
基于深度卷积长短时神经网络的视频帧预测
2019-08-27 02:26张德正翁理国夏旻曹辉
计算机应用 2019年6期
关键词:卷积神经网络
张德正 翁理国 夏旻 曹辉

摘 要:针对视频帧预测中难以准确预测空间结构信息细节的问题,通过对卷积长短时记忆(LSTM)神經网络的改进,提出了一种深度卷积长短时神经网络的方法。首先,将输入序列图像输入到两个不同通道的深度卷积LSTM网络组成的编码网络中,由编码网络学习输入序列图像的位置信息变化特征和空间结构信息变化特征;然后,将学习到的变化特征输入到与编码网络通道数对应的解码网络中,由解码网络输出预测的下一张图;最后,将这张图输入回解码网络中,预测接下来的一张图,循环预先设定的次后输出全部的预测图。与卷积LSTM神经网络相比,在Moving-MNIST数据集上的实验中,相同训练步数下所提方法不仅保留了位置信息预测准确的特点,而且空间结构信息细节表征能力更强。同时,将卷积门控循环单元(GRU)神经网络的卷积层加深后,该方法在空间结构信息细节表征上也取得了提升,检验了该方法思想的通用性。
关键词:视频帧预测;卷积神经网络;长短时记忆神经网络;编码预测;卷积门控循环单元
中图分类号: TP183 文献标志码: A
文献标志码:A
Abstract: Concerning the difficulty in accurately predicting the spatial structure information details in video frame prediction, a method of deep convolutional Long Short Term Memory (LSTM) neural network was proposed by the improvement of the convolutional LSTM neural network. Firstly, the input sequence images were input into the coding network composed of two deep convolutional LSTM of different channels, and the position information change features and the spatial structure information change features of the input sequence images were learned by the coding network. Then, the learned change features were input into the decoding network corresponding to the coding network channel, and the next predicted picture was output by the decoding network. Finally, the picture was input back to the decoding network, and the next picture was predicted, and all the predicted pictures were output after the pre-set loop times. In the experiments on Moving-MNIST dataset, compared with the convolutional LSTM neural network, the proposed method preserved the accuracy of position information prediction, and had stronger spatial structure information detail representation ability with the same training steps. With the convolutional layer of the convolutional Gated Recurrent Unit (GRU) deepened, the method improved the details of the spatial structure information, verifying the versatility of the idea of the proposed method.
Key words: video frame prediction; Convolutional Neural Network (CNN); Long and Short-Term Memory (LSTM) neural network; encoding prediction; convolutional Gated Recurrent Unit (GRU)
0 引言
在近些年深度学习快速发展的背景下,多种以前难以很好解决的计算机视觉问题有了解决方案。视频帧预测作为计算机视觉的难点问题,长期以来得不到很好的解决,也难以引起人们的重视,但是随着无人驾驶技术的爆发式发展,对其的需求越来越迫切。原因是:研究人员看重视频帧预测在无人驾驶过程中预测路面行人和车辆移动轨迹的能力。传统的方法停留在车载雷达实时检测车辆前方是否有障碍物,但不能预测t时刻后将与另一个移动物体路径交汇发生碰撞,也就无法作出需要提前减速或者加速的判断。这一能力对于危险情况有提前预防的作用,能够显著增强无人驾驶的安全性能。此外,视频帧预测在夏季短时强降水的预测任务中也可以应用。通过前一段时间雷达回波图预测下一段时间雷达回波图的可能情况,从而判断接下来那些地方可能有强降水发生。视频帧预测也为夏季多发的台风轨迹预测提供了一种方法。由于我国沿海大部分是季风气候,所以夏季东南沿海地区经常受到台风的侵扰,良好地预测台风轨迹,对防灾减灾有重要意义。
目前,已经被很好解决的识别、分类和目标检测等问题的数据集都是静态的图片,即便是同一类别的两张图也不存在时空序列相关性。而视频帧预测问题的前后两帧甚至是间隔数帧依旧存在着很强的时空序列相关性。对于这类时空序列问题,近年来火热的基于卷积神经网络(Convolutional Neural Network, CNN)的AlexNet[1]、VGG(Visual Geometry Group)[2]、GoogLeNet[3]等算法都无法解决。主要原因是以上三种算法代表的卷积神经网络的优点是对结构表征能力很强,缺点是局限于静态图,无法建模动态图的时空序列问题。如何建模时空序列问题,是一个比较基础也比较重要的任务。起初研究人员注意力主要集中在人类动作预测方向,使用的方法大多基于统计学习和传统的机器学习。Ryoo[4]把动作预测问题概率化,使用时空特征积分直方图来建模特征分布与时间的变化关系。Zhu等[5]应用条件随机场提出了感知语法事件解析、推断事件目标和预测可信动作的算法。Vondrick等[6]利用一种深度回歸网络的方法来学习视频表征,结合动作识别模型,能够很好地根据静态图像来推测未来动作。除此之外,研究人员还进行了物体轨迹预测方向的研究。Kooij等[7]基于贝叶斯算法提出了动态贝叶斯网络,应用于行人路径预测。Walker等[8]的光流预测模型对静态图中的所有像素点进行光流标记,可以预测每一个像素的运动。Mottaghi等[9]使用两个CNN和一个循环神经网络(Recurrent Neural Network, RNN)来建模物体移动动态,其结果表明可以从单个图像中预测出物体的长期运动作为外力的反映。以上的运动预测模型多是从建模移动物体的运动轨迹出发,能较好地预测物体的瞬时运动轨迹,但具有两个缺点:一是不能预测多帧后物体准确位置;二是不能表征多帧后物体的结构信息。
针对这两个难解决的问题,本文在卷积长短时神经网络(Long and Short-Term Memory neural network, LSTM) [10]基础上提出了深度卷积长短时神经网络模型,基于Moving-MNIST数据集的实验表明,在多帧后的物体位置预测和物体结构信息保留两方面取得了更优的效果。
1 卷积LSTM
1.1 循环神经网络
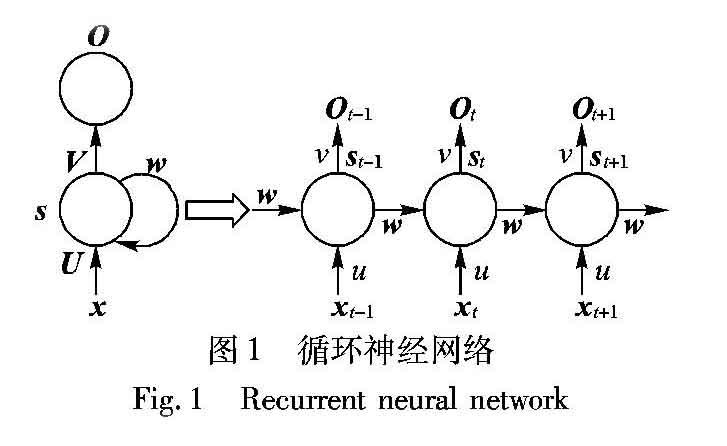
循环神经网络[11]的提出主要是为了解决自然语言处理领域的词语长期依赖问题。该问题将一条语句甚至是段落转化成词向量,而语句中不同位置上的词语存在高度相关性,体现在词向量上就是不同元素间存在相关性,这就是序列问题。循环神经网络结构如图1所示。在左边部分中,x是神经网络的输入;U是输入层到隐藏层之间的权重矩阵;w是记忆单元到隐藏层之间的权重矩阵;V是隐藏层到输出层之间的权重矩阵;s是隐藏层的输出,同时也是要保存到记忆单元中,并与下一时刻的x一起作为输入;O是神经网络的输出。图的右边是展开结构。循环神经网络接受多个独立的输入,并且最终输出多个结果。将循环神经网络的结构与一般的全连接神经网络比较,会发现循环神经网络只是多了一个记忆单元s,而这个记忆单元就是循环神经网络的关键所在。t时刻的神经元接受t时刻的输入xt,并且在给出输出之前参考上一时刻的记忆单元st-1,同样的t时刻的神经元也会留下该时刻的记忆单元st,用于下一个时刻的输出参考。实际的效果就是将不同时刻状态联系到一起,建模了时间的相关性。
在后来的神经网络发展中,为了解决一些实际的问题,例如:文本情感分析[12]、语音识别等[13],研究人员提出了基于原始循环神经网络的变体,例如为了解决多输入单分类的问题提出多输入单输出的循环神经网络。原始的循环神经网络还要求输入与输出长度对应,但在机器翻译中源语言与目标语言的句子往往并没有相同的长度,这时可采用输入与输出不等长(N vs M) 模型,这种结构又称为“编码解码”(Encoder-Decoder) 模型,也称序列到序列(Seq2Seq)模型[14],是从自编码器发展而来的。在诸多变种中,长短时神经网络(LSTM)模型由于能更好地处理长期依赖和训练时的梯度爆炸问题[15],所以经常被使用。
1.2 卷积LSTM
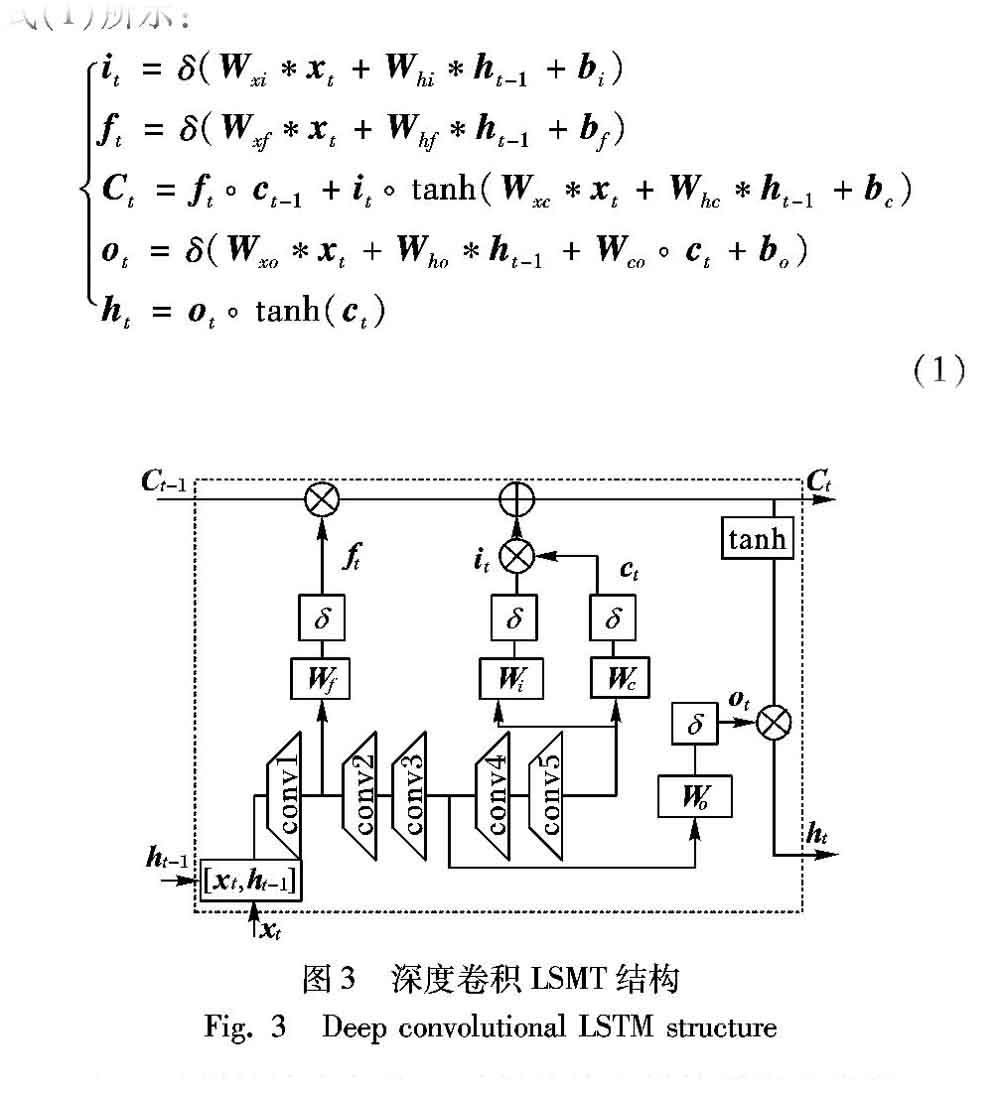
卷积LSTM的提出是为了解决临近降水预测问题,该问题的数据是雷达回波序列图,有很强的时空相关特性。Shi等[16]在结合了LSTM的序列处理能力和CNN的空间特征表达能力后,提出了能够解决时空序列预测问题的卷积LSTM模型。与各种循环神经网络不同的是:通过对输入序列图像使用卷积操作获取图像特征,在循环神经网络应用于翻译等任务时获取的都是一维的词向量输入;而这里获取的是二维的图像输入,也可以根据任务不同输入三通道的彩色图像,这时就变成了三维输入。在视频帧预测任务中,将单通道的64×64的数字序列图像作为输入。如图2所示,卷积LSTM模型与LSTM模型具有同样的三个门控制单元和一个隐藏层,分别是:输入门it、遗忘门ft、输出门ot和隐藏层ht。最大的不同是在当前时刻的输入与隐层结合后进行了单层卷积计算,这个不同点是提取空间结构信息的关键。
2 深度卷积LSTM
在深层卷积可以提取更抽象特征的思想启发下,本文提出了深度卷积LSTM模型,卷积层的具体分布上不是简单地加深而是参考了GoogLeNet中让网络变宽的方法[17-18],目的是解决普通卷积LSTM在预测多帧时结构信息模糊的问题。具体操作是将输入与隐层结合后的单层卷积加深,并且将不同层的卷积结果传递给不同的门控单元,卷积层之间用relu函数激活,结构如图3所示。
4 仿真实验及分析
4.1 对比实验
为了进一步对深度卷积LSTM模型有直观了解,在Moving-MNIST数据集上比较改进的深度卷积LSTM网络与普通卷积LSTM网络。在测试了添加不同卷积层后,得到如下结论:
1)深度卷積LSTM在处理时空相关方面优于卷积LSTM。
2)深度卷积LSTM对图片结构信息表征能力更强,细节信息可以传递到更深层预测。
对比用的两个网络都借用tensorflow框架,使用python语言编写,运行在单块NVIDIA TITAN X显卡上。具体操作:将前10帧图像作为输入,通过使用反向传播和最小化均方差损失来训练模型,学习率设置为10E-3。首先,使用普通卷积LSMT算法在训练后预测数字9和8的运动情况,结果如图8(a)所示:第一行是输入的前10帧图像,第二行是真实的后10帧图像,第三行是预测出的后10帧图像;再与原算法对比使用改进的深度卷积LSTM网络预测构造比较复杂的9和8两个数字的运动图,结果如图8(b)所示:第一行是输入的前10帧图像,第二行是真实的后10帧图像,第三行是预测出的后10帧图像。
通过观察预测的结果图8可以发现,单层卷积LSTM网络在预测时的表现很差,只有前边两帧图像还能分辨出是数字9和8,到最后一帧图片结构信息完全丢失只剩模糊的像素点;反观深度卷积LSMT网络的预测结果,前边的七帧都能较好地保持图像的结构信息,能分辨出是数字9和8,最后一帧的结构信息也很模糊但还是有一些轮廓信息。也可以发现,虽然原算法预测出的图像结构信息较差,但在位置信息预测上比较准确,这个优点在改进的深度卷积LSTM上依然得到了保留,对于位置的预测还是一样地准确。
4.2 算法通用性实验
进一步讨论加深卷积层的算法思想是否可以拓展到其他相关的序列预测算法上,实现性能的提升。为此,选择同样是由循环神经网络演变来的卷积门控循环单元(Gated Recurrent Unit, GRU)算法进行验证。GRU是新一代的循环神经网络,结构上去掉了细胞状态,使用隐藏状态来进行信息的传递,整体和LSTM非常相似。改进思路与深度卷积LSTM一样,将卷积GRU的一层卷积加深为五层,卷积层之间用如图10所示的relu激活函数,有三点好处:1)防止梯度爆炸。2)计算速度快,只需要判断是否大于0。3)收敛速度大于sigmoid和tanh。
4.3 任务通用性实验
为了测试算法在不同类型图像上的表现,选取了阿里巴巴天池大数据比赛上的部分珠三角地区降水雷达回波数据集。结合深度卷积LSMT网络的要求,对数据集中的61张降水回波图按顺序间隔两张挑出一张,做出了输入10张、输出10张的序列图。经过训练后测试结果如图13所示。从预测结果图13来看,深度卷积LSMT对深黑色的降水区域预测更准确,重合更大,尤其从前边的三张预测图对比看出:原来的卷积LSMT网络预测图的左下角黑色降水区域偏差较大。原因还是因为卷积LSMT的单层卷积在训练时对图像的深层特征学习不够,相反深度卷积LSMT的五层卷积更能挖掘到图像变化的深层特征。
同样地在测试集上对比深度卷积LSMT网络和卷积LSMT网络的结构相似度。深度卷积LSTM网络在100个序列的测试集上取得了0.68的平均结构相似度,卷积LSMT网络的结构相似度为0.62,结构相似度提升了约9.7%。对比两个数据集结果发现,不论是否改进,算法整体的结构相似度都比Moving-MNIST数据集表现好;区别在于雷达回波数据集中的图像中雨云的结构不是固定的,而Moving-MNIST数据集中的移动数字结构是固定的,所以固定的结构预测难度更大。此外,在Moving-MNIST数据集上深度卷积LSMT网络在结构相似度上提升了14.58%,而雷达回波图上才提升了9.7%。这和雨云的运动高度相关,数字图仅仅是有方向性的运动,而雨云不仅运动还可能降水消失,具有突变性,所以提升难度更大。综合表现来看,深度卷积LSMT对图像的空间结构信息预测更准确,但在图片信息出现突变的情况中提升效果会下降。
5 结语
通过对卷积LSTM网络的加深和不同卷积层与不同门控单元的结合,深度卷积LSTM模型成功增强了模型在时空序列预测问题中的空间结构信息表征能力,在图像细节的表达能力上明显优于原模型;在位置预测上,依然继承了卷积LSTM算法的精准度;并且加深的算法思想在同样可以作序列预测的卷积GRU模型上验证了,加深卷积层来提升空间结构信息表征能力的想法是有效的、可行的。但是从序列预测的结果图来看,经过深度卷积加深的网络依然很难将清晰的结构信息保留到7帧之后。分析原因,首先最小化均方差作为损失函数,会使得在反向传播后修正像素点值时过分追求均值最小,将误差均值化从而导致了模糊;其次,序列预测的过程中是利用前一张的预测结果预测下一张,误差会累计。这两方面还有很大的优化空间,未来将作进一步的研究。
参考文献 (References)
[1] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]// Proceedings of the 25th International Conference on Neural Information Processing Systems. North Miami Beach, FL: Curran Associates Inc., 2012: 1097-1105.
[2] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. [2018-10-15]. https://arxiv.org/pdf/1409.1556.pdf.
[3] SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ:IEEE, 2015: 1-9.
[4] RYOO M S. Human activity prediction: early recognition of ongoing activities from streaming videos [C]// Proceedings of the 2011 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2011: 1036-1043.
[5] ZHU S, JIA Y, PEI M. Parsing video events with goal inference and intent prediction [C]// Proceedings of the 2011 International Conference on Computer Vision. Piscataway, NJ: IEEE, 2011: 487-494.
[6] VONDRICK C, PIRSIAVASH H, TORRALBA A. Anticipating visual representations from unlabeled video [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 98-106.
[7] KOOIJ J F P, SCHNEIDER N, FLOHR F,et al. Context-based pedestrian path prediction [C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8694. Berlin: Springer, 2014: 618-633.
[8] WALKER J, GUPTA A, HEBERT M. Dense optical flow prediction from a static image [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2015: 2443-2451.
[9] MOTTAGHI R, RASTEGARI M, GUPTA A, et al. “What happens if…” learning to predict the effect of forces in images [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9908. Berlin: Springer, 2016: 269-285.
[10] HOCHREITER S, SCHMIDHUBER J. Long short-term memory [J]. Neural Computation, 1997, 9(8): 1735-1780.
[11] ELMAN J L. Distributed representations, simple recurrent net-works, and grammatical structure [J]. Machine Learning, 1991, 7(2/3): 195-225.
[12] 李洋,董紅斌.基于CNN和BiLSTM网络特征融合的文本情感分析[J].计算机应用,2018,38(11):3075-3080.(LI Y, DONG H B. Text sentiment analysis based on feature fusion of convolution neural network and bidirectional long short-term memory network [J]. Journal of Computer Applications, 2018, 38(11): 3075-3080.)
[13] 姚煜,RYAD C.基于双向长短时记忆联结时序分类和加权有限状态转换器的端到端中文语音识别系统[J].计算机应用,2018,38(9):2495-2499.(YAO W, RYAD C. End-to-end Chinese speech recognition system based on bidirectional long-term memory-timed timing classification and weighted finite state converter [J]. Journal of Computer Applications, 2018, 38(9): 2495-2499.)
[14] SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks [C]// Proceedings of the 2014 Neural Information Processing Systems Conference. Cambridge, MA: MIT Press, 2014: 3104-3112.
[15] BENGIO Y, SIMARD P, FRASCONI P. Learning long-term dependencies with gradient descent is difficult [J]. IEEE Transactions on Neural Networks, 1994, 5(2): 157-166.
[16] SHI X J, CHEN Z R, WANG H, et al. Convolutional LSTM network: a machine learning approach for precipitation nowcasting [C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2015: 802-810.
[17] MOLLAHOSSEINI A, CHAN D, MAHOOR M H. Going deeper in facial expression recognition using deep neural networks [C]// Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision. Piscataway, NJ: IEEE, 2016: 1-10.
[18] IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [C]// Proceedings of the 32nd International Conference on International Conference on Machine Learning. Cambridge, MA: MIT Press, 2015: 448-486.
[19] LESHNO M, LIN V Y, PINKUS A, et al. Original contribution: multilayer feedforward networks with a nonpolynomial activation function can approximate any function [J]. Neural Networks, 1991, 6(6): 861-867.
猜你喜欢
电子技术与软件工程(2017年3期)2017-03-22
电脑知识与技术(2016年33期)2017-03-21
科技创新与应用(2017年5期)2017-03-16
电脑知识与技术(2016年30期)2017-03-06
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
软件(2016年5期)2016-08-30
电脑知识与技术(2016年10期)2016-06-16
