
改进加权模糊C均值算法的风电变压器故障诊断
2019-09-04 10:14丁云飞
上海电机学院学报 2019年4期
张 贵, 丁云飞
(上海电机学院 电气学院, 上海 201306)
风能是我国大力发展的清洁能源,近几年,我国风力发电规模不断扩大,风力发电技术也愈发成熟,并且有着广阔的发展前景[1]。当风力不稳定的时候,风电系统的输出电压也会不稳定,这会导致风电变压器出现各种故障,甚至有可能发生重大事故。因此,在故障初期精准地发现变压器的故障并对典型故障进行分析,是保障风电变压器安全可靠运行的重要举措[2]。
模糊C均值(Fuzzy C-Means, FCM)算法是在K-means的基础上加入了模糊的思想,赋予每一个样本数据隶属度,从而实现模糊划分,聚类性能得以加强。FCM算法因其良好的效果在分类和故障诊断等方面得到大量应用。自从1974年Dunn等[3-4]提出FCM算法后,该算法被科研工作者研究改进,聚类性能和效果进一步提高。如刘长良等[5]采用变分模态分解方法提取特征向量,通过FCM聚类方法对滚动轴承故障进行故障识别,能快速地得到聚类中心,且诊断精度为100%。唐燕雯[6]将模糊核聚类算法应用于船舶故障诊断,得到了收敛速度快、鲁棒性强的故障诊断模型。代宪亚等[7]针对电厂的复杂性,将FCM算法和神经网络结合在一起,从确定隶属度到处理参数,再到神经网络诊断,最后将结果融合,从而得出高准确度的诊断结果。李赢等[8]提出基于FCM和改进相关向量机的模型,该模型采用完全二叉树改进相关向量机,对故障诊断精度有明显提升,也为实时在线检测发现故障并及时做出诊断提供了实用价值。王军辉等[9]利用集合经验模式分解得到特征矩阵,特征矩阵处理后进行模糊聚类分析,并将其应用到齿轮箱故障诊断中,实验表明,该方法更能有效进行故障分类。
由于FCM算法没有考虑样本向量中每个维度特征的差异性情况,特征加权FCM(Feature-Weighted C-Means, WFCM)算法被提出。文献[10]将特征权重、核函数与模糊聚类方法结合,将核函数从低维映射到高维,并对样本各维度加权,对于维度较高的样本有较好的处理效果,该方法在汽轮发电机组故障诊断中得到了有效的验证。文献[11]改进了人工鱼群优化,并与WFCM算法结合,能够使算法收敛更快并解决FCM受初始值影响较大的问题。文献[12]对模糊C有序均值算法通过极差正规化的手段特征加权,既保证了算法的健壮性,又能优化样本数据的分布。
本文在WFCM算法的启发下,提出基于改进加权FCM(Improved Feature-Weighted Fuzzy C-Means, IWFCM)算法的故障诊断方法,并将其应用到变压器故障诊断中。该方法考虑到聚类过程中聚类中心的变化会带来样本分布的变化,因此,权重也应动态更新来适应样本的重构。通过采用动态更新特征权重的方法,使得样本的分布更趋于合理,诊断准确度得以提高,从而为变压器的故障诊断技术提供一种新的研究方法。
1 基本算法理论
1.1 FCM算法
FCM算法通过对每一个样本数据赋予隶属度,使得聚类过程中聚到同一类的样本有最大的相似度,从而实现了样本数据的模糊划分。FCM算法以较为简单的结构和较强的聚类性能被应用于众多领域,是最受科研工作者们喜爱的算法之一。
有数据集D={xi}∈Rd,其中xi∈Rd,d为特征维数,C为分类数。聚类目标函数表示为
(1)
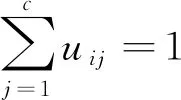
(2)

(3)
1.2 IWFCM算法
本文所提到的IWFCM算法,通过动态更新特征权重,使得不同比重的权重值能够体现各维度特征在聚类过程中所起作用的大小,这对于特征的细分优化有非常大的提升。IWFCM算法的目标函数为
(4)
式中
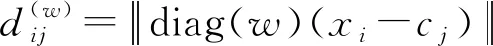
(5)
(6)
(7)
IWFCM算法是在经典的FCM算法上动态更新特征权重,使得权重得以重新分配,某些布局不均衡的样本分布也变得更合理,样本精度得以提高。IWFCM算法的具体步骤如下:
步骤1采集风电变压器故障样本,对样本做预处理。
步骤2设置参数,包括分类数C,模糊度m,隶属度uij。
步骤3初始化隶属度uij和特征权重wd。
步骤4按照式(5)~式(7)更新隶属度、聚类中心和特征权重。
步骤5判断迭代终止条件是否满足,若不满足,则转到步骤4;若满足,则停止迭代过程。
步骤6依据特征权重值的大小来判断各维度在聚类过程中所起的主次作用,通过隶属度的大小来判断故障类型。
2 风电变压器故障诊断模型
2.1 选取特征气体和预处理数据
风电变压器在工作过程中处于故障状态时,相比于正常工作状态,产生的H2、CH4、C2H6、C2H4和C2H2等含量会大幅增加。而且对于不同类型的故障,原始样本中气体含量会有较大的数量级差异。因此,以H2、CH4、C2H6、C2H4和C2H2这5种气体的体积分数作为特征量,为了减少计算误差,需要经过归一化处理后再加载到故障诊断模型。归一化公式为(处理后的样本数据值介于0到1之间)
(8)
2.2 风电变压器故障诊断的具体实现
基于IWFCM算法的模型充分考虑了数据各维度之间权重的差异,动态更新特征权重可以在训练阶段实时体现聚类信息的变化。基于IWFCM算法的风电变压器故障诊断的具体实现过程如下:
(1) 采集样本数据。采集风电变压器5种油中溶解气体的气体含量数据,构成原始数据集。
(2) 数据预处理。利用式(8)对原始数据做归一化处理,并将处理后的样本集作为输入样本。
(3) 建立故障诊断模型。确定故障样本的聚类中心和隶属度,利用式(7)动态更新数据集特征权重,使得不同的权重能够对样本的分布有更合理的重构,建立起动态加权的故障诊断模型。
(4) 故障结果分类。将样本数据输入诊断模型,聚类后通过隶属度矩阵的大小得出诊断模型聚类后的故障类别,通过特征权重矩阵的大小找出对聚类结果影响较大的几维特征,从而得出5种气体中哪几种气体的含量对聚类的效果影响较大。
故障诊断流程如图1所示。
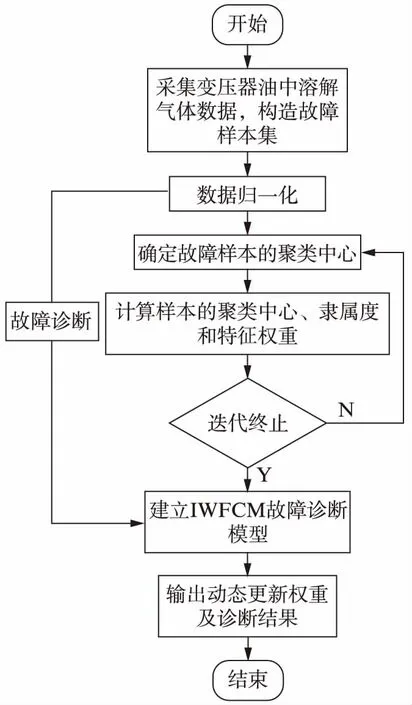
图1 故障诊断流程图
3 实验与结果分析
3.1 聚类样本的获取与选择
本文反映变压器故障类型的油中溶解气体数据来源于风电公司,数据共有246组。在本文中,将风电变压器的故障类型分为6种,具体样本个数分布如表1所示。
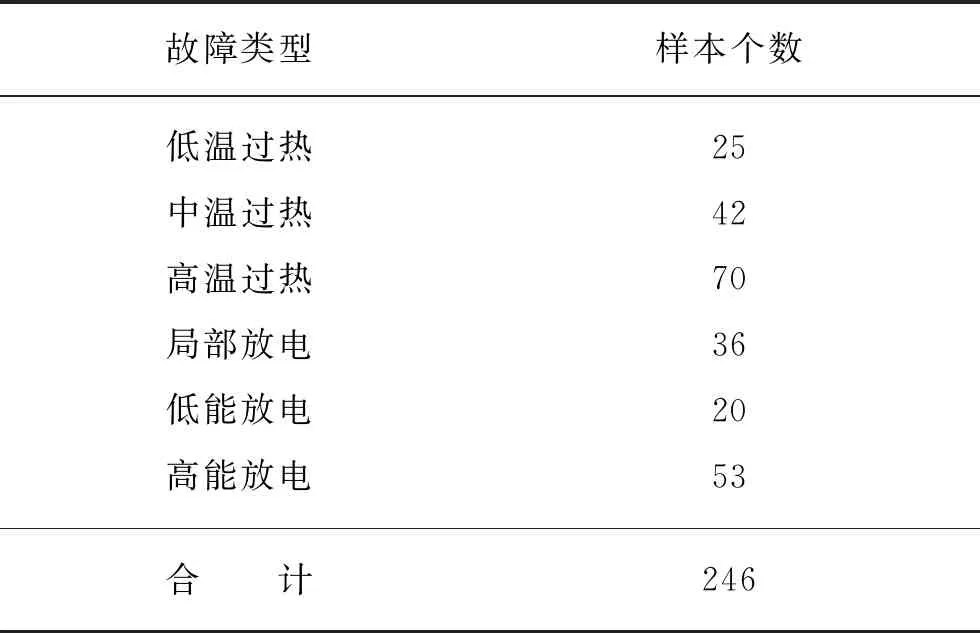
表1 故障样本集组成
3.2 故障诊断效果及对比
为验证所提方法的可行性,分别利用K-means方法、FCM和IWFCM诊断方法来识别故障并比较实验结果。设置以下参数:m=2,C=6。
聚类效果如图2~4所示。图中,横向是实际6种聚类结果,纵向是聚类后的情况。混淆矩阵对角线上的数字代表聚类结果与实际情况相符的聚类个数。
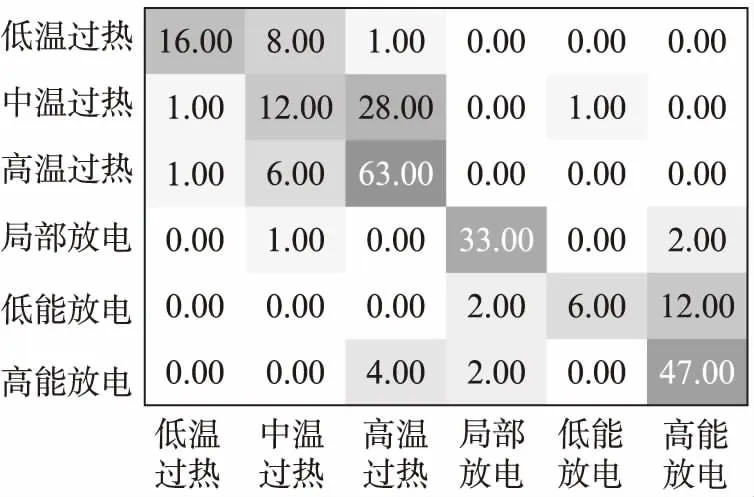
图2 K-means聚类结果与实际情况的混淆矩阵

图3 FCM聚类结果与实际情况的混淆矩阵
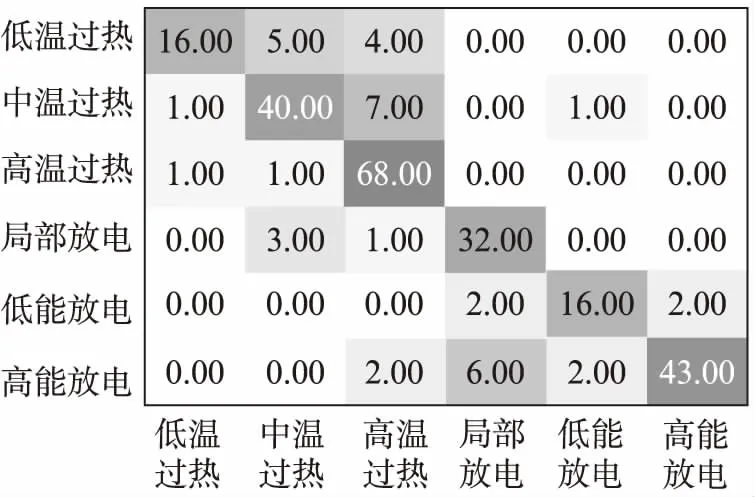
图4 IWFCM聚类结果与实际情况的混淆矩阵
图2中聚类后的低温过热中有16个样本与实际情况相符,8个被分到了中温过热,1个被分到了高温过热。IWFCM诊断方法在中、高温过热和低、高能放电上,相较于K-means和FCM诊断方法,故障识别精度分别有了大幅度的提升。其中,K-means、FCM、IWFCM诊断方法在中温过热上准确率分别为28.57%、78.57%、95.24%;在高温过热上准确率分别为90%、62.86%、97.14%;在低能放电上准确率分别为30%、55%、80%;在高能放电上准确率分别为88.68%、39.62%、81.13%。在低温过热和局部放电上,3种诊断方法的准确率无明显变化。虽然在高能放电上K-means诊断方法的精度最高,但其比IWFCM方法高的并不多,而且从整体上看,IWFCM诊断方法的精度是最高的,为87.40%。
K-means和FCM中各维度的特征权重都是相同的,对于维度较高的数据集,K-means和FCM在聚类结果上会受到不重要维度和噪声特征的干扰。因此,在FCM中加入了动态更新的特征权重,使得贡献权重的分配更趋于合理,得到的故障识别率更加精确。
3.3 故障诊断结果分析
相较于K-means和FCM,IWFCM由于加入了动态更新的特征权重,使得样本数据集的每一维特征都有着不同比重的效果,且该特征权重在训练过程中是实时更新的,因此,对于高维度的数据而言,可以突出某些维度特征的主要作用,降低冗余特征的干扰。在IWFCM聚类所得到的结果中,由权重所得到的特征权重直方图如图5所示。由图5可知,第3、第5维在聚类过程中所占的比重较大,即C2H6和C2H2是主导特征。这与实际情况是相符的,因为当变压器绝缘油分解产气只有热源输出时,主要产生低分子烃类气体,其中CH4和C2H6的含量占总烃的80%以上,而当火花放电时,产生的主要气体是C2H2。由于动态更新特征权重能够优化样本的分布,因此,可以得到最优的聚类中心。最优聚类中心如表2所示。
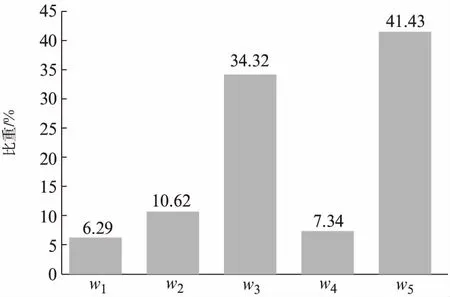
图5 5种气体的特征权重直方图
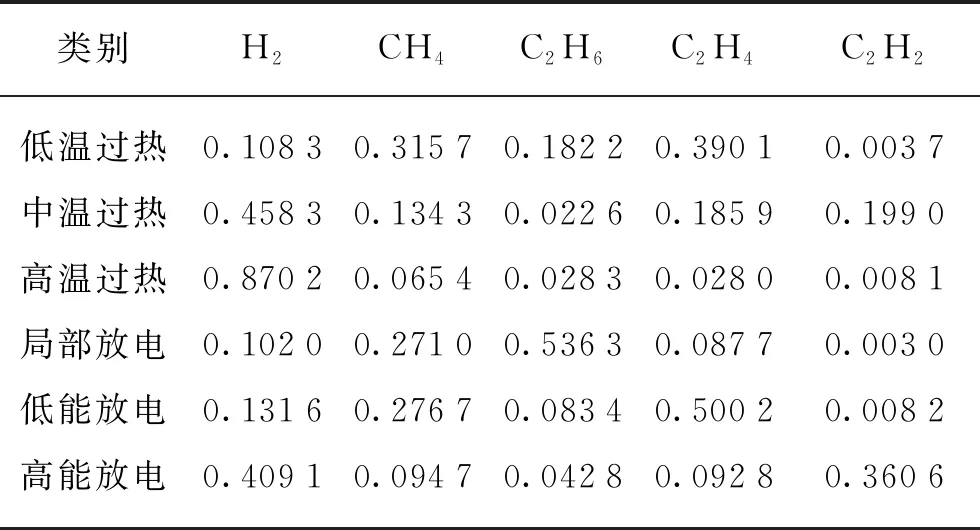
类别H2CH4C2H6C2H4C2H2低温过热0.10830.31570.18220.39010.0037中温过热0.45830.13430.02260.18590.1990高温过热0.87020.06540.02830.02800.0081局部放电0.10200.27100.53630.08770.0030低能放电0.13160.27670.08340.50020.0082高能放电0.40910.09470.04280.09280.3606
4 结 论
风电变压器发生不同故障时,其内部产生的气体含量是不同的,各气体在聚类过程中所起的作用也是不同的。针对一般的聚类方法未考虑到数据各维度之间权重的差异,本文提出了IWFCM算法的风电变压器故障诊断方法,该方法在传统的FCM算法中通过动态更新特征权重,使得样本数据集的每一维都有着主次划分,突出了某些特征对聚类的主要影响,降低了冗余特征的干扰。结果表明:此方法可以优化数据的分布,极大地提高聚类准确率,特征权重矩阵能够反映出聚类过程中数据集各维度所起作用的不同,对于变压器的故障诊断有着重要的参考价值。
猜你喜欢
一重技术(2021年5期)2022-01-18
当代陕西(2020年17期)2020-10-28
铁道通信信号(2019年6期)2019-10-08
人大建设(2018年5期)2018-08-16
电子制作(2018年10期)2018-08-04
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
应用科技(2015年5期)2015-12-09
振动、测试与诊断(2014年5期)2014-03-01
