
基于熵加权属性子空间的目标社区发现
2019-09-05 12:33:40刘海姣马慧芳李志欣
中文信息学报 2019年8期
刘海姣,马慧芳,2,昌 阳,李志欣
(1. 西北师范大学 计算机科学与工程学院,甘肃 兰州 730070;2. 桂林电子科技大学 广西可信软件重点实验室, 广西 桂林 541004;3. 广西师范大学 广西多源信息挖掘与安全重点实验室,广西 桂林 541004)
0 引言
现实世界中大量复杂系统均可以抽象为复杂网络模型,如社交网络、交通网络、生物网络等。网络的研究具有重要意义。例如,对社会网络结构的清晰认识,可以帮助人们更好地理解各种社会现象[1-2]。随着社会的不断发展,网络中的社区发现已经引起了广泛的关注。特别是目标社区发现已成为近年来的研究热点。目标社区发现是指挖掘与用户偏好一致的节点所构成的社区。该社区内部连接紧密,且与外部分离较好。目标社区发现在科学研究、商业推广等领域有了越来越多的应用[3]。例如,化妆品销售经理可能更关注于社交网络中的某个社区。该社区成员具有一定的年龄、性别以及收入水平,经理可以向社区中的成员进行推荐并期望通过口碑传播的方式推广其产品;销售体育用品的市场营销经理需要挖掘有体育用品需求的用户所在的社区。然后,根据社区中用户的需求向少数成员提供试用产品,以期待产品在社区中受欢迎。
现有的社区发现方法大致可分为以下两种: 一种是基于无监督聚类技术,另一种是基于半监督聚类技术[4]。大多数采用无监督聚类技术的社区发现方法中,在所有可用属性视为同等重要,或者采用无监督技术来确定属性权重。近年来具有代表性的工作包括: Chen等[5]提出了一种子空间图—结构匹配寻踪算法,用于解决不同得分函数和拓扑约束的问题。Gunnemann等[6]提出一种无监督的谱权重聚类方法用于检测每个社区的相关属性的子集,并采用谱聚类来学习社区结构。但是,基于无监督聚类技术的社区发现方法未能考虑先验信息。与上述方法不同,半监督聚类技术则考虑了用户给定的约束。Li等[7]提出了一种元路径图聚类框架(VEPathCluster),该框架将元路径节点—中心聚类和元路径边-中心聚类相结合。Yang等[8]提出一种基于模块度的深度学习社区检测方法,并将该方法推广到一种半监督的社区检测算法中。目标社区发现是一种新的半监督局部聚类方法,挖掘到的社区内部节点受用户偏好控制。Perozzi 等[3]提出了一种面向用户的属性图挖掘方法(FocusCO)。该方法允许用户通过提供一组样本节点来引导社区,所提供的样本节点被认为是相似的,并且与用户感兴趣的社区节点相似。FocusCO没有说明需要多少示例节点,但明确指出需要两个以上的样例节点。Wu等[9]提出了一种在目标子空间中挖掘目标社区集合的方法,该方法根据用户提供的两个样本节点扩展到一组样本节点,从中推导出目标属性权重并挖掘目标社区的集合。然而,现有的半监督目标社区聚类技术虽然考虑了用户的偏好,但在聚类过程中仅考虑了节点的属性信息或只利用节点的部分属性[10]。
针对以上问题,本文面向用户提出一种基于熵加权属性子空间的目标社区发现(Target Community Detection Based on Attribute Subspace with Entropy Weighting, i.e.TC-AE )方法,挖掘与用户偏好相关的社区。考虑到用户提供的样例节点潜在的属于目标社区。首先,从属性和结构两个方面综合考虑节点间的相似度,利用样例节点及其邻居扩展得到目标社区中心点集;其次,在中心点集上,设计一种熵加权属性子空间权重计算方法,最小化社区内部节点间的距离,并最大化负熵值来刺激更多的属性。得到目标社区的属性子空间权重,既可以确定目标社区的属性子空间,又可以避免用稀疏数据通过少数属性识别社区的问题,从而有助于精准的确定目标社区;再次,利用目标社区的属性子空间权重,基于节点的属性和结构相似度重写网络中边的权重;最后,定义社区适度函数并结合重写后网络中边的权重改进社区适度函数,以中心节点集为核心,挖掘基于用户偏好的内部连接紧密且与外部分离较好目标社区。此外,该方法可以扩展到网络中多个社区发现任务中。在人工数据和真实网络数据上的实验结果验证了本文所提算法的有效性和效率以及应用价值。基于熵加权属性子空间的目标社区发现框架图如图1所示。
1 属性子空间权重挖掘
对于一个社区而言,每个属性对社区均有贡献,但贡献不同,部分贡献较高的属性构成属性子空间。在社区发现过程中为每个属性分配一个权重,以衡量属性在该社区中的贡献,贡献越大则子空间所对应的属性权重值越大。因此,对于目标社区发现而言首要任务是捕获基于属性子空间的属性权重即属性子空间权重,然后在属性子空间权重的指导下挖掘目标社区。本文首先从属性和结构两个方面综合考虑节点间的相似度,基于用户给定的样例节点挖掘目标社区中心点集,然后在目标社区中心点集指导下推断该社区的属性子空间权重。
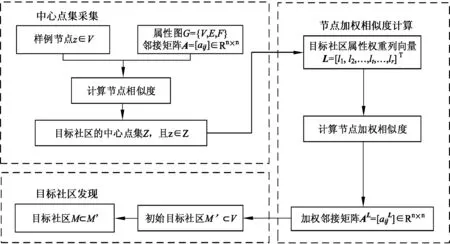
图1 熵加权属性子空间的目标社区发现框架图
1.1 中心点集采集
中心点集的采集是为了挖掘目标社区的属性子空间权重。对于目标社区,其内部节点只在对应属性子空间权重下彼此相似且与外部节点不相似。本文结合节点间的属性相似度与结构相似度利用用户给定的样例节点挖掘目标社区中心点集。
定义1(节点属性相似度): 节点u和v的属性相似度s(u,v)定义如式(1)所示。
s(u,v)=exp(-‖f(u)-f(v)‖2)
(1)
其中,‖f(u)-f(v)‖2为节点u,v属性列向量差值二范式,节点间属性相似性介于0和1之间。
定义2(节点结构相似度): 节点u和v的结构相似度σ(u,v)定义如式(2)所示[11]。
(2)
其中,N(u)={v∈V|u,v之间有边}∪{u},d(u)=|N(u)|-1。直观地说,对于两个节点,其共同邻居节点越多,结构相似度越大。任意两个节点间的结构相似度介于0和1之间。
对于给定图G={V,E,F},由于用户给定的样例节点个数有限,不能够提供更为有效的信息。所以,以用户所给定的样例节点作为目标社区中心点扩展得到中心点集。具体考虑到与中心点来自同一社区的邻居节点,应该在属性与结构上彼此相似。首先初始化目标社区中心点集Z={z},中心点集计算如式(3)所示。
Z={v|{(s(z,v)+σ(z,v))/2>β},
v∈(V-Z)}
(3)
其中,β为相似度阈值。然后,根据式(3)扩展得到社区中心点集Z={z1,z2,…,zc}。其中,c为中心点集中节点的个数。
1.2 基于熵加权的属性子空间权重挖掘
对于目标社区中心点集,计算使它们彼此相似的属性权重,则该属性权重就是能够使得社区中的内部节点基于属性彼此相似且与外部节点不相似。换句话说,该权重应该使中心点集中节点彼此之间基于属性有一个很小的距离。与文献[12]迭代的计算每个簇的属性权重不同,本文在不需要迭代优化的情况下,定义目标社区属性子空间权重,用目标函数计算属性子空间权重向量。目标函数定义如式(4)所示。
(4)
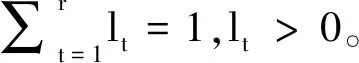
通过对F(L)最小化,求得式(5):
(5)
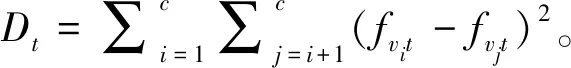
推导过程详见附录。
2 社区发现
推断出目标社区的属性子空间权重L=[l1,l2,…,lr]后,挖掘中心点集及权重所对应的目标社区。本节以中心点集Z作为目标社区的种子,调整种子以找到基于属性子空间权重内部连接紧密且与外部有较好分离性的目标社区。值得注意的是,在推断目标社区时是局部提取的,而不是划分整个图。
2.1 目标社区质量评估
为了衡量社区内节点的紧密程度,以及与外部节点的分离程度,本文定义了适度函数[2]作为一个局部的质量函数用来评估目标社区的内部紧密性和外部可分离性。
定义3(社区适度): 社区M的适度被定义如式(6)所示。
(6)
其中,invol(M)=∑vi,vj∈Maij表示社区节点内部度之和,vol(M)=∑vi∈M,vj∈Vaij表示社区节点度之值,当社区具有较多的内部边,较少的交叉边时,适度值较大。
为了评估目标社区质量,将目标社区基于属性子空间权重下的属性和结构相似度设置为边权值,然后相应地修改适度函数来重新衡量网络。基于目标社区属性子空间权重L,节点属性相似度根据式(1)被更新为如式(7)所示。
sL(u,v)
(7)
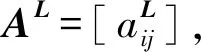
在重写权重的网络中,如果两个内部节点在属性和结构上更为相似,则它们之间的边将得到一个较大的权重。重写权重的社区适度函数被定义如式(8)所示。
(8)
社区适度可以评估目标社区的质量。当社区拥有较多的内部边,并且社区内部节点与外部节点之间的交叉边较少,与此同时基于推断的目标权重,社区内部节点间具有更高的属性和结构相似度时,目标社区的适度值较大。
2.2 目标社区发现
确定了目标社区中心点集及对应的属性子空间权重后,从图G挖掘中心点集及属性子空间权重所在的目标社区。先以中心点集作为目标社区的种子,再扩展种子以找到目标社区。算法1中描述了初始目标社区的挖掘过程。

算法1 初始目标社区挖掘输入:属性图G={V,E,F},中心节点集Z,属性子空间权重L输出:初始目标社区集合M′1. CN=ϕ;#存储候选节点2. M′=Z;#初始化初始目标社区集合3.CN={v|vi和v之间有边,vi∈Z,v∉Z∧v∈V};#将集合中现有节点的邻居节点作为候选节点4.ΔfitL(M′)=0,ΔfitL(M′)best=0;#ΔfitL(M′)记录每次添加节点时目标社区适度值的变化ΔfitL(M′)best记录适度值的最大变化5.Repeat6. bestNode=null;#最佳候选节点7. Foreachv∈CNdo8. ΔfitL(M′)=fitL(M′,add(v))-fitL(M′);#节点v加入社区时适度值得变化9. IfΔfitL(M′)>ΔfitL(M′)best≥0

续表
本文采用贪婪算法对目标社区进行局部调整,在每次迭代中,计算所有可能调整适度变化的操作,选择适度正变化最大的节点加入目标社区。迭代继续,直到没有节点的加入导致适度发生正的改变,社区的适度值不再增加。算法1中,第8行(M′, add(v))表示将节点v加入社区M′的操作。
节点的添加是基于一种改进的最优搜索策略,每次添加的节点都是当前最优的选择,在算法2中采用了追溯策略检查是否有节点的移除使得社区的适度正向增加。

算法2 目标社区更新输入:初始目标社区M′输出:更新后的目标社区M1. CN=M′; #存储候选节点2.M=M′;#初始化目标社区集合3.ΔfitL(M)=0,ΔfitL(M)best=0;#ΔfitL(M)记录每次删除节点时目标社区适度值的变化,ΔfitL(M)best记录适度值的最大变化4.Repeat5. bestNode=null;#记录最佳删除节点6. Foreachv∈CNdo7. ΔfitL(M)=fitL(M,remove(v))-fitL(M);8. IfΔfitL(M)>ΔfitL(M)best≥0;9. ΔfitL(M)best=ΔfitL(M);10. bestNode=v;11. Endfor12.CN←CN/{bestNode};#更新候选节点集合13.M←M/{bestNode};#更新目标社区集合14.ΔfitL(M)best=0;15.UntilbestNode=null;#直到没有节点的删除使得目标社区的适度值正向增加停止循环16.ReturnM;
算法2中第7行(M, remove(v))表示将节点v从M中删除。
社区的适度值介于0到1之间,每次选择节点加入社区或者删除社区中的节点都能使得目标社区的适度值正向增加,因此算法的收敛性得到保证。
2.3 方法扩展
本文所提出的方法不仅适用于基于用户的目标社区发现任务,同样适用于网络中多个社区的挖掘以及离群点检测任务。挖掘的同一社区的节点之间彼此相似而不同社区的节点之间相似度较低。
首先,在节点集中随机选取一个节点v作为第一个社区的中心z1,利用基于熵加权属性子空间权重的目标社区发现方法,挖掘得到以z1为中心的属性权重L1及社区M1。其次,从属性和结构两个方面综合考虑节点间的相似度,基于改进的K-medoid算法[13]计算得到下一个社区中心点,利用得到的社区中心点挖掘对应社区。重复迭代,直到无法得到满足条件的新的中心点。
对于给定图G={V,E,F},先初始化社区集合K=Ø,离群点集合C=Ø,在节点集中随机选取第一个点v作为第一个社区的中心z1,Z={z1},V=V-{z1}。利用基于熵加权属性子空间的目标社区发现方法得到z1所在的社区M1V,且K被更新为K=K{M1}。再根据式(9)选取G中与集合K所包含得社区中的节点基于属性和结构最大相似度最小的节点作为下一个社区中心点,如式(9)所示。
(9)
其中,zi为第i个社区的中心,α为决定社区中心个数的阈值,若α越大则得到的社区中心个数越多得到的社区越多。不断重复直到V中无满足式(9)的点时结束,得到的社区中心为Z={z1,z2,…,zk},社区集合K={M1,M2,…,Mk}以及所对应的属性子空间权重L={L1,L2,…,Lk},k为社区的个数,孤立点集合C=V-M。
3 实验结果及分析
为了验证TC-AE算法的有效性和效率,在本节中,分别在人工数据集和真实数据集上设计了两组实验。首先,对实验所用的人工数据集和真实数据集进行描述;其次,观察不同β和γ的参数值对实验结果的影响,选择适宜的参数;最后,选取两个目标社区划分算法和一个典型的社区划分算法与本文方法进行比较。
3.1 数据描述
3.1.1 人工数据集
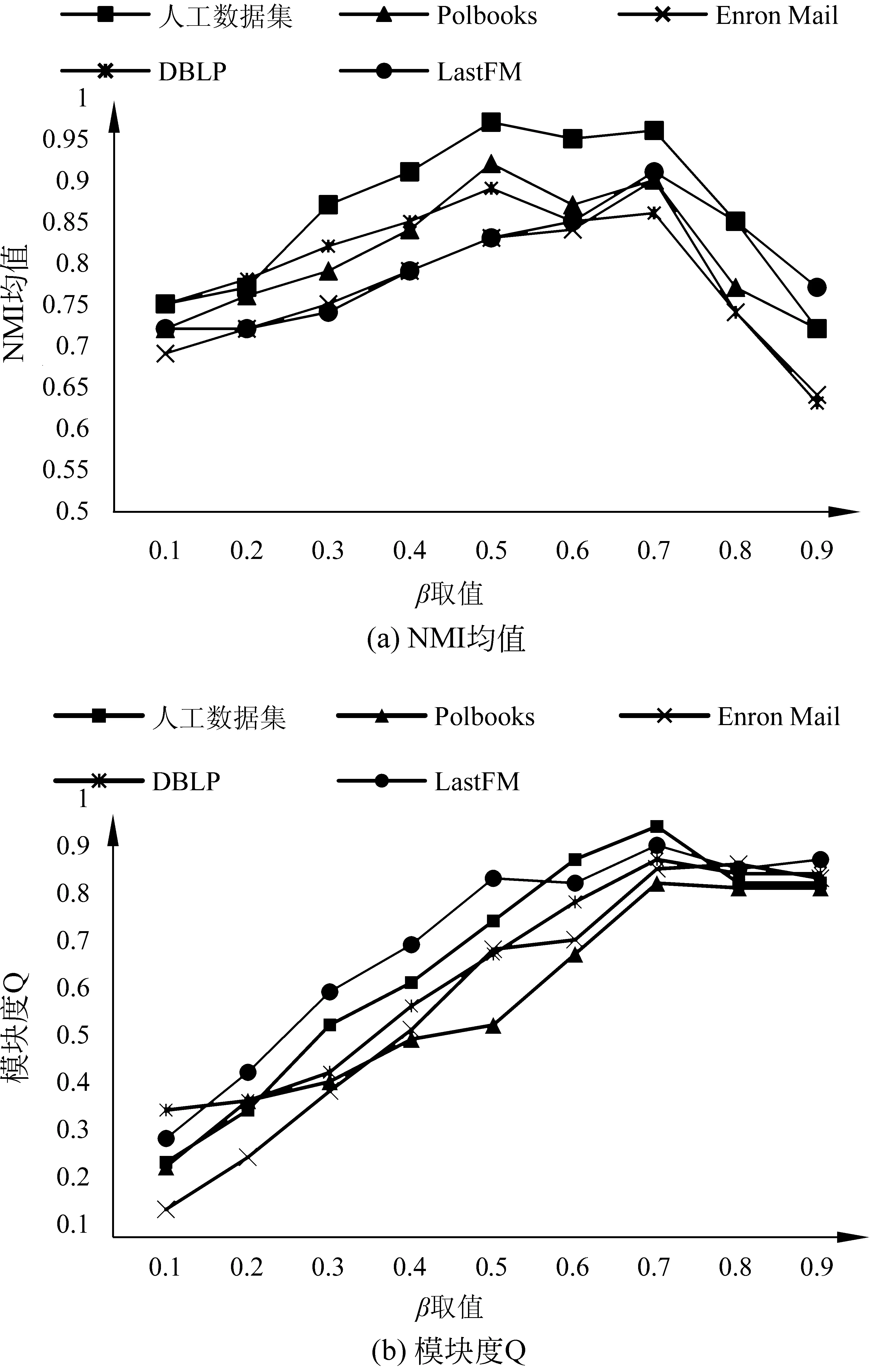
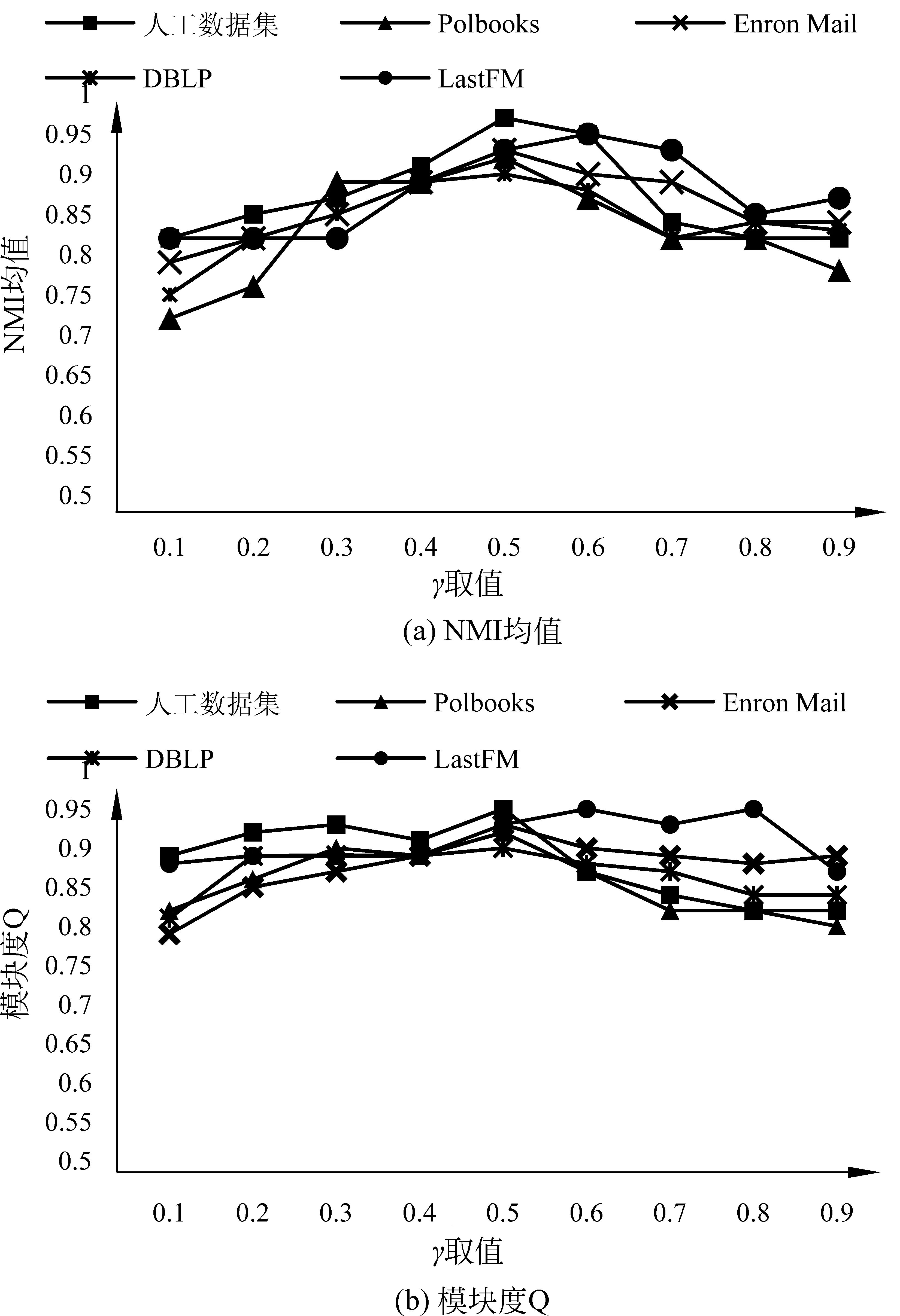
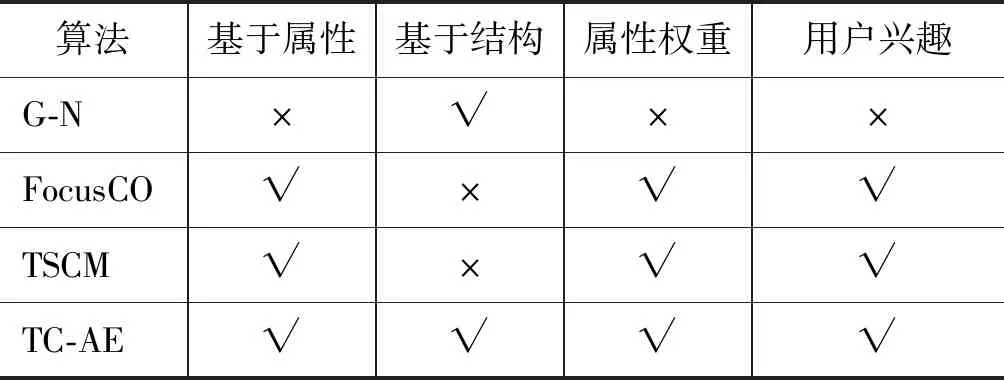
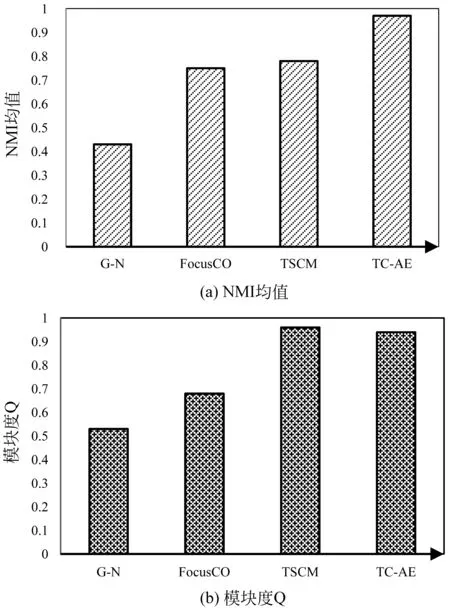
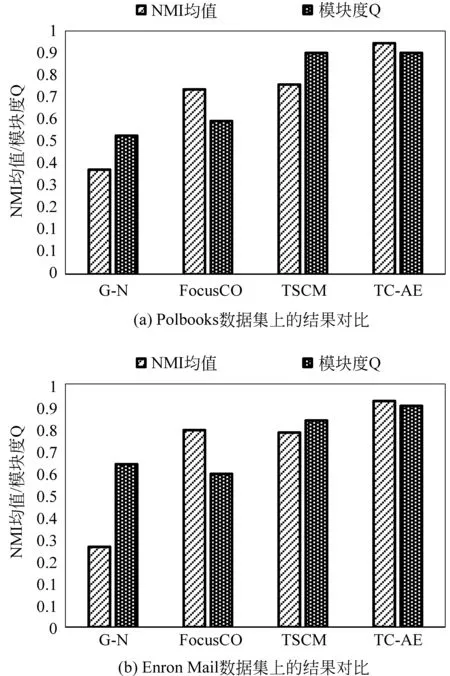
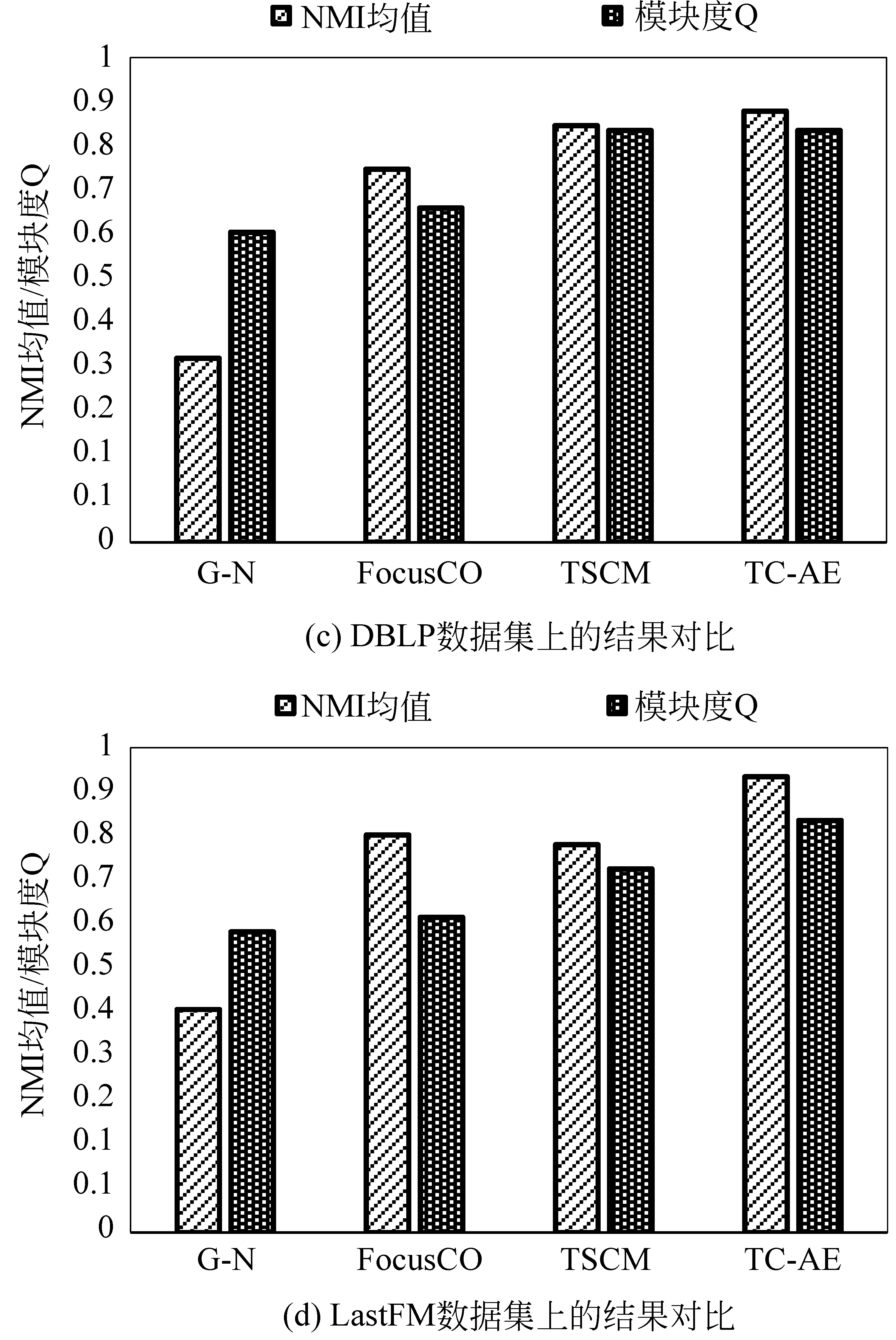
本节生成了具有不同节点数目社区的人工网络,这些社区内部节点之间基于属性相似且彼此连接紧密。人工网络生成算法是基于人工分区模型[14]。简单地说,给定每个集群中所需的节点数,通过分区约束将邻接矩阵分割成块。对于每一个块Bi j,选择一个概率pi j,除对角线外,使用随机绘制过程分配一个1,即一条可能存在的边,其余为0。换句话说,pi j衡量了每个区块的密度。对角线上的块构成实际的社区,非对角线块产生社区之间的交叉边。本文设定pi j=0.35,0.10 然后,对生成的社区分配一个不相同的属性子集(子空间)或不分配任何属性。值得注意的是,在现实世界的图中,每个社区中的成员基于多个属性彼此相似。对于每个带有属性子空间的社区,其节点基于分配的属性子集中的每个属性i,属性值fi从均值i∈[0,1]和方差σ=0.001的正态分布N(μi,σ)中提取,使得社区的节点在对应的属性子空间上“一致”。其余的属性是从方差更大的正态分布N(0,1)中提取的。对于没有分配属性子空间的社区其节点属性值均从方差大的正态分布N(0,1)中提取的。 本文共生成了6个内部节点基于属性子空间彼此相似且连接紧密的社区(社区1—社区6)和1个不分配任何属性子空间的社区(社区7),总共有7个社区。实验利用给定的来自社区1的样例节点挖掘社区1。人工网络数据集如表1所示。 表1 人工网络数据集 3.1.2 真实数据集 选取4个真实世界中的属性网络进行验证。Polbooks(1)http://www-personal.umich.edu/~mejn/netdata/是从Amazon上销售的与美国政治相关书籍页面上建立起来的网络。节点代表在Amazon在线书店上销售的美国政治相关图书,边代表一定数量的读者同时购买了这两本图书。网络中的节点分成为3个社区: 分别是“自由派”“保守派”和“中间派”。这些派别的划分是由Mark Newman根据Amazon上对于图书观点以及评价情况的人工分析得到的。Enron Mail(2)http://bailando.sims.berkeley.edu/enron/是目前在电子邮件相关研究中使用最多的公开数据集,其邮件数据是安然公司150位高级管理人员的来往邮件。邮件按主题分为13个类。DBLP(3)https://dblp.uni-trier.de/xml/是计算机领域作者的合著网络,以作者与作者合著的国际期刊和会议等公开发表的论文为边构建关系网络。DBLP集成元素不多,只有最基本的论文题目、时间、作者、发表类型及期刊或会议名称等等,包括国际期刊和会议等公开发表的论文。DBLP中以作者的主要研究方向所在的十个领域为社区划分标准。LastFM(4)http://www.dtic.upf.edu/~ocelma/MusicRecommendationDataset/lastfm-360K.html是用户收听音乐的信息,具体包括双向的朋友关系、艺术家、用户收听艺术家信息、用户对艺术家的标签信息、艺术家标签信息。LastFM中的成员被划分到该成员收听最多的音乐风格,例如,house、Britpop、Trip-Hop、Gangsta Rap等。预处理后的真实数据信息详见表2。 为了评价挖掘出的目标社区是否符合“基于用户偏好的内部连接紧密且与外部分离较好”,本章采用两种评价指标。一是,标准化互信息(NMI)均值[15],即同一数据集中运行100次的NMI的平均值,度量了算法结果与标准结果之间的相似性。该相似性越高,NMI值越接近1;反之,则NMI值接近0。二是目标社区的模块度Q[16],反映了社区的一致程度。模块度越大,则表明社区划分效果越好。Q值的范围在[-0.5,1)。研究表明当Q值在0.3~0.7之间时,说明聚类的效果较好。NMI与Q作为后续评价指标一并用于实验效果的综合评价[17]。 表2 真实数据集 3.2.1 参数分析 式(3)中,相似度阈值β作为选取中心点集时,邻居节点与样例节点间相似度的最低标准,在目标社区发现中有着极高的重要性。为选择合适的阈值,将β作为自变量,给定不同的β观察标准化互信息NMI均值和模块度Q的变化。该实验在5种数据集上进行。如图2所示,x轴为β在0到1之间的不同取值,y轴为NMI均值或模块度Q的变化情况。 图2 参数β对NMI均值和模块度Q的影响 可以看到在β=0.75时,五个数据集上的NMI均值都较高,即将参数β设定为0.75可使得算法结果与标准结果之间的相似度趋于最大化,该数值也将用作后续实验中参数的取值。 根据式(2)的目标函数可以知道γ是一个正调节因子,用于控制多维度权重的一个正参数激励强度。本小节将通过实验对参数进行调节,以确定最优的实验参数。将参数γ作为自变量,给定不同的参数值观察NMI均值的变化。通过比对不同的参数下的NMI均值,取使得目标社区的NMI均值最大的参数值作为给定参数,该实验分别在人工数据集和真实数据集上进行。如图3所示,x轴为参数γ在0到1之间的不同取值,y轴为NMI均值或模块度Q的变化情况。 图3 参数γ的对NMI均值和模块度Q的影响 当γ在[0.4,0.7]时,五个数据集上的NMI均值变化较小,因此γ的值设定为0.5,该数值也将用作后续实验中参数γ的取值。 3.2.2 与其他算法的对比 选取两个目标社区划分算法FocusCO、TSCM和一个经典的社区发现算法Girvan-Newman(G -N)[18]与本文方法分别从发现的目标社区质量和时间两方面进行比较。其中,FocusCO创新的提出了以用户为中心的属性图目标社区发现方法;TSCM基于目标子空间挖掘目标社区集合;G -N作为经典的社区发现算法不执行目标社区划分,则测量该方法返回的最佳社区与标准社区之间的相似度。因此,本文选取上述3种方法作为实验参照,各算法对比如表3所示。 表3 与现存方法对比 在人工数据集上,分别对4种方法进行实验,并对实验结果进行综合评估。NMI均值和模块度Q的值越大,则表明社区划分效果越好。 图4展示了本文所提出的算法和所选对比算法在NMI均值和模块度Q上的比较。由图可知,在人工数据集上,本文所提出的算法挖掘的目标社区NMI均值最高与标准社区最为相似,效率最高;FocusCO与TSCM算法挖掘的目标社区NMI均值较为接近且均低于本文所提出算法;G-N算法效率最低。 为了进一步验证实验效果,本节在4个真实数据集上与3个对比算法进行实验,利用NMI均值和模块度Q值对实验结果进行综合评估。 图5展示了本文所提出的算法和对比算法在NMI均值和模块度Q上的比较。由图可知,在4种数据集上,本文所提出的算法挖掘的目标社区NMI均值在所有真实数据集较为稳定且最高。如图5(a)所示,在Polbooks数据集上,TW-EC挖掘的目标社区模块度Q略低于TSCM。由算法可知,在挖掘目标社区时,同时考虑节点间的加权属性相似度和结构相似度并更新节点间边的权重信息。在以适度函数作为衡量标准扩展中心点集时,降低了部分权重值较低的边对于目标社区的影响。因而,模块度Q略低于TSCM。 图4 4种算法在人工数据集上的结果对比 图5 4种算法在真实数据集上的结果对比 图 5(续) 针对现有的大多数社区发现算法未能充分考虑用户的偏好,本文提出一种基于熵加权属性子空间的目标社区发现方法,挖掘与用户偏好相关的社区。该方法利用用户所提供的样例节点挖掘目标社区的种子集合,基于种子集合推断能够使得目标社区内部节点基于属性彼此相似的属性子空间权重;然后,结合节点间的加权属性相似性和结构相似性扩展中心点集得到目标社区。解决了传统社区发现算法忽略节点的属性权重或只利用部分属性的问题。最后,分别在人工数据集和真实数据集上实验,证明了本文所提算法的效率和有效性。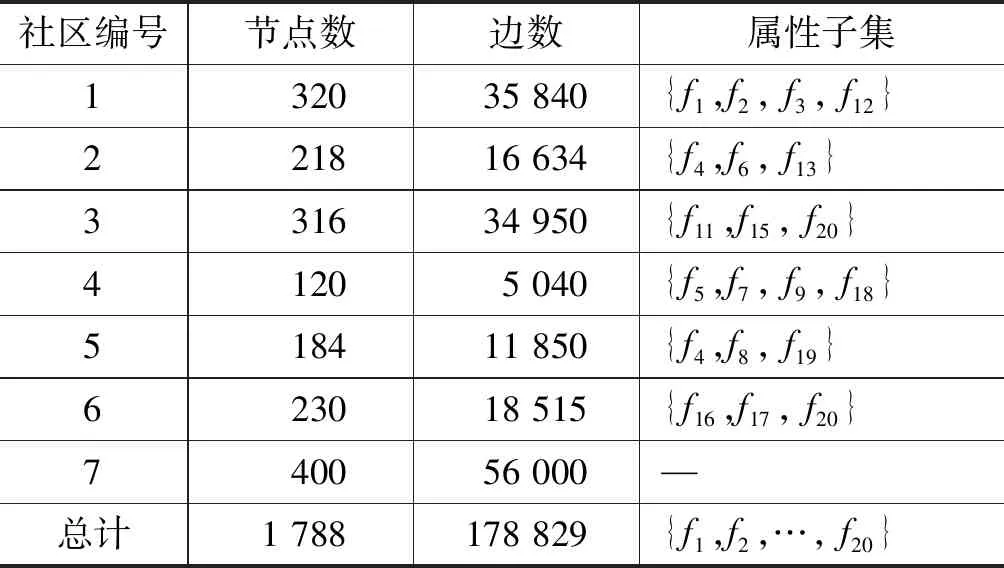
3.2 实验结果及分析

4 总结
猜你喜欢
数学物理学报(2021年3期)2021-07-19 06:02:32
当代陕西(2020年17期)2020-10-28 08:18:18
电脑报(2020年12期)2020-06-30 19:56:42
电脑报(2019年4期)2019-09-10 07:22:44
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
小天使·五年级语数英综合(2017年3期)2017-04-25 13:15:13
读写算·小学低年级(2017年1期)2017-02-06 15:40:18
少儿美术·书法版(2016年1期)2016-02-06 00:59:39
大众摄影(2015年9期)2015-09-06 17:05:41
