
基于深度学习的多媒体移动物体检测技术研究
2019-09-10 07:22李明东卢彪辛正华房爱东
牡丹江师范学院学报(自然科学版) 2019年4期
李明东 卢彪 辛正华 房爱东



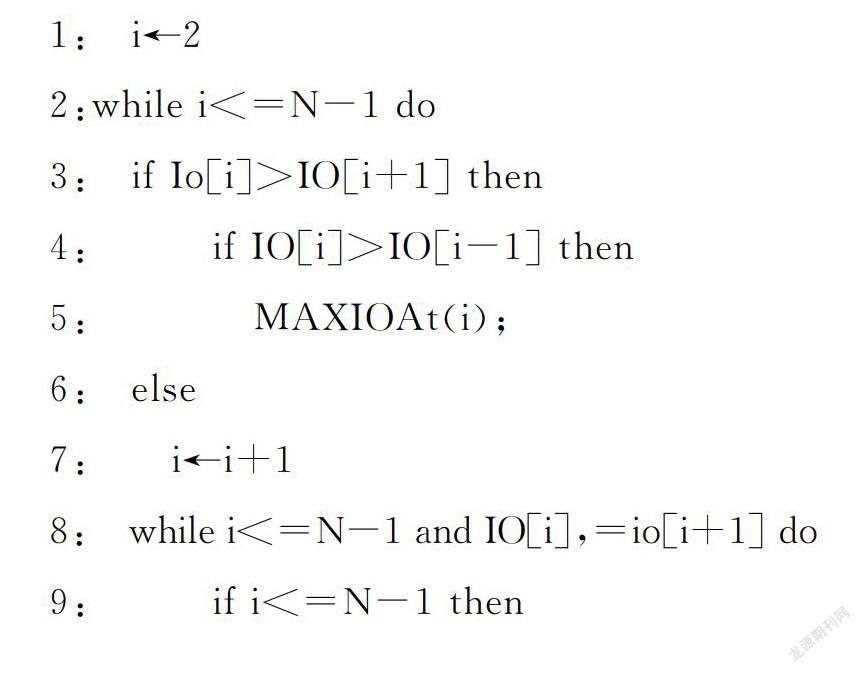



摘 要:为了解决深度学习技术无法满足用户对多张照片移动目标物体识别的需求,提出基于深度学习的多媒体移动物体检测技术.提出基于前馈神经网络的目标定位技术,设计目标定位模型,计算目标边界框的大致位置以及概率;对视频中的目标行为进行预测;利用卷积神经网络融合特征和自然语言搜索特征完成自然目标搜索.
关键词:深度学习;目标检测;自然语言
[中图分类号]TN305.3 [文献标志码]A
Research on Multimedia Mobile Object DetectionTechnology Based on Deep Learning
LI Mingdong,LU Biao,XIN Zhenghua,FANG Aidong
(Suzhou University,College of Information Engineering,Suzhou 234000,China)
Abstract:In order to solve the problem that deep learning technology can not meet the user's need for moving object recognition in multiple photos, a multimedia mobile object detection technology based on deep learning is proposed. Firstly, a target location technology based on feedforward neural network is proposed, and a target location model is designed to calculate the approximate position and probability of the target boundary box, as well as the complete algorithm flow design. Secondly, based on the method of time-space fusion, the feature extraction of time-space feature fusion and the extraction of time information from 3D convolution network are used to predict the target behavior in video. Finally, by using natural language and extracting local features, using convolutional neural network fusion features and natural language search features to complete natural target search.
Key words:deep learning; target detection; natural language
隨着计算机领域对视频目标检测要求的不断提升,传统的目标检测方法不能精确检测视频目标信息,分析动作.[1]基于深度学习的多媒体移动物体检测技术能够满足用户对视频目标识别的需求,对目标的行为进行分析.
1 基于前馈神经网络的目标定位技术
1.1 基于前馈神经网络的目标定位模型
目标定位区域L以及检测目标的类型N,将目标定位区域L平均分为K行K列,K行或K列的概率用可向量表示,记为PK=P(N)MK=1.
第一种边界概率 可能性边界表示概率计算目标边界框的行或列,行和列表示为Px=Px(i)Mi=1和Py=Py(i)My=1,(Bgl,Bgr)为手动标记边界,因此,边界概率P=pX,py的期望为T=tX,ty.
Ai∈1……,M,Tx(i)=1,Bgl≤i≤Bgr 0, 其他,
A i∈1……,M,Ty(i)=1,Bgl≤i≤Bgr 0, 其他.(1)
第二种边界概率 利用边界概率代替行的上下边界框,方框左右边界的概率可用向量表示.分别为 Pt=Pt(i)Mi=1,Pl=Pl(i)Mi=1,Pr=Pr(i)Mi=1,Pb=Pb(i)Mi=1;边界概率为P=pt,pb,pl,pr.
A i∈1……,M,Ts(i)=1,i=Bs0, 其他.(2)
1.2 基于前馈神经网络目标定位设计
基于前馈神经网络的定位模型框架如图1所示.利用前馈神经网络获取图像特征,通过池化、卷积得到搜索区域的特征图层[2],得到位置
感知的特征映射.
前馈神经网络的主要作用是通过8个卷积层将图像1和搜索区K映射到特征映射图.特征图的大小为W15×H15×215,特征映射图中M映射区域被裁剪.将模型分成两个分支:X和Y,生成相应的边界概率和行的列.对分支X方向上的特征由最大池化层聚合,得到特征图.将得到的特征映射图输入到完全连接层,搜索区域通过sigmoid函数输出.分支Y通过最大池层聚合[3]特征映射x方向的特征,获取特征图,将获取的特征图作为输入传输到完全连接层中.sigmoid函数输出判断区域k,边界的概率(pt,pb).
Fmapxy(i,f)=maxFmap2r(i,j,f).(3)
1.3 算法流程设计
视频目标定位检测算法流程为:
输入:图片.输出:目标检测结果——进行多次循环迭代;生成候选边框.对候选边框调整,得到新候选框.达到总迭代次数,生成结果.通过候选框筛选算法得到最佳结果.
两种方法生成候选边界:一是滑动窗口方法,利用详尽的方式来列举图像所有边界的可能情况;另一种方法是区域提案方法,通过预测找出目标可能出现的区域,减少过多的帧仍然可以相对较高召回率.
使用识别算法流中的模型,对于给定迭代的给定系列的候选边界Bt=BtiNi=1,将生成一系列和一边界对应的置信度数Stii=1,生成的置信度表示检测目标的可能区域.
在完成N次迭代之后,生成的候选边界Bt=BtiNI=1,且在每次迭代之后的相应置信水平Stini=1以值对的形式存储以获得数据集合.p=UTt=1St,Bt迭代完成后获得的结果Q有重叠候选边界. 使用合理的最优帧选择方案来消除冗余重叠边界并获得结果S.使用非最大抑制获得最优目标检测结果S.算法的目的是搜索候选边界和人工标签边界的重叠率U的最大值,抑制重叠率U的非最大值,并获得最大重叠率边界. 非最大抑制策略[5]的算法流程如下:
输入:集合中每个元素对应的数组
输出:数组的极大值
1: i←2
2:while i<=N-1 do
3: if Io[i]>IO[i+1] then
4: if IO[i]>IO[i-1] then
5: MAXIOAt(i);
6: else
7: i←i+1
8: while i<=N-1 and IO[i],=io[i+1] do
9: if i<=N-1 then
10: i←i+2
2 基于時间和空间多媒体物体动作检测
2.1 时间空间结合方法
时空网络的融合表明,目标的动作与视频空间和时间的特征使用有关,神经网络时间与空间的融合不仅仅是两个神经网络的叠加.首先进行神经网络的特征图匹配,若不匹配则将较大的要素图进行采样.
ysum=fsum(ma,mb).(4)
ysumi,j,d=mai,j,d+mbi,j,d.(5)
公式(4)表示两个神经网络的特征图和融合神经网络的特征,并将其合并为一个新的特征图.H表示特征要素图的高度,W表示特征要素图的宽度,D是要特征要素图通道数.公式(5)表示如何使用求和方法收敛d通道特征图的像素点(i,j),其中1≤i≤H,1≤j≤W,1≤d≤D.
2.2 框架设计
框架主要包括三个模块:空间和时间特征提取,空间时间特征的融合,3D卷积神经网络的视频目标识别.使用3D卷积神经网络,在时间轴上进一步扩展2D卷积神经网络.连接层输出特征时,可能在时间轴上丢失图像特征的信息,而通过融合时空卷积层的特征,可以将其作为3D卷积神经网络的输入,获得的特征图改善了像素点上时空特征的相关性,补偿光流特性.
2.3 目标动作检测
模型包括3个卷积层,2个池化层,1个完全连接层和能够识别多媒体目标行为的丢失层.卷积层核心数分别是70,150,240,3D,汇集层使用的汇集方法为最大池法.3D汇集内核的大小为1×1×1,空间和时间的深度为3,时间和空间的跨度为1×1×1.
3 基于递归神经网络目标的自然搜索
3.1 自然搜索模型框架
自然查询模型框架见图2.模型包括以下部分:两个门控循环单元[4]分别记为GRUlocal,GRUquest1个卷积神经网络表示为GRUlocal,字嵌入和字预测层.首先得到候选目标位置信息,环境和语句的特征,然后进行单元融合特征,通过短语预测层完成目标预测.
系统对用户给定的图片进行查询语句L和对应于图片的候选边界图片,K表示目标候选{ai}边界的数量.通过运算输出对应于候选边界{ai}. 通过查找最大置信度得分来确定搜索的目标边界.
3.2 模型训练
通常图像标签仅包含在图像中,不包含目标的数据集中.简化模型包括卷积神经网络CNNglobal,1个GRU循环单元是GRUquest,一个字嵌入层和一个字预测层.简化原始模型的公式.
P(wt)wt-1,……,w1=SoftmaxWglobalhtglobal. (6)
LRCN模型中,随机梯度下降用于优化整个
图像标记的数据集.公式(6)中参数htlocal的权重矩阵的值被设置为Wlocal=0.
基于Bag of Words的CAFFE-7K搜索精度较低.CAFFE-7K模型的单词基于ImageNet,ReferIt数据集的目标文本注释若出现具有未包含在数据集ImageNet中的标签词,就不能准确搜索目标.本文提出的SGRC模型的目标搜索精度高于CAFFE和LRCN模型,在2例中逐渐改善了SGRC模型的搜索精度,可获得目标的环境特征、空间参数和SGRC模型在数据集上改善了目标的语言搜索.
4 总结
本文实现了基于深度学习的视频运动目标检测技术.利用前馈神经网络获取图像特征,得到位置感知的特征映射,进行迭代后通过候选边框筛选算法得到目标可能区域;结合时间空间融合技术进行特征提取,3D卷积网络提取时间信息对视频中的目标行为进行预测.利用自然语言搜索算法提取全局特征并通过卷积神经网络融合特征完成目标搜索.试验验证了目标搜索算法的优越性.
参考文献
[1]林海波,李扬,张毅,等.基于时序分析的人体运动模式的识别及应用[J].计算机应用与软件,2014,31(12):225-228.
[2]李敬德.信号多维特征向量的评价模型[J].牡丹江师范学院学报:自然科学版,2018(3):33-38.
[3]高震宇,王安,董浩,等.基于卷积神经网络的烟丝物质组成识别方法[J].烟草科技,2017,50(09):68-75.
[4]高震宇,王安,刘勇,等.基于卷积神经网络的鲜茶叶智能分选系统研究[J].农业机械学报,2017,48(7):53-58.
[5]谭峰,薛龄季轩,姜珊,等.基于云平台的棚室环境远程监控系统[J].牡丹江师范学院学报:自然科学版,2017(2):6-10.
[6]杨祎玥,伏潜,万定生.基于深度循环神经网络的时间序列预测模型[J].计算机技术与发展,2017,27(3):35-38+43.
编辑:吴楠
猜你喜欢
软件(2016年4期)2017-01-20
科教导刊·电子版(2016年28期)2017-01-10
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
科学与财富(2016年28期)2016-10-14
电脑知识与技术(2016年5期)2016-04-14
