
基于符号执行的缓冲区溢出漏洞自动化利用
2019-09-13 03:39胡建伟崔艳鹏
计算机应用与软件 2019年9期
李 超 胡建伟 崔艳鹏
(西安电子科技大学网络与信息安全学院 陕西 西安 710071)
0 引 言
信息技术的快速发展使得计算机软件在社会活动与工业生产中起着越来越重要的作用。同时,软件规模与数量的快速增长给信息安全带来了严峻的挑战。信息系统中存在软件漏洞是导致信息安全问题的重要原因。软件漏洞通常指软件系统在设计、实现、配置、运行等过程中,由操作实体有意或无意产生的缺陷、瑕疵或错误,它们以不同形式存在于信息系统的各个层次与环节中。为确保信息系统的安全,众多研究人员对漏洞分析与防护问题进行了大量的研究工作。然而,由于冯·诺依曼计算机体系自身的缺陷,以及当前软件系统的代码规模和技术复杂度的急剧提升,并且在软件生命周期的每个阶段都需要人工参与,难免会引入一些错误,导致无法彻底清除软件中存在的漏洞。
在不能完全杜绝漏洞存在的情况下,需对其进行分析与研究,以最小化漏洞所带来的损失。由于大多数商业软件都不公开源码,并且二进制代码是软件的最终表现形式,分析二进制代码可以更加全面和直接地找到软件中存在的漏洞,因此,二进制漏洞分析技术更具有实用性。文献[1]的数据显示,2017年新增漏洞中,缓冲区溢出漏洞为数量最多的漏洞类型,占新增漏洞总量的18.06%,远远高于其他漏洞类型。因此,研究缓冲区溢出漏洞具有重要意义。
面对各类信息系统中存在的大量漏洞,CNNVD[2]等组织对漏洞进行统一的分类管理,评估漏洞的危害性并将其标记为不同危害等级,指导软件厂商采取相应的修复措施,从而减少漏洞带来的威胁和损失。通常可利用的软件漏洞具有很高的危害性,攻击者往往通过这些漏洞控制目标系统。因此,在漏洞响应过程中,需要快速甄别大量软件错误中的可利用漏洞。虽然使用模糊测试技术发现软件错误具有很好的效果,但由于漏洞类型的多样性和漏洞形成机理的复杂性,漏洞可利用性的评估和利用数据的构造通常需进行动态调试分析漏洞形成的细节,这个过程由分析人员以手工方式完成,并且要求分析人员熟悉汇编语言等计算机底层原理。随着软硬件产品和应用的快速增长,漏洞数量急剧攀升,2017年共发布漏洞信息13 417条,漏洞数量达到2016年的近2倍[1]。因此,传统漏洞分析方式已难以应对上述挑战。
为提高软件漏洞风险评估的效率,本文研究缓冲区溢出漏洞,提出一种面向二进制程序的自动化漏洞利用方法,通过构建exploit证明漏洞的危害性。该方法首先使用符号执行检测漏洞,然后构建路径约束表达式和利用约束表达式,最后通过约束求解器求解得到exploit。
1 相关工作
目前已有学者对自动化漏洞利用进行了研究,并取得了一定的进展。由Brumley等[3]提出的APEG基于补丁比对的方法定位程序中已修补的漏洞,通过分析补丁中添加的过滤条件,构造不满足过滤条件的输入触发漏洞。该方法无法适用于补丁中没有添加过滤条件的情况,并且构造的输入只能进行拒绝服务攻击。相对于APEG对补丁的分析,Avgerinos等[4]提出了基于源码的漏洞自动挖掘和利用方法AEG,AEG使用预置条件的符号执行找到程序漏洞,利用动态二进制插桩获取程序运行时信息,构建约束表达式,并求解得到可实现控制流劫持攻击的利用数据。
为了能够在无法获取程序源码的情况下自动构造利用数据,Heelan[5]提出了基于二进制程序的漏洞自动利用方法。该方法以可触发漏洞的样例作为输入,通过代码插桩定位到漏洞,并使用污点分析找到可用于存放攻击代码的可控内存,构建生成利用数据所需的约束表达式,最后求解得到控制流劫持攻击利用数据。Cha等[6]提出的漏洞自动利用生成方法Mayhem使用混合符号执行技术,分析过程中符号执行引擎在离线符号执行与在线符号执行间不断切换,以减少内存消耗,缓解状态爆炸问题。此外,该方法使用基于索引的内存模型优化符号化内存的加载提高系统效率。Wang等[7]提出自动化生成多样性漏洞利用的方法PolyAEG,该方法以崩溃样例为输入,通过动态污点分析获得程序执行的相关信息,构建污点传播流图和全局污点状态记录获取程序中所有可能被控制的劫持点、跳板指令和内存区域,最后利用不同的跳转指令和可控制内存区域构造多样性的利用样本。Huang等[8]提出的CRAX同样以崩溃样例为输入对程序进行全系统模拟的符号执行分析,分析过程中对漏洞利用不相关的库函数或内核函数进行具体执行,以优化符号执行,提高处理速度。该方法可适用于Microsoft office word等规模较大的应用程序。
相对于上述面向控制流的利用方法,Hu等[9]提出了面向数据流的自动利用方法FlowStitch,利用内存错误修改程序数据流中的关键变量,可达到敏感信息泄露或提权的攻击效果。该方法可实现敏感信息泄露,因此实用性较强。其缺点是需要能触发内存错误的输入。由于堆管理机制的复杂性,导致堆漏洞利用的难度相对较大,Revery[10]对堆漏洞自动化利用问题进行了探索,在19个测试程序中可成功对9个程序生成利用。此外,NAVEX[11]对Web应用漏洞自动构造利用数据,可成功利用SQL注入和XSS漏洞,该方法与二进制漏洞利用有较大的差别。
综上所述,APEG和AEG分别依赖于补丁和源码检测漏洞;Mayhem使用符号执行检测漏洞,采用具体化部分符号变量的方法减少搜索空间,但可能导致漏洞不可利用;文献[5]和文献[7-9]均依赖于已知的崩溃输入,无法自动检测程序中存在的漏洞。此外,上述方法未考虑进程中不存在空间足以容纳shellcode的可控内存块的情况,构造利用的适用性较差。本文所提方法使用符号执行检测漏洞,通过切片减少状态数量,并改进漏洞利用时shellcode存放方式,可提高系统适用性。
2 缓冲区溢出漏洞自动化利用
缓冲区溢出漏洞产生的原因是程序未正确检查用户输入数据的长度是否超过目标缓冲区的大小,向缓冲区写入过多数据覆盖了内存中其他数据,可能导致控制流劫持。通过缓冲区溢出劫持控制流的常见方法包括覆盖栈中函数返回地址和覆盖函数指针。利用代码注入或代码复用[12]可实现执行任意代码。代码注入将一段攻击代码写入进程空间,之后劫持控制流到攻击代码执行;代码复用将内存中已有的代码片段拼接成可实现特定功能的攻击链进行攻击。本文主要研究代码注入攻击的自动化。
本文基于二进制分析框架angr[13]设计并实现缓冲区溢出漏洞自动利用原型系统AutoExp(Automatic Exploitation),该系统以漏洞程序为输入,使用符号执行[14]检测漏洞,通过构建约束表达式和约束求解生成exploit。以exploit作为程序输入可触发漏洞,并利用漏洞达到获取系统控制权、运行任意代码或窃取数据等目的。
如图1所示,自动化生成exploit包括4个步骤:1) 预处理。为了减小漏洞检测过程中符号执行的状态空间,首先扫描目标程序中危险函数调用位置,然后通过程序切片技术获取危险函数调用位置到程序入口点的代码切片。2) 漏洞检测。针对上一步得到的切片进行符号执行,记录每个状态的路径约束、寄存器和符号内存信息。同时,每运行一步均检测是否存在包含漏洞的状态。3) 构建利用约束。找到漏洞后,判断漏洞的可利用性,通过构建shellcode约束将可控内存区域的值约束为shellcode以实现攻击代码注入,构建EIP约束将EIP寄存器的值约束为shellcode存放地址以实现控制流劫持。4) 约束求解。使用约束求解器求解路径约束和利用约束,若有解则成功生成exploit。

图1 漏洞自动利用系统设计
2.1 基于符号执行的漏洞检测
漏洞自动化利用的前提条件为找到程序中存在的漏洞,本文采用符号执行检测漏洞。符号执行以符号变量代替具体值作为程序输入,并动态模拟执行程序中的指令,在执行过程中记录寄存器和内存状态。当遇到分支语句时,复制程序状态以便继续分析所有分支,并构建路径约束表达式记录到达不同分支的路径信息。符号执行过程中,根据不同漏洞模型设置违例断言可检测程序中存在的漏洞。
由于符号执行分析过程中每一个分支语句都可能导致新增一条路径,所以路径数量可能按指数级别增长,即存在状态爆炸问题。为了缓解状态爆炸问题,并且使分析过程更具有针对性,本文提出基于危险函数切片的方法获取包含危险函数调用的程序切片,符号执行时根据切片剔除无关路径。
2.1.1预处理
控制流劫持漏洞的利用主要关注漏洞脆弱点和控制流劫持点[15],漏洞脆弱点指导致漏洞产生的函数或指令,而控制流劫持点指程序控制流被输入数据控制的指令。缓冲区溢出漏洞多是由于程序中使用了危险函数,并且未对用户输入数据进行严格的检查所导致的。因此,缓冲区溢出漏洞的脆弱点往往为危险函数调用位置。常见危险函数如表1所示。

表1 危险函数列表
预处理过程如算法1所示,首先通过静态分析获取程序中的脆弱点位置。具体方法为,根据预先定义的危险函数名列表unsafe_func_name查找程序链接表PLT(Procedure Linkage Table)得到危险函数地址unsafe_func_addr;根据地址查找控制流图CFG(Control Flow Graph)得到所有危险函数节点unsafe_nodes,获取危险函数节点的前驱节点即可得到危险函数调用点地址列表unsafe_callsites。接着对危险函数调用点进行程序切片[16],得到从程序入口点到危险函数调用点的切片。具体方法为,分析程序数据依赖关系和控制依赖关系构建数据依赖图ddg(Data Dependence Graph,DDG)和控制依赖图cdg(Control Dependence Graph,CDG),根据ddg和cdg使用轻量级污点分析[17]从危险函数调用点target进行后向切片得到切片bk_slice。
算法1预处理
输入:目标程序program, 危险函数名列表unsafe_func_name
输出:程序切片bk_slice
1 plt = get_plt(program)
// 获取程序 plt 信息
2 cfg = create_cfg(program)
// 构建程序CFG
/* 获取每个危险函数的调用点 */
3 for fname in unsafe_func_name:
4 unsafe_func_addr = plt[fname]
// 根据CFG得到程序中所有危险函数节点
5 unsafe_nodes = cfg.get_all_nodes(unsafe_func_addr)
// 获取危险函数节点的前驱节点得到危险函数调用点
6 for node in unsafe_nodes:
7 unsafe_callsites.append(node.predecessors.addr)
/* 根据危险函数调用点进行切片 */
8 ddg = create_ddg(cfg)
// 构建DDG
9 cdg = create_cdg(cfg)
// 构建CDG
10 for target in unsafe_callsites:
11 bs=create_backward_slice(cfg, ddg, cdg, target)
//切片
12 bk_slice.append({‘target’: addr, ‘slice’: bs})
13 return bk_slice
2.1.2漏洞检测
符号执行引擎[13]在模拟运行程序时,以状态(state)表示程序的执行过程,其中记录了程序的执行路径和内存、寄存器等运行时信息;使用模拟管理器(SimulationManager)控制符号执行过程,可管理不同类型的状态和使用搜索策略探索程序状态空间。SimulationManager通过stash管理active、found、unconstrained等不同类型的状态,active state为当前正执行的状态,found state为通过设定探索目标所找到的状态unconstrained state为不受约束的状态。
符号执行以符号值替换用户输入,如果程序中存在缓冲区溢出漏洞,当程序运行到漏洞劫持点时EIP寄存器将被符号化,由于符号化变量不是具体值,符号执行引擎不能确定下一步需执行的指令,导致无法继续运行,此时状态类型为unconstrained。因此,通过判断符号执行过程中是否存在unconstrained状态即可检测缓冲区溢出漏洞。
算法2描述了漏洞检测方法。符号执行过程中,在程序入口点与脆弱点间运行时根据预处理得到的切片进行状态修剪,剔除切片之外的路径,以减少状态数量。具体方法为,符号化用户输入并创建模拟管理器simgr,接着获取切片bk_slice中脆弱点地址(即危险函数调用点)target作为符号执行的探索目标。同时设定状态修剪策略函数drop_states_not_in_slice,该函数判断active stash中的状态是否在切片范围内,若是则返回False,即保留该状态;否则返回True,丢弃该状态。当找到脆弱点状态后,丢弃active中所有状态,并把脆弱点状态从found stash移动到active stash以便从脆弱点继续运行;找到脆弱点之后继续执行,当unconstrained stash非空时则表明存在控制流劫持点,即找到漏洞状态vul_state。
算法2漏洞检测
输入:目标程序program, 切片bk_slice
输出:漏洞状态vul_state
1 for slice in bk_slice:
/*程序入口点到脆弱点间运行时根据切片进行状态修剪*/
2 sym_input = symbolic(input)
// 符号化用户输入
3 init_state = entry_state(program, sym_input)
//创建初始状态
4 simgr = simulation_manager(init_state)
// 创建模拟管理器
5 target = slice[‘target’]
// 获取脆弱点地址
// 以脆弱点为目标进行符号执行,并设定状态修剪策略
6 simgr.explore(find=target, filter=drop_states_not_in_slice)
// 若找到脆弱点状态,则使active stash中只包含该状态
7 if simgr.found not NULL:
8 simgr.drop(stash=′active′)
9 simgr.move(from_stash=″found″, to_stash=″active″)
/* 从脆弱点继续探索,直到找到unconstrained状态 */
10 while simgr.unconstrained is NULL:
11 simgr.step()
// 向前执行一步
12 vul_state = simgr.unconstrained
13 return vul_state
2.2 基于约束求解的利用生成
2.2.1利用约束构建
进程空间中存在可控内存块是进行代码注入攻击的必要条件。进程中可控内存区域并非都是连续的,为了找到能存放shellcode的可控内存块,需获取可控内存块信息,包括内存块的起始地址和大小。获取可控内存块信息的方法如算法3所示,首先获取漏洞状态vul_state中符号化内存地址列表sym_addrs;然后根据地址是否连续来统计内存块的大小size,并记录内存起始地址buf_start;最后将内存块按空间从大到小的顺序排序。
算法3获取可控内存块信息
输入:漏洞状态vul_state
输出:符号化内存块sym_bufs
// 获取符号化内存地址列表
1 sym_addrs = find_symbolic_addr(vul_state)
2 while sym_addrs not NULL:
3 size = 0
// 设定内存块初始大小
4 buf_start = sym_addrs[0]
// 记录内存块起始地址
/* 统计连续内存地址组成的内存块大小 */
5 while True:
6 if not buf_start + size in sym_addrs:
7 break
8 sym_addrs.remove(buf_start + size)
//删除已处理地址
9 size += 1
10 sym_bufs.append({‘addr’: buf_start, ‘size’: size})
11 sorted_by_size(sym_bufs)
// 根据内存块大小排序
12 return sym_bufs
当进程空间中不存在足以容纳shellcode的可控内存块时,现有方法将无法成功构建exploit。如图2所示,为提高漏洞自动利用系统的适用性,AutoExp把shellcode分段存放在多个可控内存块,并使用跳转指令连接不同内存块中的攻击代码,从而完成攻击过程。

图2 shellcode分段存放
对shellcode分段时应确保指令的完整性,本文将机器码形式的shellcode反汇编为汇编指令,分段时以指令为基本单位。算法4具体描述了分段的方法,首先反汇编shellcode为汇编指令asm,根据可控内存块信息与shellcode大小确定分段数量和每个片段的长度segs_len;接着根据片段长度对shellcode进行分段;最后在除末尾片段外的所有片段后添加跳转指令jmp_ins。
算法4shellcode分段
输入:符号化内存块sym_bufs, 攻击代码shellcode
输出:shellcode片段sc_segments
1 asm = disassemble(shellcode)
// 反汇编shellcode
/* 确定每个片段的长度 */
2 length = 0, n = 0
// 初始化片段长度length和内存块序号n
3 for ins in asm:
// 若当前内存块还能容纳指令ins,则划分在该内存块
4 if length + ins.size <= sym_bufs[n].size-len(jmp_ins):
5 length += ins.size
6 else:
// 否则,当前内存块已存满,考虑下一个内存块
7 segs_len.append(length)
8 length = 0, n += 1
/* 在除末尾片段外的所有片段后添加跳转指令 */
9 for len in segs_len not last:
10 sc_segments.append(shellcode[:len] + jmp_ins)
11 shellcode = shellcode[len:]
// 删除已处理的数据
12 sc_segments.append(shellcode)
13 return sc_segments
利用缓冲区溢出漏洞进行代码注入攻击需要两个步骤,分别是把攻击代码写入进程空间和劫持程序控制流到攻击代码处,该过程可通过构建shellcode约束表达式和EIP约束表达式的方法实现自动化。如算法5所示,首先需把shellcode片段写入进程中对应的可控内存块,实现方法为依次加载可控内存块sym_bufs[n],并构建约束表达式将内存块中数据约束为对应的shellcode片段sc_segments[n];接着构建约束表达式将漏洞状态的EIP寄存器值约束为shellcode存放内存的起始地址sym_bufs[0].addr。
算法5构建利用约束
输入:漏洞状态vul_state, 符号化内存块sym_bufs, shellcode片段sc_segments
输出:约束表达式constraints
/* 依次约束可控内存块中数据为对应shellcode片段的值 */
1 for n in range(len(sc_segments)):
// 加载可控内存块
2 memory = vul_state.load_mem(sym_bufs[n].addr)
// 将可控内存块中数据约束为shellcode
3 vul_state.add_constraints(memory == sc_segments[n])
4 constraints.append(memory == sc_segments[n])
/* 约束EIP寄存器的值为shellcode起始地址 */
5 vul_state.add_constraints(vul_state.eip == sym_bufs[0].addr)
6 constraints.append(vul_state.eip == sym_bufs[0].addr)
7 return constraints
2.2.2约束求解
对于上述构建的路径约束表达式和利用约束表达式,使用支持SMT求解理论的Z3求解器[18]进行求解。若有解,则得到一个可触发漏洞并进行代码注入攻击的exploit;若无解,则表明检测到的漏洞无法利用。
3 实验与分析
实验运行环境为Intel Core i7-7700HQ CPU,主频2.8 GHz,4 GB内存, Ubuntu 16.04 64 bits系统,测试程序使用gcc 5.4.0 编译。本文不考虑漏洞缓解机制的绕过,编译时不启用NX和Stack Canary保护,同时关闭系统ASLR保护[19]。为验证系统的有效性,本文设置两组实验,分别用于验证漏洞检测效果和测试自动生成利用数据的有效性。
3.1 漏洞检测
实验选取以下3个已披露漏洞作为测试样本,分别使用angr和本文实现的AutoExp检测目标程序中存在的漏洞,并记录两种方法检测漏洞所需时间。实验结果如表2所示,表中第三列和第四列分别为目标程序的基本块数量和使用AutoExp进行预处理所得切片的基本块数量。从实验数据可知,使用切片技术对程序进行预处理可减少待分析程序的基本块数量,从而有效减小符号执行分析的复杂度。
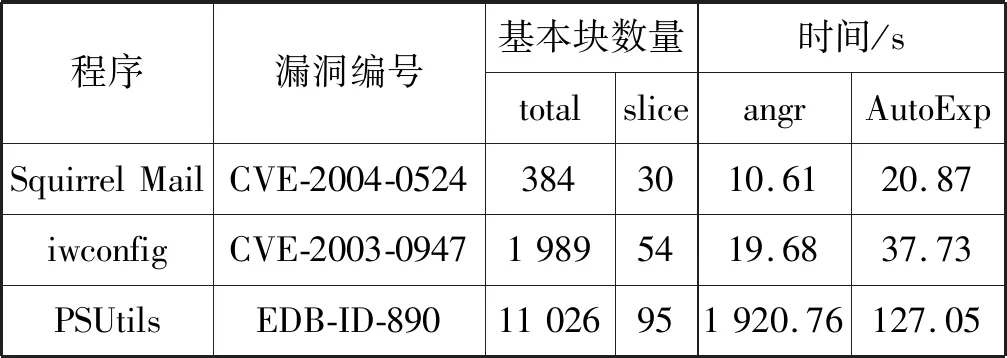
表2 漏洞检测结果
表2使用两种方法检测漏洞所需时间。实验数据表明,当程序结构较简单且基本块数量较少时,直接使用angr进行符号执行分析能更快地检测到漏洞;而随着程序基本块数量的增大,angr检测漏洞所需时间远远多于AutoExp。具体原因如图3所示,AutoExp在预处理阶段构建CFG需花费较多的时间,但是预处理可避免分析与漏洞无关的路径,从而在符号执行阶段花费的时间相对angr要少,且消耗的内存也随之减少。测试结果中,AutoExp检测PSUtils中漏洞所需时间为127.05 s,而angr所需时间是AutoExp的15倍,分析代码发现程序中switch语句会导致状态爆炸问题,该语句与漏洞路径无关,进行代码切片能避免分析该语句,使得符号执行效率得以提高。由此可见,对于结构较复杂的程序而言,本文所提方法可极大提高漏洞检测的效率。
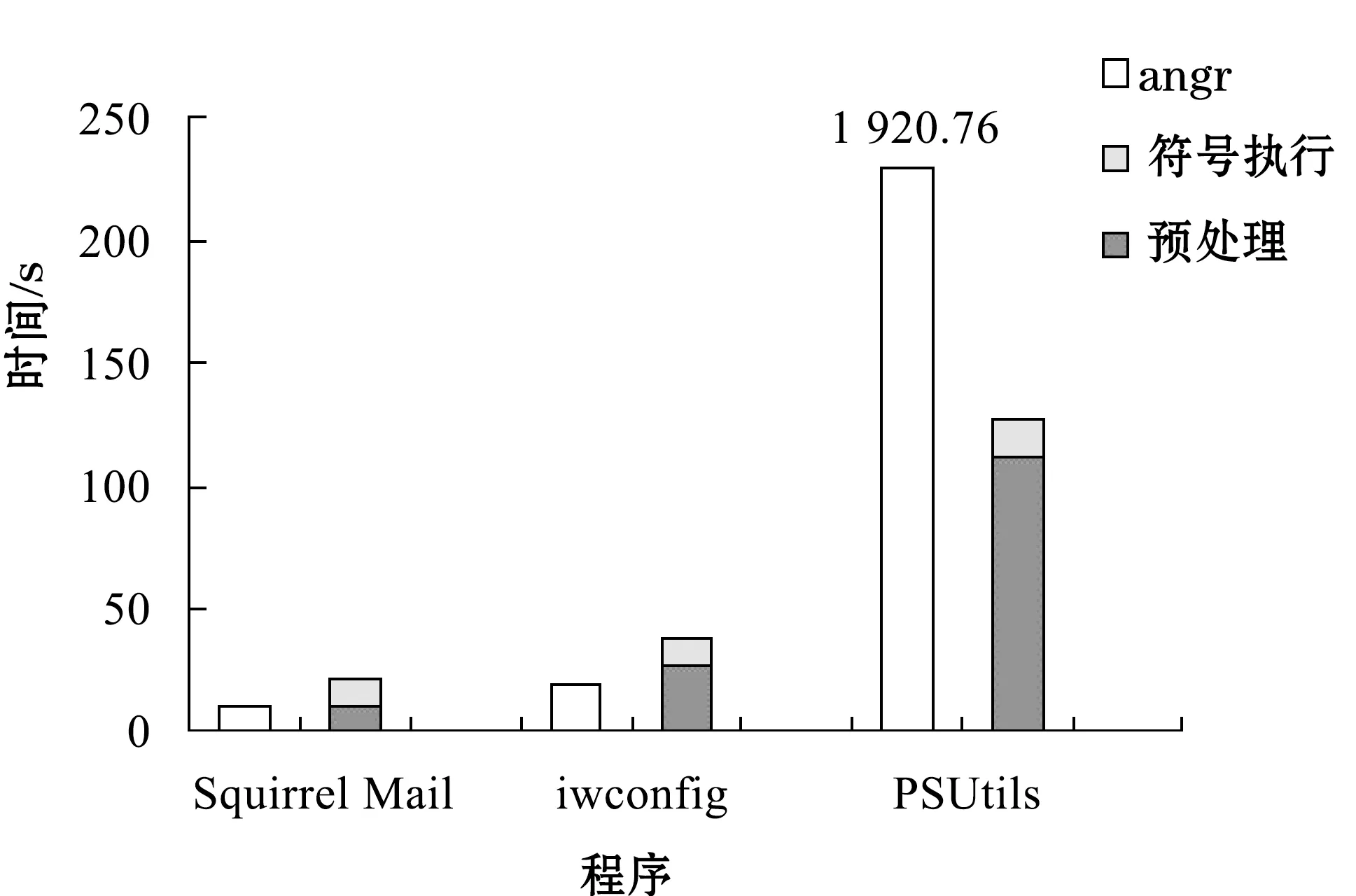
图3 漏洞检测时间对比
3.2 漏洞利用
为验证系统自动生成exploit的适用性,以图4中漏洞程序memo和上述3个漏洞程序进行测试,测试时选取长度为25 bytes的shellcode利用漏洞。memo程序第14行调用read函数获取用户输入到缓冲区buf中,由于第15行strcpy函数往数组title中写入过多的数据而导致缓冲区溢出漏洞,从而覆盖相邻内存中函数指针func_ptr,利用该漏洞可劫持控制流进行代码注入攻击。

1typedefstructmemo{2charcontent[22];3time_ttime;4chartitle[15];5int(∗func_ptr)();6}memorandum;7memorandummemo;8intmessage(){9printf(″%s″,memo.title);10}11intmain(){12charbuf[22];13memo.func_ptr=message;14read(0,buf,sizeof(buf));15strcpy(memo.title,buf);16read(0,buf,sizeof(buf));17strcpy(memo.content,buf);18time(&memo.time);19memo.func_ptr();20}
图4 缓冲区溢出漏洞程序memo
实验结果如表3所示,AutoExp可成功利用4个漏洞,而Mayhem[7]由于未考虑可控内存块不足以容纳shellcode的情况,因此无法成功利用memo中漏洞。实验结果表明,本文所提方法相对Mayhem具有更好的适用性。
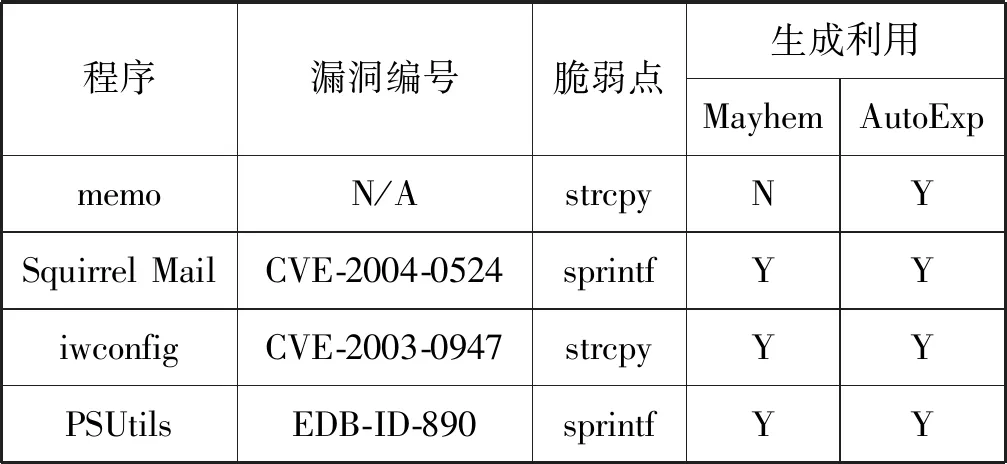
表3 漏洞自动利用结果对比
下面具体分析AutoExp自动生成exploit的效果。程序memo中存在content[22] 和title[15] 两块连续可控内存,利用过程中选取不同长度的shellcode,AutoExp可根据内存块能否容纳shellcode采取不同的exploit构造方法。如图5所示,当选取长度为21 bytes的shellcode利用漏洞时,由于存在能容纳shellcode的可控内存块,故选择可控内存块content[22]注入shellcode构造利用。

图5 shellcode连续存放
如图6所示,当选取长度为25 bytes的shellcode利用漏洞时,由于不存在可容纳shellcode的内存块,故将shellcode分段存放在content[22]和title[15]中,并用指令“eb 07”实现不同分段间的跳转。

图6 shellcode分段存放
上述结果表明,本文所提方法可根据漏洞程序中可控内存块的大小和所选取的shellcode调整exploit构造方法,具有更好的适用性。
4 结 语
本文对漏洞自动化利用方法进行了总结,提出一种基于符号执行的缓冲区溢出漏洞自动化利用方法。该方法采用危险函数切片减少漏洞检测中符号执行的状态数量,可有效缓解状态爆炸问题,提高符号执行的效率。在漏洞利用阶段,当进程中不存在空间足够的可控内存块时,将shellcode进行分段存放,具有更好的适用性。本文实现了缓冲区溢出漏洞利用的自动化,后续工作可进一步研究其他类型漏洞的自动化利用,以及自动绕过程序和系统中部署的漏洞缓解机制。
猜你喜欢
今日农业(2022年13期)2022-09-15
科学与财富(2020年15期)2020-07-04
移动通信(2020年4期)2020-05-07
移动通信(2019年4期)2019-06-25
现代信息科技(2018年4期)2018-07-12
阅读(低年级)(2018年2期)2018-05-14
中国新通信(2017年3期)2017-03-11
儿童时代(2016年6期)2016-09-14
时代人物(2014年10期)2015-01-28
环球时报(2012-01-12)2012-01-12
