
云服务模式下的多媒体资源检索及服务
2019-09-10 06:21侯新宇
文化产业 2019年4期
◎侯新宇
(中国传媒大学图书馆 北京 100024)
一、背景
随着5G网络技术商用、自媒体时代信息爆炸,内容提供者所提供的内容服务也早已从文字、图片向音频和视频转变。数字图书馆作为专业的内容服务提供者,如何将现有分散存储和检索的馆藏数字资源,实现内部关联检索、智慧检索,让所有数字资源都统一为一个整体,向读者揭示一个检索词的全媒体资源,再根据读者喜好进行智能推送相关检索内容,让数字图书馆转变成智慧图书馆,将成为下一个十年图书馆人的工作重心[1]。
二、检索技术的现状
(一)文字检索技术
基于文字的全文检索技术早已成熟,跨行、跨段、跨页检索,自动断词,语义识别等检索技术,使读者可以在亿级汉字库中检索,得到毫秒级结果的响应。检索系统可根据用户喜好和文章被捡、被引次数,刊发主体在学术界影响的权重作为检索结果的排序依据,为用户快速呈现最主流、最核心的检索结果。
(二)图片检索技术
近年来,图片检索技术突飞猛进,以谷歌、百度为代表的互联网企业,都在进行着图片检索技术的研究。微信朋友圈每天产生的图片量超过10亿张,对海量图片进行检索和标引,就成为了图片检索技术中的难点。通过对图片进行元数据标引,从而揭示图片的主题、内容、拍摄技巧等信息,但对于当前海量的图片数据来说,靠编目员的标引是不现实的。通过以图搜图、字符识别、人脸识别、图像分割等自动化的图像处理技术,自动化地对图片进行元数据分类和标引,形成统一的规范化标引,能够极大地减轻编目员的工作量[2]。
(三)音频检索技术
随着语音识别技术的发展,音频中的对话内容已可以转换成文本,转换正确率超过98%,且不需要1:1的时间进行转换,一小时音频最快只需要5分钟即可转换为文本。将音频转换成文本后,即可通过文本方式对其进行全文检索,所以语音识别技术是音频检索技术的先导技术,只有不断地提供语音识别率,才能更好地实现对音频文件的结果检出。但目前语音识别技术还存在很多难点,例如对于中文方言的识别率,目前最高仅为85%。中国的方言大大小小有几百种,全球大约有1.2亿人说四川话、7000万人讲粤语,且在音频中还经常出现普通话、方言、外语等语言交织出现的情况,如果不能大幅度提高方言的识别率,将难以提高检出率。
对于其他音频的识别,例如音乐、动物叫声、车辆噪音、工业噪音、环境噪音等等(包括人类语言)音频,通过例如Echo Nest Musical Fingerprint (ENMFP)这类的算法产生声纹,存储到公共声纹数据库中。进行声音比对时,将要比对的音频也转换成声纹,再在数据库中进行比对,即可得出相应的结果,这样就可以满足声音片段检索的功能需求。
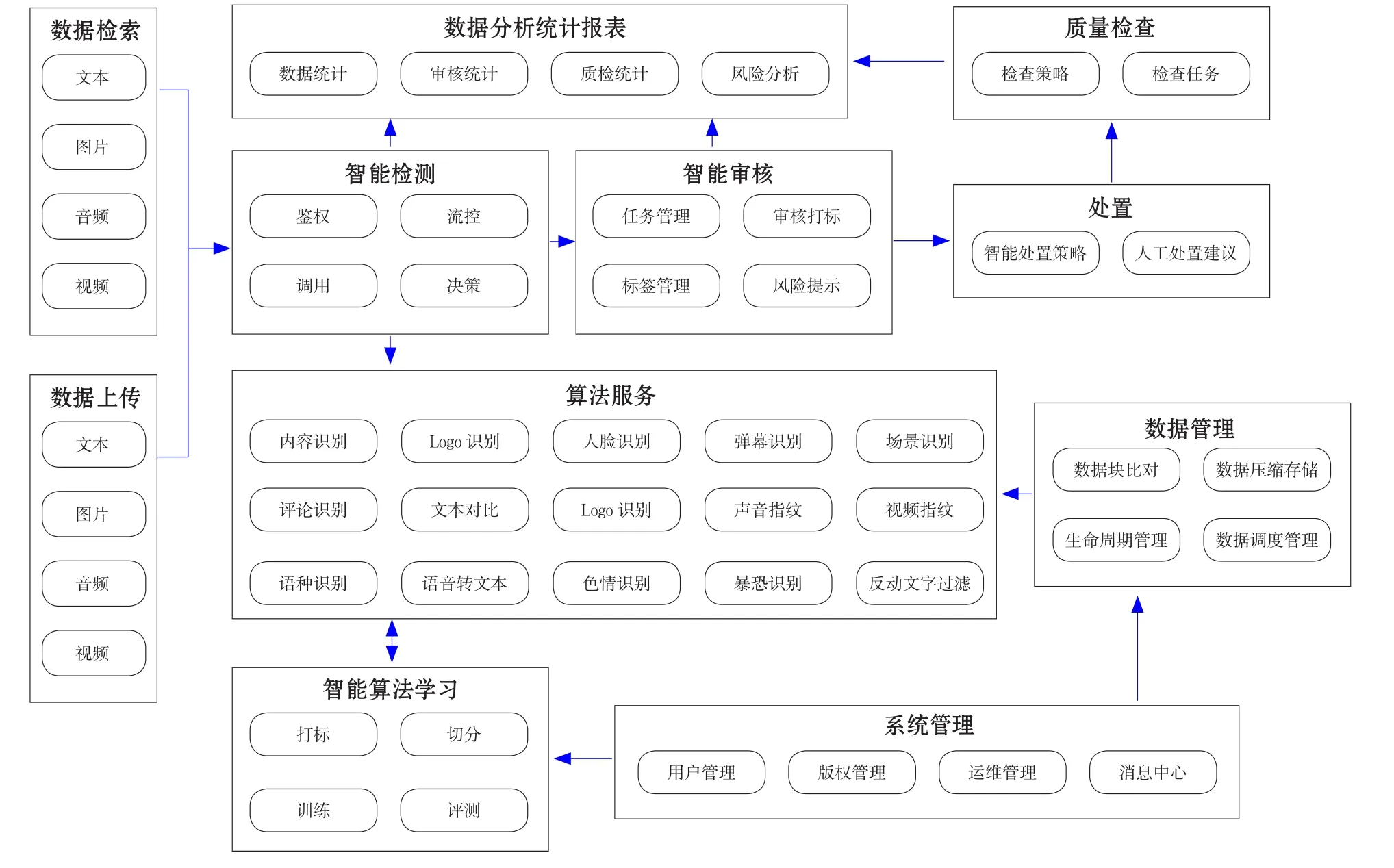
智能多媒体资源构建及检索平台
(四)视频检索技术
视频检索技术则是对图像、声音、文本检索技术的整合。首先对音频和视频进行分离,音频采用音频的智能语音识别、转换声纹等方式进行标引,视频则按帧进行分割,通过图像分割、人脸识别、文字识别等方式进行智能分类和标引,将音频与视频标引的元数据分别存放在数据库中,以便用户进行检索。使用算法视频分别进行指纹特征转换,通过区块链服务与视频指纹进行融合,依托区块链将视频指纹信息上链,从而实现版权存证、侵权追溯和版权交易。
三、云服务发展趋势
目前多媒体检索技术越来越成熟,且逐渐由本地开发、本地部署、本地服务的SaaS(Software as a Service软件即服务)模式转变为云计算时代的PaaS(Platform as a Service平台即服务)模式。
如图所示,服务开发者不用关心底层的基础架构及维护,也就是IaaS(Infrastructure as a Service基础设施即服务);不用关心资源的审核、查重、分类、标引、存储、发布、归档等操作,也就是PaaS(Platform as a Service平台即服务)。这些服务全部由云平台服务商提供,同时它还能提供更为强大的内容智能搜索引擎。数据开放和管理者只需要专注于数据资源的挖掘、整理、收集、分类、标引、服务等工作即可。
目前很多提供公有云的高科技企业,例如AWS(Amazon Web Services)、阿里云、百度云等公司,在提供云计算基础架构平台的基础上,还提供多媒体检索、查重、标引及基于区块链技术的版权保护的服务整合,开发者甚至只需要做一些简单的UI(用户交互)和数据库的存储设计,其它工作全部交由云计算平台来完成,极大地降低了开发成本和开发难度;而数据管理者则只需要关心资源的上传与使用,极大地减轻了运维的压力和使用成本,从而可以将全部精力投入到资源建设上,提供更高质量服务和扩大服务范围,同时又能兼顾业务的连续性。
综上所述,云服务模式下的资源整合,将带给数据管理者以翻天覆地的服务模式的变化,也为用户带来方便快捷的资源获取方式。
猜你喜欢
南京中医药大学学报(2022年5期)2022-05-18
家庭影院技术(2021年1期)2021-03-19
白求恩医学杂志(2020年4期)2020-12-12
家庭影院技术(2018年11期)2019-01-21
通信产业报(2018年32期)2018-11-24
电子制作(2018年19期)2018-11-14
科技创新与品牌(2018年2期)2018-09-18
人间(2015年8期)2016-01-09
祝您健康(2009年4期)2009-04-08
青年文摘·上半月(1982年1期)1982-01-01
