
基于云计算的异地双活容灾技术在民航生产保障中的应用
2019-08-23 02:29吴波李鹏
职工法律天地 2019年12期
吴 波 李 鹏
(401120 重庆机场信息通信网络有限公司 重庆)
0 引言
习近平总书记在网络安全和信息化工作座谈会上的讲话中提到:“网络安全和信息化是相辅相成的。安全是发展的前提,发展是安全的保障,安全和发展要同步推进。”[1]新时代中国特色社会主义建设对民航工作提出了更高的要求,习总书记在十九大中更是提出了“安全隐患零容忍” 的重要精神指示。
随着民航业的发展,民航现代化程度越来越高、生产规模越来越大、分工越来越细、生产协作越来越广泛。民航空安全生产已涉及航空公司、空管、机场、油料等众多互相协作的系统,巳遍布全国各地,甚至世界上不同国家和地区。而民航机场作为这样复杂生产组合下的重要交通枢纽,其指挥和保障工作涉及飞机、车辆、人员和特种设备等多个方面。为了使机场各岗位能够有条不紊地开展工作,各机场都建立了一套适合自身情况的IIS,并与企业战略紧密整合在一起。高度集成的智能化信息系统的确为生产保障提升了效率,但也不可避免的带来了高风险的安全隐患。突发事件造成的非计划宕机的事件不可避免,一旦出现这种情况,轻则影响航班保障流程,重则造成航班信息丢失其损失无法估量。如何容灾已成为各大机场不可回避的严峻问题。
1 行业现状
中国民航信息化建设起步较晚,各大民航机场普遍采用传统的灾备方案来保证关键应用的业务连续性。这种灾备部署方式为一个生产中心、一个灾备中心,灾备中心平时处在不工作状态,只有当灾难发生时,生产数据中心瘫痪,灾备中心才启动。这种传统模式通常是采用存储数据级复制,或是采用数据库Golden Gate或Data Gurd特性复制,但是数据库本身License比较昂贵,且无法自动化主备切换,更不能满足业务对连续性RPO=0、RTO≈0要求,即使采用存储复制技术也很难解决RTO≈0的要求;从运维角度来说,切换时间长、突发事件中存在必然的数据损失、灾备中心健康状态不可见、缺少演练等等实际情况普遍存在。
所以也有部分走在信息化建设前沿的机场,已经看到传统灾备方案确实不能满足现有安全生产的需求,由此提出并落地实施了基于云计算的信息化系统建设。
云计算在海外经过多年的发展,其虚拟化、分布式计算、分布式存储、编程模型、云平台等核心技术已日臻成熟。相对于传统部署模式而言,其灵活配置、资源利用率高和节省成本的优势将愈发显著,也确实极大程度降低了突发事件造成的非计划宕机事件RPO、RTO。
但是,任何一件事物都有利弊之分,云计算也不例外。尽管众云计算厂商把云计算炒得大红大紫,每个厂商推出的公有云、私有云、混合云、云套件也是层出不穷,在介绍产品时更是提出99.99%的可靠性、高可用性、安全性,故障率可控在0.01%以下等。不可否认,云计算很好,但还有很长的路要走,很多地方都得完善和优化:
2018年6月27日,阿里云因上线一项更新操作,导致提供的云计算服务除部分管控功能外,MQ、NAS、OSS等产品的部分功能出现访问异常。此次事故从16点21分至17点30分,时长约一小时,被誉为中国互联网半壁江山,惊魂整整一小时!
2019年3月3日,阿里云再次发生类似故障,导致华北2地域可用区ECS服务器(云服务器)等实例出现IO HANG,所有依托在上面的信息服务停止响应。
类似情况不仅是国内产品,国际大品牌同样时有发生:
2017年 1月26日,IBM:客户用于访问其Bluemix云基础架构的一个管理网站服务中断了数小时,用户无法管理自身的应用程序,添加或删除支持工作负载的云资源。
2017年 1月31日,GitLab:GibLab.com遭遇了18小时的服务中断,最终无法完全修复。一些客户的生产数据最终丢失,影响范围约5000个项目。
2017年 2月28日, 亚马逊:亚马逊坐拥约三分之一的全球云市场,此次事件造成诸如Slack,Quora和Trello等众多全球性企业服务平台宕机4个小时,根据外媒估算,此次宕机造成了最高数千万美元的损失。
2017年 6月28日, 苹果iCloud:苹果iCloud Backup服务停止服务至少36个小时。
2018年 7月17日,谷歌:谷歌云的宕机,持续近1小时。
2018年 7月16日,亚马逊:当天是第四届亚马逊会员日,当日的开幕仪式后几分钟,大规模的故障使得当日的销售陷入了瘫痪。而亚马逊的云平台确实世界上最领先,用户数量最多的平台。
由此可见,云虽好,但“鸡蛋不能放在一个篮子里”,哪怕是0.01%的故障几率,造成的结果可能也是无法承受之重。
因此,当一个数据中心发生故障时,另外一个数据中心可实时接管所有业务的双活容灾解决方案成为当前讨论和建设的热门技术方案。双活容灾解决方案能够盘活现有IT资源,充分发挥资源利用优势,实现应用级双活无感知切换,达到业务服务的7x24小时服务质量保证,降低灾难性事件发生后业务宕机的风险。
2 异地容灾真实案例
前文的宕机实例中有两次都是阿里云,但却从未对阿里自身的业务造成任何影响,正是因为阿里没有把鸡蛋放在同一个篮子里:
2015年5月28日下午17时许,支付宝被反映故障;18时许,支付宝通过官方微博给出回应,解释是因为电信运营商光纤被挖断,导致小规模用户登录异常。19时许,支付宝服务恢复正常;次日凌晨,电信运营商恢复光线链路。此次事件中,绝大部分用户实现了无感知切换。而“小部分”不能无感知切换的用户,是应为在事故发生的瞬间正在产生交易记录,支付宝处于金融安全的考虑,进行了完整的数据校验,保证所有客户的客户信息、账户信息、资金信息、交易信息都是正确的,一切确认完成后,才重新“开门迎客”。这个过程耗时了一个多小时,不过相比较支付宝数亿客户所对应的校对数据量,这个时间完全是可以接受的。此次事件是中国金融史上第一次在完全突发情形下,成功完成快速切换的真实案例,整个切换过程中,没有一条客户数据丢失,充分体现了金融级的数据高可用要求。
此次事件虽然时间稍微长了一点,但技术是不断进步的。
2017年杭州云栖大会ATEC主论坛现场上,支付宝工程师针对此次的事件进行了一次特别技术演练:他们基于支付宝的真实机房,现场模拟挖断支付宝近一半服务器的光缆。断网后的约20秒内,账户页面显示系统异常,26秒后,观众全部都能顺利转账。
3 异地双活容灾技术
支付宝的案例,是一次异地多活的“三地五中心”金融级别的典型案例,就民航机场而言,我们大可不必大张旗鼓,异地多活过于奢侈,我们只需要做到“同场不同楼的异地双活”即可。
3.1 业界主流双活技术
目前的业界主要针对存储,为解决数据库"高可用性"(High availability, HA)问题而衍生出两种主流技术:active-active(真双活)和active-passive(伪双活)。
active-active:用两个完全一样的server,然后用一个load balancer(负载均衡)进行请求的调度。load balancer的算法可以很高深也可以很简单。简单的例如"round-robin", 就是轮换.第一个请求发给服务器1, 第二个发给服务器2, 第三个发给服务器1, 以此类推。重要的是这两个服务器应该是完全一致的,这样才能确保用户端,仿佛一直在访问同一个服务器。Huawei HyperMetro,HDS GAD,EMC VMAX SRDF/Metro Active-Active均采用这种技术,双活的两个副本可同时被主机并发读写访问,负载均衡,有完备仲裁机制。
active-passive:active-passive也是两个服务器节点, 但是绝大多数时间是active的那个(或者说primary)进行服务, 当primary服务器出问题, 就使用另一个passive服务器作为备用。跟active-active一样, active-passive也应该确保两个服务器完全一致。NetApp,HP PeerPersistence,FUJITSU Storage Cluster,DELL LiveVolume,IBM HyperSwap 等厂商采用这种技术,Server间有各自不同的仲裁机制。
3.2 理想的异地双活容灾方案
一套理想的异地双活容灾方案,不应当仅仅局限在存储层面的双活。在保障民航生产系统7X24小时不间断安全稳定这个前提下,我们所提出的双活,应该是更加广义的,涵盖应用、网络、存储和数据的端到端的数据中心双活。即应用、网络、存储、数据都应该是双活状态。如下图三是一个理想中的广义数据中心双活方案:
3.2.1网络和存储层面
方案中数据中心A和数据中心B之间采用网络互联,数据中心内采用传统两层或三层组网方式互联;接入层链接业务服务器、核心/汇聚层通过大二层互通技术链接到对端数据中心;存储、交换机和服务器通过专门的SAN网络互联;通过冗余组网的方式,用FC协议实现两个数据中心的交换机互联,各节点间互为备份,均衡负载,任何节点故障后,其承接的业务自动切换到正常节点,保证系统的可靠性、业务的连续性。在数据双活的情况下,实现数据零丢失,业务零中断。[2]
3.2.2. 数据层面
方案中以大二层网络为基础,通过VMware、Hyper-V、Oracle RAC、SQL MSCS/MSFC、IBM PureScale、华为 VIS等业界主流技术,均可以实现数据中心的数据同步,其中Oracle RAC、PureScale和华为VIS均可实现active-active,既可以单独使用,也可以混合搭配以实现更为完备的功能,可根据各机场实际情况采用不同的技术架构。图四以华为VIS技术为例,介绍数据层同步的基本原理:
VIS镜像的写I/O流程如下:
①写请求到镜像卷;
②镜像卷将请求复制为两份下发到两中心的镜像数据盘;
③镜像数据盘返回写操作完成;
④镜像卷返回写I/O操作完成。
VIS镜像的读I/O流程如下:
①读请求到镜像卷;
②镜像卷根据读策略下发请求到其中一个中心的镜像数据盘;
③镜像数据盘返回读数据;
④镜像卷返回读数据。
该方案利用VIS镜像卷技术,保证两个数据中心存储阵列之间数据的实时同步。由于VIS镜像卷技术对主机层透明,当任一存储阵列故障时,镜像阵列无缝接管业务,数据零丢失,业务零中断。当单阵列或单数据中心故障时,镜像卷选取正常数据中心的阵列响应主机I/O,并采用差异位图盘记录故障期间数据的变化情况,待故障修复后进行增量同步,从而减少数据同步量,缩短数据同步时间,降低数据同步对带宽的需求。[3]
3.2.3应用层面
方案中在两个数据中心均部署了相同的应用服务器,用户对双活数据中心资源访问的访问,通过LAN经过服务器本地缓存、第三方仲裁(Thrid-place quorum site)定位到资源。为了保证负载均衡,数据中心会部署GSLB和SLB来保证每次访问都能负载均衡到相应的数据中心、相应的服务器上。GSLB和SLB之间实时同步两个数据中心IP资源情况,通过HA或本地优先方案的策略实现资源访问IP分配。在具体实现上,目前成熟技术有OracleRAC、IBMGPFS、Symantec VCS、PowerHA HyperSwap和华为VIS等。由于技术并不复杂,有实力的机场也可以自己开发适合自己的技术方案。
3.2.4 第三方仲裁
方案中使用到了第三方仲裁,该仲裁其实是对存储集群和服务器应用集群之间的仲裁。因为成本低、技术简单,目前支持仲裁服务器的厂商比较多。但该设备也不是必须,很多厂商也提供优先存活站点策略来实现业务访问,不过如果运气不好,优先存活站点发生故障,后果很严重。所以在预算许可的情况下,采用第三方站点仲裁更保险。
3.3 异地双活的基本要求
双活方案对网络健康情况有较高的要求。网络时延、带宽、误码率都会影响双活方案。由于两个数据中心数据实时复制,所以链路网络带宽必须高于高峰IO访问时的带宽;网络时延会影响整个应用系统业务响应;误码率会影响网络的利用率,误码率越高就意味着数据需要被重传,从而形象整个网络。
同时,双活方案对硬件也有一定要求。因为两个数据中心在级别上是对等的,所以两个数据中心的存储、服务器等系统都应该是对等的,否则任何一方如果成为性能瓶颈都将影响另外数据中心。
4 双活容灾解决方案的不足
世上没有完美无缺的技术。虽然双活容灾解决方案优点很明显,对于集中式管理的数据中心更大限度的保证了业务生产的在线性及有效的防御了灾难性事件恢复业务生产的能力。但是双活数据中心的容灾方案还是存在一定的不足之处,理想与现实总存在一定的距离:
4.1 脑裂现象
双活数据中心方案实现了站点级的冗余的容灾解决方案,但是受限于当前的技术等因素,在建设过程中解决了企业当前面临的业务连续性问题,同时也产生了新的问题,就是双活解决方案普遍存在的脑裂现象,在意外事件发生时,若监测技术不到位、系统平台不健康、两数据中网络波动性中断等因素的发生,使得两个数据中心一体化的业务系统会分裂成两个独立的数据中心。使用户很难取舍那一个是唯一的生产数据,那一个是将要废掉的非生产数据。
4.2 非“零丢失”,不具备软错误的保障
双活容灾解决方案的优势强调在健康的运行平台下,大型灾难事件发生是的“零”数据丢失,但是若双活平台本身不健康或者遭遇逻辑故障时,并不能保障数据零丢失。这种故障发生在渐变式灾难发生的情况下,比如业务系统升级过程中导致系统错误,这种时候还需借助备份系统的数据恢复手段或方法。因此,双活容灾方案大多数情况下不具备解决软错误的保障,而恰恰这种事件发生的概率远远超过站点级的灾难及硬件故障事件。
4.3 运营维护并不简单
双活容灾解决方案灾难切换方面变的较为简单,但在实际的维护方面并不简单,企业自身人员的维护能力必须加强,才具备能力维护跨站点的双活系统。也就是需企业用户自身人维护人员必须从维护设备的能力转变为具备维护双活系统架构的能力,才能维稳系统的正常运行,让双活系统实现该有的效果。[4]
5 结束语
随着科技发展和技术的进步,信息化建设成为民航机场现代化建设持续发展的必然趋势,而确保信息系统稳定可靠的运行和数据安全则成为民航机场信息化建设的重中之重。双活容灾技术有其不足之处,但随着技术的发展、管理的提高、运维人员能力的增强,其现有的不足之处必将被无限的缩小,在民航系统现代化建设中展现出重要的作用。
6 缩写词
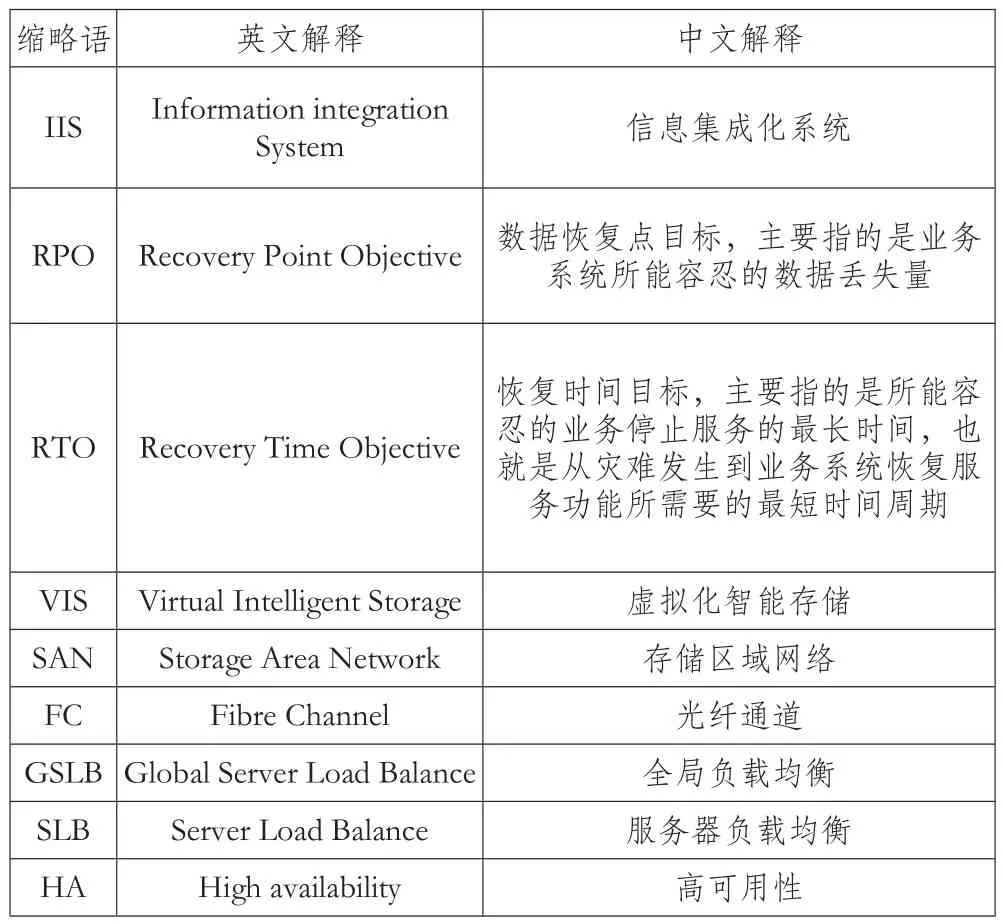
缩略语 英文解释 中文解释IIS Information integration System 信息集成化系统RPO Recovery Point Objective 数据恢复点目标,主要指的是业务系统所能容忍的数据丢失量RTO Recovery Time Objective恢复时间目标,主要指的是所能容忍的业务停止服务的最长时间,也就是从灾难发生到业务系统恢复服务功能所需要的最短时间周期VIS Virtual Intelligent Storage 虚拟化智能存储SAN Storage Area Network 存储区域网络FC Fibre Channel 光纤通道GSLB Global Server Load Balance 全局负载均衡SLB Server Load Balance 服务器负载均衡HA High availability 高可用性
猜你喜欢
电子乐园·下旬刊(2022年5期)2022-05-13
建材发展导向(2021年7期)2021-07-16
当代党员(2020年20期)2020-11-06
中国计算机报(2018年12期)2018-10-08
小康(2018年23期)2018-08-23
中国计算机报(2017年25期)2017-07-15
小康(2015年4期)2015-03-31
网络与信息(2009年4期)2009-04-26
中国计算机报(2009年21期)2009-04-22
