
基于主述位理论的汉语基本篇章单元识别
2019-09-05 12:33:36葛海柱周国栋
中文信息学报 2019年8期
葛海柱,孔 芳,周国栋
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
近年来,随着句子级研究的日趋成熟,篇章分析成为研究热点之一,它在信息抽取、机器翻译、指代消解等自然语言处理领域中的应用越来越广泛,逐渐成为自然语言理解的核心问题之一。
篇章也称语篇,通常是由一系列连续的子句、句子和句群构成的语言整体单位。任何文本单元都不可孤立地进行分析,而是需要根据其上下文进行解读。而篇章分析的目的就是从整体上解读文本,分析篇章内部的结构和关系。因此,篇章分析的一般步骤包括: ①识别基本篇章单元。基本篇章单元(Elementary Discourse Units,EDU)是句子中具有独立语义和独立功能的最小单位,是进行篇章分析的基本单位。②篇章结构及关系的解析。将识别出的基本篇章单元依据一定的关系(例如,修辞关系)构建成特定结构,常见的结构有树和图等。可以看到,无论进行哪种篇章结构的分析,EDU识别都是一项基础工作,它的识别性能会对后续篇章结构的解析产生极大的影响。
从篇章衔接性角度[1]出发,我们认为每个EDU都由主位和述位两部分构成,其中主位是说话人想要表达信息的起始点,而述位代表话题的核心,用于表示说话人扩展或解释主位的信息,是说话人要传达的新信息。因此,只要准确地识别主位和述位的位置,就能通过主、述位确定基本篇章单元的边界。基于此,本文给出了一个基于主述位理论的基本篇章单元自动识别方法,其基本思想是充分利用主、述位间的信息序列化特性,将主述位识别看作一个序列化标注问题,在识别出主述位的基础上,再根据主述位的位置确定EDU的边界。在微观话题结构语料库CDTC[2]上进行的实验表明,基于主述位理论的EDU识别方法在不使用句法等复杂信息的情况下就能取得不错的效果,EDU识别的F1值为89.46%,而主位、述位识别的F1值分别为84.26%、85.91%。
1 相关工作
随着RST-DT(Rhetorical Structure Theory Discourse Treebank)[3]与PDTB(Penn Discourse Treebank)[4]英文篇章语料库的发布,针对英文基本篇章单元识别的研究受到了很多研究人员的关注。代表性工作包括: Sporleder和Lapata[5]第一个引入神经网络模型,将基本篇章单元识别作为序列化标注问题。Xuan Bach等[6]在RST-DT语料中进行的EDU识别实验得到目前的最优性能,F1值为93.7%。但他们的工作过分依赖标准词法、句法信息,而在实际应用中这些信息的获取需要耗费大量的人力物力。Chloe Braud[7]采取序列化标注的方法,使用自动词法、句法信息作为输入特征,F1值为86.8%。
相比英文,汉语篇章分析的相关研究刚刚起步,目前主要存在以下问题。
(1) 针对汉语篇章分析的理论指导体系还不够完善。汉语注重意会,严重依赖上下文,与西方语言差异显著,使得汉语篇章分析不能照搬西方语言的篇章分析方法,需要汉语篇章研究者们结合汉语特点,通过借鉴西方语言篇章分析方法,找出适合汉语篇章分析的研究方法。
(2) 适用于汉语篇章分析研究的大规模语料库相对缺乏。近年来建立汉语篇章语料库资源成为研究者关注的焦点。乐明[8]依据修辞结构理论(Rhetorical Structure Theory,RST)完成了语料标注工作。Zhou和Xue等[9]在分析中英文差异的基础上,通过扩展PDTB体系构建了中文篇章树库CDTB(Chinese Discourse Treebank)。李艳翠等[10]结合RST和PDTB体系的优点,联合汉语句群理论,提出了连接词驱动的篇章树表示体系,并以此为依据标注完成了500个文档的汉语连接词驱动篇章树库CDTB(Connective-driven Discourse Treebank)。奚雪峰等[11]提出了基于主述位理论的篇章微观话题结构表示体系,并依据它标注形成了500篇文档的微观话题结构语料库CDTC。(1)李艳翠等标注的汉语连接词驱动的篇章树库CDTB与奚雪峰标注的微观话题结构语料库CDTC使用了一致的基本篇章单元(EDU),它们从不同篇章视角进行汉语篇章分析。
受限于语料库,有关汉语基本篇章单元识别的研究相对较少,主要思想是将EDU识别任务看作汉语中的逗号分类问题,代表性工作有: 李艳翠等[12]分析了逗号与基本篇章单元的关系,并在标注语料上进行了基于逗号的汉语EDU识别研究。Xue Nianwen等[13]将中文子句切分当作逗号分类问题,自动识别汉语句子中表示句号功能的逗号,识别的准确率接近90%。Jin等[14]提出利用逗号、谓词等特征分割汉语句子的方法,准确率为87.1%。
上述汉语EDU识别研究都是基于传统机器学习方法,基本思想是将汉语EDU识别当作逗号分类问题,虽然取得了不错的识别效果,但也有不足之处。首先,他们的模型均需人工提取特征,而人工建立特征工程往往需要投入大量时间研究和调整输入特征。同时实验效果依赖标准词法、句法信息,当没有标准信息时,实验结果较差。
为了解决上述问题,我们参考了英文基本篇章单元的识别方法,结合汉语实际情况,在使用深度学习方法的同时引入主述位结构,一方面将EDU识别当作关于主述位的序列化标注问题,实现了主述位结构与EDU的联合识别;另一方面从EDU内部构成的完整性角度进行EDU边界的识别,提升了EDU的识别性能。
2 主述位理论
主述位理论的核心是主位和述位两个概念,最早由布拉格学派的Mathesius[15]提出,并在语言学中得到广泛运用,但在计算机领域运用较少。此后,Halliday[16]认为,句子按主位展开,主位用于表示在上下文语境中已知或是明显的信息,是说话人想要表达信息的起始点;述位代表话题的核心,用于表示说话人扩展或解释主位的信息,往往是说话人要传达的新信息。
从篇章角度分析,主位是基本篇章单元(EDU)中的第一个构成成分,述位是基本篇章单元中去除主位后遗留的成分[17]。因此,一个完整的句子可看作“主位—述位—主位—述位……”的序列,其中相邻的主位—述位构成一个基本篇章单元。据此奚雪峰借鉴主述位理论提出了基于主述位理论的篇章微观话题结构表示体系,并据此标注完成了500篇文本的微观话题结构语料库CDTC(Chinese Discourse Topic Corpus)[18]。该语料从CTB 6.0中选取500篇文档,标注了基本篇章单元(Elemental Discourse Unit,EDU)、基本篇章话题的主位(Theme)和述位(Rheme)等信息,反映了汉语基本篇章单元以及汉语篇章衔接性的语言现象和特点,为面向汉语的篇章话题结构提供了语料资源。关于该语料的详细介绍,可参考文献[10],本文仅关注其中基本篇章单元和主述位的定义,具体如下:
定义: 基本篇章单元(EDU),在话题结构中又被称为篇章基本话题单元(Elementary Discourse Topic Unit,EDTU)。一个EDTU由一个主位(Theme)和一个述位(Rheme)构成,其中主、述位可能会出现省略现象,省略时称为隐式主、述位。篇章基本话题单元中的主位是指包含在一个篇章基本话题单元(EDTU)之中的谓词前面的成分,一般包含主语;述位是指EDTU中除主位外的剩余部分。基本篇章单元与主位、述位的关系如例1所示。
例1[[外商投资企业的出口商品]T1 [仍以轻纺产品为主,]R1 ]EDU1 [[其中,出口额最大的商品]T2 [是服装,]R2 ]EDU2 [[Φ]T3 [去年为七十六点八亿美元。]R3 ]EDU3
例1中,句子“外商投资企业的出口商品仍以轻纺产品为主,其中,出口额最大的商品是服装,去年为七十六点八亿美元。”由三个基本篇章单元组成。EDU1“外商投资企业的出口商品仍以轻纺产品为主,”中包含主位T1“外商投资企业的出口商品”和述位R1“仍以轻纺产品为主”。同理,EDU2中T2“其中,出口额最大的商品”为主位,R2“是服装”为述位。但EDU3则与EDU1、EDU2不同,其主位T3被省略,为隐式主位,述位为R3“去年为七十六点八亿美元”。
由上述定义可知,准确地识别出、主述位的位置信息就能确定EDU的边界。如例1中,如果识别出主位T1“外商投资企业的出口商品”和述位R1“仍以轻纺产品为主”的边界,就可以得到EDU1的边界,具体实现将在下一节中详细介绍。
3 基于主述位理论的EDU识别
本文通过确定EDU中主、述位的位置间接获得EDU的边界,因此可将EDU识别分成两个部分,首先进行主、述位识别,然后在识别主位和述位后再依据一定的规则合并得到EDU。
图1给出了基于主述位理论的EDU识别的完整框架。从框架图中可以看到,模型以句子为基本处理单位,输入句子后,进行分词和词性标注,再以词为单位,交由主述位识别模型的Word Sequence Layer层进行编码,再由Inference Layer层进行解码和标注,最终得到主位和述位的边界,最后依据一定的规则进行主、述位的合并,得到最终的EDU边界信息。
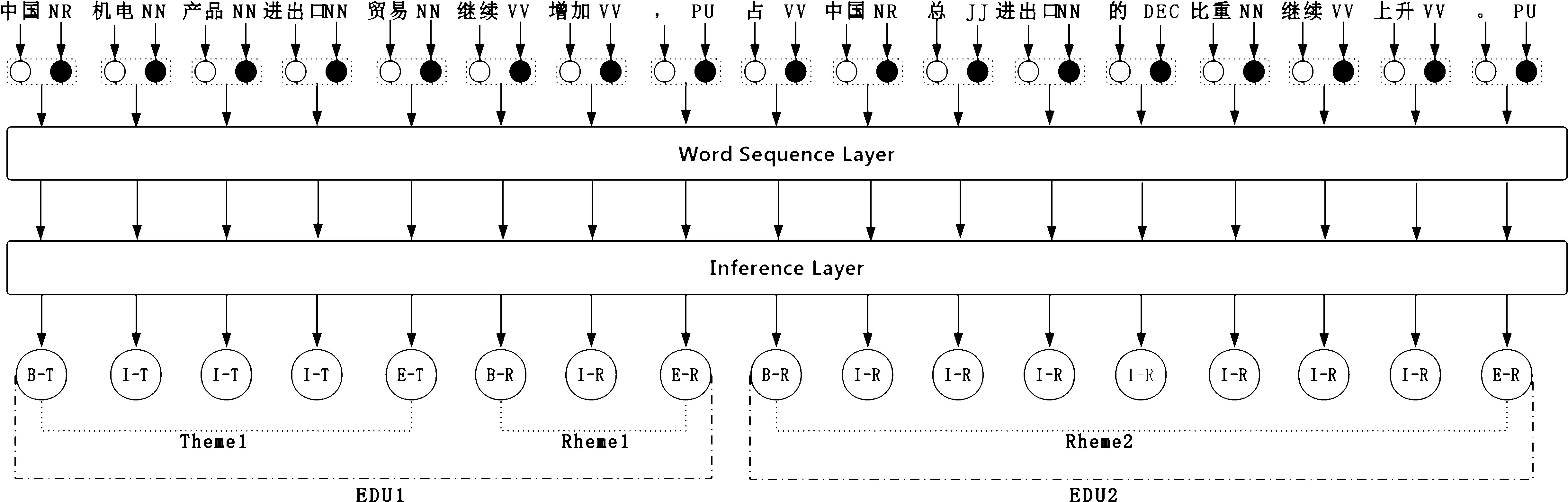
图1 基于主述位理论EDU识别的完整框架
3.1 标注体系
从篇章衔接性角度看,主位和述位构成了信息推进的序列,可以在对上下文信息进行编码的基础上借助序列化标注方法完成主位和述位的标注。而序列化标注方法首先需要设计一套切实可行的标签集合。这些标签要能体现每个词的归属,在主、述位识别任务中,我们采用了BIE标签集合,将每个词标注为“B-X”、“I-X”、“E-X”。其中,“B-X”表示这个词所在片段属于X类型,并且该词位于所在片段的开头,“I-X”表示这个词所在片段属于X类型并且该词位于所在片段的内部;“E-X”表示这个词所在片段属于X类型,并且该词位于所在片段的结尾。
通过对语料的分析,我们发现待标注的主述位结构可以分为三种类型。对于这三种不同类型,我们设计了不同的标注方案。
(1) 主述位结构完整型,即包含完整的非单词型的主位和述位。如例2所示,标注方法如图2所示。
例2[[湄洲湾南岸]T [将主要依靠大工业来带动发展。]R ]EDU

图2 主述位结构完整型
(2) 单词型主位,即主位仅包含一个词。如例3所示,标注方法如图3所示。
例3[[九江]T [是连接长江南北的要道。]R ]EDU
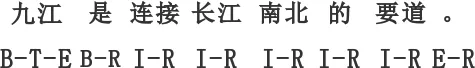
图3 单词型主位
(3) 隐式主位型,即当前EDU的主位信息可由上下文推导得出,并未显式给出。如例4所示,标注方案如图4所示。
例4[[崇明]T1 [是中国第三大岛,]R1]EDU1 [[Φ]T2 [具有悠久的历史。]R2]EDU2
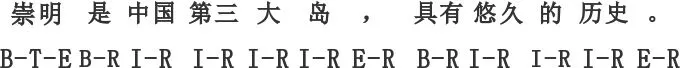
图4 隐式主位型
3.2 主述位识别模型
如图1所示,主述位识别模型由两部分构成,Word Sequence Layer和Inference Layer,下面分别进行介绍。
3.2.1 Word Sequence Layer
Word Sequence Layer需要完成两个任务:
(1) 处理输入的句子,返回一个由词向量和词性向量拼接而成的序列;
(2) 对于给定的词信息序列(x1,x2,x3,…,xn),提取其对应的上下文特征,返回一个关于输入序列的表示序列(h1,h2,h3,…,hn)。
任务1中,我们将一个含有n个词的句子(词的序列)记作式(1):
x=(x1,x2,x3,…,xn)
(1)
其中,xi表示句子的第i个词在字典中的id。然后,我们利用预训练的Embedding矩阵将句子中的每个词xi映射为低维稠密的词向量,最终将词向量、词性向量拼接,作为下一个任务的输入。实验过程中,我们同时考虑过使用字向量和字性向量(2)我们将每个词的词性同时映射给构成该词的所有字。例如,“中国/ns”映射得到“中/ns”“国/ns”,并将映射得到的词性称为该字的字性。作为下一个任务的输入,结果发现使用词向量和词性向量的EDU识别效果要优于字向量和字性向量。
对于任务2,我们选用双向LSTM对输入序列进行建模,动态捕获序列数据信息,得到目标左边和右边的上下文信息,学习长期的依赖关系,自动提取句子特征。
图5给出了Word Sequence Layer的具体实现方法。模型的输入为词和词性,在Word/POS Representations部分,通过查找词向量表,借助预训练的词向量将词转化为向量表示,同时随机生成词性向量,最终在每个词处将词向量与词性向量拼接形成整体后,送入Forward LSTM与Backward LSTM中进行特征抽取。前向LSTM从左向右捕获文本信息,而后向LSTM以相反方向提取信息。前向LSTM与后向LSTM的隐藏状态在LSTM hidden处串联表示整个序列的全局信息,最终将此信息传入Inference Layer层。
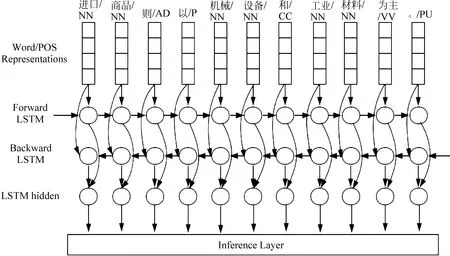
图5 Word Sequence Layer
3.2.2 Inference Layer
Inference Layer将Word Sequence Layer传来的全局信息作为特征,借助解码环节为每个词分配标签。Inference Layer通常有两种标签分配方式: softmax和条件随机场(CRF)。主、述位识别任务属于强输出标签依赖性的任务,而条件随机场更适合处理此类任务,因为它可以在相邻标签之间添加转换分数来捕获标签的依赖性。因此我们在Inference Layer中,借助Word Sequence Layer传来的全局信息,使用CRF模型进行句子级的序列化标注。
如果记一个长度等于句子x中词的个数的标签序列为y=(y1,y2,y3,…,yn),那么模型对于句子x的标签等于y的打分,如式(2)所示。
(2)
其中,Aij表示的是从第i个标签到第j个标签的转移得分。从式(2)可以看出,整个序列的打分等于各个位置的打分之和,而每个位置的打分由双向LSTM输出的Pi和CRF的转移矩阵A决定。对所有的得分使用softmax进行归一化后的概率,如式(3)所示。
(3)
其中,x为训练样本,分子上的y为正确的标注序列,下面对真实标记序列y的概率取log,得到损失函数,如式(4)所示。
(4)
最终的目标就是最大化上述公式,因此对式(4)取负,然后最小化,就可以使用梯度下降等优化方法来求解参数。
模型训练完毕,使用动态规划的Viterbi算法解码,求解最优路径,如式(5)所示。
y*=argmax score(x,y′)
(5)
最终,将y*作为预测结果输出。如图1中Inference Layer层下面的输出所示,模型的输入为“中国 机电 产品 进出口 贸易 继续 增加,占 中国 总 进出口 的 比重 继续 上升。”,预测结果为“B-T I-T I-T I-T E-T B-R I-R E-R B-R I-R I-R I-R I-R I-R I-R I-R E-R”,预测结果中的每一个标签对应输入句子中相应位置的词,由标签我们可将输入句子分为3个片段,如图1所示,第一个片段为Theme1,即主位“中国机电产品进出口贸易”;第二个片段为Rheme1,即述位“继续增加”;第三个片段为Rheme2,即述位“占中国总进出口的比重继续上升”。
3.3 合并生成EDU
确定主位、述位的位置后,由EDU的定义可知:
(1) 在主、述位结构完整的情况下,基本篇章单元由相邻的主位和述位构成,据此可以确定一个基本篇章单元的位置,如图1中EDU1所示,该基本篇章单元由主位Theme1和述位Rheme1构成。
(2) 对于连续出现多个述位的情况,后续述位可看作是包含隐式主位的EDU。如图1中的第三个片段Rheme3,前面位置没有主位,省略了主位“中国机电产品进出口贸易”,因此Rheme3“占中国总进出口的比重继续上升”为基本篇章单元。
4 实验结果与分析
4.1 实验设置
实验选用的语料为苏州大学自然语言处理实验室构建的基于微观话题结构(Micro-Topic Scheme)的汉语篇章话题结构语料库(Chinese Discourse Topic Corpus,CDTC)。汉语篇章话题结构语料库从CTB 6.0中抽取了500篇文档进行语料标注,采用微观话题结构标注体系。该语料中所有识别项目的Kappa值均大于0.75,其中基本篇章单元识别的Kappa值为0.91,主述位识别的Kappa值为0.83。实验超参数设置如表1所示。
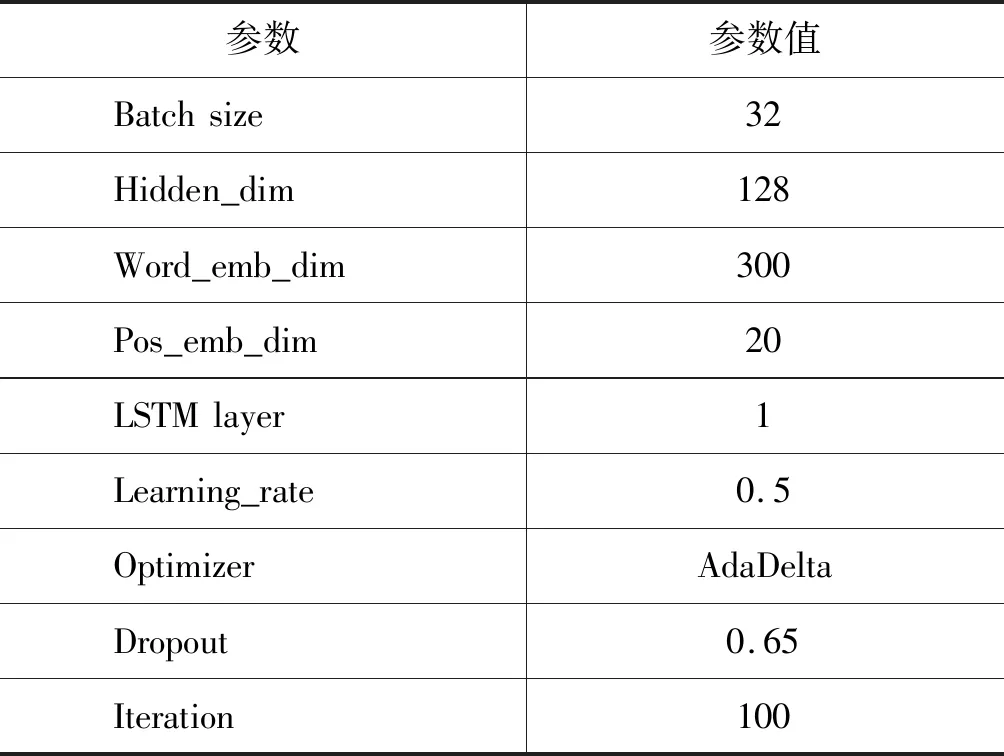
表1 实验超参数设置
4.2 实验结果及分析
本文提出了一种基于主述位理论的EDU识别方法,首先验证该方法的有效性。由于CDTC语料规模有限,因此在这部分实验中将语料均分为5份,采用5倍交叉验证衡量系统性能,使用Precision(P),Recall(R),F1-score(F)作为评测标准。
如前文所述,本文将EDU识别当作基于主述位的序列化标注任务,而在英文EDU识别中同样采用了序列化标注的方法。不同点在于英文中直接通过序列化标注EDU得到EDU的边界,并没有引入主、述位的概念。为了说明主、述位结构在汉语EDU识别中的作用,我们将基于主述位理论的EDU识别方法(TR-EDU-Detector)与直接采用序列化标注策略进行EDU识别方法(EDU-Detector)进行了对比,具体结果如表2所示。
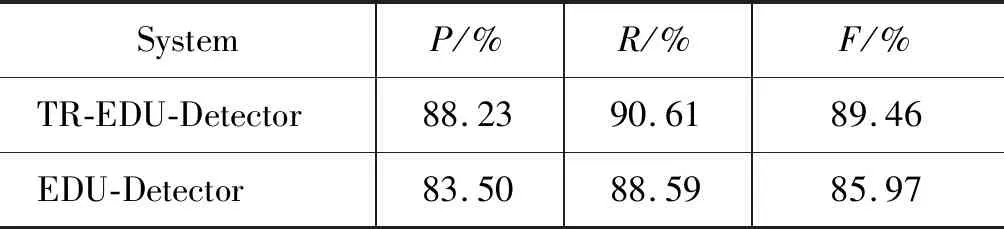
表2 两种不同EDU识别方法对比
通过实验结果的对比可以发现,在汉语中直接对EDU进行序列化标注的结果要比基于主述位理论的EDU识别方法的性能差,准确率和召回率都有不同程度的下降,系统F1值下降了约3.5%。
虽然英文中直接将EDU识别作为序列化标注任务取得了不错的效果,但在汉语中的识别效果不如基于主述位理论的EDU识别方法,主要原因如下。
(1) 汉语注重意会,省略现象较多,例如,“[崇明是中国第三大省,]EDU1 [具有悠久的历史。]EDU2”由两个EDU组成,第二个EDU省略了“崇明”,若直接进行序列化标注可能会由于主位省略导致两个EDU被划分为一个。而基于主、述位理论的EDU识别方法由于隐式主位的存在反而降低了这种情况出现的概率。
(2) 对于构成复杂、长度较长的EDU,直接进行EDU识别比较困难,而通过引入主、述位结构可将复杂的EDU转化为相对简单、长度较短的主位、述位两个部分,分别进行识别。
(3) 主、述位在一定程度上体现了篇章的信息流,特别是新旧信息间的推进,通过Bi-LSTM对上下文进行表征,能很好地区分这一信息,从而有助于EDU边界的确定。
已有的一些中文EDU识别研究都是把EDU识别看作逗号消歧问题,通过人工提取逗号所在上下文的多种信息对逗号进行分类,从而完成EDU的识别。代表性的工作有李艳翠等[19],他们借助最大熵、决策树、贝叶斯等分类器,人工提取了词法、句法、距离和语义等13类特征,从CTB 6.0中抽取了与本文相同的500篇文档进行实验。本文采用与其相同的实验语料配置,对应性能如表3所示。
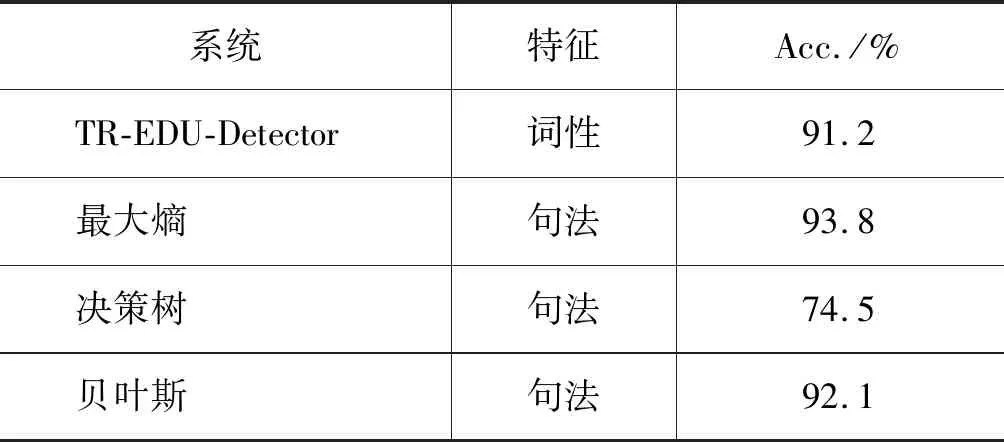
表3 TR/机器学习 EDU识别结果
由上述实验对比结果可以看到,虽然基于主、述位EDU识别的准确率比基于特征的最大熵分类方法低2.6%,但我们在实验中仅使用词法特征,对句法特征没有依赖。而它们的实验结果严重依赖句法信息,去除句法相关特征后,EDU识别的准确率下降了约6%[12]。
这些传统机器学习方法存在一个问题,它们仅关注逗号的功能类别,忽略了EDU作为一个独立的篇章单元的内部构成。本文提出的基于主述位理论的EDU识别方法的输入是句子及其对应的分词和词性标注信息,不依赖句法信息。我们进一步进行了标准/自动分词和词性标注场景下的EDU识别,对应的性能如表4所示。
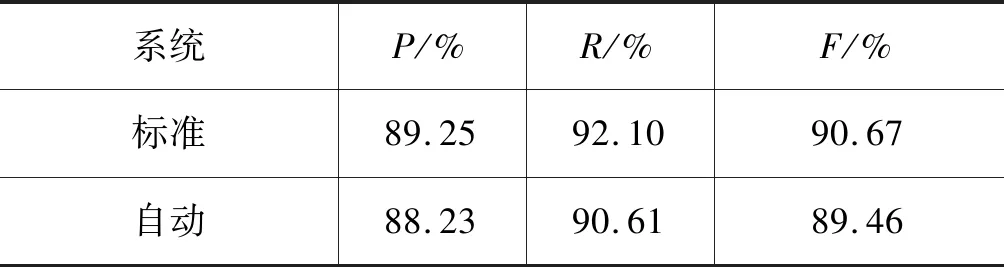
表4 标准/自动分词和词性标注下EDU识别
我们借助结巴分词工具进行了自动分词和词性标注。从表4所示的结果可以看到,本文提出的基于主述位理论的EDU识别方法更稳定,对标准信息的依赖性较小,使用自动词性与标准词性EDU识别的性能相比,F1值仅下降约1.2%。
与其他已有方法相比,本文提出的基于主述位的EDU识别方法更关注EDU内部的成分构成,在识别主位和述位的同时完成EDU的识别。表5给出了自动分词和词性标注场景下主位和述位的识别性能。从显示的结果可以看到,本文给出的方法能高效地进行主、述位和EDU的联合识别。

表5 自动分词和词性标注下主述位的识别性能
5 总结
本文提出了一种基于主述位理论的EDU识别方法。其基本思想是充分利用主、述位间的信息序列化特性,将主、述位识别看作一个序列化标注问题,在识别出主、述位的基础上,再根据主、述位的位置确定EDU的边界。实验结果表明本文给出的基于主述位理论的EDU识别方法的F1值可达89.4%,对标准信息的依赖极小,而且模型使用深度学习方法,不需要人工建立特征工程,免去了手工提取特征的烦恼。我们下一步的工作是进一步提高EDU识别的性能,以便为篇章分析中篇章解析树的构建提供基础。
猜你喜欢
天津外国语大学学报(2021年3期)2021-08-13 08:32:12
甘肃教育(2020年14期)2020-09-11 07:58:36
智富时代(2018年6期)2018-08-06 19:35:08
海外华文教育(2016年1期)2017-01-20 08:21:58
网络空间安全(2016年3期)2016-06-15 20:27:09
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
佳木斯大学社会科学学报(2015年5期)2015-12-01 08:23:33
语文知识(2015年12期)2015-02-28 22:02:15
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
