
基于LDA主题模型的制造业选址新闻案例研究
2019-09-10 07:22:44陈瑶徐磊徐天骋
上海管理科学 2019年3期
陈瑶 徐磊 徐天骋



摘 要: 选取2011—2016年国内外主流媒体关于跨国企业生产布局与研发中心选址的新闻报道为样本,经过筛选、分类、编码后形成307篇新闻案例,建立新闻案例库。运用LDA主题分析法,分别对制造业在中国的选址案例、工厂与研发中心案例、电子产品与汽车业案例进行主题挖掘,获取影响其选址决策的关键因素。
关键词: 制造业;选址;新闻案例;LDA
中图分类号: C 93
文献标志码: A
Abstract: In this paper, we collect news from domestic and foreign mainstream media on multinational corporations′ layout of production and location of R&D centers from 2011 to 2016 as samples. After screening, classification and coding, 307 news cases were formed and a case library of news was established. Through the method of LDA Topic Model, the news cases of manufacturing location in China, factory and R&D center location, electronics and the automotive industry are mined, and we obtain the key factors that affect the location decision.
Key words: manufacturing; location; news case; LDA
1 文獻综述
1.1 制造业选址相关研究
对于制造企业而言,选址属于最为重要的长期决策之一,研发中心或是工厂的选址是建立、运营、管理企业的开始。企业选址的正确与否往往会直接影响服务的方式、效率、质量和成本等,进而左右企业的利润、市场份额和市场竞争力。而影响企业选址的因素错综复杂,国家区域政策、交通、环境等都会对企业选址决策产生影响,故企业的选址是很多企业都面临的经营管理中的一个重要问题,也是国内外学者的重点研究方向。
任慧娟等通过盈亏分析法、因素评分法、重心法等方式来进行设施选址,并总结出了市场条件、原材料供应条件、交通运输条件、动力、能源和水的供应条件、气候条件、环境保护等6个影响制造业选址的因素;梁琦通过建立空间经济学模型,考察运输成本、交流成本和地方税收政策对企业工厂选址的共同作用;邬珊华等基于双层规划模型对制造业选址布局优化方法进行了研究,并以中国钢铁产业的选址为例证明其有效性。
1.2 LDA主题建模方法
LDA (Latent Dirichlet Allocation)主题模型由 David M Blei提出,属于自然语言处理中主题挖掘的典型模型,是一个基于概率图的三层贝叶斯概率生成模型。LDA 主题模型的主要思想是假设文档集中的每个文档均由多个主题混合而成,每个主题是固定词表上多个词汇的多项式分布,目的在于采用高效的概率推断算法处理大规模数据,从文本语料库中抽取潜在的主题,提供一个量化研究主题的方法。该方法目前已经被广泛应用到各类主题发现中,如热点挖掘、主题演化、趋势预测等。
王树义等提出用LDA识别主题对竞争企业新闻文本进行挖掘,可以及时感知重要的新闻动态。周娜等将LDA 模型运用到学术文献的研究中,提取文献研究主题,进而发现研究内容与研究方法之间的关系。熊回香等以LDA为基础,对微博用户进行主题分析,较准确地描述了用户的微博特征。
本文将LDA主题建模方法应用到制造业选址新闻文本挖掘中,通过对新闻文本主题的提取,来研究制造业企业建设工厂、研发中心选址的关键因素。
2 研究方法
2.1 数据收集
本文以“企业选址”“制造业选址”“研发中心选址”等为关键词,针对近年来制造业选址类新闻,搜集了 2011—2016 年国内外主流媒体集中报道的大量跨国企业生产布局与研发中心选址的新闻报道,同时通过一些现有的新闻采集系统,如八爪鱼、火车头等网页采集软件,共获得新闻案例307篇,包括多家知名跨国企业的180次生产决策、130 次研发决策的案例。
文章根据内容将新闻案例分为3类,以固定格式编号,并采取utf-8编码保存在案例库中。分类如下:(1)制造业企业选址在中国的案例共计149 篇,其中选择来中国建造工厂的共计 68 篇,研发中心共计 82 篇,其中博世-西门子家用电器有限公司在长沙同时建了新的研发中心和工厂,故各计一篇;(2)按企业建造目标的职能进行分类,涉及工厂建造的共计 180 篇,研发中心建造的共计 130 篇,因部分案例同时建造工厂和研发中心,故计数有重复;(3)按案例内容所处的行业进行划分,案例数过少的行业存在较强的不确定性,故对汽车行业89篇、电子产品行业84篇进行分析。
2.2 LDA主题挖掘
本文的整体研究思路如图1所示:
新闻采集后,首先对文本进行预处理,去除与企业选址不相关的内容,如新闻案例中的信息来源、作者信息、报道的时间、文中的图片与数字等,然后对文本进行中文分词、去除停用词,使文本成为可供挖掘的对象,最后将处理好的文本输入LDA模型,进行主题抽取。LDA主题建模问题的关键在于主题数的确定,本文通过人为调试主题数量,使之达到困惑度最低。同时,通过比较各主题的强度,来寻找新闻案例库中制造业选址的关键因素。
3 实证分析
3.1 数据的描述性统计
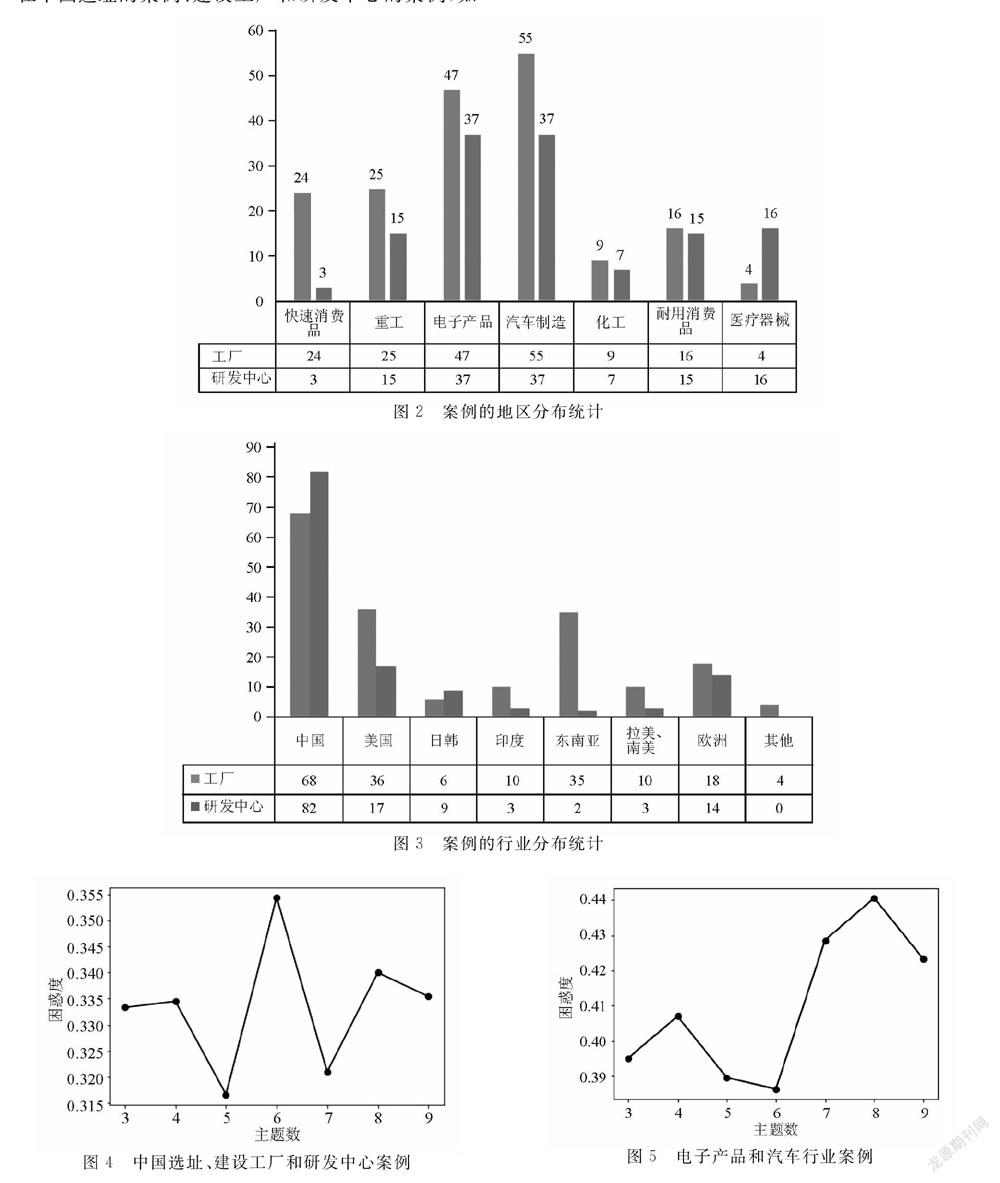
3.1.1 案例的地区分布
如图2所示,中国以接近4成的占比成为主要的工厂建设国,美国、东南亚各国以接近20%的占比紧随其后。相对而言,印度、拉美、南美以及日韩各国的工厂建设案例则较少。这个结果不仅体现了中国世界工廠的传统地位,同时也反映了东南亚以及印度因其较低的生产成本逐渐成为制造业企业工厂选址的新宠,而欧美作为工业强国仍占据一定地位。
3.1.2 案例的行业分布
如图3所示,新闻案例库中的企业涉及快速消费品制造业、机械/电气设备制造、计算机/电子通信、汽车制造业、化工业、耐用消费品制造业、生物医药与医疗器械制造等 7大类行业。其中,汽车、电子通信行业较多。
3.2 LDA主题建模结果
将处理过的文本数据输入LDA主题模型,本文使用python机器学习工具包scikit-learn中的LDA函数进行参数训练。设定文档–主题分布θ的参数α为0.1, 主题–词分布的参数β为0.01, 迭代次数iter为1000,选择Gibbs Sampling估计模型的后验参数。本文首先将主题数设定为3~8,并对每一类中的特征词分布概率进行分析。研究发现,在中国选址的案例、建设工厂和研发中心的案例,如图4所示,当主题数设为5时,模型的困惑度较低,特征词拥有较高的概率分布,主题也有了较好的区分度,模型对于选址影响因素的主题涵盖度较高。
3.3 结果分析
3.3.1 在中国选址的因素分析
将LDA主题模型运用于选址在中国的全部案例、工厂案例、研发案例这三种情况。从各分类的案例中提取出5个主题并计算其主题强度,以及与各主题相关的前10位特征词。以表1为例,根据设定呈现了5个主题,每个主题有自己的主题强度,反映了该主题在该分类中的概率分布,主题强度越高权重越大,即更常被提及,可见在该表格中第4个主题的主题强度即概率分布最高。接下来,每个主题下罗列了10个与主题最为紧密相关的特征词,LDA主题模型本身不会定义主题,需要通过特征词进行归纳。
在中国进行投资的原因主要在于中国政府的支持程度,其分布概率超过21.9%,可见中国近年来不断进行招商引资的举措取得了较好的效果。同时,产业链布局、全球化战略、中国的技术水平和广阔的市场前景,也是企业选址中国的重要因素。除了制造业企业都非常看重中国的市场需求以外,选择来华建厂更看重的是上下游产业链的布局以及政府出台的政策;而研发中心的建设则更多考量的是当地的科技研发水平以及科研院所的合作意向。
3.3.2 工厂与研发中心案例选址因素分析
在这一部分本文将LDA主题模型运用于制造业企业选择建设工厂和研发中心的两类案例中,寻找选址因素。
由表4可见,企业兴建工厂最重视的因素是成本,分布概率超过26.4%,根据特征词可以发现该主题主要包括劳动力成本和关税。同时,当地业务的需求以及占领市场的战略也是企业纳入考量范围的因素,如果当地上下游供应链基础较为完备,则更有利于吸引工厂入驻。而研发中心更看重当地的技术水平以及人才的丰富程度,其分布概率都超过20%,高素质劳动力显然更具有吸引力。总体而言,工厂和研发中心选址的因素区分较明显,与在中国进行选址的案例结论较为接近,也符合本文对于这两者选址考虑因素的一般认识。
3.3.3 电子产品与汽车行业案例选址因素分析
据统计,案例的行业分布主要集中于电子产品和汽车制造两个行业,分别占总案例数的30%左右,而其余行业案例较少,故本文针对这两个行业进行分析。
首先,依旧运用LDA主题模型寻找选址因素。与之前不同的是,实验结果显示当主题数设为6时,主题之间有更好的区分程度。
4 结论与不足
通过收集、分析知名制造企业的 307 项生产、研发决策的相关案例,对制造企业工厂选址和研发中心选址的影响因素有了比较清晰的了解。成本和市场需求依旧是工厂投资最为看重的因素,辅以政策上的支持以及供应链的完善能够最有效地吸引制造业企业投资建厂。对于研发中心而言,先进的技术水平、优秀的研发人才是企业最为看重的因素,辅以良好的市场前景和稳定的投资环境将会有利于研发中心的落地。
本文的不足之处在于案例库研究不可避免在样本上有局限以及主观性。首先,样本量越大越有助于结果的真实可靠,而本文的案例库构建主要基于百度、搜狐、新浪等新闻门户网站并最终得到了307篇案例,样本量不足。其次,本文的新闻案例主要集中在中国,国外的案例较少。
在后续研究中,本文将依托最新的自然语言处理技术,增加新闻案例库的样本量以及来源,提高文本分析的精确度,进一步挖掘新闻报道中潜在的价值信息。
参考文献:
[1] 梁琦,丁树,王如玉. 总部集聚和工厂选址[J]. 经济学(季刊), 2012, 11(3):1137-1166.
[2] 任慧娟. 服务业和制造业的设施选址方法[J]. 知识经济, 2012(8): 15-16.
[3] 阮光册. 基于LDA的网络评论主题发现研究[J]. 情报杂志, 2014(3).
[4] 杨星,李保利,金明举. 基于LDA模型的研究领域热点及趋势分析[J]. 计算机技术与发展, 2012(10):66-69.
[5] BLEI D M, ANDREW Y N G, MICHAEL I J. Latent dirichlet allocation [J] . Journal of Machine Learning Research, 2003(3): 993-1022.
[6] BLEI D M, LAFFERTY J D. A correlated topic model of science[J]. Correction to Annals of Applied Statistics, 2007,1(1): 17-35.
[7] 曾利,李自力,谭跃. 进基于动态LDA的科研文献主题演化分析[J]. 软件, 2014(5):102-107.
[8] 王树义,廖桦涛,吴查科.基于情感分类的竞争企业新闻文本主题挖掘[J].数据分析与知识发现,2018,2(3):70-78.
[9] 周娜,李秀霞,高丹.基于LDA主题模型的"作者-内容-方法"多重共现分析——以图书情报学为例[J].情报理论与实践, 2019(2):1-9.
[10] 熊回香,叶佳鑫.基于LDA主题模型的微博标签生成研究[J].情报科学,2018,36(10):7-12.
[11] 杨海霞,高宝俊,孙含林.基于LDA挖掘计算机科学文献的研究主题[J].现代图书情报技术,2016(11):20-26.
[12] DING Y. Topic-based page rank on author cocitation networks[J]. Journal of the Association for Information Science and Technology, 2011, 62(3):449-466.
[13] 贺亮,李芳. 基于话题模型的科技文献话题发现与趋势分析[D]. 上海:上海交通大学, 2012.
猜你喜欢
走向世界(2022年3期)2022-04-19 12:39:10
大众投资指南(2020年10期)2020-07-24 08:03:48
华人时刊(2019年15期)2019-11-26 00:55:50
中国科技纵横(2016年20期)2016-12-28 17:37:45
商(2016年28期)2016-10-27 13:58:12
科技视界(2016年20期)2016-09-29 12:22:45
商业经济研究(2016年14期)2016-09-14 08:50:04
科技视界(2016年10期)2016-04-26 20:55:18
科技视界(2016年10期)2016-04-26 18:18:35
专用汽车(2016年1期)2016-03-01 04:12:59
