
多路反馈型两级交换结构*
2019-09-14 07:13申志军陶东华
计算机与生活 2019年9期
申志军,陶东华,高 静
内蒙古农业大学 计算机与信息工程学院,呼和浩特 010020
1 引言
流媒体、高清视频以及云计算等相关业务的迅猛发展使网络用户对远端数据的依赖与日俱增,从网络承载的角度分析,传统业务向网络的迁移以及新型网络业务的涌现都会显著增加网络的数据传输压力。
互联网“云-管-端”的抽象模型中,所谓“管”即从云数据中心出发到网络终端的数据通道,宏观上是由各级交换设备(交换机和路由器)将多段光纤连接而成。就现阶段技术而言,光纤通信技术通过多波长复用可实现单根光纤20 Tb/s 的数据传输率,已经能够提供相对较充足的传输带宽,然而交换设备的端口速率却远低于光纤所能提供的数据传输速率。这使得提高交换设备的交换速率成为缓解数据传输压力的研究方向之一。
为提高交换设备的数据交换能力,业界对交换技术领域展开了深入研究,较为重要的阶段性成果如输出排队(output queuing,OQ)[1-2]、输入排队(input queuing,IQ)[3-4]、复合输入和交叉点排队(combined input cross-point queuing,CICQ)[5-6]等。自Internet 中的数据流被证实具有自相似[7]特征以来,研究人员发现传统的单级crossbar 型交换结构在突发型数据流环境中性能不够理想,于是业界开始转向两级crossbar结构的研究。
两级交换结构的第1级crossbar将到达输入端口的突发数据均匀散布,第2 级crossbar 将散布后“均匀”到达的数据包转发到输出端口,故能够在自相似数据流环境中表现出较为优异的性能,因此成为近年来交换技术领域的研究热点。
文献[8]提出两级交换结构的原型LB-BvN(load balanced Birkhoff-von Neumann switch architecture),其对突发数据流的散布效果为业界开启了全新的思路,但LB-BvN 有两个明显缺陷:数据包失序和时延性能偏低。针对这两个问题,后续的研究中逐渐涌现出大量的研究成果,如满帧优先(full frames first,FFF)[9]、有序满帧优先(full ordered frames first,FoFF)[10]、Mailbox[11]、Byte-Focal[12]、LB-IFS(load balanced switch based on implicit flow splitter)[13]等。这些成果在保证数据包不失序及时延性能方面取得较为显著的成效。然而相对于传统交换结构而言,时延性能仍存在明显差距。文献[14]提出反馈型两级交换结构(feedback-based two-stage switch architecture,FTSA)之后这种局面才得以扭转。FTSA的两级crossbar采用错列对称特性(staggered symmetry property,SSP)连接方式,在同一线卡的输出和输入端口之间进行信息反馈,在保证数据包不失序的同时,极大地提高了时延性能(两级交换结构中,其理论时延性能最优),其在多播[15]、连接序列[16]和调度[17-18]等方面的研究工作正逐步深入。虽然如此,FTSA也存在明显不足,即其所允许的算法执行时间极短(纳秒级)且算法复杂度为O(N),在当前技术条件下,FTSA 的调度算法缺乏足够的可执行时间完成既定的调度任务,这使得该结构难以运用于工程实践。
2 相关研究进展和问题
针对FTSA中算法可执行时间不足的问题,总体存在两种典型解决思路:
(1)降低算法复杂度;
(2)扩展算法可用时长。
对于第一种思路,文献[14]提出用O(1)复杂度的Quasi-LQF(Quasi-longest queue first)[19]算法进行调度,然而由于FTSA中每个时隙的调度算法所依赖的数据集是变化的,而且数据集之间并无直接联系,故无法将Quasi-LQF算法应用于FTSA。

Fig.1 Switch architecture of MFTS图1 MFTS交换结构
对于第二种思路,现有方案如前置反馈结构(front-feedback-based two-stage switch architecture,FFTS)[20],虽然扩展了算法可用时长,但代价过高。FFTS在每个时隙开始时将中间缓存信息(非精确的)反馈至输入端口,使其可提前进行调度,但由于算法所依赖的数据是不精确的,因此可能出现数据包冲突现象[20]。为此FFTS被迫在中间端口设置额外的缓存空间来缓存发生冲突的数据包,但这样又会导致数据包在输出端口失序,故FFTS还须在输出端口设置重排序缓存来解决数据包失序问题。
为进一步解决算法的时间限制和现有方案中代价过高的问题,本文提出一种多路反馈型两级交换结构(multichannel-feedback-based two-stage switch architecture,MFTS)。
为便于描述,本文做以下约定:
(1)交换结构的输入端口和输出端口数均记为N,两级crossbar分别记为X1、X2;
(2)序号为i的输入端口记为Ii,序号为j的中间端口记为Mj,序号为k的输出端口记为Ok;
(3)到达Ii且目标输出端口为Ok的数据包的集合定义为数据流Fi,k。
3 多路反馈型两级交换结构MFTS
3.1 交换结构
MFTS 由两级crossbar(X1和X2)和两级缓存组成,如图1 所示。位于X1之前的缓存记为VOQ1,位于X1和X2之间的缓存记为VOQ2,VOQ1(i,k)用于缓存流Fi,k的数据包。VOQ2(j,k)位于Mj,用于缓存目标输出端口为Ok的数据包,任意VOQ2(j,k)仅设置一个数据包的缓存空间,i,j,k=0,1,…,N-1。
3.2 Crossbar连接方式
MFTS 中X1和X2使用图2 所示的crossbar 连接方式。该连接方式由式(1)和式(2)共同确定。

Fig.2 Crossbar connection of MFTS图2 MFTS的crossbar连接方式
t时隙与Ii相连的中间端口的序号j需满足:

t时隙与Mj相连的输出端口的序号k需满足:

该连接方式具有如下特性:
定理1若t时隙Mj与Ok相连,则t+2 时隙Ik必与Mj相连。
证明不妨设t0时隙Mx与Oy相连,则必有:

由式(1)可知t0+2 时隙与Iy相连的中间端口的序号z需满足:

将式(3)带入式(4)可得:
z=x□
式(2)中的“j-2-t”恰使得MFTS 具有定理1所述的特性,这也正是算法可执行时间得以延长的基础条件。
定理2确定的输入端口在不同的时隙总是经不同的中间端口与一个确定的输出端口相连。
证明考虑序号为i0的输入端口在时隙t0时:
不妨设与之相连的中间端口的序号为j0,则依据式(1)有:

若将与该中间端口相连的输出端口序号记为k0,依据式(2)有:

将式(5)代入式(6)可得:

式(7)表明,无论何时,对于一个确定的输入端口Ii,与之相连的输出端口固定为Oi-2。 □
3.3 多路反馈工作机制
图3所示为MFTS工作原理示意图。MFTS通过反馈机制使得在t时隙之初将Mj的缓存数据传输给Oi,随后反馈给Ii,之后Ii基于本地VOQ1 和提前到达的Mj的缓存状态数据开始进行调度,调度过程可持续到t+2 时隙开始之前。如此即可有效扩展算法的执行时间区间。
本文以t时隙端口Ii的三路数据汇集、数据处理和调度算法为例对MFTS的工作机制予以说明。
3.3.1 第一路反馈
如图3(a)所示,t时隙Ii+2经Mj与Oi相连。
反馈的时间:t时隙开始时刻。
反馈的路径:Mj→Oi→Ii。

Fig.3 Diagram of all feedback paths图3 反馈路径示意图
反馈的信息:Mj在t时隙初始时刻的缓存状态数据,本文将其记为Dj(tbg),Dj(tbg)共有Nbit,其生成算法如下:
算法1生成算法

实践中,可通过并行处理快速得到Dj(tbg)。
3.3.2 第二路反馈
如图3(b)所示,t时隙Ii+2经Mj与Oi相连。
反馈的时间:t时隙开始时刻。
反馈的路径:Ii+2→Mj→Oi→Ii。
反馈的信息:Ii+2在t时隙向Mj发送的数据包的目标端口信息,本文将其记为IMj(t)。IMj(t)有Nbit,若Ii所发送数据包的输出端口号为v,则IMj(t)[v]←1,其余位均为0。若Ii+2在t时隙未发送任何数据包到Mj,则IMj(t)←0。
3.3.3 数据处理和初级调度
为了能够向调度算法提供准确的基础数据,MFTS需对t时隙开始后经第一路和第二路反馈到达输入端口的数据进行处理。数据处理方法如下(以Ii为例):

数据处理完成后,Ii基于VOQ1 和Dj(tbase)开始进行初级调度,调度算法选择LQF(longest queue first)算法[14]。算法调度完成后返回值记为Ri(t),Ri(t)具有Nbit,若算法选择的是VOQ1(i,v)中的数据包,则Ri(t)[v]←1,其余位均为0。若算法未能找到符合要求的数据包,则Ri(t)←0。
3.3.4 第三路反馈
如图3(c)所示。
反馈的时间:时隙t结束时刻。
反馈的路径:Ii+1→Ii。
反馈的信息:输入端口Ii+1在t+1 时隙向Mj发送的数据包的目标端口信息,本文将其记为IIi(t+1),若Ii+1所发送数据包的输出端口号为v,则IIj(t)[v]←1,其余位均为0。若Ii+1在t+1 时隙未发送任何数据包到Mj,则IIj(t)←0。
第三路反馈发生在相邻输入端口之间,故MFTS考虑设置专用反馈链路如下:
首先,在交换背板增加N个容量大小为Nbit 的存储器SM0,SM1,…,SMN-1,分别对应于输入端口I0,I1,…,IN-1;其次,为输入端口Ii设置读SMi+1和写SMi的读写控制电路。如此即可在不影响既有数据传输机制的前提下,通过线卡和交换背板实现第三路反馈操作。
3.3.5 终裁
终裁时间:t+1时隙结束时刻。
终裁基础数据:初级调度返回值v和第三路反馈数据IIj(t)。
终裁目的:(1)判断初级调度结果是否有效,否决无效的调度结果;(2)尽可能提高交换性能,避免浪费带宽。若初级调度结果未能获得可用结果或其结果被否决,则需判断新到达的数据包是否可作为调度结果。
若t时隙有数据包到达Ii,则将其输出端口信息记为ToIi(t),若其输出端口号为v,则ToIi(t)[v]←1,其余位均为0。同理,ToIi(t+1)记录的是t+1 时隙到Ii的数据包的信息。
若令Fi(t)表示Ii的终裁结果,则终裁算法如下:
算法2终裁算法

4 理论分析
4.1 MFTS保证数据包不失序
定理3同一个流的数据包在中间缓存的等待时延相等且为定值。
证明不失一般性,考虑流Fi,k的数据包p:
首先,p到达某个中间端口,依据定理2可知,本时隙该中间端口必然与Oi-2相连,下一时隙必然与Oi-3相连。
其次,因为中间端口总按照固定的顺序依次与各个输出端口相连,故p最快(当k=i-1 时)可在下一时隙被转发至输出端口。p需在中间缓存等待的时延d为:

上式表明,p在中间缓存等待的时延d仅与其输入端口(i)和输出端口(k)有关,亦即同一个流的数据包在中间缓存等待的时延相等且为定值。 □
定理3 表明先到达输入端口的数据包也将先到达输出端口,即MFTS保证数据包不会失序。
4.2 算法可用时长扩展效果分析
初级调度起始于Dj(tbase)生成之后,结束于t+1时隙结束时刻。本文用TMFTS表示MFTS所容许的算法调度时间,则其可表示为:

其中,TSlot表示一个时隙的时间,而TReconf表示两个时隙中间的crossbar重配置时间,T*表示Nbit的IMj(t)到达Ii以及数据预处理时间之和。
TReconf取决于crossbar交叉点的开关速度,就当今微电子技术工艺而言,其极限耗时可低至纳秒级。考虑256 Byte 的数据包和32 端口的交换规模,TSlot包含264 Byte(256+2×32/8)数据传输时间与传播时延之和,显然有TSlot>>T*。
按照同样的分析方法可知,FTSA要求算法必须在TReconf时间内完成反馈和调度过程;FFTS所允许的算法工作时长接近一个TSlot。式(11)表明,MFTS可将算法可执行时间提高到FFTS的2倍左右。这种优势可提高交换结构的可扩展性,使之能够支持更大的交换规模和更高的端口速率。
4.3 时延性能分析
在相同的交换环境并采用相同调度算法的情况下,MFTS 的时延性能会略低于FTSA,其原因在于MFTS的初级调度所依赖的Dj(tbase)并不完全准确,其调度结果可能会被否决,若其结果被否决且新到达的数据包不能递补为调度结果时,该时隙的转发带宽被浪费,时延性能会下降。
定理4对于Ii在t时隙的调度算法而言,Dj(tbase)最多只有一位是不准确的。
证明Ii在t时隙的调度算法需要的是t+1 时隙结束时刻Mj的缓存状态数据,而通过第一路和第二路反馈得到的是Dj(tbg)和IMj(t)。
对于交换端口而言,一个时隙内最多只能有一个数据包到达,也最多只能有一个数据包离开。因此,对Ii在t时隙的调度算法而言,Dj(tbg)最多有3 bit是不准确的,这是因为:
(1)Dj(tbg)缺少t时隙到达Mj的数据包信息;
(2)Dj(tbg)缺少t+1时隙到达Mj的数据包信息;
(3)Dj(tbg)缺少t+1时隙离开Mj的数据包信息。
3.3.3小节中式(8)的数据处理可向Dj(tbg)添加t时隙到达Mj的数据包信息,并更新为Dj(tbase)。式(9)排除Dj(tbase)中t+1时隙离开Mj的数据包信息。
经过上述处理后,Dj(tbase)仅缺少t+1 时隙到达Mj的数据包信息,即Dj(tbase)最多只可能有1 位是不准确的。 □
终裁算法表明,同时满足如下条件才可能出现明显的性能损失:
(1)Dj(tbase)恰有1位是错误的;
(2)Dj(tbase)错误的1 位恰好导致错误的调度结果,该结果必将被终裁算法否决;
(3)新到数据包无法作为替补调度结果。
上述分析表明,MFTS中发生显著性能损失的概率是较低的,第5章中的仿真实验结果也证实了这种分析。
5 仿真实验
为验证MFTS 的时延性能,本文使用Opnet14.5对三种反馈型两级交换结构MFTS、FTSA和FFTS分别建模进行仿真研究。
仿真平台包括数据发生、数据包交换和数据统计三部分。数据发生模型根据特定的概率分布模拟各种不同的数据包到达方式,用以表征常见的数据流,如均匀数据流用于模拟传统的交换环境,突发数据流用于模拟自相似交换环境等。
数据包交换模型是交换结构、缓存设置方式和调度策略的具体实现,用以表征数据包从到达至离开的所有处理逻辑。
数据统计模型用于统计队列长度,数据包在交换结构中的时延等信息并同步计算最值和均值等。
本文选择均匀数据流环境和突发数据流环境分别进行仿真,图4和图5分别为两种数据流环境下各种交换方案的平均时延比较图。

Fig.4 Average latency under uniform traffic图4 均匀数据流环境下的平均时延
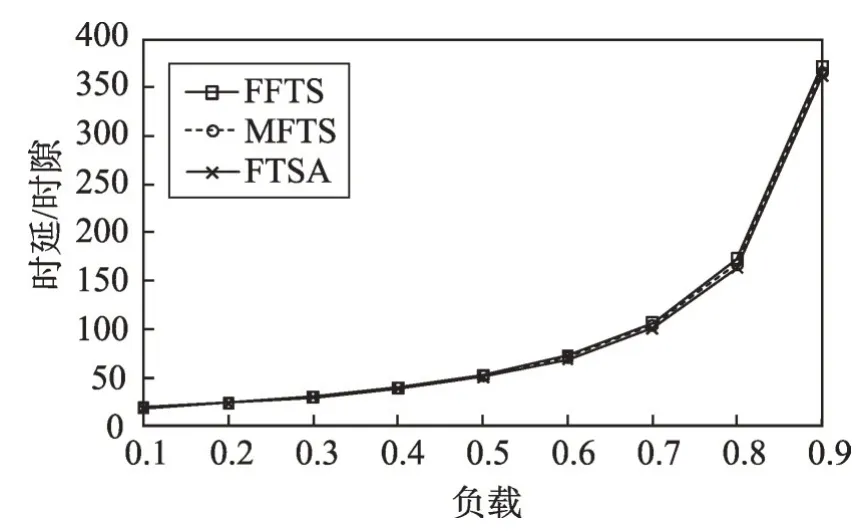
Fig.5 Average latency under burst traffic图5 突发数据流环境下的平均时延
图4 表明,在均匀数据流环境中,因所有数据包的输出端口是均匀分布的,故能够获得较好的时延性能。MFTS 相对于现有方案FFTS 而言,因为不需要在中间缓存设置额外的临时缓存空间,也不需要在输出端口设置重排序缓存,避免了数据包在这两个缓存的等待时延,故其时延性能略有提升。相对于FTSA,MFTS因存在无效调度事件(尽管发生概率较小),其平均时延略有增加。在突发数据流环境中,到达输入端口的数据包是一簇一簇的,数据包在端口容易堆积而使时延性能恶化。图5表明,三种交换方案的平均时延均随负载的增加而迅速上升。基于相同的原因,MFTS 的时延性能仍然优于FFTS 而稍逊于FTSA。
6 结束语
MFTS 特有的多路反馈机制将多路信息汇聚至输入端口,从而为调度算法提供了接近两个时隙的可执行时间。相对于现有方案而言,MFTS的优势在于以下三方面:
(1)算法可执行时间提高到原来的两倍左右;
(2)因为终裁模式能够否决无效调度结果,故MFTS无需设置用于信元冲突的缓存空间,无需设置重排序缓存;
(3)时延性能相对于现有方案略有提升。
考虑到未来更严苛的高速交换环境,后续研究将从降低算法复杂度和降低算法耗时的角度进一步提高中继设备的高速交换性能。
猜你喜欢
汽车维修与保养(2020年10期)2021-01-22
舰船电子对抗(2020年2期)2020-06-23
汽车维修与保养(2020年11期)2020-06-09
计算机技术与发展(2020年5期)2020-05-22
中国自行车(2019年2期)2019-11-16
经济研究导刊(2018年26期)2018-11-14
计算机技术与发展(2018年1期)2018-01-23
现代计算机(2017年5期)2017-03-29
纺织服装周刊(2016年7期)2016-03-07
山东工业技术(2016年5期)2016-03-04
