
基于隐马尔科夫模型的深度视频哺乳母猪高危动作识别
2019-08-23 02:24:28薛月菊杨晓帆陈畅新甘海明李诗梅
农业工程学报 2019年13期
薛月菊,杨晓帆,郑 婵,陈畅新,甘海明,李诗梅
基于隐马尔科夫模型的深度视频哺乳母猪高危动作识别
薛月菊1,杨晓帆1,郑 婵2,陈畅新1,甘海明1,李诗梅1
(1. 华南农业大学电子工程学院,广州 510642;2. 华南农业大学数学与信息学院,广州 510642)
哺乳母猪的高危动作和仔猪存活率有密切关系,能直接体现其母性行为能力,而这些高危动作又与其姿态转换的频率、持续时间等密切相关。针对猪舍环境下,环境光线变化、母猪与仔猪黏连、猪体形变等给哺乳母猪姿态转换识别带来的困难。该文以梅花母猪为研究对象,以Kinect2.0采集的深度视频图像为数据源,提出基于Faster R-CNN和隐马尔科夫模型的哺乳母猪姿态转换识别算法,通过Faster R-CNN产生候选区域,并采用维特比算法构建定位管道;利用Otsu分割和形态学处理提取疑似转换片段中母猪躯干部、尾部和身体上下两侧的高度序列,由隐马尔科夫模型识别姿态转换。结果表明,对姿态转换片段识别的精度为93.67%、召回率为87.84%。研究结果可为全天候母猪行为自动识别提供技术参考。
图像处理;算法;模型;高危动作;哺乳母猪;Faster R-CNN;隐马尔科夫模型;定位管道
0 引 言
在养猪场饲养环境下,母猪高危动作主要体现在姿态转换次数、频率和持续时间,这也是其母性行为优劣的重要体现,与仔猪成活率密切相关[1]。通过人工眼睛直接观察或视频监控观察母猪姿态转换具有强主观性,且耗时费力[2]。母猪姿态转换行为自动识别可为其母性行为特质和规律研究提供基础信息,对防止仔猪踩压死亡,提高仔猪生存率,降低猪场管理的人工成本意义重大[3-4]。
传感器技术已被用于监测母猪姿态,如Thompson等[4]通过传感器获取加速度数据,用支持向量机识别母猪姿态和姿态转换,姿态转换识别的精度和召回率分别为 82.60%和76.10%;闫丽等[5]通过在母猪颈部或腿部佩戴MPU6050模块采集母猪行为数据,对高危动作识别的准确率为81.7%。为克服母猪应激、传感器脱落或损坏等影响,计算机视觉开始用于获取母猪姿态信息。如Lao等[2]用深度图像对母猪的卧、坐、跪、站立和饮食等动作进行识别,准确率分别为99.9%、96.4%、78.1%、99.2%和92.7%;Zheng等[6]和薛月菊等[7]用目标检测器Faster R-CNN,识别了深度图像中母猪的站立、坐、俯卧、腹卧和侧卧姿态,对5类姿态的平均精度均值分别为87.1%和93.25%。但文献[2,6,7]的工作仅限于基于静态图像的姿态识别。
而哺乳母猪姿态转换行为是从一个姿态变换到另一个姿态的行为,涉及到转换的前后姿态及转换过程。由于未充分利用行为的时间序列信息,已有的静态图像目标检测算法难以直接用于行为识别[8]。需从视频帧序列中自动分析正在进行的姿态转换行为。但因视频的时域和空域都有极强的相关性,伴有大量时空信息和冗余信息,给行为识别带来了挑战[9-10]。
为实现行为识别,研究者采用不同方法提取视频集中的时空信息并对其进行分析。如Wang等[11]提出了基于时空密集轨迹的行为识别方法,在HMDB51数据集上的识别精度达到57.2%;Peng等[12]用堆叠的2个Fisher向量编码层对文[11]密集轨迹进行编码,聚合形成视频的描述特征,以提高行为识别精度,与文[11]相比在HMDB51数据集上的识别精度提高9.59%。但上述手工设计特征的方法过于依赖于专家经验,模型泛化能力不强,难以应用于真实的实时场景中[13]。最近,卷积神经网络(convolutionalneural networks,CNN)被引入至视频行为识别领域[14-15]中。对于场景中存在多个运动目标的情况,为克服场景中其他运动对象对所关注对象行为识别的影响,研究者基于CNN在视频帧上进行动作区域检测,并进行跟踪和行为分析[16-18]。如Gkioxari等[16]和Saha等[17]分别通过双通道CNN网络提取每个候选区域的表观特征和运动特征,再计算候选区域的动作分数,最后将候选区域在时间维度上利用优化算法进行连接形成动作管道,行为识别效果较好。然而,文[16-17]计算复杂,仅适合短视频(小于200帧)的动作分类,难以解决长段视频的母猪姿态转换行为识别。
为克服自由栏场景下,母猪姿态转换行为过程中姿态的不确定性和身体的形变,及仔猪对哺乳母猪姿态转化行为识别的影响,借鉴文献[16-18]动作管道生成的思路,利用目标检测-跟踪-行为分析的方法研究母猪姿态转换行为识别。以深度视频图像为母猪姿态转换识别的数据源,提出以Faster R-CNN[19]输出的姿态概率形成疑似转换片段定位管道,提取定位管道中的母猪高度时间序列特征,然后输入隐马尔科夫模型(hidden Markov model,HMM)[20],实现母猪姿态转换高危动作识别,试验验证本文方法的有效性。
1 材料与方法
1.1 试验数据采集
本文试验数据均采集于广东佛山市三水区乐家庄养殖场,于2016年5月30日、11月29~30日;2017年4月19~20日、4月25日;及2018年9月5~6日共进行5次采集,见表1。其中试验数据B1和B4以尽可能涵盖不同哺乳母猪尺寸为目的,每间猪栏采集时间长度为30~50 min不等。试验数据B2、B3和B5以尽可能涵盖母猪全天活动为目的,每次仅针对1栏或2栏猪进行采集。每间猪栏长3.8 m×宽2.0 m,均包含一头哺乳母猪及6~10只日龄为2~21 d的仔猪。通过在猪栏顶部架设Kinect2.0摄像头垂直向下以5帧/s的速率采集RGB-D视频图像。为拍摄猪栏整个区域,摄像机架设的高度为200~230 cm。本文利用512×424像素的深度视频图像,研究母猪姿态转换行为自动识别。

表1 试验数据集
1.2 训练集、验证集和测试集准备
训练集、验证集和测试集应保证数据多样性,涵盖不同母猪尺寸、姿态和转换行为。本文选择表1中B1、B4和B5的部分数据作为Faster R-CNN和HMM训练集和验证集,B2和B3作为本文算法的测试集,用于算法的性能评价。
对于Faster R-CNN的训练集和验证集,为避免时序相关性等问题,从B1、B4和B5每个母猪姿态未发生变化的视频段中随机抽取至多5张深度图像,并在动物行为专家指导下人工标注母猪边界框和姿态类别,分别得到站立2 941、坐2 916、趴卧2 844和侧卧3 085张。再从每类姿态中各随机抽取1 500张,共6 000张,分别做顺时针90°、180°和270°旋转以及水平、垂直镜像扩增,最后形成36 000张图像作为训练集,剩余站立1 441、坐1 416、趴卧1 344和侧卧1 585张作为验证集。
对于HMM的训练集和验证集,在B1、B4和B5中随机截取发生与未发生姿态转换的图像序列各120段,共240段。根据姿态转换持续时间的统计结果,每段图像序列长度为60~120帧不等。随机抽取其中120段作为训练集,其余作为验证集。
选取试验数据B2和B3作为测试样本。B2从连续时间长度29.7 h的视频中人工选取了26个片段,每段长度30~47 min,在切分视频前剔除了部分母猪长时间保持不动的视频片段。B3为连续29 h的视频,为适应图像处理服务器计算性能和内存的限制,简单地将29 h的视频人工切分成34个长视频,每段长度36~50 min。人工切分并未涉及母猪姿态转换的起始和结束,仅为适应服务器内存的限制,并在切分时避免切分点落在姿态转换的过程中。而母猪姿态转换的起始和结束以及姿态转换的类别,是通过算法从该部分长视频识别出来。在各长视频分析之后,将分析结果按时间顺序拼接即可获得1d以上(29 h)的识别结果。
由于B2和B3视频数据共包含380 073张深度视频帧,人工标注每张视频帧中母猪的边界框工作量过大,本文从每个母猪姿态未发生变化的视频段中随机抽取至多5张深度图像进行边界框标注,分别得到站立967、坐940、趴卧972和侧卧984张,作为Faster R-CNN测试集。并人工标注了视频中母猪各类姿态及姿态转换的起始帧和结束帧,姿态转换共156次,用于与本文算法自动识别结果对比,评价本文算法的识别精度。
1.3 母猪姿态转换类别及定义
母猪自高向低的俯身动作对仔猪威胁较大,被称为高危动作[21]。Weary等[22]通过观察统计发现,仔猪被挤压主要发生于以下三类姿态转换:1)母猪从站立转至卧,易造成仔猪在母猪腹部被挤压;2)母猪从坐转换至卧,其中从坐转换至侧卧对仔猪威胁较大;3)母猪在趴卧与侧卧间转换,该类转换对仔猪威胁较小。而母猪的身体上升动作极少发生挤压仔猪的情况。按照对仔猪的威胁程度和发生频率,本文将母猪的姿态转换分为4类,见表2。

表2 母猪4类姿态转换
注:DM1为下行转换1,DM2为下行转换2,AM为上行转换,RL为翻身。下同。
Note: DM1 represents descending movements 1, DM2 represents descending movements 2, AM represents ascending movements, and RL represents rolling. The same below.
2 母猪姿态转换识别
由于母猪姿态转换中身体的形变和姿态的多样性,易导致Faster R-CNN目标定位和姿态识别错误。因此,本文提出母猪定位管道算法(详见2.3节)以修正目标定位错误,将疑似姿态转换视频片段的定位管道中母猪身体各部分高度序列输入HMM,来进一步判断是否发生姿态转换。
本文姿态转换识别方法分为5个步骤(见图1):第一步,深度图像质量增强。第二步,用改进Faster R-CNN[7]进行目标定位和姿态分类,选取每帧中概率最大的姿态,形成姿态序列,用于第三步疑似转换片段的检测和第五步单一姿态片段的分类;同时保留概率最大的前5个检测框作为候选区域,用于第三步的管道构建。第三步,针对姿态序列中存在分类错误,根据时序相关性,采用时间域中值滤波进行修正,再检测视频中的疑似转换片段,通过维特比算法构建各疑似转换片段的最大分数定位管道。第四步,在定位管道中,用最大类间方差法(Otsu)[23]分割各帧的母猪,计算各帧母猪躯干部、尾部和身体两侧的高度,形成高度序列特征。第五步,将每个定位管道的高度序列输入HMM模型,将疑似转换片段分为姿态转换与未转换片段;根据转换前后单一姿态片段的类别对姿态转换片段进行分类,最终实现姿态转换识别。
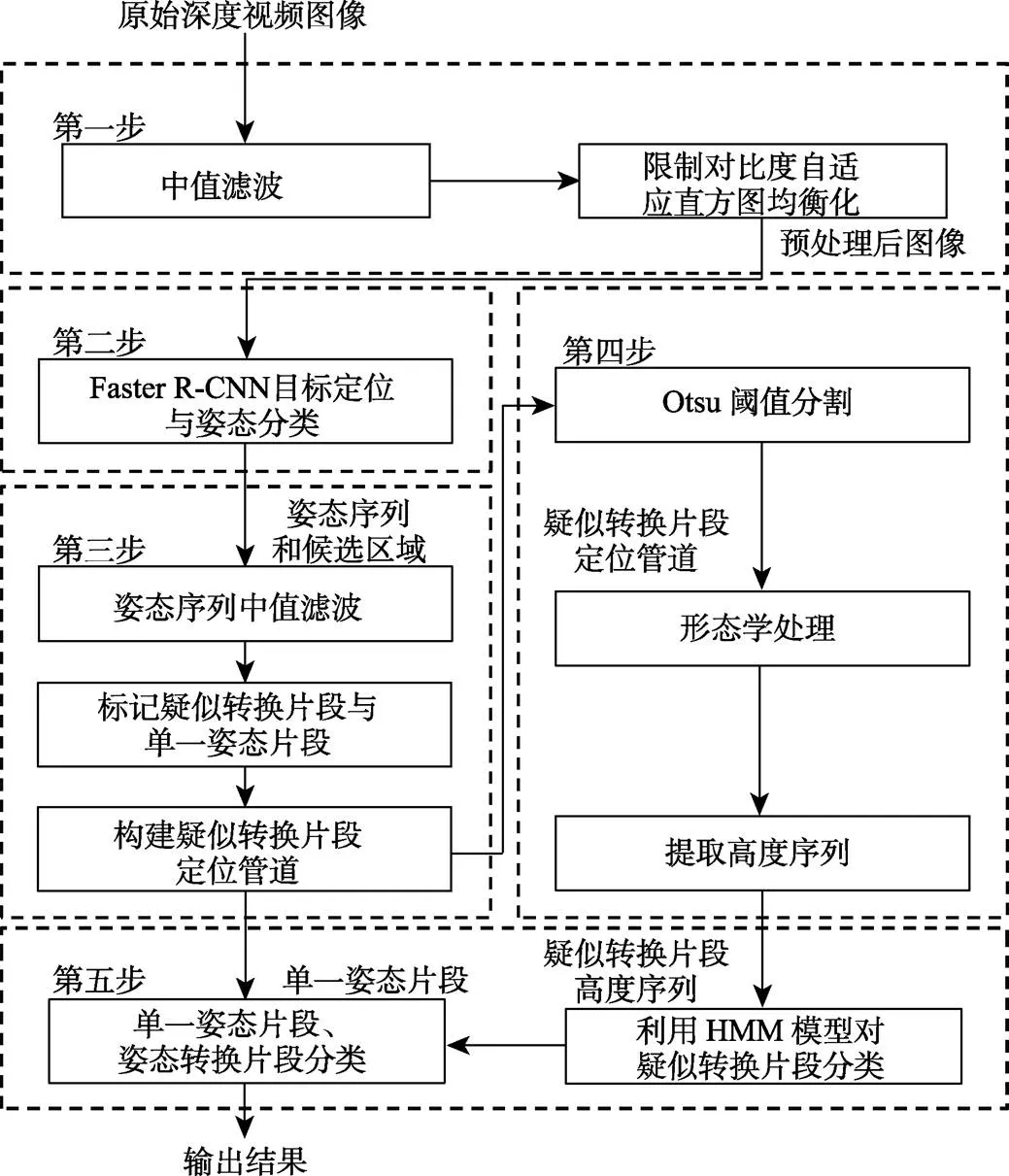
图1 母猪姿态转换识别流程图
2.1 深度图像质量增强
猪舍环境下,猪舍内部粉尘阻挡造成Kinect2.0的红外光无法投射至拍摄对象,且未封闭猪舍四周受阳光直射导致该部分区域反射回的红外光捕获困难,因此,采集到的深度图像存在大量噪声。本文采用5×5中值滤波器进行去噪,通过限制对比度自适应直方图均衡化提高图像对比度。
2.2 母猪深度图像的目标定位和姿态分类
采用改进Faster R-CNN[7]在视频帧上进行母猪定位和姿态分类,该网络主要包含卷积层、最大池化层、正则化层、残差结构和全连接层。模型在共享卷积层中引入残差结构,提升模型收敛速度和精度[24];并引入Center Loss监督信号,以增大不同姿态类别间特征的距离,减少类内差异[25]。
模型的训练基于Caffe框架[26],用随机梯度下降法和反向传播算法微调参数,最大迭代次数为9×104,其中前6×104次学习率为10-3,后3×104次学习率为10-4,冲量为0.9,权值的衰减系数为5×10-4,mini-batch为256,对网络层采用均值为0,标准差为0.1的高斯分布初始化。根据深度图像中母猪的尺寸,将锚点面积设置为962、1282和1602像素,长宽比设置为1:1、1:3和3:1。当检测框与人工标注框交并比超过阈值0.7并且类别一致,则认为检测结果正确。
测试时,将B2和B3的深度视频图像逐帧输入至该模型,选取每帧中概率最大的姿态形成姿态序列,用于第三步疑似转换片段的检测和第五步单一姿态片段的分类,同时保留每帧概率最大的前5个检测框作为候选区域,用于第三步定位管道构建。
2.3 疑似转换片段检测及定位管道构建
由于母猪姿态转换行为中姿态连续地变化,其姿态不确定,随着时间推移可能一定程度上与站、坐、侧卧或趴卧其中一种相似,也可能相异于任何姿态。如图2左右虚线之间部分为母猪从趴卧到站立的转换。在未转换前,趴卧姿态概率最高;转换过程中,4类姿态的概率均较低且最大概率变化频繁,导致Faster R-CNN输出姿态类别不确定和频繁变化;姿态转换结束后,站立姿态概率最高。

图2 母猪从趴卧转站立的前后姿态概率图
因此,在利用时序相关性以长度为5帧的中值滤波进行姿态类别的修正之后,根据姿态转换频繁程度检测疑似姿态转换片段。采用长度为20帧、步长为1帧的滑动窗口计算每个窗口内姿态序列的变化次数。通过统计姿态转换片段中姿态变化次数,最终截取变化次数大于3的片段作为疑似转换片段,其余片段作为单一姿态片段。在疑似转换片段中,部分片段是由Faster R-CNN姿态识别错误而被误认为姿态转换,实际上母猪未发生转换,将该类片段称为未转换片段。因此,需对疑似转换片段进一步判断,分为姿态转换片段和未转换片段两类(详见2.5节)。为降低Faster R-CNN目标定位错误对姿态转换判断造成的影响,本文参考文献[16]的动作管道思想,提出母猪定位管道建立方法,对第二步获得的各帧中最大概率的前5个候选区域,计算相邻帧候选区域的连接分数:
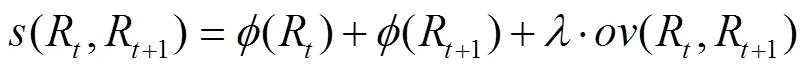

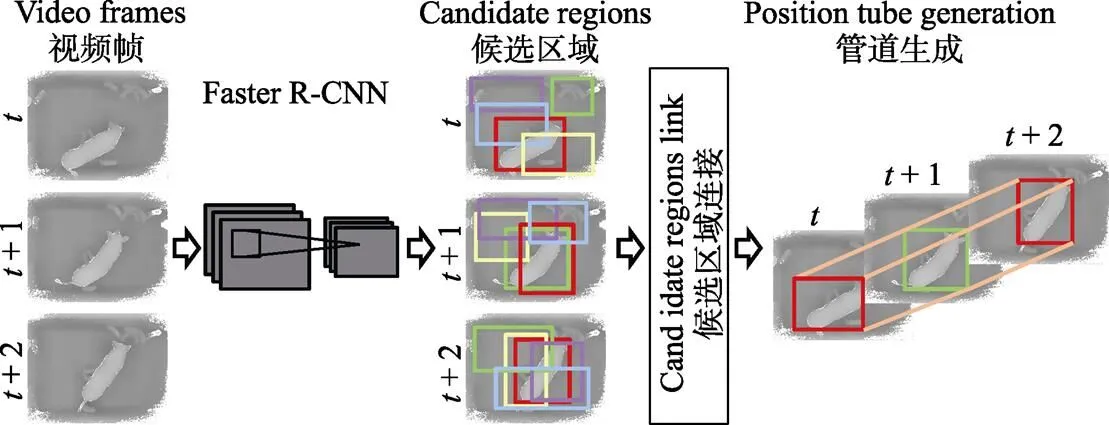
注:t表示疑似转换片段中的第t帧。
2.4 疑似转换片段的高度序列计算
母猪发生姿态转换时,由于身体的变形和姿态的多样性难以利用母猪身体形状信息,而身体高度则会发生相应变化。因此,可用身体不同部位的高度时间序列对疑似转换片段进行分类。考虑到母猪在站立和坐姿下,头部高度及朝向经常发生变化,本文利用母猪身体部分高度,而不用头部高度。
对优化后的定位管道,逐帧在检测框中采用Otsu和形态学处理将母猪从背景中分割出来。由于在自由栏猪舍中,母猪大部分时间靠墙活动,通过Otsu分割出来的母猪常与墙体和仔猪相连,本文采用霍夫变换检测Otsu分割结果中的墙壁并将其剔除,再进行闭操作,断开母猪与仔猪黏连,最后将分割结果映射至原始深度图像。
不同的母猪姿态猪体各部位的高度值也不同,为提取该高度特征,对猪体划分区域,见图4。考虑到图像中猪体角度不同,在划分前统一对目标区域进行双三次插值法旋转。用圆弧度判断母猪尾部和头部,再连接头尾2点形成直线,于直线1/4和3/4点处分别作垂线,将母猪猪体分为头部(区域1和4)、躯干部(区域2和5)、尾部(区域3和6)及身体上侧(区域2和3)和下侧(区域5和6)。计算母猪躯干部、尾部和身体上下两侧各部分的平均高度,合并各帧结果,形成疑似转换片段的高度序列,即属性个数为4、长度为60~120不等的高度时间序列特征。对每段高度序列作减均值预处理。

图4 母猪区域划分示意图
2.5 疑似转换片段再分类
将高度时间序列特征输入连续型HMM[28]进行分类,并选用混合高斯概率密度函数描述每个隐状态的分布。一个HMM模型可记为:

式中为隐状态数,为高斯混合模型中核函数的个数,为隐状态转移概率矩阵,为概率分布函数矢量,为初始隐状态概率矢量。

对HMM设置核函数个数和隐状态数均为2,最大迭代次数为500,训练最小误差为10-6。重复10次试验,保留准确率最高的模型。测试时,将采集的B2和B3数据中所有疑似转换片段高度序列输入至HMM进行分类,其中未转换片段与单一姿态片段合并,形成分段结果。
考虑到未转换片段伴有多帧姿态误分类,对于合并后的单一姿态片段,用片段中姿态序列占比最大的类别作为单一姿态的类别。再根据转换前后单一姿态片段的类别对姿态转换片段分类,形成最终结果。
2.6 评价标准
本文采用分类混淆矩阵[29]评价Faster R-CNN模型。用准确率(accuracy)评价HMM模型:

采用成功定位率(success plot)[30]评价定位管道提取结果,反映目标跟踪的准确性。用召回率(recall)和精度(precision)[31]评价姿态转换片段识别结果,以综合反映分段点定位和片段分类的准确性。各指标定义:


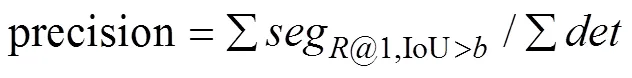
3 结果与分析
算法开发环境具体如下:计算机处理器为Intel(R) Xeon(R) E3-1246 v3,主频3.50 GHz,内存32G,GPU为NVIDIA GTX980Ti,操作系统为Windows7-64bit,算法开发平台为Matlab 2014b。
在测试集上,按算法流程分别计算Faster R-CNN模型的分类混淆矩阵、管道的成功定位率及HMM模型准确率;最后,整体评价本算法对姿态转换识别的精度和召回率。
3.1 Faster R-CNN模型评价
表3为Faster R-CNN模型的分类混淆矩阵(IoU>0.7,测试集见1.2节)。四类姿态的平均精度和平均召回率分别为98.49%和92.35%,检测速度为0.058 s/帧。
表3表明,Faster R-CNN模型识别精度较高,同时检测时间低于采样间隔(0.2 s),实时性较强,对于身体花色与尺寸不同的母猪,该模型具有较好的泛化能力。
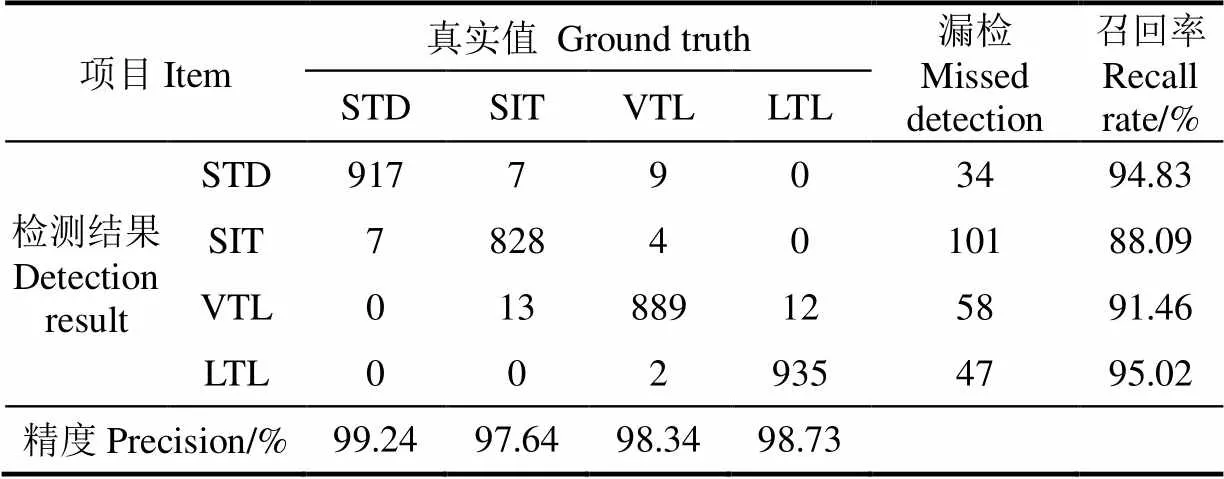
表3 Faster R-CNN模型在测试集上的分类混淆矩阵
注:STD为站立,SIT为坐立,VTL为趴卧,LTL为侧卧。下同。
Note: STD represents standing, SIT represents sitting, VTL representsventral lying, and LTL representslateral lying. The same below.
3.2 定位管道结果评价
图5表明,优化后的定位管道对猪舍环境下的母猪有良好的跟踪效果,有效克服了热灯光线、母猪身体形变等对跟踪的影响,说明本文算法有较高的鲁棒性。

图5 不同交并比阈值下的成功定位率
3.3 HMM模型评价
通过本文算法的前3个步骤,在测试集中共检测出433个疑似转换片段,经人工判别其中158个为姿态转换片段,剩余275个为未转换片段。用HMM模型判断转换和未转换片段,真正类、真负类的数量分别为153和266,准确率为96.77%。
HMM模型能有效地对疑似转换片段进行分类。对实际发生姿态转换,而算法错分为未转换的片段,该类情况主要发生在翻身及坐与趴卧间转换,原因在于转换前后母猪身体运动幅度小,高度变化不明显。对实际未发生转换,而算法错分为姿态转换的片段,主要由于深度图像噪声影响导致母猪身体部分缺失,各部位高度计算错误。
3.4 本文算法整体结果评价
将B2和B3视频数据输入本文算法,可得到姿态转换识别的结果。表4为4类姿态转换的分类混淆矩阵(=0.5),测试集中母猪姿态转换共156次,检测出的139个姿态转换片段与人工分段结果类别一致,平均精度为93.67%,召回率为87.84%。

表4 测试集姿态转换分类混淆矩阵
由于大部分时段母猪姿态转换频率较低,为突出本文算法效果,图6仅从测试集试验结果中截取转换次数较多的视频段进行展示,每段截取长度为15 min。其中,粉红色的部分为姿态转换片段,其他颜色分别表示不同的姿态。可以看出,与基于Faster R-CNN单帧检测相比,本文算法分段效果更好。图6a中,Faster R-CNN在识别母猪站立、坐的过程中伴有多帧误分类,通过定位管道和HMM模型将该部分疑似转换片段归为未转换片段,进而修正视频帧类别;图6b是将本文算法应用于夜间场景中,所选视频段环境光线均偏暗,但从分段结果来看,大部分片段定位正确。说明本文算法对光线变化问题有较好的泛化能力,解决了环境光线给识别带来的困难。但图6c最后一次转换分段点位置不够准确,主要因为在母猪转换姿态后部分视频帧分类错误,而采用滑动窗口的方法会提取全部姿态序列中变化次数较多的片段,未能准确定位姿态转换片段的起始和结束帧;图6d则存在分段点过多的问题,主要原因是母猪在姿态转换期间为避免踩压仔猪,会先转换至其他过渡姿态后暂停,出现环视周围及拱鼻探查仔猪等母性行为,确保仔猪安全后再进行转换。该类母猪过渡姿态的不确定性易被误识别为发生两次姿态转换,进而导致分段点过多。
图7为本文算法对测试集连续29 h视频(B3)的姿态转换自动识别结果,共检测出84次转换。21:00~7:00母猪处于夜间休息时间,姿态转换频率较低,而日间母猪姿态转换较为频繁,识别结果符合人工视频观察和母猪动物行为的规律[6]。
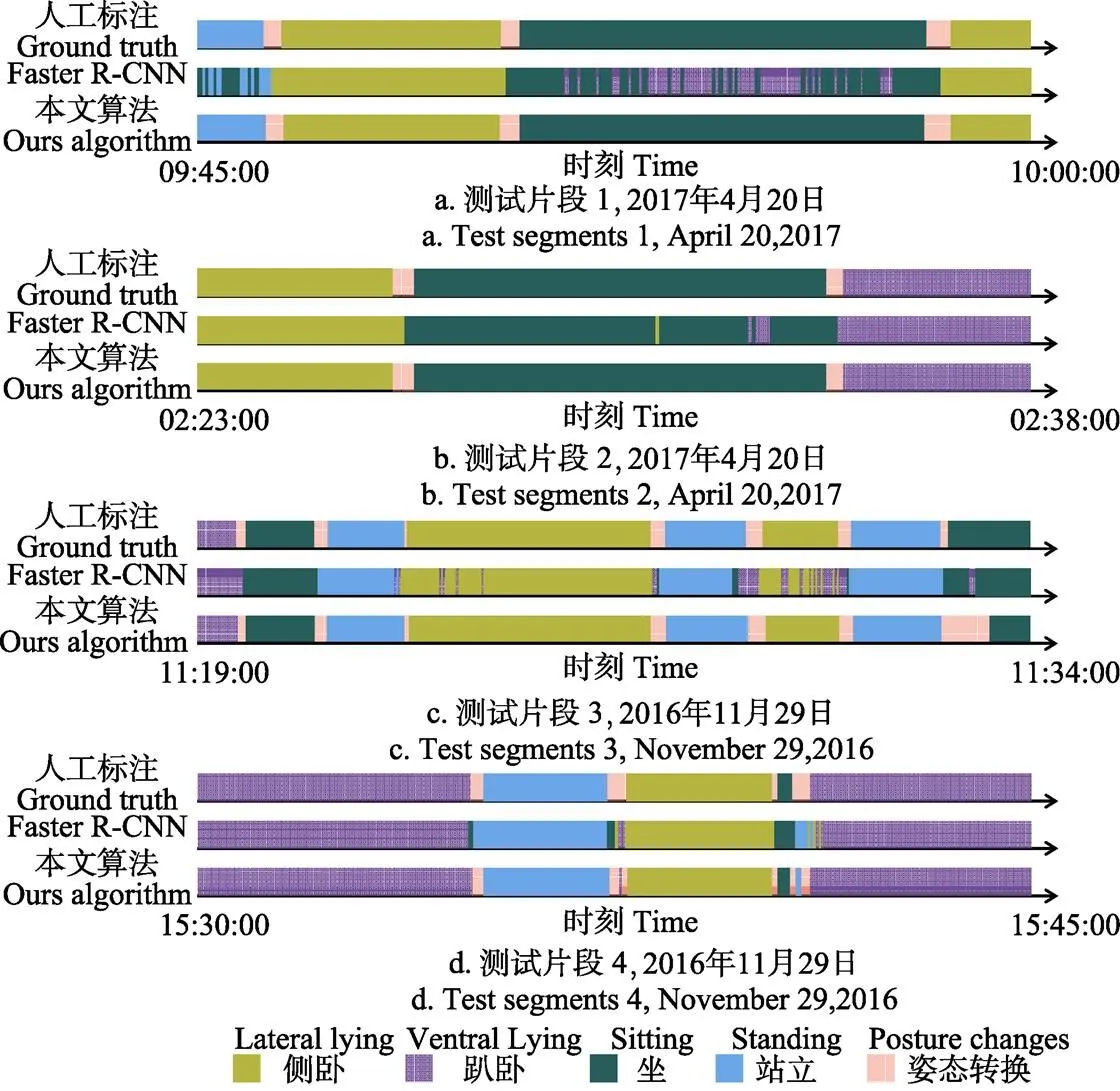
图6 部分测试样本分段结果

图7 本文算法在29 h连续视频上的自动识别结果
4 结 论
本文研究可为哺乳母猪高危动作自动识别中的姿态转换行为识别提供思路,为后续母猪福利状态评估等研究打下基础,但仍存在以下不足:1)Faster R-CNN模型识别精度有待提高,深度图难以辨别母猪部分姿态,后续工作考虑融合RGB图像。2)分段点定位及片段分类的准确性有待提高,改进分段算法将更有利于识别母猪姿态转换。
[1] Marchant J N, Broom D M, Corning S. The influence of sow behaviour on piglet mortality due to crushing in an open farrowing system[J]. Animal Science, 2001, 72(1): 19-28.
[2] Lao F, Brown-Brandl T, Stinn J P, et al. Automatic recognition of lactating sow behaviors through depth image processing[J]. Computers & Electronics in Agriculture, 2016, 125(C): 56-62.
[3] Wang J S, Wu M C, Chang H L, et al. Predicting parturition time through ultrasonic measurement of posture changing rate in crated landrace sows[J]. Asian Australasian Journal of Animal Sciences, 2007, 20(5): 682-692.
[4] Thompson R, Matheson S M, Plötz T, et al. Porcine lie detectors: Automatic quantification of posture state and transitions in sows using inertial sensors[J]. Computers & Electronics in Agriculture, 2016, 127: 521-530.
[5] 闫丽, 沈明霞, 谢秋菊, 等. 哺乳母猪高危动作识别方法研究[J]. 农业机械学报, 2016, 47(1): 266-272.Yan Li, Shen Mingxia, Xie Qiuju, et al. Research on recognition method of lactating sows' dangerous body movement[J]. Transactions of The Chinese Society for Agricultural Machinery, 2016, 47(1): 266-272. (in Chinese with English abstract)
[6] Zheng C, Zhu X, Yang X, et al. Automatic recognition of lactating sow postures from depth images by deep learning detector[J]. Computers and Electronics in Agriculture, 2018, 147: 51-63.
[7] 薛月菊, 朱勋沐, 郑婵, 等. 基于改进FasterR-CNN识别深度视频图像哺乳母猪姿态[J]. 农业工程学报, 2018, 34(9): 189-196.Xue Yueju, Zhu Xunmu, Zheng Chan, et al. Lactating sow postures recognition from depth image of videos based on improved Faster R-CNN[J]. Transactions of the Chinese Society for Agricultural Engineering (Transactions of the CSAE), 2018, 34(9): 189-196. (in Chinese with English abstract)
[8] Jhuang H, Gall J, Zuffi S, et al. Towards Understanding Action Recognition[C]// IEEE International Conference on Computer Vision, 2014.
[9] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos[C]. Advances in Neural Information Processing Systems, 2014: 568-576.
[10] Aggarwal J K, Ryoo M S. Human activity analysis: A review[J]. Acm Computing Surveys, 2011, 43(3): 1-43.
[11] Wang H, Schmid C. Action recognition with improved trajectories[C]// Proceedings of the IEEE International Conference on Computer Vision, 2013: 3551-3558.
[12] Peng X, Zou C, Qiao Y, et al. Action recognition with stacked fisher vectors[C]// European Conference on Computer Vision, 2014: 581-595.
[13] Du Y, Yuan C, Li B, et al. Hierarchical nonlinear orthogonal adaptive-subspace self-organizing map based feature extraction for human action recognition[C]// Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
[14] Shuiwang J, Ming Y, Kai Y. 3D convolutional neural networks for human action recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2013, 35(1): 221-231.
[15] Feichtenhofer C, Pinz A, Zisserman A. Convolutional two- stream network fusion for video action recognition[C]. Computer Vision & Pattern Recognition, 2016.
[16] Gkioxari G, Malik J. Finding action tubes[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015: 759-768.
[17] Saha S, Singh G, Sapienza M, et al. Deep learning for detecting multiple space-time action tubes in videos[C]// British Machine Vision Conference, 2016.
[18] Miao M, Marturi N, Li Y, et al. Region-sequence based six-stream CNN features for general and fine-grained human action recognition in videos[J]. Pattern Recognition, 2017, 76: 506-521.
[19] Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149.
[20] Rabiner L, Juang B. An introduction to hidden Markov models[J]. IEEE ASSP Magazine, 1986, 3(1): 4-16.
[21] Moustsen V, Hales J, Lahrmann H, et al. Confinement of lactating sows in crates for 4 days after farrowing reduces piglet mortality[J]. Animal, 2013, 7(4): 648-654.
[22] Weary D M, Pajor E A, Fraser D, et al. Sow body movements that crush piglets: A comparison between two types of farrowing accommodation[J]. Applied Animal Behaviour Science, 1996, 49(2): 149-158.
[23] Ohtsu N. A threshold selection method from gray-level histograms[J]. IEEE Transactions on Systems Man & Cybernetics, 2007, 9(1): 62-66.
[24] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778.
[25] Wen Y, Zhang K, Li Z, et al. A Discriminative Feature Learning Approach for Deep Face Recognition[M]. Springer International Publishing, 2016: 499-515.
[26] Jia Y, Shelhamer E, Donahue J, et al. Caffe: Convolutional architecture for fast feature embedding[C]// Proceedings of the 22nd ACM International Conference on Multimedia, 2014: 675-678.
[27] Viterbi A. Error bounds for convolutional codes and an asymptotically optimum decoding algorithm[J]. IEEE Transactions on Information Theory, 1967, 13(2): 260-269.
[28] Guo D, Zhou W, Wang M, et al. Sign language recognition based on adaptive HMMS with data augmentation[C]// IEEE International Conference on Image Processing, 2016: 2876-2880.
[29] Stehman S V. Selecting and interpreting measures of thematic classification accuracy[J]. Remote Sensing of Environment, 1997, 62(1): 77-89.
[30] Wu Y, Lim J, Yang M H. Online object tracking: A benchmark[C]// Computer Vision and Pattern Recognition, 2013: 2411-2418.
[31] Gao J, Sun C, Yang Z, et al. TALL: Temporal activity localization via language query[C]// Proceedings of the IEEE International Conference on Computer Vision, 2017: 5277-5285.
Lactating sow high-dangerous body movement recognition from depth videos based on hidden Markov model
Xue Yueju1, Yang Xiaofan1, Zheng Chan2, Chen Changxin1, Gan Haiming1, Li Shimei1
(1.,,510642,; 2.510642,)
The high-dangerous body movements of lactating sows are closely related to the survival rate of piglets, which can directly reflect their maternal behavioral ability, and these movements are closely related to the frequency and duration of posture changing. Under the scene of commercial piggery, the influence of illumination variations, heat lamps, sow and piglet adhesion, body deformation, etc., brings great difficulties and challenges to the automatic identification of the posture changes of lactating sows. This study took the Small-ears Spotted sows raised in the Lejiazhuang farm in Sanshui District, Foshan City, Guangdong Province as the research object, and used the depth video images collected by Kinect2.0 as the data source. We proposed a localization and recognition algorithm of sow posture changes based on Faster R-CNN and HMM(hidden Markov model )models from the depth videos. Our algorithm consists of five steps: 1) a 5×5 median filter is used to denoise the video images, and then the contrast of images are improved by contrast limited adaptive histogram equalization;2) an improved Faster R-CNN model is used to detect the most probable posture in each frame to form a posture sequence, and the first five detection boxes with the five highest probabilities are reserved as candidate regions for the action tube generation in the third step;3) a sliding window with a length of 20 frames and a step size of 1 frame is used to detect the suspected change segments in the video,and then the maximum score of action tube of each suspected change segment is construct by the Viterbi algorithm;4) each frame is segmented by Otsu and morphological processingin the suspected change segments,and the heights of the sow trunk, tail and both sides of body are calculated to formheightsequences; 5) the height sequence of each suspected change segment is fed into the HMM model and then classified as posture change or non-change, and finally the posture change segments are classified according to the classes of before and after segments belonging to single posture segments. According to the threat degree of sow accident and the frequency of sow behavior, the posture changes of sows were divided into four categories: descending motion 1, descending motion 2, ascending motion and rolling motion.The data set included 240 video segments covering different sow sizes, postures and posture changes. The 120 video segments were chosen as the testing set, and the rest of the video segments were used as training set and validation set for Faster R-CNN and HMM. Our Faster R-CNN model was trained by using Caffe deep learning framework on an NVIDIA GTX 980Ti GPU (graphics processing unit), and the algorithm was developed on Matlab 2014b platform.The experimental results showed that the Faster R-CNN model had high recognition accuracy, and the detection time of each frame was 0.058 seconds, so the model could be practicably used in a real-time detective vision system.For sows with different body colors and sizes, theFaster R-CNN model had good generalization ability. The HMM model could effectively identify the posture change segments from the suspected change segments with an accuracy of 96.77%. The accuracy of posture changeidentification was 93.67%, and the recall rate of the 4 classes of posture change i.e. descending movements 1, descending movements 2, ascending movements and rolling were 90%, 84.21%, 90.77%, 86.36%.The success plot was 97.40% when the threshold was 0.7, which showed that the optimized position tube had a good tracking effect for sows in the scene of commercial piggery, effectively overcoming the influence of heat lamps and body deformation of sows. Our method could provide a technical reference for 24-hour automatic recognition of lactating sow posture changes and make a foundation for the following research on sow high-dangerous body movement recognition and welfare evaluation.
image processing; algorithms; models; high-dangerous body movement; lactating sows; Faster R-CNN; HMM(hidden Markov model); action tube
10.11975/j.issn.1002-6819.2019.13.021
TP391
A
1002-6819(2019)-13-0184-07
2018-12-18
2019-04-24
国家科技支撑计划(2015BAD06B03-3);广东省科技计划项目(2015A020209148);广东省应用型科技研发项目(2015B010135007);广州市科技计划项目(201605030013);广州市科技计划项目(201604016122)
薛月菊,汉族,新疆乌苏人,教授,研究领域为机器视觉与图像处理。Email:xueyueju@163.com
薛月菊,杨晓帆,郑 婵,陈畅新,甘海明,李诗梅.基于隐马尔科夫模型的深度视频哺乳母猪高危动作识别[J]. 农业工程学报,2019,35(13):184-190. doi:10.11975/j.issn.1002-6819.2019.13.021 http://www.tcsae.org
Xue Yueju, Yang Xiaofan, Zheng Chan, Chen Changxin, Gan Haiming, Li Shimei.Lactating sow high-dangerous body movement recognition from depth videos based on hidden Markov model [J]. Transactions of the Chinese Society for Agricultural Engineering (Transactions of the CSAE), 2019, 35(13): 184-190. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2019.13.021 http://www.tcsae.org
猜你喜欢
今日农业(2022年4期)2022-11-16 19:42:02
今日农业(2021年5期)2021-11-27 17:22:19
今日农业(2021年21期)2021-11-26 05:07:00
今日农业(2021年20期)2021-11-26 01:23:56
猪业科学(2021年3期)2021-05-21 02:06:10
今日农业(2020年24期)2020-12-15 16:16:00
学生天地(2020年3期)2020-08-25 09:04:16
汽车观察(2018年9期)2018-10-23 05:46:40
中国自行车(2018年8期)2018-09-26 06:53:44
兽医导刊(2016年6期)2016-05-17 03:50:21
