
虚拟化模型驱动的分布式数据湖构建方法研究*
2019-09-14 07:13谭景信刘玉龙李慧娟
计算机与生活 2019年9期
谭景信,刘玉龙,李慧娟
华北计算技术研究所,北京 100083
1 引言
我国非公有制经济主体已超过9 000 万,贡献了全国税收的50%,GDP的60%,社会固定资产投资的60%,技术创新的70%,就业岗位的80%和90%以上的新增就业,非公有制经济已经成为经济社会发展的重要基础。工商联是党和政府联系非公有制经济的“桥梁纽带”,服务于政府与非公有制经济群体的双向服务需求,这些需求的特点就是体量庞大、不断变化并具有极强的不确定性。做好工商联工作要求兼具广度和深度的数据支撑。广度是指信息收集工作要尽量全面地覆盖9 000 多万的非公有制经济实体,真正做到“广泛联系、直接服务、宣传到位”;深度是指能够及时、高效、深入地了解非公有制经济实体的发展状况和迫切需求,评估出非公有制经济运行发展情况。
非公有制经济群体数据是持续产生的,这些数据具有对象分布广、类型多、碎片化、不确定性强、异构等特点,汇聚起来呈现海量增长特性。如何有效存储、治理和利用这些数据,实现对非公有制经济发展态势的分析、挖掘和预测,从而支撑工商联为党和政府的辅助决策支持是必须要解决的问题。
面向海量数据的汇聚、治理、应用,业界有众多研究成果和实践案例。主要包括传统数据仓库技术、新涌现的数据池与数据湖技术等。但这些技术都不能全面满足所提需求。如:文献[1]采用了大数据平台+MPP 型数据库(GBase 8a MPPCluster)混合架构虽然解决了海量数据存储问题,但因其为关系型数据库,需要规范结构化数据存储模式与强数据依赖关系。文献[2]采用了业务数据Mysql(Oracle)+ETL+缓存数据库(Mysql)+数据仓库(Hive)架构,虽然解决了复杂结构数据聚集问题,但所提非公有制经济实体数据的分布广、碎片化、质量参差不齐等问题仍不能很好得到解决。同时,该方案将全国数据通过ETL(extract-transform-load)进入集中式数据库本地化存储,数据搬运成本极高。另外该解决方案也不能很好处理多模态非结构化文件的存储问题。文献[3]采用了近期较热点的数据湖技术,使用了总部/省两级部署形式和1+N模式,总部存储全量的原生态数据,并实现跨域协作能力,但随着时间的推移,总部数据湖数据会因为缺乏“鲜活化治理”而可能成为“数据沼泽”,该方法也无法解决部分数据源头不愿提供原始数据的问题。
本文在充分分析工商联业务特性的基础上,提出基于虚拟化模型驱动的分布式数据湖构建方法,面向9 000万非公有制经济实体的信息资源,定义了包括统一的数据模型、微分析模型和整套数据规范的虚拟化模型,结合数据边缘计算技术来实现非公有制经济实体内部数据的自治理(生成融合态数据)以及高时效性跨区域非公有制经济数据的协作与深层挖掘。通过对比发现,使用所提方法构建的分布式数据湖具有逻辑集中而物理分散的特点,通过虚拟化模型构建逻辑上的数据湖,实行“有目的”的数据搬运,既解决了部分非公有制经济实体不愿上传原始数据情况下工商联分析业务对大数据的需求,也很好满足了实时处理业务对鲜活数据的需要,同时减少了数据搬运成本,提升了经济性。
2 主流的数据存储方法分析
2.1 数据仓库技术及其局限性分析
传统数据仓库系统实现架构多采用OLTP(on-line transaction processing)+ODS(operational data store)+ETL+OLAP(online analytical processing)+BI(business intelligence)。参见图1 DW/BI(data warehouse/business intelligence)系统模型图。
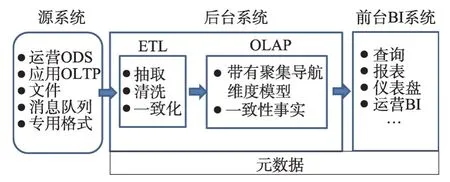
Fig.1 DW/BI system model diagram图1 DW/BI系统模型图
数据仓库可以很好地完成面向主题的、集成的和相对稳定的数据集合处理,能支持经营管理中的决策制定过程[4]。但是数据仓库架构在处理海量异构数据和时效性数据需求时缺陷明显。主要表现在:
(1)传统数据仓库是一个优化的数据库,用于分析来自事务系统和业务线应用程序的结构化数据,数据存储为面向既定主题的,无法满足所提工商联多源、多态、无预置主题的非公有制经济数据存储需求[5]。
(2)数据仓库的存储介质多为中高性能集中式集群数据库服务器,面对海量数据的快速检索,需要高额的服务器、存储的扩展和维护成本。
(3)数据仓库数据的读取需依据严格的数据维度关联规则,无法适用于工商联多模态特性非公有制经济数据资源的数据分析[5]。
(4)基于数据仓库的数据分析运算多为批处理报告、BI形式,无法适应工商联在海量非公有制经济数据的机器学习、预测分析、数据发现方面发展分析需求[6-9]。
2.2 集中式数据湖技术及局限性分析
为解决数据仓库技术在海量数据存储和运算方面的不足,国外近两年提出了数据湖(data lake)技术。数据湖技术目前正处于高速发展中,其优势是可较好支持多模态数据和异构数据的存储和计算,关系型、非关系型数据以及文本、图片、音频、视频等原生态数据均被集中存储于基于HDFS(Hadoop distributed file system)的服务器集群平台之上,这些数据在使用前并不进行处理,而是在使用时才去计算。这种架构具有一定的先进性,但随着数据的不断汇聚,集中式数据湖会产生如下问题[10-12]:
(1)由于集中数据湖汇聚的是数据源产生的原始数据,这些数据的状态和质量不可预见,随着数据量的不断增长,数据治理难度会不断加大,数据湖会因为缺乏有效治理而变成“数据沼泽”。
(2)全量的原始数据通过ETL 工具持续搬运至数据湖中存储,一是会持续占用大量带宽资源,二是规模数据的搬运和治理会产生延迟,最多能保证T+1 的数据时效性,会大幅降低对外发布数据的有效性。
(3)集中式数据湖存储沿时间轴持续采集的原始数据而不太关心这些数据的可用性,存储成本和管理成本会不断攀升,直至难以承受。
3 虚拟化模型驱动的分布式数据湖构建方法
3.1 总体架构思路
针对工商联业务服务对象分布广、类型多、不确定性强等特点带来的分散、碎片化数据收集需求,通过结合数据仓库和集中式数据湖技术的优势,并改进所存在的不足,采用虚拟化模型驱动技术、边缘计算技术和数据路由技术,构建辐射型的、去中心化和去ETL化的分布式数据湖。(1)可弥补传统数据仓库需要有既定主题、强结构化存储的不足,可以存储工商联无主题、多模态原始非公有制经济数据;(2)在中央数据库强化全局数据索引网络,弱化数据物理存储,构建以逻辑模型驱动的一体化分布式数据湖,解决集中式数据湖存在的“数据沼泽”危机问题;(3)采用云端服务技术接入分布在广大非公有制经济实体的边缘数据库,消除了传统ETL 数据延时问题与持续高带宽消耗问题。
所提分布式数据湖的架构设计为三层:非公有制经济实体边缘数据库层、二级区域数据库层和中央数据库层,体系架构如图2所示。
(1)数据湖末端的非公有制经济实体数据库受数据虚拟化模型驱动来实现以数据自清洗和融合为目的的边缘计算与微统计,一是由自身保证数据的正确性、可用性;二是按需提交融合态微统计数据,不必提交节点内部的敏感数据。
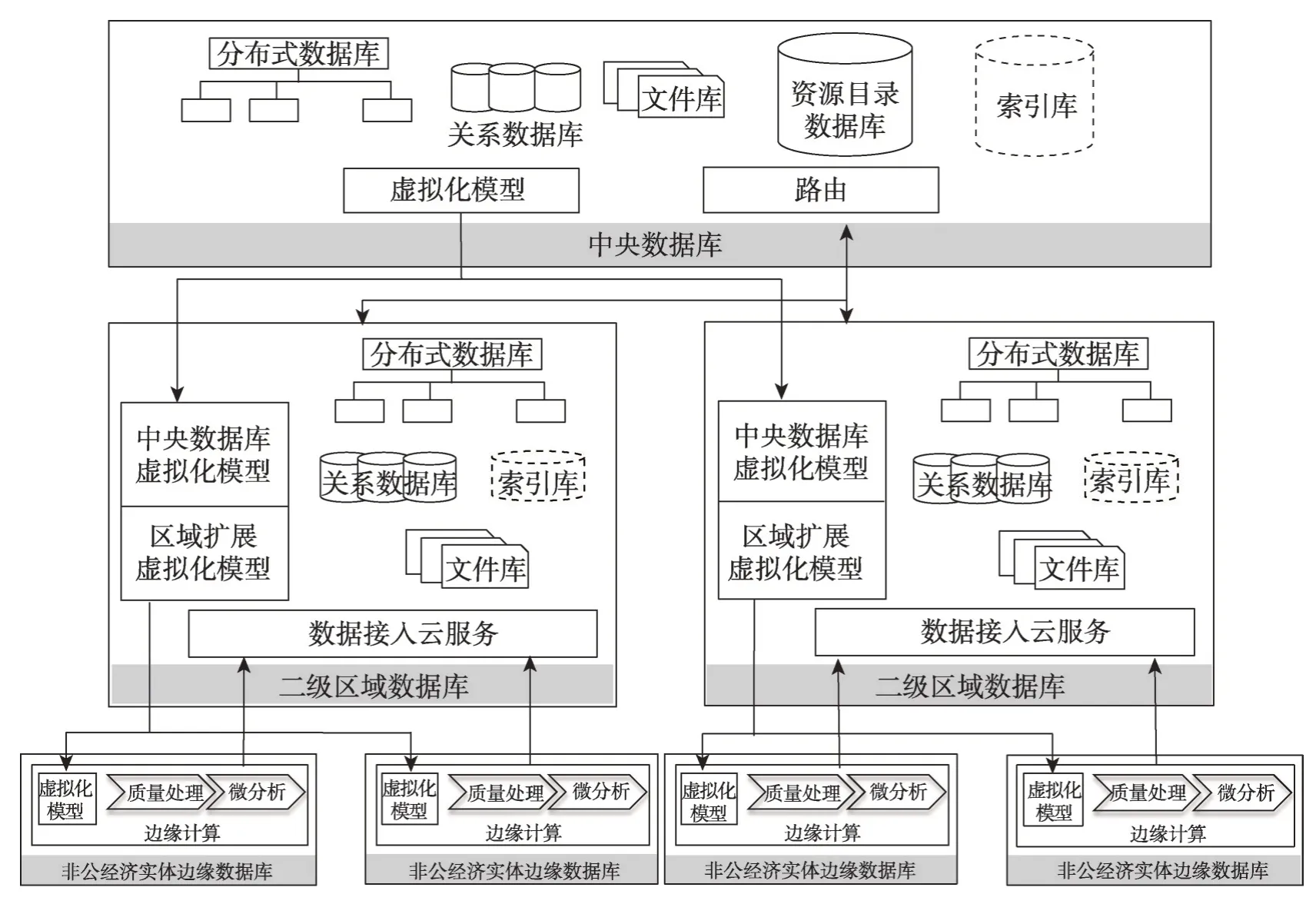
Fig.2 Distributed data lake architecture diagram图2 分布式数据湖体系架构图
(2)由于非公有制经济实体存在不确定强的特点,其节点数据库存在数据不可持续提供等不确定因素,如果分布式体系依靠非公有制经济实体边缘数据库,一旦此边缘节点关闭前置数据库,分布式数据湖将出现数据缺失现象,如果出现大批边缘节点的关闭,分布式数据湖将失效。针对此问题,将基于新经济地理学思想构建二级区域数据库,其将在统一的模型驱动下汇聚区域内的非公有制经济实体的高质、原始态或微统计数据,汇聚的数据可以实现无缝整合,支持区域经济的大数据分析业务。
(3)中央数据库承载对工商联敏捷需求的支撑,由其统筹全域数据索引,按需动态关联二级区域数据库虚拟化模型,生成虚拟数据对象或物理数据对象,以实现全国范围内跨域深层数据的分析挖掘。
(4)二级区域数据库也可向中央数据库申请跨区域数据资源,中央数据库将借助构建好的虚拟化数据链路实现数据路由,构成区域间数据路由,最终实现区域数据协作。
3.2 构建虚拟化数据模型实现去ETL化和去中心化
所提虚拟化模型分为数据模型集、微统计模型集和数据管理规范集,如图3所示。
3.2.1 数据模型集
非公有制经济实体受内部应用系统建设制约,从全国范围看肯定是各自为政建设的,且水平参差不齐,不同单位的系统元数据定义大相径庭,数据项也没有统一编码规则。如何对这些非公经济实体边缘数据库的异构数据进行转换融合,实现标准、规模化的聚合数据是迫切需要解决的问题。
提出了数据模型驱动数据融合概念,构建实体模型、元数据模型、数据映射模型、数据元模型、数据质量校核模型、数据版本模型、资源目录模型、数据服务模型、安全访问模型等。模型用以规范数据的采集内容、采集格式、治理方式、检索方式、存储方式和利用方式。非公有制经济实体边缘数据库数据模型应用过程如图4所示。

Fig.3 Data virtualization model图3 数据虚拟化模型

Fig.4 Application process of edge database model of non-public economic entities图4 非公有制经济实体边缘数据库模型应用过程
(1)聚焦中央数据库关注的有价值的非公有制经济数据形成数据实体规范,非公有制经济边缘数据库需依据数据实体模型选取与之相关的数据内容进行抽象,同时依据数据映射模型对数据进行模式匹配与映射,映射匹配逻辑如下[13-16]。
假设边缘非公有制经济实体数据库为A,分布式数据湖的二级区域数据库的标准数据库为B:
①在数据库A中包含数据集合C,A={C1,C2,…,Ct}。
②在数据库B中包含数据集合D,B={D1,D2,…,Dr}。
③A中C可以表示为列向量的集合,Ci={p1,p2,…,px}。
④A中包含t张表,每张表包含x个字段,构成矩阵
⑤B中D可以表示为列向量的集合,Di={q1,q2,…,qy}。
⑥B中包含r张表,每张表包含y个字段,构成矩阵
⑦数据汇聚到二级区域数据库B后,产生数据记录,针对Di有y个字段s条记录,则每个记录值为tiys,即
⑧由B和Di综合来看,实际构成了一个三维记录数值模型,如图5所示。

Fig.5 Three-dimensional recording numerical model图5 三维记录数值模型
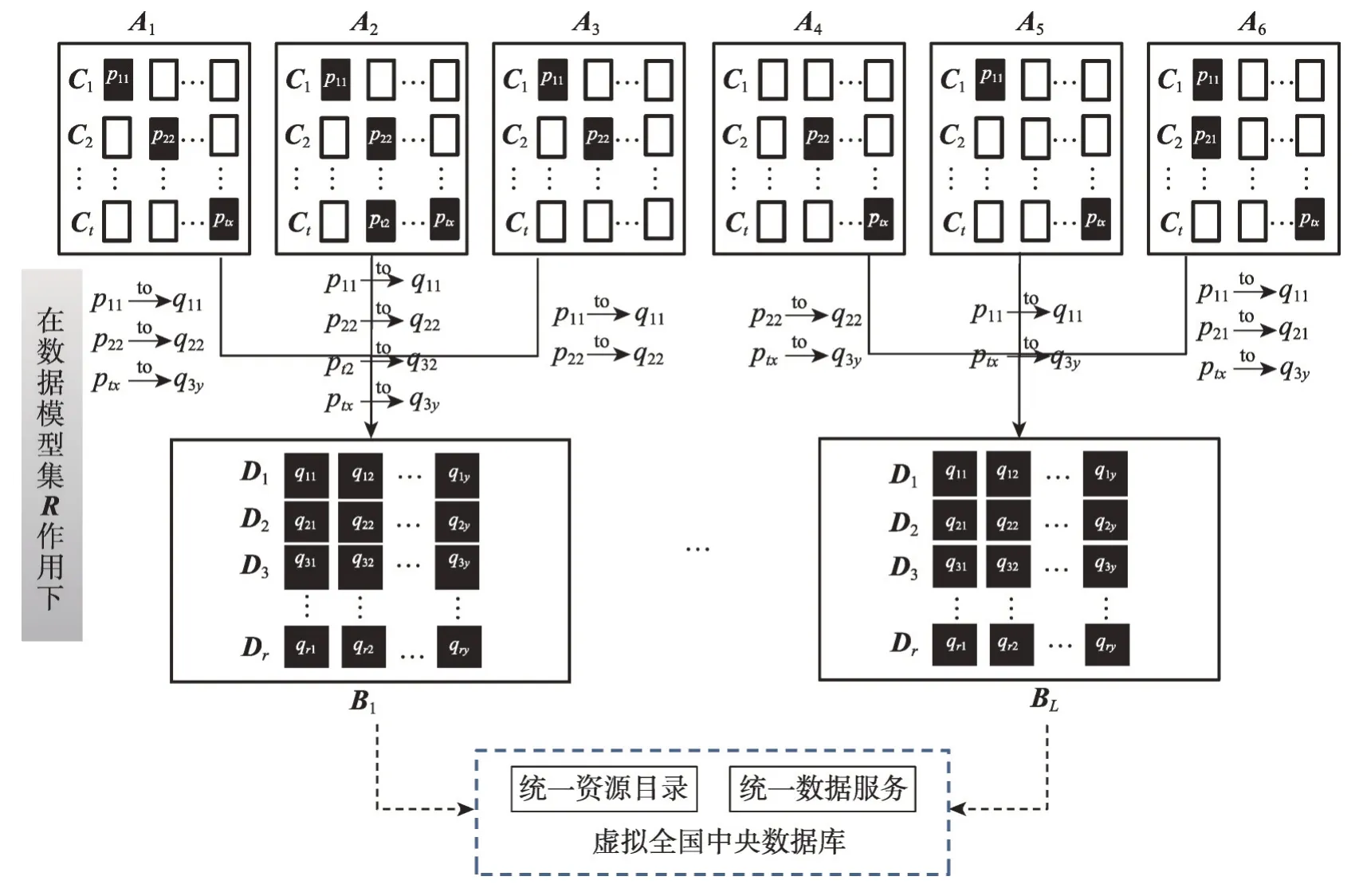
Fig.6 Data pattern matching logic图6 数据模式匹配逻辑
⑨在B中根据实体模型和数据映射模型会产生A到B的模式匹配规则:R=f(C),R={R1,R2,…,Rm},在R的作用下对不同Ci进行整合生成Di,从而产生B。规则R主要包括:数据源定义、目标数据库定义、数据源表定义、数据源数据域定义、目标数据库表定义、目标数据域定义、数据更新机制定义、时间戳定义、数据更新条件组合定义、提交数据范围定义、数据受众范围定义等。
⑩全国各地非公有制经济实体数据映射到不同二级区域数据库,将形成庞大的分布式数据湖泊B1到BL,覆盖整个非公有制经济数据资源,全国数据矩阵K为:
数据模式匹配逻辑如图6所示。
(2)广大非公有制经济实体对象映射数据的格式依据数据元格式进行规范,依据数据元模型进行描述和转换。这两个模型对映射数据Di产生数据定义规则H=f(D),主要内容包括字段名称、字段类型、字段长度、字段定义描述、字段业务含义描述等。
(3)对标准化的匹配数据进行暂存。
(4)非公有制经济实体根据数据质量校核模型对数据自检验和清洗,以保证数据的完整性、有效性和正确性,同时有全国编码的数据需要依据编码规则进行转换和补充,以保证汇聚数据之间的协作、共享和聚合分析。以上模型生成清洗规则为O=f(D),主要包括:校核数据域、校核格式、校核算法、校核任务、校核警戒线、校核输出日志模式;清洗对象、清洗算法、清洗任务、清洗输出格式、异常数据日志模式;编码转化类型、编码格式、编码含义、转换算法、转换任务、异常数据规范等。
(5)对清洗后合规数据进行持久化存储。
(6)在二级区域数据库和中央数据库实现对汇聚数据的统一存储、统一资源目录、统一服务和统一安全访问管理。区域数据库在数据版本模型控制下实现对数据的有序存储,版本模型包括数据更新记录与数据加工记录,可以实现全局数据溯源与血缘分析;中央数据库在数据目录模型控制下建立全国统一资源目录,实现全国数据一本底账;同时,依据数据服务规范构建数据服务平台,在安全访问模型控制下为全国提供有效的数据共享。
3.2.2 数据微统计模型集
数据微统计模型集规定了一组末端非公有制经济实体数据库需统计的内容与统计算法,统计功能将通过二级区域数据库云平台提供,只将形成融合态的统计数据保存于二级区域数据库中。统计数据涉及但不限于以下方面:企业分支机构信息、企业上市信息、企业投资信息、企业财务信息、企业纳税信息、企业资质信息、企业创新信息等。
3.2.3 数据管理规范
数据管理规范为各级数据库和节点在数据产生、清洗、整合、利用、消亡、管理整个生命周期应遵循的数据规范。主要包括:数据存储规范、数据治理规范、数据资源目录规范、数据服务规范等。其规定了参与数据活动的相关方的义务与责任、引用的相关数据模型、数据传递的流程等。从而保障整个数据体系的安全、有效、可持续运转。
3.2.4 去ETL化去中心化的分布式数据湖
(1)非公有制经济实体数据库准备数据就绪后,传统方法是采用ETL 方式进行数据上传,但这种方式面对分布广泛的数据源很难实施,例如:针对北京地区节点就需要完成4 000 余家企业同步任务的配置,整个运维工作是相当庞大的;(2)同步如果不采用错峰方式,在短时间内中央数据库网络节点会产生高带宽消耗,但如果错峰会增加ETL设计与运维的复杂度;(3)传统的集中式存储需要高昂的硬件设备资源;(4)集中处理广泛来源的非公有制经济数据,并且面向全国的数据传输也会给数据库造成很大压力。
提出去ETL 和去中心化分布式数据湖技术,依据新经济地理学理论选择中心城市建设物理分散的分布式二级区域数据库。
对二级区域数据库的划分主要包括:活动数据域、历史数据域和文件数据域,每类数据域共涉及参政调研、非公服务、组织建设、思想引导、社会服务、综合管理以及扩展业务七大数据类别。文件数据域主要包括:结构化、半结构化数据文件以及文本、图片、音频和视频非结构化文件等。
非公有制经济边缘数据库产生内部数据后,依据所提虚拟化模型进行校核、清洗、转化与微统计,通过调用云服务方式实时将数据汇聚于二级区域数据库活动数据域的不同类别数据中,同时将更新的历史数据迁移至历史数据域。
3.3 多源异构的数据生产节点和边缘计算
将产生多源异构数据的非公有制经济实体节点定义为端节点,这些端节点物理上分散且数量庞大,是整个分布式数据湖体系中的边缘节点,而这些节点的上级区域定义为云端。这些节点大多为中小企业,每日产生的数据量不多,但种类繁多,且非公有制经济实体的出现和消亡具有极强的不确定性,针对这种碎片化特点,采用边缘计算与计算结果通过数据服务上传相结合的技术。边缘非公有制经济实体节点主要包括:非公有制经济实体生产数据库、逻辑前置数据库、数据服务代理服务器等。
非公有制经济实体边缘数据处理过程如图7所示。
非公有制经济实体生产数据库为其内部数据库;逻辑前置数据库为以虚拟形态或物理形态存在,为区域数据库准备抽象数据实体的质量合规数据;首次数据上传采用数据文件提交形式,增量数据上传通过调用在数据服务代理上发布的解析前置数据、与云服务对接的应用API(application programming interface)方式实现;文件上传可以调用云端文件上传功能,文件如果关联数据,则需要开发与云服务对接API,实现数据与文件的同时上传。
采用边缘计算方式的主要优势在于,数据准备与处理工作将交由各非公有制经济实体节点分散完成,不用发送全部数据到云端,消除区域数据库治理数据的复杂性与数据发送的网络压力;由于数据在做拆分或组合后形成前置数据,从前置库中读取可以较容易保证数据的一致性;云端数据服务将不直接嵌入其业务应用系统,使数据生产与服务调用解耦,不用改造其生产应用系统。
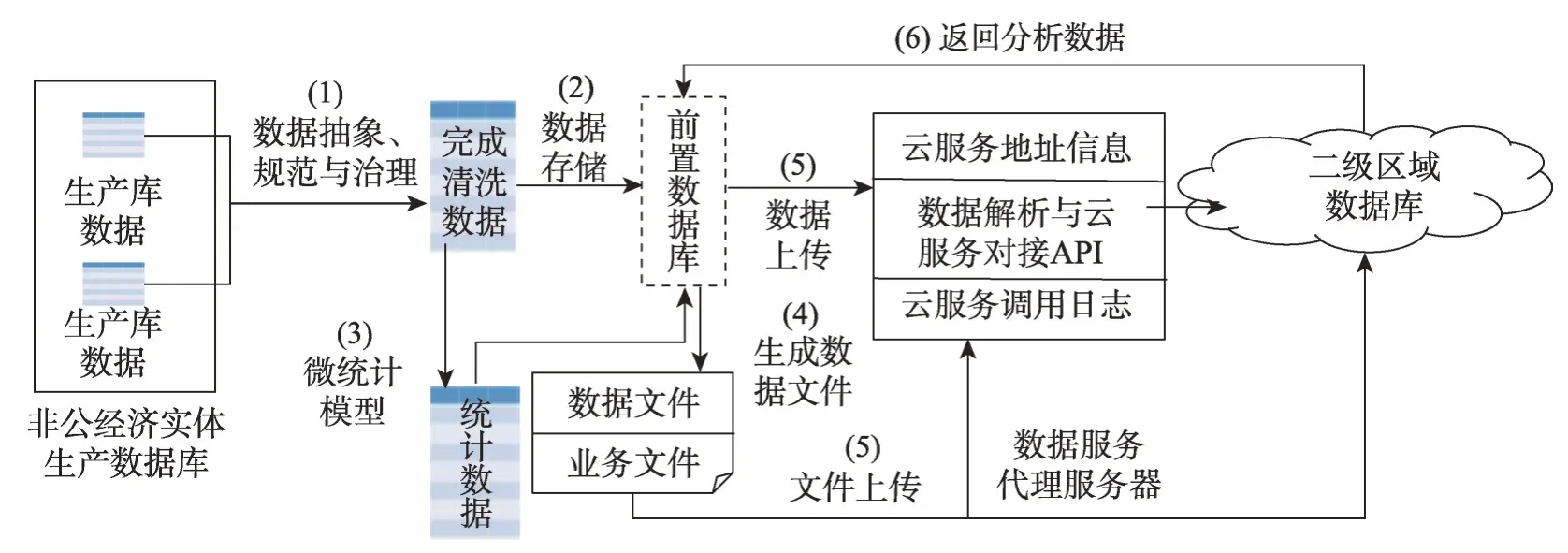
Fig.7 Process flow diagram of edge data processing of non-public economic entities图7 非公有制经济实体边缘数据处理过程图
在边缘非公有制经济实体节点可实现实体自身数据分析。区域分析数据可以通过云服务返回非公有制经济实体与其内部数据相融合,实现快速边缘数据深度探索,辅助非公有制经济实体不断调整经营决策,优化产业结构,进行前端产品技术研发,构建符合自身发展的产业链、客户关系链和产业金融链。
3.4 基于分布式架构实现数据库间路由
提出中央数据库路由方法来实现分布式数据湖体系中各区域数据库之间的数据互操作。构建完整的资源目录与数据索引体系,实现凭借路由调度控制实现点对点去中心化二级区域数据库通信。此种方式有效规避数据总线应用模式下可能产生的集中式通信“雪崩”效应,提高了数据库的高可用性、高可靠性和高可扩展性。
中央数据库作为分布式数据湖路由核心,其将重点实现数据目录检索、数据服务发布和申请审核、数据索引、数据寻址与路由,但不集中存储全量数据。主要包括:数据索引服务器、目录服务器、数据服务管理服务器、配置服务器、调度服务器、通信服务器、数据库服务器。
一个数据库数据调用者与跨地域数据库数据提供者的数据协作过程如图8所示。
数据调用者借助数据资源目录确认所需资源并向中央数据库提出申请。审批后,中央数据库进行数据提供者区域寻址,通知并确认其资源准备就绪,将数据库连接通道配置信息保存,并通知数据调用者,数据调用者与数据提供者间建立点对点直连,后续为长连接过程,数据库连接将不会再访问中央数据库。中央数据库持续监控连接过程,确保数据合法使用,当数据利用时效结束或出现非法使用数据的状况,中央数据库通知数据调用者和数据提供者,数据提供者关闭数据连接,数据调用者失去数据库直连权限。
4 虚拟化模型驱动的分布式数据湖构建方法的优势
虚拟化模型驱动的分布式逻辑数据湖构建方法实现了去中心化分布式存储,中央数据库重点建设全域数据索引,实现全域数据管控,同时承担数据路由角色,为跨域数据协作提供支撑;中央数据库可快速应对应用需求变化,通过虚拟视图方式或短期物理存储方式获取不同地域非公有制经济数据,保证数据时效性,提高数据分析挖掘的可信度;逻辑数据湖内各级存储资源可呈现多模态化,支持关系型、非关系型数据以及文本、图片、音频、视频等数据存储;数据质量治理交由非公有制经济边缘数据库自行承担,提高数据治理可操作性、数据可信度和可用性;中央数据库将实现对存储资源的动态伸缩利用,减低设备投资和维护成本;各区域由于只存储本地数据,基础设施建设和维护成本将可控。
所提数据仓库系统的代表包括早期的国网系统、银行系统;随着大数据分析条件的逐步具备和决策支持业务对数据总量的需求越来越大,这些数据仓库系统逐步向集中式数据湖系统发展,但随着数据量的持续堆积,集中式数据湖的治理问题越发突出。对比发现,所提虚拟化模型驱动的分布式数据湖构建方法相比传统的数据仓库技术、集中式数据湖技术,在同时满足工商联分析业务对大数据的需求和实时处理业务对鲜活数据的需要方面具有优势,尤其在减少数据搬运成本,提升经济性方面存在较明显的优势,结果参见表1。

Fig.8 Process flow diagram of data invoke图8 数据调用过程图
5 结束语
本文提出的虚拟化模型驱动的分布式数据湖构建方法,是集成碎片化、多模态非公有制经济数据的较有效方法。所提方法将边缘计算、新经济地理区域数据库建设、大数据分析与挖掘、数据路由等技术相融合,实现了非公有制经济数据在虚拟模型驱动下的区域协同。
所提方法在构建工商联分布式数据湖体系中得到了初步的应用尝试,并在持续完善中。工商联分布式数据湖体系以全国工商联本级为中央数据库节点,按照新经济地理学选取6个省级工商联作为二级区域节点,建立二级区域数据库,6 个省级二级区域节点负责联系全国9 000 万非公有制经济实体边缘节点,并保持与边缘节点的通信畅通。在实际的业务开展过程中,各非公有制经济实体作为此体系中的边缘节点,不断产生原始数据,并在本地端存储,这些数据由边缘非公经济实体在数据模型驱动下完成清洗后,提交主数据和融合态、微统计数据给二级区域节点。全国工商联中央数据库维护了一个完整的数据资源目录和资源门户,掌控着全国数据的一本底账,并承担了数据交换共享“总调度”的角色,其通过数据路由按需访问二级区域数据库,提取鲜活数据进行分析,支撑辅助决策需求。此种分布式数据湖架构确实在提升大数据分析挖掘效能、实现数据的按需搬运与虚拟调用方面成效明显,很大程度上降低了中央节点数据存储压力,同时也改善了频繁搬运数据带来的高网路带宽消耗问题,使工商联在面向9 000 万非公有制经济实体构建高价值生态数据资产平台成为可能。
下一步,将对所提方法在边缘节点是否处于活动状态,及时高效地发现掉线节点方面的效率问题进行优化。同时,在部分区域中心节点和边缘节点掉线的情况下,如何快速建立数据补全机制,提升分布式数据湖体系的自我完善能力和健壮性也是本文下一步需持续研究的重点。

Table 1 Comparison among data warehouse,centralized data lake and distributed data lake表1 数据仓库、集中式数据湖与分布式数据湖对比
猜你喜欢
攀登(2022年2期)2022-11-27
电子乐园·下旬刊(2021年3期)2021-02-08
电子制作(2019年10期)2019-06-17
电子制作(2018年14期)2018-08-21
山东工业技术(2016年15期)2016-12-01
国外科技新书评介(2016年8期)2016-11-16
四川党的建设(2015年6期)2015-06-19
卷宗(2014年12期)2014-04-02
中国商人(2012年5期)2012-08-15
中国商人(2012年5期)2012-08-15
