
基于组合DNN的语音分离方法
2019-09-19 10:31:02闵长伟江华闫格2冯利琪
数码设计 2019年2期
闵长伟,江华,闫格2,冯利琪
(1.闽南师范大学粒计算及其应用重点实验室;2.闽南师范大学计算机学院,漳州,363000)
引言
随着社会的发展和科学技术的不断创新,智能手机等智能设备越来越受到普及,人们越发关注和重视人机语音交互技术,并对此进行了一系列研究。但是如何使得人机语音交互变得更加有效和快捷,就像人与人之间相互便捷交流一样成为了近几年比较热门的研究方向。而语音分离是人机语音交互技术的核心问题之一,由于语音信号总是不可避免的受到外围环境的干扰,降低了语音信号的质量,因此语音分离起着非常重要的作用。
语音分离起源于著名的“鸡尾酒会效应”问题[1],就是在复杂的混合语音中把目标语音有效的分离出来。语音分离的研究在语音通信、语音目标检测、语音增强等方面有着非常重要的理论意义和使用价值,语音分离技术在各个领域都被广泛应用,例如语音自动翻译、助听器、移动通信、无线电视电话会议和声源定位等方面[2]。
目前,语音分离技术取得了很大的发展和突破,但是由于实际情况下环境的复杂多变,语音分离技术仍然存在着一些难题急于解决。例如,在我们生活的环境中,大部分应用场合下都只有一个麦克风设备,我们对它的参考信息了解的也不多,对目标语音估计的难度很大,这种情况下的语音分离被称为单 声道语音分离,几十年来,一些专家和学者都在着力研究单声道条件下的语音分离问题,他们提出估计噪音的功率或理想维纳滤波器方法[3]来提高语音分离的性能,由于这是基于信号处理的方法,那些噪音通常假设为平稳的或慢变的,在满足假设条件下,这些方法在语音分离中取得了很好的效果,但是在现实环境中,这些假设条件通常很难满足,特别在低信噪比的情况下,这些分离性能效果可能会没用[4],跟基于信号处理的方法相比,基于模型的方法能在低信噪比的情况下取得很好的语音分离性能,但是它的不足就是过于依赖在之前训练好的语音和噪声模型[5-7],所以研究出在各种实际环境下的语音分离技术就显得尤为重要,本文研究的语音分离的方法也是基于单声道情况下进行的。
近年来,由于深度学习的兴起,各种深层模型被广泛应用于语音领域,取得了巨大的成功[8]。而深度神经网络(Deep Neural Network,DNN)又是典型的深层结构,它在语音分离领域显示出了巨大的研究前景[9-15],日益得到人们的重视。Wang等人提出了一种基于深度神经网络-支持向量机(Deep Neural Networks-Suppore Vector Machines,DNN-SVM)的系统[16],这一系统与传统的系统相比,不但能够在较大的数据集上进行训练,而且还能实现较好的泛化性能。Wang等人又在一篇文章中提出用典型的监督性语音分离系统DNN[17],对监督性语音分离的目标进行侧重分析,解决了适合于有监督语音分离的训练目标这一问题。最近,Le Roux、Hershey和Hsu等把NMF扩展成深层结构,并把这一深层结构运用到语音分离领域中,取得了不错的效果[18-20]。
神经网络是现代人工智能的重要领域之一,由于单个的神经网络存在许多的局限和不足,专家和学者开始用两种神经网络组合进行研究。赵凯通过BP和RBF两种神经网络组合对RD经费的支出进行预测[21],从预测结果来看,两种神经网络组合很好的预测了每年的RD经费支出,避免了单个神经网络预测精确度不高。Vera Simon等人用两种不同的神经网络进行组合来预测化学反应[22],发现两种神经网络组合之后的化学反应效果要比单个神经网络好,XH Song等人用两种神经网络组合对土壤样品源进行解析[23]。虽然DNN具有较强的学习和非线性映射能力,但是还存在着一些问题,比如噪声估计不准确的问题等,因此本文遵循DNN语音分离的系统框架,在此基础上利用两种不同结构的DNN进行组合,试图提高语音的可懂度和清晰度。
1 基于DNN的语音分离方法
语音分离过程可以理解为从含有噪音的混合语音信号到纯语音信号的一个非线性映射函数,这个过程能够很自然地表达成一个有监督性学习问题。监督性语音分离系统的结构框图如图1所示,实验主要分为训练阶段和测试阶段。在训练阶段,首先要把训练的纯净语音和噪声按照一定的信噪比进行混合得到混合的语音,将输入的一维时域信号通过时频分解变为二维的时域信号,然后进行特征提取,提取的特征一般是帧级别或者时频单元级别的听觉特征,将提取的听觉特征和分离目标分别作为语音分离模型的输入和输出来训练模型,直到模型训练完成。在测试阶段,将测试的纯净语音和噪声按照一定的信噪比进行混合得到测试数据集,将测试数据集同样进行时频分解和特征提取,输入到训练模型中估计出测试数据集的语音目标,最后将混合的语音和估计出的分离目标进行波形合成,通过逆Gammatone滤波获得我们想要的目标语音,同时可以根据目标语音的评价指标来验证模型的实用性。
2 基于CE_DNN的语音分离方法
CE_DNN语音分离系统主要分为5大模块:时频分解、特征提取、分离目标、模型训练、波形合成。图2所示概述了在CE_DNN语音分离系统在测试阶段利用DNN训练模型进行测试的一般结构图,该图表示,不同训练集经过训练得到训练模型后,将测试数据放入训练模型后得到的输出结果进行合成,再通过逆Gammatone滤波之后进行波形合成来分离想要的目标语音。
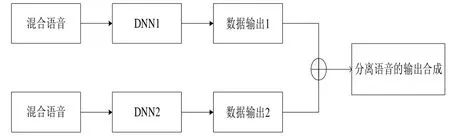
Fig.2 Represents a schematic diagram of the CE_DNN speech separation system
图2 表示CE_DNN语音分离系统的结构简图
2.1 时频分解
时频分解作为语音分离过程中的前端模块,在语音分离过程中,通过时频分解将输入的一维时域信号变成二维的时频信号,本实验中采用的是Gammatone听觉滤波模型[24]来进行时频分解。
Gammatone听觉滤波是将一组听觉滤波器g(t)对输入的信号进行滤波,得到一组滤波输出G(t)。滤波器组的冲击响应为
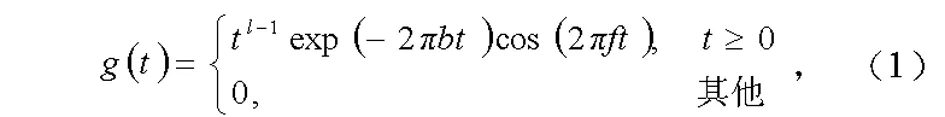

2.2 特征提取
特征提取是语音分离中至关重要的步骤之一,因为提取的特征不但能够减少的训练时间,而且还能提高分离语音的性能。本实验是基于深度神经网络的语音分离,主要用了四种声学特征[25-26],包括相对频谱变换-感知线性预测系数(Relative Spectral Transform and Perceptual Linear Prediction,RASTA-PLP)、幅度调制频谱图(Amplitude Modulation Spectrogram,AMS)、梅尔频谱倒频谱系数(Melfrequency Cepstral Coefficients,MFCC)和伽玛通特征(Gammatone Feature,GF),这些特征都是帧级特征,通过调用MATLAB函数中的combine函数,将这些特征相互组合形成特征集合。
2.3 分离目标
语音分离目标选择的好坏直接关系到合成目标语音的质量。语音分离最常用的分离目标是时频掩蔽,常见的时频掩蔽有理想二值掩蔽(Ideal binary mask,IBM)和理想浮值掩蔽(Ideal ratio mask,IRM)。本实验中选用的分离目标是IBM,IBM是计算听觉场景分析的主要计算目标,由纯净的语音和噪声组合的混合信号计算得到。对于每一个T-F单元,如果局部的SNR大于本地阈值(Local criterion,LC),则将矩阵中相应位置标为1,否则标为0。IBM的公式如下:

其中SNR(f,t)表示时间t和频率为f的T-F单元的局部信噪比值,IBM(f,t) 表示SNR(f,t)对应的时频单元的IBM值,通常本地信噪比阈值LC小于混合语音信噪比5dB。例如混合语音信噪比为-5dB,那么LC的信噪比阈值为-10dB。
2.4 DNN训练
正文内容本实验中,DNN设置一个输入层,四个隐含层,一个输出层,其中隐含层每层有1024个节点,Sigmoid函数作为激活函数,图(3)所示的Sigmoid函数[27]具有连续、光滑等性质。其公式定义如下:

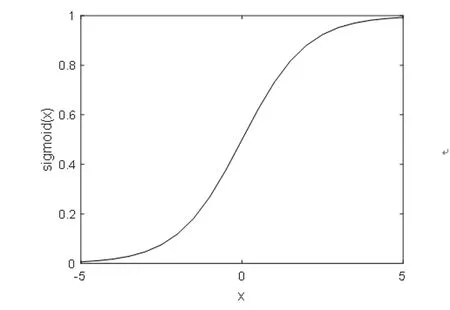
Fig.3 Sigmoid function.
在DNN中,层与层之间的单元是全连接的,即一个神经元节点与相邻层的所有神经元之间都相连。另外,DNN系统经随机梯度下降和交叉熵准则训练,初始学习率设为0.01,系统的最大训练次数设为20,用标准的反向传播算法进行训练。
2.5 模型合成
在DNN训练过程中,针对两个DNN网络使用了两种不同的训练集,训练的结果是得到两个具有不同内部参数的DNN训练模型,将测试数据放入训练模型中进行训练,得到输出结果,最后将得到的输出结果进行合成,其公式如下:
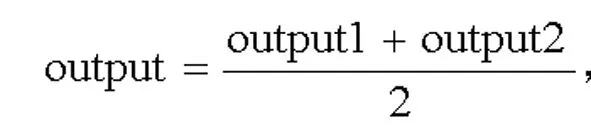
(6)
其中output1是一个输出矩阵,指的是测试数据经过DNN1训练模型得到的输出结果,output2是一个输出矩阵,指的是测试数据经过DNN2训练模型得到的输出结果,output是一个输出矩阵,指的是输出结果的合成。
2.6 波形合成
由估计得到的目标IBM与混合语音的特征相乘得到恢复出来的幅度谱,但是没有包含语音的相位信息,所以我们还需要使用原始混合语音的相位信息进行波形重构得到目标语音的频谱,再通过逆Gammatone变化获得目标语音的波形信号。
3 实验
3.1 数据描述
本实验从IEEE Corpus语音库[28]中选用了720条纯净语音,前600条纯净语音作为训练数据集,后120条纯净语音作为测试数据集,其中训练集的前300条纯净语音作DNN1语音分离系统的训练集,后300条纯净语音作为DNN2语音分离系统的训练集,DNN1和DNN2语音分离系统的测试集是一样的,训练集与测试集没有重叠的部分。另外,我们从NOISEX-92[29]中选用了三种噪声作为实验的训练和测试噪声,这些噪声都是不平稳的,分别是餐厅内嘈杂噪声(babble noise)、白色噪声(white noise)、驱逐舰机舱噪声(destroyer engine room noise)。为了使训练集与测试集没有重合的部分,本文将每个噪声分成两部分,然后将第一部分与训练语音进行混合产生训练集,输入信噪比分别为-5dB、-2dB、0dB、2dB、5dB,将第二部分噪声与测试语音进行混合产生测试集,最后将所得的训练集与测试集数据做均值方差归一化处理。
3.2 性能评估
本文采用命中率-误报率(HIT rate minus False-Alarm rate,HIT-FA)[30]和短时客观语音可懂(Short-Time Objective,STOI)[31]对模型性能进行评估。
HIT-FA表示的是命中率与误报率的差值。在IBM中,HIT是在目标语音的时间-频率单元被正确识别出来的比例,FA是在目标语音的时间-频率单元被错误识别出来的比例。其计算公式为:
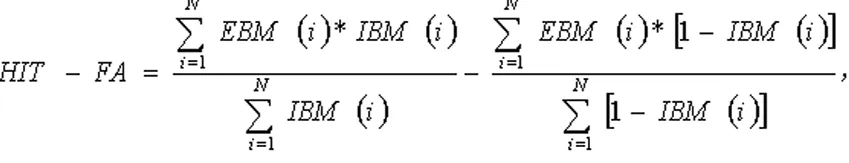
(7)
其中IBM表示理想二值掩蔽,EBM表示估计的理想二值掩蔽,N表示理想二值掩蔽中的元数个数。HIT-FA指标与人类对语言的可理解性相关联,所以常被用来评价系统性能。
STOI算法是一种比较常用的可懂度客观评价方法,该算法是纯净语音和降噪语音的函数,STOI的输出结果是一个标量值,与人对语音的实际可懂高度相关,取值范围为0到1之间,数值越大表示分离后的语音可懂度越高。使用客观可懂度测量语音的性能可以大大减少计算时间和成本。
3.3 实验结果
根据上面所提出的算法流程,采用MATLAB语言进行仿真实验,实验中所用的声音文件都是wav格式的语音。图4表示DNN1语音分离系统的纯净语音、混合信号和分离语音的时域波形图和对应的语谱图,图5表示DNN2语音分离系统的纯净语音、混合信号和分离语音的时域波形图和对应的语谱图,图6表示CE_DNN语音分离系统的纯净语音、混合信号和分离语音的时域波形图和对应的语谱图。
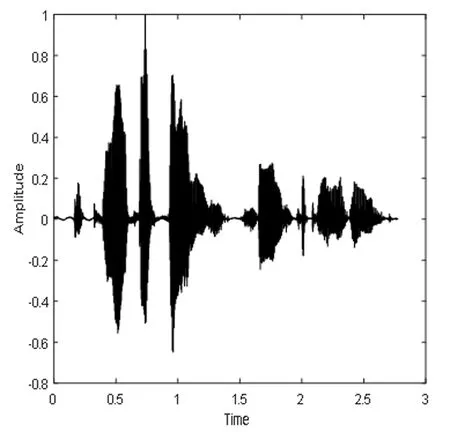
(a)纯净语音时域波形图
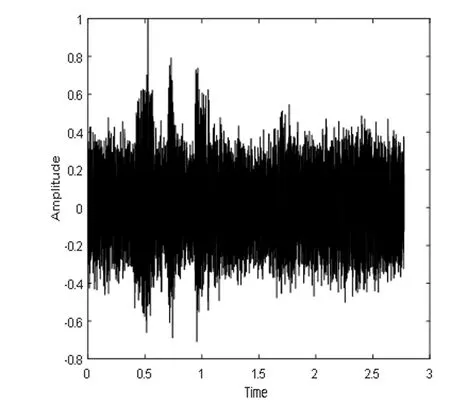
(b)混合语音时域波形图
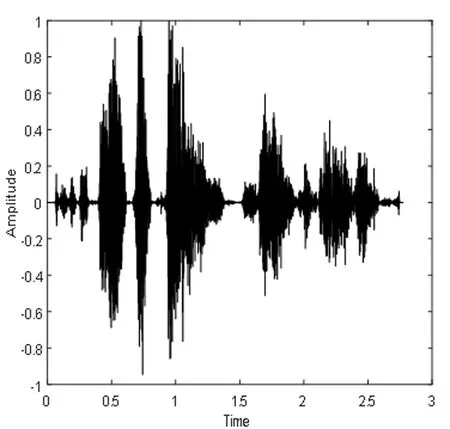
(c)分离语音时域波形图
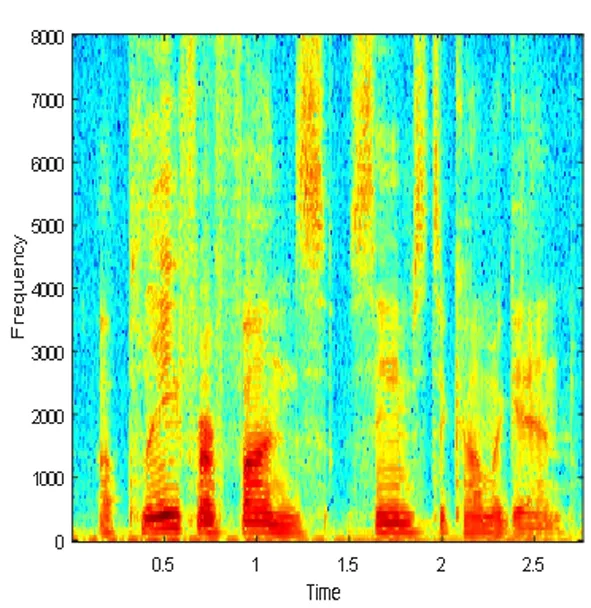
(d)纯净语音的语谱图
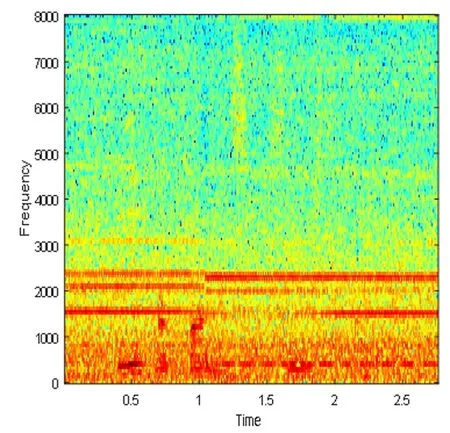
(e)混合语音的语谱图
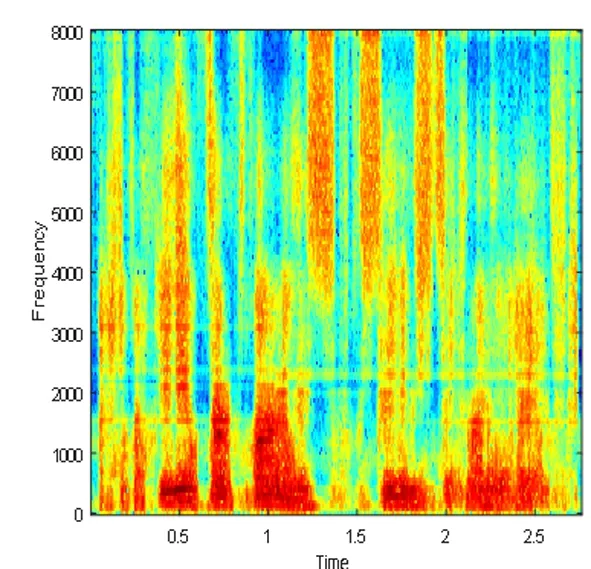
(f)分离语音的语谱图
Fig.4 DNN1 speech separation system of pure speech, mixed signal and speech separation of time domain waveform graph spectra and the corresponding language
图4 DNN1语音分离系统的纯净语音、混合信号和分离语音的时域波形图和对应的语谱图
(g)纯净语音时域波形图
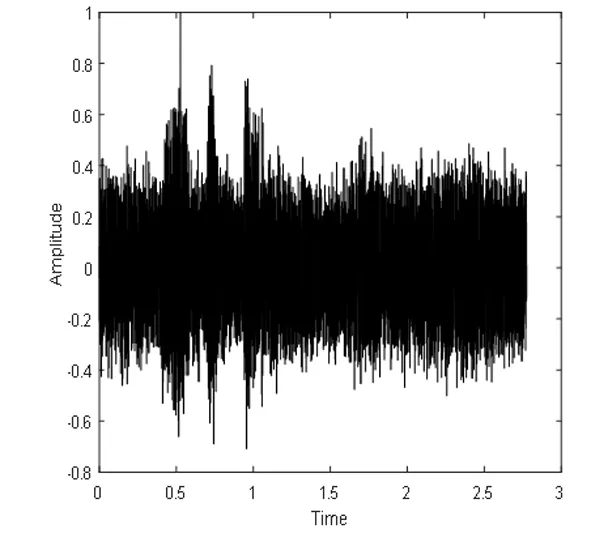
(h)混合语音时域波形图
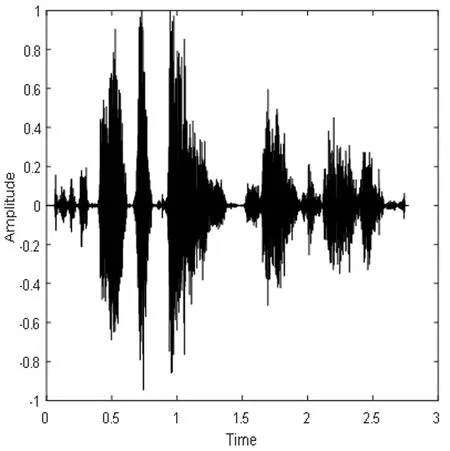
(i)分离语音时域波形图

(j)纯净语音的语谱图

(k)混合语音的语谱图

(l)分离语音的语谱图
Fig.5 DNN2 speech separation system of pure speech, mixed signal and speech separation of time domain waveform graph spectra and the corresponding language
图5 DNN2语音分离系统的纯净语音、混合信号和分离语音的时域波形图和对应的语谱图
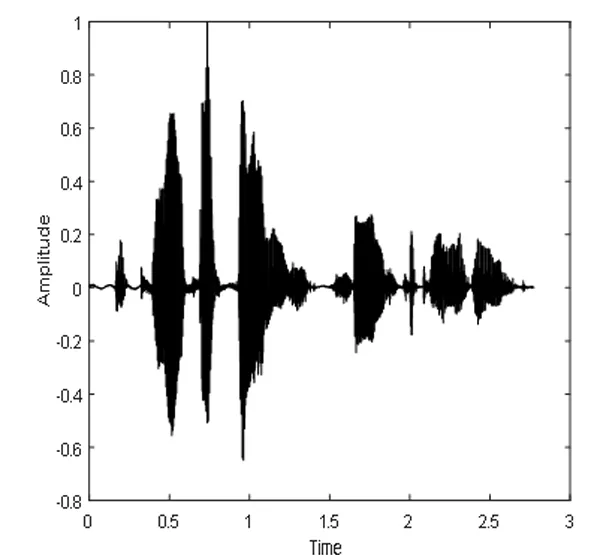
(m)纯净语音时域波形图
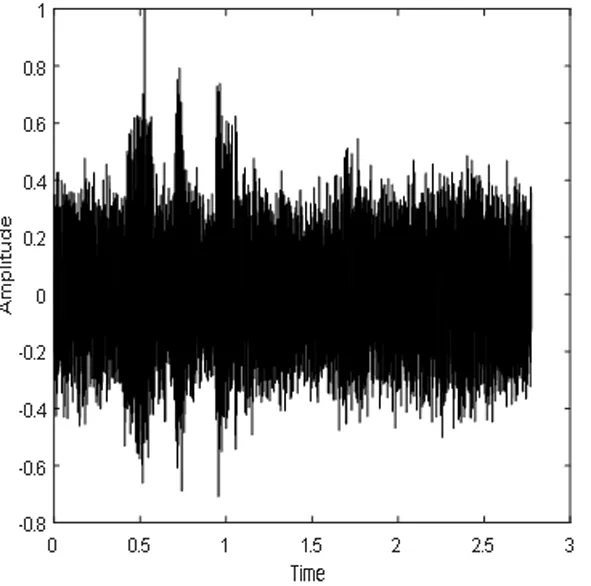
(n)混合语音时域波形图
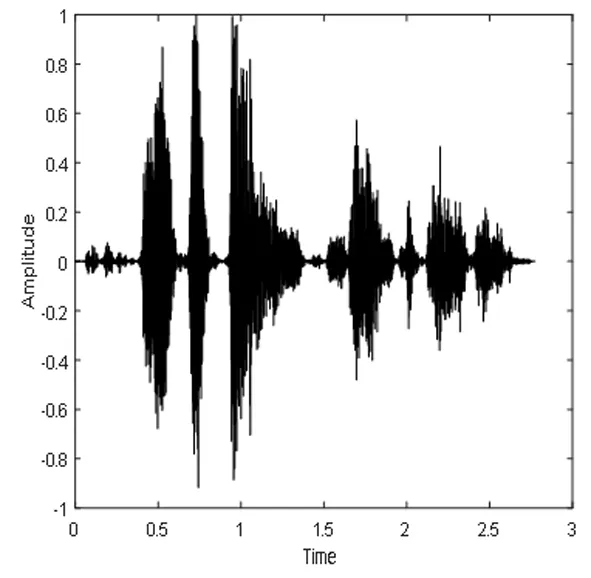
(o)分离语音时域波形图
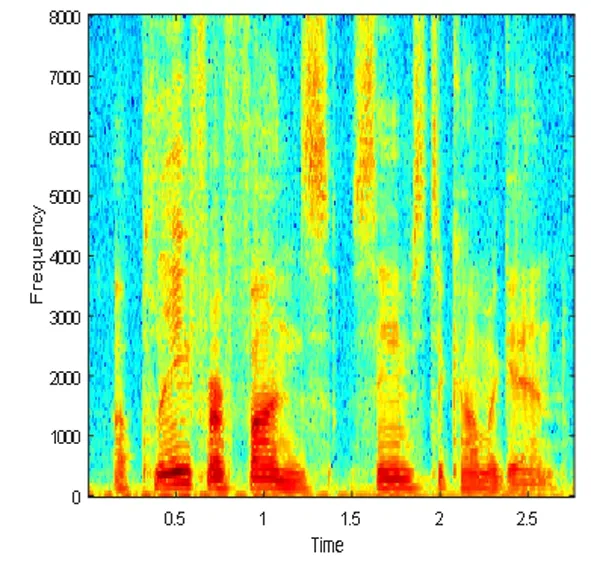
(p)纯净语音的语谱图

(q)混合语音的语谱图

(r)分离语音的语谱图
Fig.6 CE_DNN speech separation system of pure speech, mixed signal and speech separation of time domain waveform graph spectra and the corresponding language
图6 CE_DNN语音分离系统的纯净语音、混合信号和分离语音的时域波形图和对应的语谱图
图4、图5和图6都选用了混入的噪声为驱逐舰机舱,SNR为-5dB的一个相同的测试语音。从图中可以看出,DNN1和DNN2算法分离后的语谱图上有明显的杂音,与纯净语音的语谱图还有着较大的差别,而CE_DNN算法分离后的语谱图上杂音变少了,而且与纯净语音的语谱图也较为相似,波形图同理可得,这表明我们的算法在分离性能上有较好的表现,目标语音分离的更准确,分离语音失真变得更小。
Tab.1 Mixed into the SNR is -5dB、-2dB、0dB、2dB、5dB obtained HIT-FA results
表1 混入SNR为-5dB、-2dB、0dB、2dB、5dB时得到的HIT-FA结果
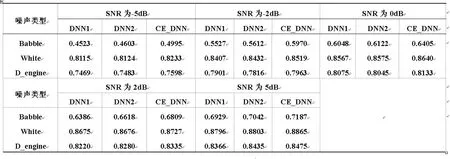
Tab.2 Mixed into the SNR is -5dB、-2dB、0dB、2dB、5dB obtained STOI results.
表2 混入SNR为-5dB,-2dB、0dB,2dB、5dB时得到的STOI结果
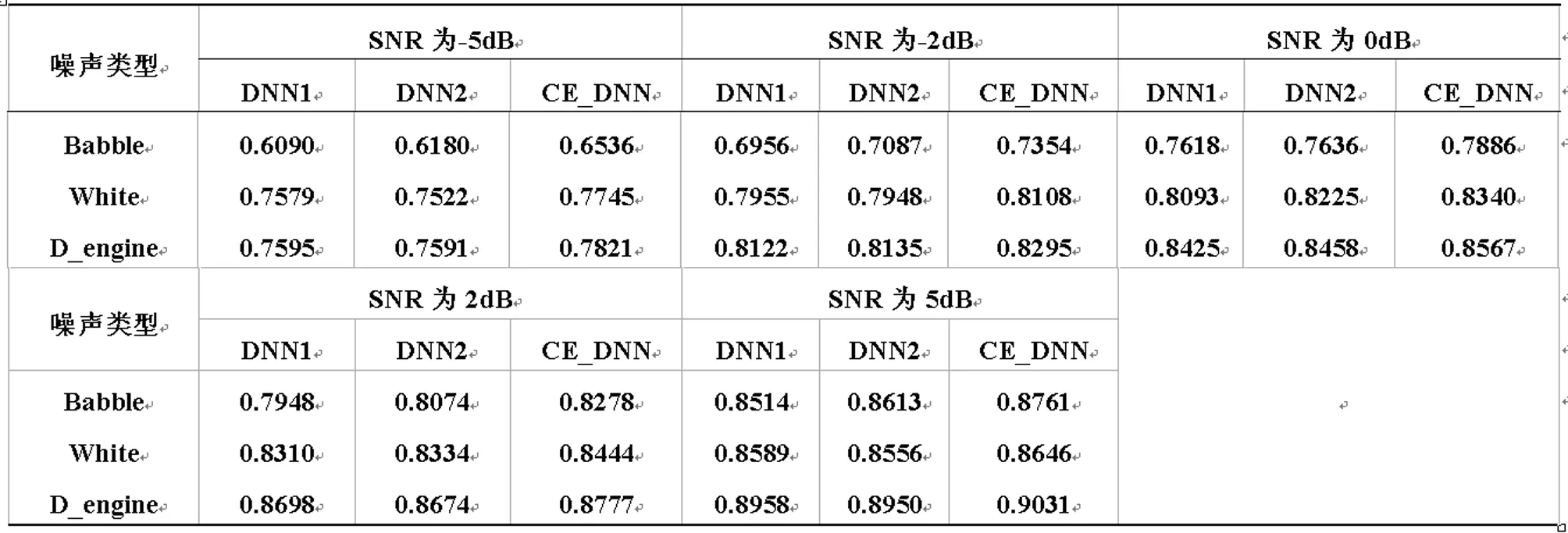
表1给出了输入信噪比为-5dB,-2dB、0dB,2dB、5dB时对应的餐厅杂音噪声、白色噪声和驱逐舰机舱噪声混合信号的HIT-FA结果。结果表明,与DNN1和DNN2语音分离系统相比,CE_DNN语音分离系统在混入SNR为-5dB、-2dB、0dB、2dB、5dB时,三种噪声信号的HIT-FA数值都有一定地提升,当混入的信噪比一定时,进行不同的噪声混合,HIT-FA所提升的数值不同,这说明质量差的噪声混合时提升的空间很大,并且在混入低信噪比的情况下,效果会更好,这对语音分离目标的质量有很大的裨益。
表2给出了输入信噪比为-5dB,-2dB、0dB,2dB、5dB时对应的餐厅杂音噪声、白色噪声和驱逐舰机舱噪声混合信号的STOI结果。由表2中的数据可得知,改进算法得到的STOI比原算法得到的STOI略高,说明了改进算法能更有效的进行语音分离,当混入的信噪比一定时,进行不同的噪声混合,STOI所提升的数值不同,这说明质量差的噪声混合时提升的空间很大,并且在混入低信噪比的情况下,效果会更好,这对语音分离目标的质量有很大的裨益。
4 结束语
本文主要是在DNN语音分离系统的基础上,提出了一种基于组合DNN的语音分离方法,实验结果表明,与已有的DNN语音分离系统相比较,所提出的CE_DNN方法不仅能够显著提高训练目标为理想二值掩蔽(IBM)的HIT-FA指标,而且还提高了语音目标的短时客观语音可懂度(STOI) ,有效的改善了分离语音的质量。针对现有的框架,在未来的研究中我们还要对深度学习方法这一研究热点进行探讨,在有效确保训练精度准确的同时,提高模型的自适应能力和训练速度。
猜你喜欢
中学生数理化·八年级物理人教版(2021年9期)2021-11-20 06:00:28
攀枝花学院学报(2021年5期)2021-10-19 02:52:58
大学物理(2021年2期)2021-01-25 03:26:18
小型微型计算机系统(2019年9期)2019-09-09 03:38:42
测控技术(2018年11期)2018-12-07 05:49:02
吉林大学学报(信息科学版)(2018年3期)2018-06-13 10:36:38
大陆桥视野·下(2017年9期)2017-09-17 15:11:21
东北师大学报(自然科学版)(2017年2期)2017-06-13 10:43:55
系统工程与电子技术(2016年7期)2016-08-21 13:59:14
西北工业大学学报(2015年4期)2016-01-19 03:31:55
