
基于自组织映射神经网络K-means 聚类算法的风电场多机等值建模
2019-09-02 08:35:14侯玉强
浙江电力 2019年8期
赵 凯,侯玉强
(1.国网浙江省电力有限公司绍兴供电公司,浙江 绍兴 312000;2.南瑞集团有限公司,南京 211106)
0 引言
随着能源短缺和环境污染等问题的日益突出,大力发展可替代的清洁能源是当今世界各国研究的重点。风能作为重要的清洁能源在全世界得到了广泛的应用。然而,随着风电场规模的不断扩大,一个风电场往往含有几十甚至几百个机组,这给大电网仿真建模带来巨大的挑战。在高比例风电接入电网情况下,如果对每台机组都进行详细建模,不仅会耗费大量的计算时间,而且对计算机的软硬件也提出很高的要求。为解决这一问题,本文对大型风电场进行合理等值建模展开研究并进行相应的仿真分析[1-2]。
在风电场等值方法中,一般可以分为单机等值法和多机等值法。单机等值法[3]是将大型风电场等效为一个风力机加发电机,现在电力系统最常用是容量加权单机等值法。该方法以自身额定容量与同群机组总的额定容量之比作为权值系数,对风电机组各参数进行加权求和。文献[4]提出了容量加权法的具体公式和理论推导。文献[5]用容量加权法把一个大型风电场等值成一台风电机组,但没有考虑到风速差异对风机等值的影响。随着风电机组台数的增多及风机尾流效应的影响,可能导致单机模型与实际风电场输出特性相比误差较大,仅凭单机等值模型难以表征整个风电场的实际工况。多机等值法是将风电场等效为多台风力机和发电机的组合,这种方法相较于单机等值法,模型拟合精度更高,效果更好[6-7]。但相对而言步骤较复杂,首先需要选取能够反映机组实际运行特性的分群指标,然后对风电场的所有机组进行分群,最后将同群机组等值为一台风机模型,从而形成由若干等值机构成的多机等值模型来表征整个风电场。所以对于风电机组的多机等值法,分群指标和聚类方法是关键所在,目前最常用的方法是基于聚类算法的多机等值法,文献[8]提出了一种基于K-means 算法的风电场多机等值建模,但是对于K-means 算法中分群数目K 的选取是人为给定。文献[9]应用模糊聚类算法对实际风电场进行多机等值,对于K 值的选取需要进行繁琐的隶属度的计算,随着风电机组台数的增多,其计算量也会增大。
本文提出基于SOM(自组织映射神经网络)Kmeans 聚类算法可以自动对风电场进行聚类分群。SOM K-means 聚类算法属于两阶段聚类算法:第一阶段,利用SOM 自动聚类的特质得到初始的聚类数目K 和聚类中心Z;第二阶段,将其作为K-means 聚类的初始输入得到具体的分群信息。该算法解决以往聚类算法在聚类时分群数目需人为给定的缺点,避免了复杂的计算过程。
1 算法描述
1.1 SOM
SOM 根据人类大脑神经元自组织映射的特点对样本进行自动聚类,属于无导师学习网络[10-11]。它可以根据样本特征和内在规律将高维数据通过神经元网络映射到低维空间,达到降维聚类的目的,其结构如图1 所示。它由输入层和输出层(也称为竞争层)两层网络结构组成,输入层与输出层之间通过权重向量连接。输入层对应于样本的输入向量;输出层对应于一系列神经元节点构成的二维平面。输出神经元节点与邻域内其他节点广泛相连,节点之间相互竞争以求被激活。在同一时刻只有一个神经元节点被激活,其他神经元节点被抑制。这个被激活的神经元节点称为获胜单元,更新获胜单元及其相邻区域的权值,使得输出节点保持输入向量的拓扑特征。通过这种无监督的竞争式学习网络,可完成对样本的自动聚类。具体步骤如下:
(1)网络初始化。对输出层每个节点权重Wj随机赋予较小的初值,定义训练结束条件。
(2)从输入样本中随机选取输入向量Xi,求Xi中与Wj距离最小的连接权重向量:

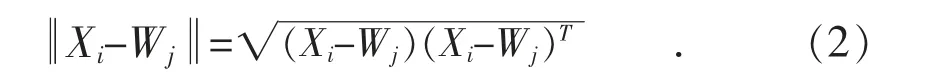
(3)定义g 为获胜单元,Ng(t)为获胜单元的邻近区域。对于邻近区域内的单元,按照式(3)调整权重使其向Xi靠拢:

式中:t 为学习次数;α(t)为第t 次的学习率;hgj(t)为g 的邻域函数。
(4)随着学习次数t 的增加,重复步骤(2)以及步骤(3)。当达到训练结束条件停止训练。

图1 SOM 神经网络结构
1.2 K-means 聚类算法
K-means 算法[12-13]作为一种经典的聚类算法,由于其简单、速度快的优势在大数据处理上被广泛应用。其基本原理是用距离函数作为相似度指标,将距离相近的样本对象划分为同一类别(称为“簇”)。由于每个样本对象的聚类中心是由簇中所有数据的均值得到的,但缺点是需要给定聚类数目、聚类中心,否则容易导致算法不收敛。K-means 算法具体步骤如下:
(1)随机从样本数据中选取K 个样本,将这K 个样本作为初始聚类中心。
(2)将其余的样本数据根据它们与初始聚类中心的欧式距离划分给距离最小的初始聚类中心,形成新的簇。
(3)重新计算每个簇的均值作为新的聚类中心。
(4)循环步骤(2)和步骤(3),直至每个聚类不再发生变化。
(5)输出样本具体的聚类分群信息。
结合表1 所示SOM 聚类和K-means聚类2 种算法的优缺点,提出SOM K-means 聚类算法,较好地将两种算法的优点相结合,具体算法流程如图2 所示。

表1 2 种算法比较
2 基于SOM K-means 聚类的多机等值法
2.1 分群指标的选取
多机等值法一般包括分群指标选取、风电机组聚类分群、同群机组等值3 个步骤,对于分群指标的选取,文献[14]提出一种以风电机组的风速、风向为分群指标对风电机组进行分群,在风速的基础上加入了风向,利用风速、风向进行快速分群。文献[15]根据故障切除前后风电机组的转速变化情况作为分群指标。本文为了提高多机等值法的工程实用性,选取以下表征风电场实际运行工况的5 种运行状态变量作为分群指标:风机运行时的有功功率、无功功率、机端电压、输出电流、平均风速。获取这5 个状态变量稳态运行时的数据,构成运行状态变量矩阵X。

图2 SOM K-means 聚类算法流程

式中:n 为机组数量;b 为指标个数。

式中:Pi,Qi分别为第i 台机组稳态时的有功功率、无功功率;Ui为第i 台机组机端电压有效值;Ii为第i 台机组A 相电流有效值;Vi为第i 台机组平均风速。
2.2 SOM 聚类
将上述运行状态变量矩阵X 作为SOM 聚类算法的初始输入,调用MATLAB 神经网络工具箱,SOM 聚类算法的参数设置:竞争层为6×6=36 个神经元节点,训练次数为10,学习率0.9,邻域半径为1。利用SOM 算法自动聚类的特性可以得到聚类数目K 和聚类中心Z,具体步骤如1.1 节所示。
2.3 K-means 聚类算法
K-means 聚类算法需要指定初始的聚类数目K 和聚类中心Z 来得到具体的分群结果。恰好上述SOM 聚类可以大致得到聚类数目K 和聚类中心Z,将其作为K-means 聚类算法的初始输入,输出具体的风电场分群信息,具体步骤如1.2 节所示。
2.4 同群机组等值
传统的同群机组等值主要依赖于容量加权单机等值法,一般包括风速等值、风电机组等值两个步骤,其从原理上都是对风电场多个风电机组进行参数聚合。随着风场规模的增大,风电机组数量增多,若对每台机组进行参数折算最终将导致计算量大且计算繁琐。因此本文提出采用单台风电机组并联理想受控电流源的方法来对同群机组进行等值。该方法仅保留1 台风电机组的详细模型(称为“中心机组”),其他机组模型通过并联受控电流源的方式进行模拟,将传统单机等值模型中的风速等值及风电机组等值步骤合并为一个步骤,从而简化了风电机组的等值计算过程。
2.4.1 中心机组的选取
由于本文所采用的同群机组等值需要1 台风电机组的详细模型(称为“中心机组”),因此合理地选取中心机组对准确表征整个风电场特性十分关键。假设同一群里有m 台机组,这里巧妙利用SOM 产生的聚类中心Z 与m 台机组指标向量X的距离关系,选择每个机组指标向量X 与聚类中心Z 距离最小的机组来作为能够表征同群机组平均运行状态的中心机组,其距离公式如式(2)所示。
2.4.2 并联受控电流源
选取能够反映机组平均运行状态的中心机组之后,需要通过并联受控电流源的方法将同群机组等值为1 台风机模型,从而形成由多台等值机构成的多机等值模型,如图3 所示,其具体过程如下:
(1)首先通过中心机组的详细模型获取其输送到风电并网点的输出电流Ii。
(2)然后将具有m-1 倍输出电流的受控电流源作为除中心机组以外的其他机组等值模型。
(3)最后将中心机组和受控电流源并联,形成等值机群模型。
2.5 等值建模
基于PSCAD 仿真平台,将多机等值模型、传统的容量加权单机等值模型[16]及详细模型在风速扰动、短路故障场景下进行仿真验证。风电场等值建模流程如图4 所示。
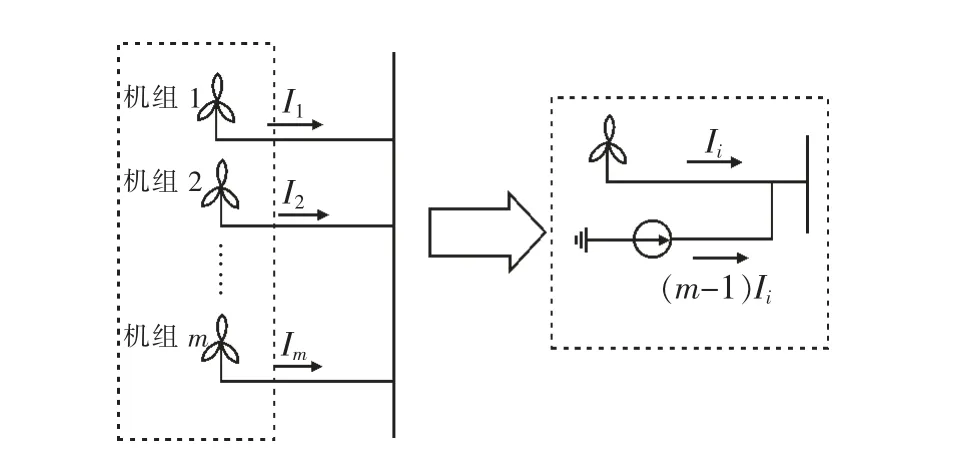
图3 同群机组等值示意

图4 风电场等值建模流程
3 算例分析
3.1 风电场介绍
以由12 台双馈风力发电机组构成的风电场为例进行等值建模研究,图5 为其拓扑结构。风电机组采用PSCAD/EMTDC 自带的双馈风电机模型机组,其特点是数据详实,仿真结果可靠性高。单机容量为5 MW,机端电压690 V,集电系统采用放射式接线,经过35 kV/220 kV 的升压后通过双回线接入电力系统,机组风速设置分别如表2 所示。
3.2 基于SOM K-means 聚类的多机等值法
3.2.1 风电机组运行状态变量矩阵
本节以3.1 节所示双馈型风电场为例,在PSCAD 搭建仿真模型。风场中各台机组的运行变量如表3 所示。为便于比对,风电机组各机组初始运行状态变量均采用标幺值,其容量基值为SB=5 MW,电压基值为UB=35 kV。

图5 风电场接线

表2 机组风速设置

表3 风电机组运行状态变量矩阵p.u.
3.2.2 SOM 聚类
将上述运行状态变量矩阵作为SOM 聚类算法的输入,得出具体的聚类数目K=3 和聚类中心Z(如表4 所示)。如图6 所示,神经网络中共36个神经元,经过运算,SOM 聚类算法自动将风电场分成三群,数字3,4,5 分别表示总机组中的3 台、4 台和5 台机组分别归于一个神经元。中间空白神经元表示3 个聚类中心的距离。
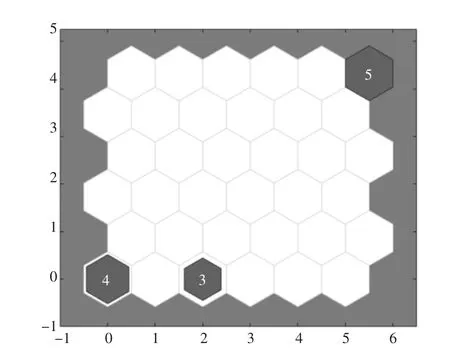
图6 SOM 聚类结果
3.2.3 K-means 聚类
将第一阶段的聚类分群数目K=3 和聚类中心Z 作为K-means 聚类算法的初始输入,得到具体的分群结果,其中:1,2,3 号机组为同一机群;4,5,6,9,10 为同一机群;7,8,11,12 为同一机群。
3.2.4 同群机组等值
从3.2.3 节可知已经合理地将机组分为3 个同群机组,计算各机组指标向量X 与聚类中心Z的距离,可得3 号、7 号、9 号机组是各自群中与聚类中心向量距离最小的机组,因此将这3 个机组分别定义为反映3 个等值机群内平均运行状态的中心机组。将3 号、7 号、9 号机组作为中心机组通过并联受控电流源来表征同群其他机组,如图7 所示。
3.2.5 仿真验证
将上述风电场通过SOM K-means 聚类算法分成3 群,利用聚类中心Z 与指标向量X 的距离选取3 号、7 号、9 号机组作为中心机组进行建模,并且通过并联受控电流源来表征同群其他机组,从而形成由3 台等值机组构成的多机等值模型。基于PSCAD 仿真平台,搭建上述多机等值模型。为验证分群方法的有效性,将多机等值模型与传统的容量加权单机等值模型及详细模型对风场的2 类工作状况进行仿真对比,2 类工况分别为电网侧位置发生三相短路故障以及风速波动下的运行工况。

图7 等值风电场
(1)电网侧三相短路故障
假设16 s 时在PCC(公共连接点)处发生三相短路故障,故障持续0.2 s。 由于故障时间较短,故障期间认为风速不变。如图8 所示,当系统发生三相短路时,多机等值模型在有功功率、无功功率、电流、电压曲线上均能很好地模拟风电场详细模型的动态响应,而单机等值模型在有功功率、无功功率、电流曲线变化上均与风电场的详细模型有较大误差。
(2)风速波动工况
基本风叠加渐变风分量[17-19]来模拟风速扰动。渐变风15 s 时启动,18 s 时结束,峰值为3 m/s,仿真得到PCC 处母线输出特性响应曲线如图9所示。可以看出,当系统发生渐变风扰动时,多机等值模型与单机等值模型在输出特性曲线上均能很好地跟随风电场详细模型的变化,但是多机等值模型的误差比单机等值模型更小。
三相短路故障及风速扰动工况下的单机模型、多机模型及详细模型的响应对比分析表明,对于含相同容量的风电机组的风电场来说,单机模型、多机模型下的响应与详细模型的变化趋势总体一致,但多机模型精度与详细模型接近,更能表征整个风场的运行情况。需要说明的是,使用多机模型的仿真时间约为详细模型的4/5,具有更高的计算效率。
4 结论

图8 三相短路故障下风电场PCC 点处曲线变化

图9 风速扰动下风电场PCC 点处曲线变化
本文提出基于SOM K-means 聚类风电场多机等值建模法,结合SOM 自动聚类的特质和Kmeans 算法快速聚类的特性将风电场用若干风电机组表征,从而实现风电场多机等值建模。得出结论如下:
(1)实际电网中每时每刻都有大量数据的产生,在某种程度上电网可以看做一个大数据网络。本文选取风电场中易于获取的5 种运行状态变量产生的数据进行分析,对实际具有指导价值。
(2)通过经典的大数据处理技术将人工智能算法SOM 与K-means 聚类相结合。可以有效地对风电场进行聚类分群。对人工智能在电网中的建模与仿真有指导作用。
(3)本文提出基于SOM K-means 聚类的风电场多机等值建模方法,其中SOM 产生的聚类中心既可以作为K-means 算法的初始聚类中心加速其快速收敛,也可以利用其与指标向量的距离对中心机组进行优选。
(4)受PSCAD/EMTDC 仿真容量和速度的限制,本文只是搭建了12 台双馈型风电机组进行仿真模拟。未来可以通过搭建更多不同型号的机组进行仿真模拟,来验证模型的实用性。
猜你喜欢
新疆钢铁(2021年1期)2021-10-14 08:45:36
防爆电机(2020年5期)2020-12-14 07:03:50
航天工业管理(2019年11期)2019-04-20 07:05:38
电子制作(2018年17期)2018-09-28 01:56:44
能源(2017年9期)2017-10-18 00:48:22
电测与仪表(2016年14期)2016-04-11 12:33:08
通信电源技术(2016年4期)2016-04-04 02:57:38
电测与仪表(2015年16期)2015-04-12 00:44:24
风能(2015年9期)2015-02-27 10:15:25
风能(2015年7期)2015-02-27 10:15:02
