
非平衡分类技术在人群糖尿病疾病风险预测模型中的应用*
2019-09-17 11:45武海滨胡如英钟节鸣游顶云李立明陈铮鸣
中国卫生统计 2019年4期
武海滨 李 康 杨 丽 胡如英 钟节鸣 游顶云 郭 彧 卞 铮 李立明 陈铮鸣
【提 要】 目的 分析比较几种常用的非平衡分类技术在人群糖尿病疾病风险预测模型中的应用。方法 利用中国慢性病前瞻性研究浙江省桐乡市项目点基线调查数据和随访数据,使用机器学习算法建立人群糖尿病发病风险的预测模型,同时探讨欠采样、过采样、SMOTE技术及替换切点技术对分类器性能的影响。结果 本研究中神经网络预测模型的AUC值最高,达0.7971,经最优切点的选择和分类后,灵敏度和特异度分别为0.7149和0.7431,模型具有较高的预测能力,同时较好的平衡了灵敏度和特异度的分布。采样法对不同分类器的AUC值影响不同,一般欠采样比过采样具有更高的AUC值;随着SMOTE中少数类比例的上升,AUC出现下降的趋势。结论 使用神经网络结合替换切点技术建立的人群糖尿病5年发病风险模型具有较高的预测能力,并能够较好的处理非平衡数据的影响。
非平衡数据(imbalance data)即研究数据中的一个或几个类别相对于其他类别在数量上具有非常低的比例,由于少数类的获得常常较为困难或代价较高,很多研究关注少数类的情况。非平衡分类(class imbalance)是一种有监督学习问题,在流行病学研究中非常常见,如调查显示我国成人糖尿病患病率为10.9%[1],估计高危人群10年后脑卒中的发病风险为3.2%[2],浙江省儿童青少年1型糖尿病平均发病率为2.02/10万[3]。近年来,非平衡分类问题在机器学习领域已经得到了越来越多的关注,通过数据预处理、建立新的模型或改善现有模型,多种技术被应用至非平衡分类问题。不同非平衡数据处理技术的优劣并无明确定论,仍主要取决于研究数据本身[4-5]。
人群疾病风险预测模型的建立通常使用大型自然人群队列的随访数据,本研究使用中国慢性病前瞻性研究(China Kadoorie Biobank,CKB)浙江省桐乡项目点的基线数据和随访数据,通过比较几种常用的非平衡分类技术,建立2型糖尿病发病风险预测模型,为糖尿病的防治提供科学依据,为流行病学中非平衡分类问题的处理提供参考。
方法和原理
1.非平衡分类问题及处理方法
非平衡分类中少数类的信息较少,易受噪声的影响,类别间容易形成重叠或小的间断,影响了分类模型的预测结果[6-7]。此外,传统分类算法的构建多基于样本类是平衡的假设,算法具有一个待优化的损失函数,建模中会将所有样本同等对待,不同类别的误分类情况产生的误差相同,没有考虑数据类别的分布情况。当遇到非平衡分类问题时,传统的算法往往偏向多数类,在极端的情况下,少数类的样本被视为多数类的离群值并被忽略,算法只生成一个简单的分类器,将每个样本分为多数类。因此,传统算法应用于非平衡分类问题时常常导致在多数类的分类精度较高而在少数类的分类精度很低。本研究使用采样法(sampling methods)和替换切点(alternate cutoffs)技术处理非平衡分类问题。
(1)采样法
采样法对原始数据进行重新抽样,改变少数类和多数类的频数分布,从而使得少数类在训练集中有更好的表现。该方法可以视为对数据的预处理,主要包括过采样法(oversampling)、欠采样法(undersampling)及两种技术的混合[8],在采样完成后能够使用不同的分类器,因此应用范围较广。
欠采样法是减少样本数量以提高类别间平衡性的技术,如保留少数类中所有样本并在多数类中随机选择样本使各分类达到近似的样本量。本研究固定少数类的样本量,并在多数类中进行随机抽样,直到多数类的样本量与少数类相同。
过采样法是使用模拟或补充额外数据点以提高类别间平衡性的技术,如对少数类进行有放回的抽样直到各分类达到近似的样本量。本研究固定多数类的样本量,对少数类进行有放回的随机抽样,直到少数类的样本量与多数类相同。
SMOTE技术(synthetic minority oversampling technique)[9]是一种可以根据分类同时使用过采样和欠采样的数据抽样技术,以往的研究发现该方法有较好的性能,在高维非平衡数据的机器学习中具有较广的应用,在医学中的应用也越来越广泛。SMOTE技术有3个参数,过采样的数量,欠采样的数量及用于产生新样本的近邻点数量。在对少数类的过采样中,SMOTE在少数类中随机选择一个样本点,其K个最近邻(K-nearest neighbors)样本点也被确定,新合成的样本点是该样本点和其最近邻点特征的随机组合,因此它们与原始数据中少数类的样本点近似[10]。同样,该技术也可以对多数类中的样本点进行欠采样。本研究使用SMOTE方法在确保少数类与多数类样本量一致的前提下,利用5个近邻样本点产生新的样本点,将少数类样本分别扩大2倍,5倍和10倍,分别表示为SMOTE2,SMOTE5和SMOTE10。
(2)替换切点
很多分类器可以计算出事件发生的概率,当分类问题是二元时,可以通过改变模型预测概率的切点(cutoff),提高模型对少数类的预测性能。切点选择的方法如使用约登指数(Youden index)或ROC曲线,ROC曲线能够在连续不同切点下计算灵敏度和特异度,并在灵敏度和特异度之间找到一个合适的平衡点。为准确评估模型的优劣,本研究在使用该方法时将数据集分为训练集(2/3样本量)、验证集(1/6样本量)和测试集(1/6样本量),使用训练集建立预测模型,对验证集进行预测,同时搜索ROC曲线上的最优切点,在测试集中使用该最优切点对样本进行最终的判别分类。
2.评价指标
非平衡分类问题要求模型能够具有较高的预测能力,同时能够处理非平衡数据对模型的影响,即平衡灵敏度与特异度的能力。为保证结果的稳健性,使用不同的种子数对上述算法流程重复20次,比较测试集中预测结果的平均值,包括准确率、灵敏度、特异度和AUC,评估不同非平衡数据处理方法及不同参数下各分类器的性能。本研究使用AUC评估模型的预测能力,AUC越大分类器预测能力越强;使用特异度与灵敏度之比(Sep/Sen)评估非平衡数据对模型的影响,Sep/Sen越接近1越好。
资料来源
1.数据来源
CKB项目调查对象的入选标准和排除标准以及有关项目其他情况见文献[11-13]。桐乡市的基线调查从2004年至2008年共收集57704名30~79岁常住社区人口。基线调查包括问卷调查、体格检查、血样本采集和现场随机血糖检测等。所有调查对象每年进行一次随访,收集相关疾病的发病时间和疾病类型。本研究随访时间截止至2013年底,调查对象的随访时间至少为5年。排除在基线时已经诊断为糖尿病的调查对象,同时排除数据变量缺失的调查对象,50877人纳入分析,其中新发T2DM 1652例,未发生T2DM 49225例,少数类与多数类的比例近1:30。
2.数据处理及建模流程
为提高风险评估模型的适用性和可行性,减少冗余变量对模型预测效能的影响,首先根据流行病学专家和临床专家的相关经验挑选出可能与糖尿病发生相关的预测变量72个,接着对基线数据进行预处理,包括数据的标准化和使用随机森林方法进行变量筛选,保留变量重要性排序前20位的变量(Gini指数排序),最后分别使用原始数据和采样法处理后的数据进行机器学习算法的建模,通过模型评估指标筛选出具有最高分类性能的分类器作为最终的预测模型,具体流程见图1。
本研究使用6种机器学习算法分别建立糖尿病发病风险预测模型,包括线性和非线性的分类器:logistic回归(LR)、朴素贝叶斯分类器(NB)、分类回归树(CART)、随机森林(RF)、单隐层前馈神经网络(NNET)和AdaBoost.M2 (Ada.M2)。所有模型均使用2/3样本作为训练集,剩余1/3样本作为测试集,模型训练过程中在训练集内使用网格搜索等方法进行参数的选择,采用3折交叉验证计算不同参数或参数组合时的AUC,AUC指标最大时的参数作为模型的最优参数,使用R语言完成建模过程。
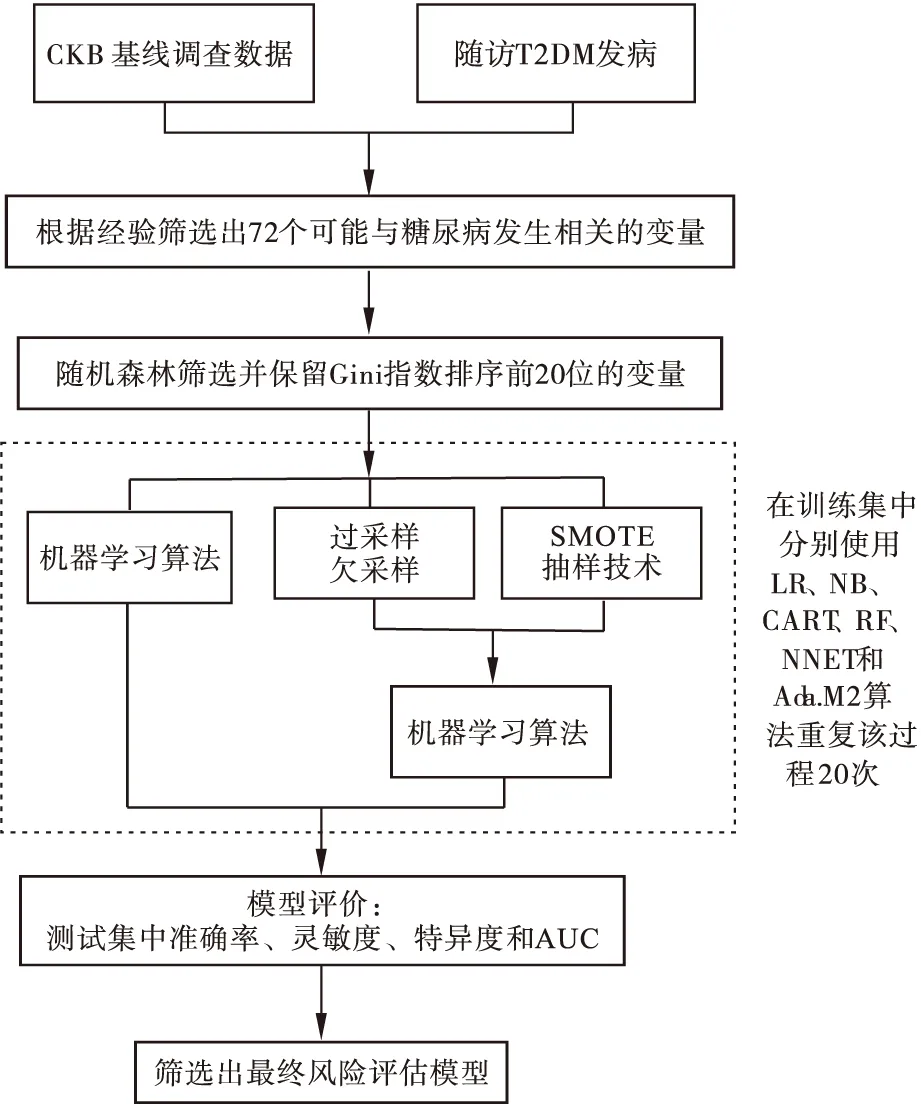
图1 糖尿病发病风险评估模型的筛选流程
结 果
1.不同机器学习方法的性能
表1为使用原始数据时不同分类器的预测能力。可见,各模型均具有较高的预测准确率,除NB最低为0.9458外,其他模型均在0.95以上,RF的预测准确率最高,达0.9677。NNET的AUC最高,达0.8015,CART的AUC最低且标准误最大(AUC=0.7207,标准误为0.0326),基于CART的RF和Ada.M2预测能力得到了显著的提升,AUC分别上升至0.7830和0.7964。NNET和Ada.M2的特异度非常高,而灵敏度接近于0,非平衡数据对这两个模型的影响较大;NB的Sep/Sen值最小,为5.96,说明NB受非平衡数据的影响最小。
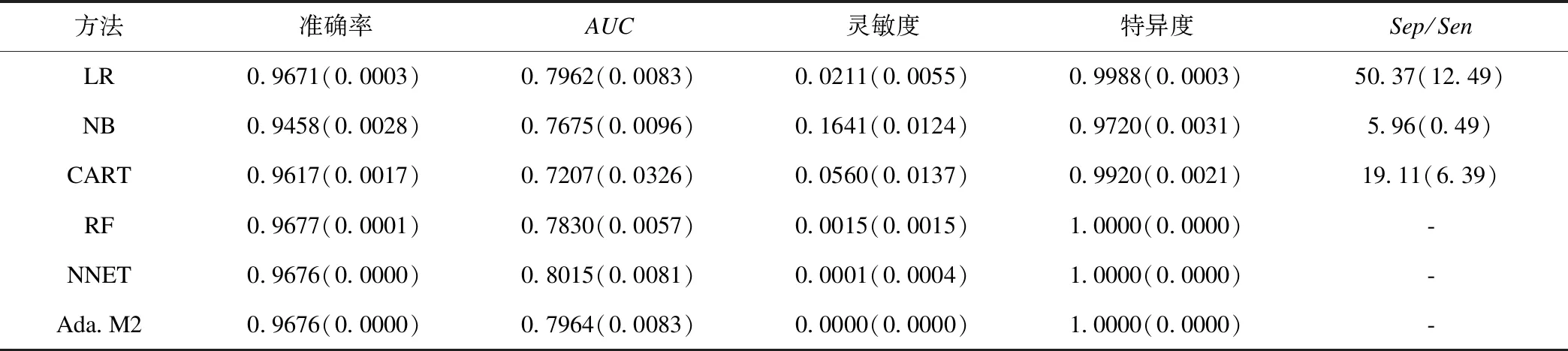
表1 不同分类器的预测能力均数(标准误)
2.采样法对分类器的影响
使用采样法对原始数据进行抽样后,各分类器的准确率均出现显著的下降,见表2。过采样时的准确率普遍高于欠采样,在SMOTE采样中随着少数类比例的上升,准确率均有增加的趋势。

表2 不同采样法分类器的准确率均数(标准误)
使用采样法对原始数据进行抽样后,不同分类器AUC指标的变化较为复杂。图2中垂直的实线和虚线表示该分类器在原始数据中的AUC值及95%CI,误差线表示使用不同采样方法时的AUC值及95%CI。CART的AUC值有较大的提升,见图1(C);RF和NNET的AUC值下降明显,图1(D)和图1(E);LR和NB的AUC值变化不明显,图1(A)和图1(B)。除LR和Ada.M2外,其余算法中欠采样后模型的AUC均高于过采样,与准确率相反;在SMOTE中随着少数类比例的上升,NB、CART、RF、NNET和Ada.M2的AUC均出现下降的趋势,亦与准确率相反,而LR的预测能力有轻微的上升趋势。对比所有模型后发现,AUC指标最高的仍为在原始数据中NNET算法(AUC=0.8015),将其作为最终的糖尿病风险预测模型。
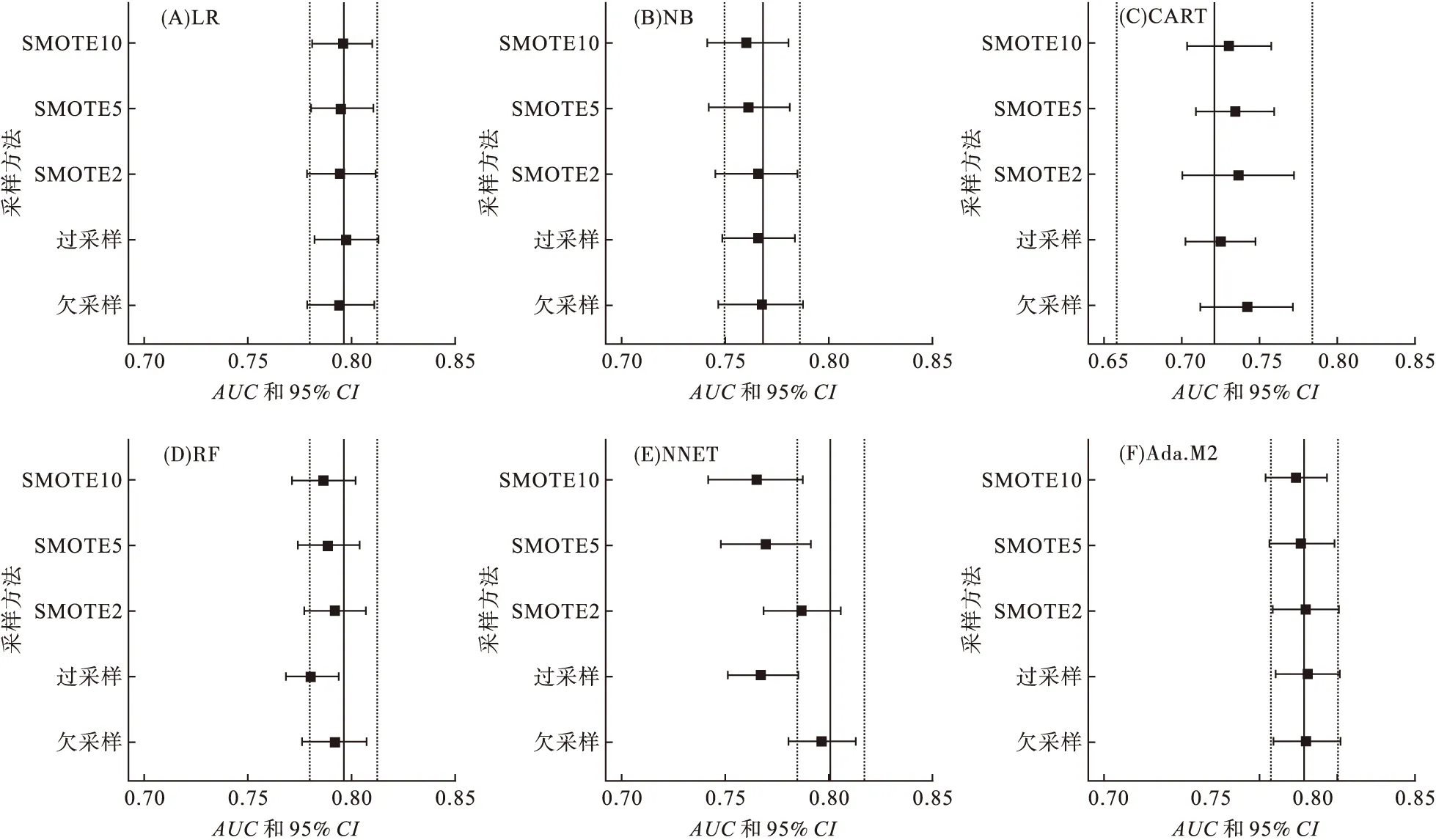
图2 不同采样法各分类器的AUC值
3.采样法在非平衡数据中的性能
表3中可见,不同采样法均显著降低了Sep/Sen,平衡了灵敏度和特异度的分布。相对于过采样法,欠采样法后分类器的Sep/Sen更接近于1;此外,SMOTE采样中随着少数类比例的上升,Sep/Sen与1的差值有增大的趋势,特别是CART、RF和Ada.M2分类器。

表3 不同采样法分类器的Sep/Sen均数(标准误)
*均值计算时删除2例灵敏度为0的数据
4.糖尿病风险评估模型
考虑到模型的分类性能和对非平衡数据的处理,我们最终选择NNET分类器并使用替换切点的处理技术建立糖尿病发病的风险评估模型,结果见表4。在验证集和测试集中NNET的AUC分别达0.8060和0.7971,在验证集中选择的ROC曲线切点均值为0.0347,使用这些切点在测试集中对样本进行判别,灵敏度和特异度均值分别为0.7149和0.7431,Sep/Sen均值为1.04,模型具有较高的预测能力,同时较好的平衡了灵敏度和特异度的分布。
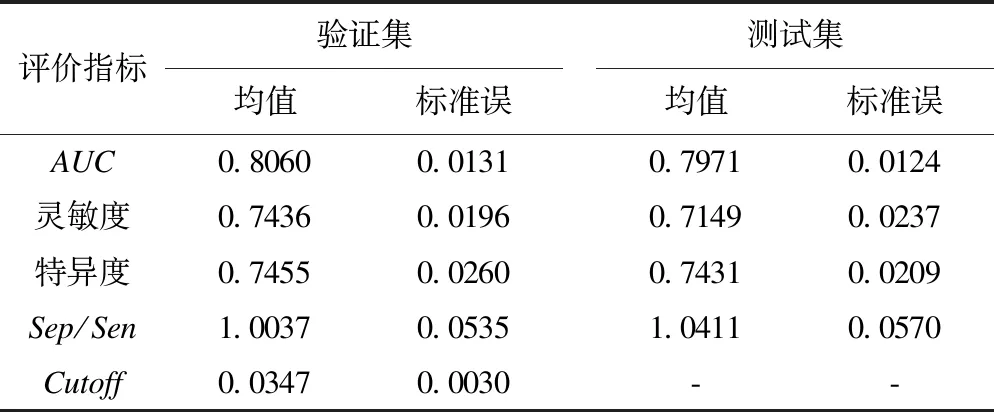
表4 糖尿病风险评估模型的预测性能
讨 论
本研究利用CKB项目的基线和随访数据探讨了欠采样、过采样、SMOTE及替换切点技术在非平衡分类问题上对分类器性能的影响,通过变量筛选和模型筛选建立了人群5年糖尿病发病风险的预测模型。本研究样本量较大,随访观察时间较长,建模过程中考虑了非平衡分类问题,能够为我国人群糖尿病的预防和控制提供方法和依据,为非平衡分类问题处理技术在流行病学中的应用提供参考。
使用采样法对原始数据进行抽样后,各分类器的准确率均出现显著的下降,灵敏度和特异度的比值更接近于1,但不同分类器AUC的值变化较为复杂。一般来说,欠采样比过采样具有更高的AUC值,但准确率较低;在SMOTE采样中随着少数类比例的上升,AUC均出现下降的趋势,而准确率则有上升趋势,非平衡分类模型的AUC值与准确率之间可能存在平衡关系,提示我们使用采样法或SMOTE时,应尽可能减少少数类的生成和抽样。过采样法可能会导致模型的过拟合,此外,当多数类样本量很大时,过采样会显著增加模型的训练时间;SMOTE技术降低了过采样中过拟合的风险,但是可能导致少数类和多数类的决策边界更近或重叠更多;欠采样法虽然忽略了潜在的数据信息,但运算量较小,建议实际应用中使用欠采样或SMOTE技术,使用SMOTE时少数类样本量新样本点的产生应控制在合理范围内。Alghamdi等人使用机器学习方法对糖尿病发病预测中发现,欠采样并不能显著提高各分类器的AUC,与我们的结论一致,但SMOTE显著提高了各分类器的AUC[14],这种差异可能来自数据的结构、参数的设置等原因。
本研究存在的局限性:(1)基于抽样的方法如对SMOTE改进的技术,包括Borderline-SMOTE、Adaptive Synthetic Sampling(ADA-SYN)和Tomek Links法等,有待于以后的进一步比较;(2)模型评估中仅考虑了AUC、灵敏度和特异度,未考虑净重新分配指数(net reclassification index,NRI)、精确率召回曲线(precision-recall curves)等评价指标;(3)各分类器重复运算20次,结果可能不够稳健;(4)未使用我国其他地区的相关数据对模型性能进行验证,仍待于进一步研究。
致谢感谢中国慢性病前瞻性研究项目管理委员会、国家项目办公室、牛津协作中心和浙江省项目地区办公室的工作人员。
猜你喜欢
心理学报(2022年10期)2022-10-12
内蒙古统计(2021年4期)2021-12-06
计算机系统应用(2021年2期)2021-02-23
中学生数理化(高中版.高考数学)(2020年12期)2021-01-13
电子技术与软件工程(2019年18期)2019-11-18
中国卫生统计(2019年3期)2019-07-10
中国卫生统计(2019年3期)2019-07-10
中等数学(2018年7期)2018-11-10
电子技术与软件工程(2017年14期)2017-09-08
福建中学数学(2016年4期)2016-10-19
