.
[4] 尹刚, 王涛, 刘冰珣. 面向开源生态的软件数据挖掘技术研究综述[J]. 软件学报, 2018 (8):2258-2271.
[5] 罗子展. 开源软件社区开发者推荐的研究[D]. 长沙: 国防科学技术大学, 2015: 19-23.
[6] 廖志芳, 李斯江. GitHub开源软件开发过程中关键用户行为分析[J]. 小型微型计算机系统, 2019, 40 (1): 164-168.
Research on Recommendation of Open Source Software Based on Crowd Participation
Lu Guohao
( Shazhou Professional Institute of Technology, Zhangjiagang 215600, Jiangsu, China )
In this paper, a recommending method for open source software on the platform of Crowd Participation is proposed by means of Factorization Machines. The text, code and tags of open source software are extracted and trained in the model, and then the training results of the model are recommended. The behavior of developers on the code cloud platform is used to establish the developers’ interest ratings for open source software, and to generate the user-to-open source software relationship matrix as a learning goal. Experiments show that compared with the traditional collaborative filtering recommending methods, a better performance is realized under the Mean Average Precision, Recall and F1 Score.
open source software; Factorization Machines; software recommendation; Crowd Participation platform
TP391.3
A
1009-8429(2019)02-0016-05
2019-02-20
2017年江苏省高校哲学社会科学研究基金项目(2017SJB1441)
陆国浩(1979-),男,沙洲职业工学院电子信息工程系讲师。
猜你喜欢
计算机仿真(2023年8期)2023-09-20 11:23:42
现代信息科技(2021年21期)2021-05-07 21:44:50
含能材料(2021年1期)2021-01-10 08:34:34
创新作文(1-2年级)(2019年3期)2019-09-03 05:14:07
中国司法鉴定(2018年4期)2018-07-30 06:08:26
办公自动化(2016年18期)2016-08-20 12:50:20
办公自动化(2016年18期)2016-08-20 12:50:18
工业设计(2016年8期)2016-04-16 02:43:24
中国房地产业(2016年8期)2016-03-01 01:25:55
上海理工大学学报(社会科学版)(2015年3期)2015-11-30 03:02:13
