
一种基于聚类的服务QoS值协同过滤预测方法
2019-08-22 01:27任丽芳陈三丽
山西大学学报(自然科学版) 2019年3期
任丽芳,陈三丽
(1.山西财经大学 信息学院,山西 太原 030006;2.太原师范学院 计算机科学与技术系,山西 晋中 030619)
0 引言
互联网技术的飞速发展促进了计算模式的不断演变,软件、数据、存储、计算力等都被打包成服务的形式交付用户使用,服务的种类和数量急剧增长,出现了许多具有相同功能而不同QoS的服务[1-2]。而且现有研究已经表明服务QoS是个性化的,即不同的用户使用相同服务时其QoS值是不同的[3]。因此,如果能对用户使用服务的QoS进行预测,不仅有助于用户在相同功能的服务中选择QoS更优的服务,而且能主动地为用户推荐QoS最优的服务。服务QoS值预测正受到学术界和工业界越来越多的关注[4]。
现有的服务质量预测方法通常是基于协同过滤的,包括基于内存的方法和基于模型的方法。其中基于内存的方法在本质上是基于近邻的方法,根据历史数据挖掘用户或服务之间的相似模式,然后基于K个最相似用户或相似服务对目标用户使用未知服务的QoS做出预测。这类方法在理论上可解释性强,引起了国内外学者的广泛关注[5-14]。
基于相似用户的方法将与目标用户偏好相似的用户的历史记录中QoS好的或者评价高的服务推荐给目标用户。如Shao等人在文献[5]考虑用户间在相同服务上的相似的QoS体验,提出了基于用户的协同过滤个性化QoS 预测方法。在文献[6]中Zheng和Lyu提出了一种基于用户的面向服务的系统的可靠性预测方法,并指出可靠性可以扩展到其他QoS 属性。他们用Pearson相关系数来度量用户之间的相似性,利用相似用户的数据来预测组件服务对于目标用户的失败率。基于相似服务的方法将与目标用户的历史记录中QoS高或者评价好的相似服务推荐给用户,常常与基于相似用户的方法联合使用。如Zheng 等人在文献[7]和[8]提出了集成用户相似的方法与服务相似的服务推荐方法,通过将基于用户的QoS值与基于服务的QoS值加权平均来计算未知QoS值,提高了服务QoS 预测的准确率,为服务推荐提供了依据。Jiang等人在文献[9]提出了一个协同过滤方法,该方法集成了基于相似用户的协同过滤与基于相似服务的协同过滤,他们在度量用户或者服务的相似性时通过考虑共同服务或者用户的标准差改进了相似度计算方法,提出了集成相似用户与相似服务的Top-N服务推荐方法,进一步提高了个性化QoS预测的准确率。Chen等[10]提出了基于特征聚类的潜在因子模型CFLFM来预测QoS。Min等[11]根据用户的相似性设计了鲁棒的服务QoS预测方法,阻止先令攻击。Ren和Wang在文献[12]利用SVM预测服务QoS是否能被目标用户偏好,进而实现服务推荐。Hwang等[13]将服务的QoS值表示为具有概率函数的离散随机变量,为服务选择预测QoS值。Ma等[14]根据高度相似的相似不变性,用回归的方法进行服务QoS预测。
这类基于近邻的方法中K值的确定需要通过实验进行参数调节,不具有通用性。而且对于不同的目标用户,使用相同的K值。然而实际中,有的用户相似用户较多,而有的用户相似用户较少。小K值使相似用户较多的用户失去部分相似用户提供的信息,大K值又使相似用户较少的用户参考了许多本来不相似的用户的信息,导致QoS预测的准确度不高。因此,本文提出一种基于聚类的服务QoS预测方法,该方法能根据数据本身疏密程度自然地个性化地确定相似用户的个数。
1 问题描述
服务QoS是服务的推荐与服务选择中的关键因素。然而,不同的用户使用相同的服务其QoS值是不同的,因此,对于用户尚未使用过的服务其QoS值是未知的,本文解决的问题正是对未知QoS值的预测。
定义1:目标用户是指要为其使用服务能获得的QoS值进行预测的用户。
定义2:未知服务是指目标用户尚未使用过的服务,对于该用户而言他使用该服务能获得的QoS值事先是未知的。
因此,服务QoS值预测的目的就是对目标用户使用未知服务能获得的QoS值进行预测。我们希望通过用户使用服务的历史QoS数据,为目标用户找到相似用户,然后利用相似用户使用该服务的QoS值对该用户使用该服务的QoS值进行预测。因此,相似用户的判定是服务QoS预测的核心步骤。
定义3:相似用户是指在历史记录中,与目标用户有共同使用过的服务的用户,且在这些共同用户上获得的QoS值与目标用户获得的QoS值相等或接近。由目标用户的所有相似用户组成的集合为相似用户集。
定义4:相似服务是指在历史记录中,与目标服务被共同用户使用过的服务,且在这些共同用户获得的QoS值与目标服务获得的QoS值相等或接近。由目标服务的所有相似服务组成的集合为相似服务集。
协同过滤思想认为在以往共同使用过的服务上有相似QoS值的用户,在未知服务上得到的QoS也可能是相似的。因此,可以借助相似用户在目标用户的未知服务上获得的QoS值对目标用户使用未知服务的QoS值进行预测。
2 方法描述
CQoSP (Cluster-based QoS Prediction)是通过聚类识别相似用户/服务,自然地确定相似用户/服务,然后基于相似用户/服务进行协同过滤服务推荐。
2.1 用户/服务空间聚类
K个初始化的质心的位置选择对最后的聚类结果和运行时间都有很大的影响,因此需要选择合适的K个质心。如果仅仅是完全随机的选择,有可能导致算法收敛很慢。K-Means++算法就是对K-Means随机初始化质心的方法的优化,如算法1所示。

算法1 K-Means++聚类算法
在该算法中,类簇个数K是输入参数,K值的确定也是聚类算法的关键。由于在用户空间聚类之前,我们并不知道可能的类簇个数,因此,CQoSP拟使用如式(1)定义的DB指数(Davies-Bouldin Index,DBI)作为聚类性能指标。
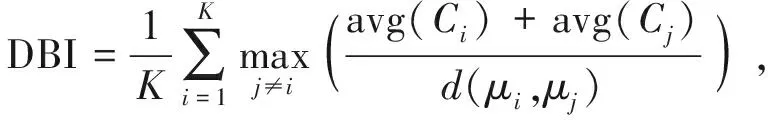
(1)
其中,avg(Ci)是对应于类簇Ci内样本间的平均距离,d(μi,μj)是类簇Ci与Cj中心点μi与μj间的距离。DBI越小聚类性能越好,因此CQoSP选取使DBI取得最小值的聚类个数K为类簇的个数。
经过聚类相似用户自然地被分到同一类簇,记用户u的同类用户集为C(u)。同时,一些不可信用户在聚类后往往呈现为一种离群点,可以较为容易地被识别并从模型中过滤掉。
同样地,服务空间也可以类似地进行聚类,以一种自然的方式发现相似服务。
2.2 用户间/服务间相似性计算
属于同一类簇的用户,他们之间的相似度也会有差异。CQoSP细致地对待同类用户之间相似度的差异,使用式(2)所示的改进的PCC计算每对相似用户的相似度[16]。
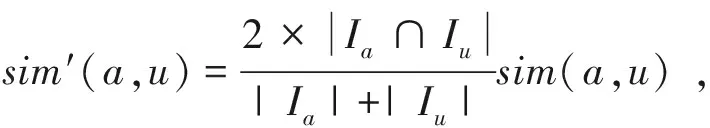
(2)
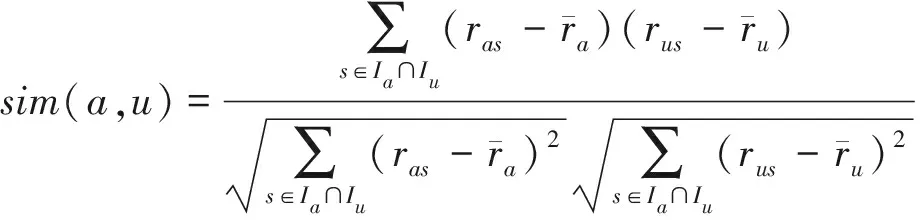
相同的方法,可以计算服务i和服务j之间的相似度sim′(i,j)。
2.3 综合预测
根据式(3),可以综合基于用户和基于服务的相似邻居进行QoS值预测:
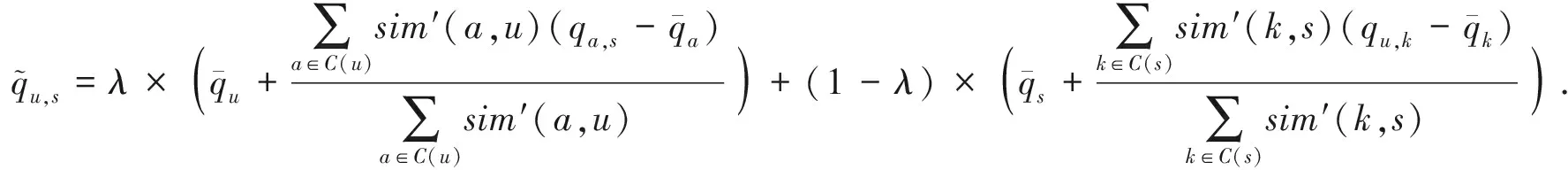
(3)
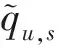
因此,基于聚类的服务QoS值预测方法的主要步骤如算法2所示。

算法2 基于聚类的服务QoS值CF预测算法
3 实验结果与分析
3.1 实验数据及环境
本文使用香港中文大学郑子彬博士等人公开的真实数据集WSDream[1]中的Dataset2数据集进行测试,该数据集描述了真实世界中来自不同国家的339个用户调用5 825个Web服务的QoS数据,其中响应时间矩阵rtMatrix(单位:秒)和吞吐量矩阵tpMatrix(单位:比特率),皆为339行×5 825列的用户-服务矩阵。矩阵中用-1表示服务调用发生失败。
实验中随机将数据集分为两部分,分别用于训练和测试。由于实际应用中,数据通常是非常稀疏的,而WSDream测试数据集是稠密的,因此,本文随机删除一定数量的值,形成不同的密度的QoS矩阵。仿真实验在MATLAB R2014b环境运行,操作系统Windows10 64位,处理器为Intel Core i7,3.6 GHz,内存8 GB。
3.2 评价指标
本文对QoS预测值准确度的评价指标是式(4)定义的平均绝对误差(Mean Absolute Error,MAE)和式(5)定义的均方根误差(Root Mean Square Error,RMSE)。
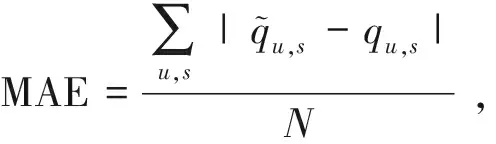
(4)
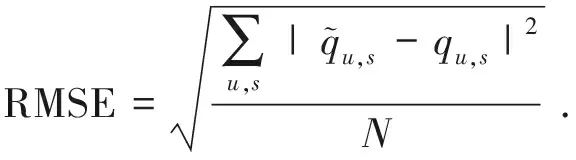
(5)
其中是N为需要预测的QoS的总个数。MAE与RMSE越小,表示预测的准确度越高。
3.3 实验结果分析
为了验证CQoSP的有效性,本文首先考察不同数据的用户/服务的最优聚类,然后考察权重参数的不同值时的预测准确度,最后与3个经典的基于近邻方法比较QoS值的预测准确度。
(1)聚类个数K的确定
为得到相似用户/服务类簇,首先对用户/服务空间进行聚类,为得到最合理的聚类效果,分别考察不同聚类个数的DBI值。图1关于用户空间的聚类情况,其中图1(a)是密度为0.1的响应时间矩阵在不同用户聚类个数的DBI值,图1(b)是密度为0.1的吞吐量矩阵在不同用户聚类个数的DBI值。
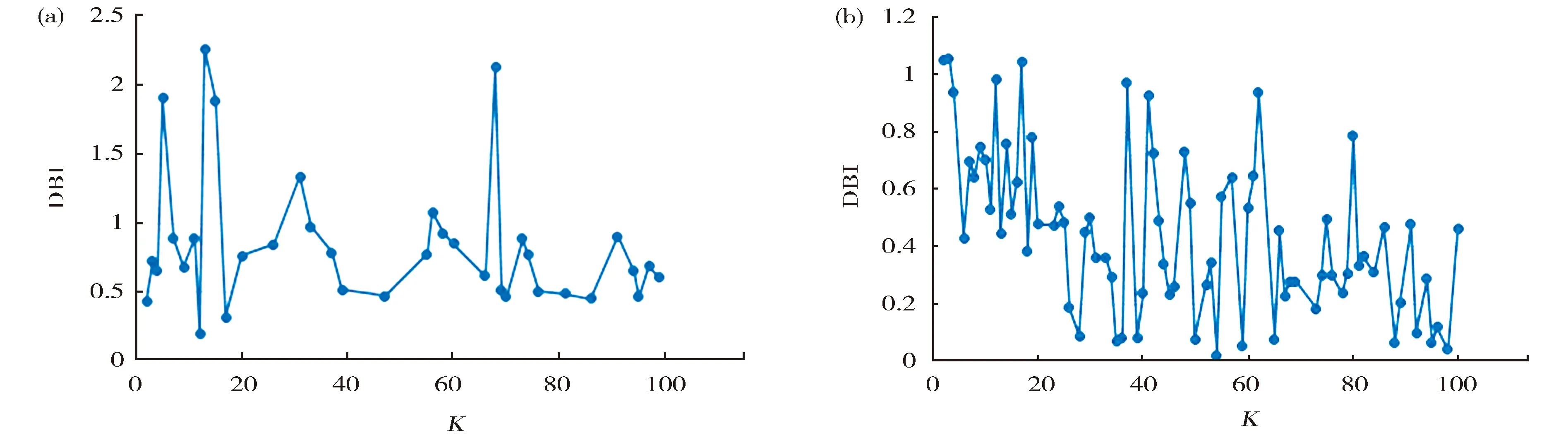
Fig.1 Different DBI values with different user clusters on the dataset of density=0.1图1 密度为0.1的数据集上,不同类簇个数K下,用户空间的聚类DBI值
图1(a)与图1(b)分别反应的是响应时间数据上和吞吐量数据上用户类簇个数K从2变到100时,DBI的值,有些K上聚类不收敛,没有取到相应的点。从图中不难发现吞吐量的用户聚类收敛情况较多,取点较密,而且聚类效果较好。响应时间数据的最优聚类个数K=12,此时DBI=0.196 3;而吞吐量数据的最优聚类个数为K=54,此时DBI=0.020 7。
图2是关于服务空间的聚类情况,其中图1(a)是密度为0.1的响应时间矩阵在不同服务聚类个数的DBI值,图2(b)是密度为0.1的吞吐量矩阵在不同服务聚类个数的DBI值。

Fig.2 Different DBI values with different services clusters on the dataset of density=0.1图2 密度为0.1的数据集上,不同类簇个数K下,服务空间的聚类DBI值
图2(a)与图2(b)分别反应的是响应时间数据上和吞吐量数据上不同服务类簇个数时DBI的值。实验中K从2取到300,为了图形的清晰,只取了最优聚类出现的一段。实验结果表明,响应时间数据的最优聚类个数K=216,此时DBI=0.050 6;而吞吐量数据的最优聚类个数为K=295,此时DBI=0.045 6。
表1是不同密度的响应时间数据和吞吐量数据在用户空间和服务空间的最优聚类个数及相应的DBI,本文后续实验的聚类个数参照本表设置。
(2)与其他方法的比较
为验证本文提出的CQoSP方法的有效性,与UPCC(user-based collaborative filtering method using PCC,基于用户的PCC协同过滤)[5]、IPCC(item-based collaborative filtering method using PCC,基于项目的PCC协同过滤)[17]、UIPCC(user-based and item-based collaborative filtering method using PCC,基于用户和项目的PCC协同过滤)[8]3种方法比较QoS预测值的准确度。

表1 不同密度下响应时间与吞吐量在用户和服务空间的最优聚类个数及相应的DBI

表2 准确度比较
从表2可以看出,CQoSP方法在响应时间和吞吐量数据集的不同密度上的预测准确度比其他方法都有明显提高,说明按照数据本身的特性自然地确定相似用户以及相似服务的个数,有助于提高基于近邻的预测方法的准确度。
4 结论
本文提出了基于聚类的服务QoS预测方法CQoSP,首先通过聚类分析出相似用户/服务类簇,再进一步计算同一类簇的用户/服务与目标用户/服务的相似度,根据相似程度确定他们提供的数据的权重,最后按权重综合基于相似用户的预测值与基于相似服务的预测值得出最终的预测值。在真实QoS数据集WSDream上进行了实验,在与3种经典方法的比较中验证了CQoSP方法对预测准确度的提升。由于Web服务中的服务和用户都在不断增长,且动态环境中服务的QoS具有不确定性,未来将结合贝叶斯网络探索大数据情境下服务QoS值的个性化预测。
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
集装箱化(2017年4期)2017-05-17
集装箱化(2016年11期)2017-03-29
集装箱化(2016年12期)2017-03-20
中国交通信息化(2016年5期)2016-06-06
中小企业管理与科技·中旬刊(2014年10期)2015-02-03
