
考虑布局熵的多态性车间布局稳健优化模型与算法
2019-08-22 00:46程子文姜枞聪王亚良郦仕云
中国机械工程 2019年15期
陈 勇 程子文 姜枞聪 王亚良 王 成 郦仕云
浙江工业大学机械工程学院,杭州,310014
0 引言
制造业的市场需求有着持续性、关联性、多变性等特点,客户需求多样化和订单动态波动的趋势日益突显,企业需要更加合理的车间布局来满足生产高柔性、制造低碳化、布局高稳定性等要求。复杂性作业车间的布局问题近年来的研究主要集中于面积利用率、物流成本、搬运距离、设备利用率、鲁棒性和柔性等多目标对布局系统的影响。 朱琳等[1]为解决多品种混合装配车间的布局问题,以工人平均取料路径最短为目标,以物料摆放位置为决策变量,建立了数学模型,采用只允许最优解释放信息素的蚁群算法求解目标函数;刘琼等[2]针对动态环境下频繁的布局优化,以物料搬运费用和面积费用最小化为目标,建立了鲁棒性布局优化模型,利用改进的蛙跳算法求解具有较高鲁棒性的布局方案;马淑梅等[3]考虑产品不确定性随时间变化的特性,构建了基于柔性区域结构的不确定需求动态布局模型,并提出一种结合模糊理论与改进遗传算法的动态布局方法;刘琼等[4]以制造过程总碳排量和调度完工时间最小为双目标,建立了车间布局与调度集成优化模型;陈勇等[5]针对一类多态性作业车间,利用成组技术与分层思想构建低熵布局模型,提出了低熵化布局评价指标;GONZALEZCRUZ等[6]以多产品工艺顺序作为设备间物流紊乱度指标,采用熵优化算法求解了混合生产车间低紊乱度布局问题;KAVEH等[7]通过建立期望值、机会约束规划、相关机会规划模型来解决模糊约束条件下的动态车间布局问题;GARCIAHERNANDEZ等[8]针对物流量最小和稳定性最高的多目标,设计了融合专家定性评判与聚类遗传算法的混合优化算法;RAZAVIALAVI等[9]同时考虑设备位置、物流成本以及动态物料配送,建立了多目标布局模型,采用遗传算法与仿真软件的交互式运算解决了多态性车间布局问题;LENO等[10]以单元间设备布局、物料进出口最佳位置和物料移动距离为目标建立基于混合整数规划的数学模型,通过最小化处理成本来评估布局的质量,设计融合模拟退火算法与遗传算法的混合进化算法来求解目标。
在解决多目标问题时,多目标优化算法求解Pareto解集是主要趋势。如非支配解排序遗传算法(non-dominated sorting genetic algorithmⅡ,NSGAⅡ)[11]、强度Pareto进化算法(strength pareto evolutionary algorithm,SPEA)[12]等。近年来,又相继出现了在NSGA基础上改进的多目标粒子群算法(multi-objective particle swarm optimization,MPSO)[13]、多目标果蝇优化算法(multiobjective optimization algorithm for drosophila melanogaster,MOADM)、多目标差分元胞遗传算法(multiobjective differential cellular genetic algorithm,MDCGA)[14]。总体而言,这些算法在一定程度上能够很好地求得Pareto解,但也存在一些问题。如NSGAⅡ、SPEA会出现解集分布不均匀、收敛性不足等问题。改进的多目标算法整体上表现出良好的性能,但在非线性、高维度的NP-Hard问题上依然不能满足要求。
本文提出以单位面积布置成本、单位产品物流成本以及布局熵为指标,设计多目标的布局模型,实现一类多态性车间低成本、高稳健性布局。设计基于Pareto优化的模糊聚类并行多目标遗传算法以提高Pareto解集分布的多样性与均匀性;提出改进的多元胞差分进化重插入操作以避免算法陷入局部最优。提出的算法能够有效地保证整个Pareto曲面解集的均匀分布,保证种群的多样性,提高进化效率与解的质量。
1 一类多态性作业车间布局目标
1.1 一类多态性作业车间问题描述
一类多态性作业车间是指大规模定制和产业集群下代工企业为满足多品种、小批量的市场需求,以单元群制造模式为基础,实现多产品、多工艺、多功能区域一体化的生产车间[15]。其生产过程在订单、设备、工艺、批量、瓶颈等层次上越来越凸显出形态和状态的多样性,加工批量和运转批量呈现动态性,布局高稳健性需求逐步增强。
多态性作业车间布局问题描述如下:n种产品需要在m个功能单元内加工装配,每种产品具有不同的加工路线,受到功能区域紧前关系约束,需要完整地在必须经过的功能单元上完成相应的过程。布局过程受单元形状、物流成本、产品工艺、布局稳定性等多条件约束,需寻求车间布局整体最优化。
1.2 车间布局多目标
企业希望通过提高车间面积利用率,降低产品物流成本,同时保证车间的稳定性,实现车间的有效布局。参考文献[16]给出的布局关键目标建议,提出以下3个布局目标。
(1)单位面积布置成本T。传统意义上的车间面积利用率是需求面积与车间总面积之比,仅表示车间面积被占用情况,无法表征土地利用价值。笔者认为在有限的土地资源中,单位面积布置成本能够更加直观地体现车间面积的有效利用价值。单位面积布置成本越小,表明面积的利用价值越高,布局更合理高效。
考虑不同的设备布局方式会带来单元形状变化,进而引起布置成本变动,因此研究中考虑单元形状不固定的情况,引入单元纵横比的概念,即
(1)
式中,li、hi为单元i的长度和宽度。
对任意单元而言,恰当的纵横比表征合理的单元形状,不易引起额外的布置成本,否则易造成布置成本增加。将纵横比与设备成本耦合,定义布置成本:
(2)
s.t.
Δx=max|xi-xj|
Δy=max|yi-yj|
i,j=1,2,…,m
式中,m为单元数;Mi为单元i的设备数;qM为设备M的成本;F(ηi)为单元纵横比ηi模糊评价函数,参考文献[17],文中引用图1所示的最简单的评价函数;ηi,max、ηi,opt为单元i纵横比上限和最优值,可根据实际情况定义;Δx、Δy分别为单元i、j沿x轴和y轴方向的间距;ΔxΔy为车间包含所有单元的最小面积;xi、xj、yi、yj分别为单元i、j的横纵坐标。
(2)单位产品物流成本Z。最小化物流搬运耗费是传统的布局评价目标。产品物流流向的复杂性与功能单元的不确定性导致常规的物流量距模型只能模糊地描述车间物流对布局的约束。多品种多工艺生产的路线较多、交叉频繁,需根据不同产品组合选择合理的生产工艺路线,以减少其交叉。同时考虑搬运距离,以达到总物流量距最小。笔者提出以单位产品的有效物流量距成本与路线交叉惩罚成本衡量物流对布局的约束,有
(3)
s.t.
dij=|xi-xj|+|yi-yj|
式中,n为产品总数量;fijp为产品p在单元i至单元j间的物流量;cijp为产品p在单元i和j之间的单位运输成本;Cpk为产品p与产品k的路线交叉惩罚成本;dij为单元i和单元j间的距离,考虑车间内物料搬运无法沿两点间直线搬运,故视为单元间折线距离。
(3)布局熵E。多态性作业车间需要一个较为稳定的生产环境,稳定性的获得不仅依赖于布局系统的可靠运行,同样依赖于布局系统单元间各种关联关系的相对稳定性。本文引入热力学中象征系统紊乱度的物理熵概念,根据熵的含义,布局自然发展的过程为在自组织作用下熵值不断增大的过程,即系统紊乱度增加。由于熵值的增大导致布局系统复杂性增加,从而降低了效率,因此需要给出低熵化、引导性的布局约束。基于脆弱性抽象的布局熵模型以物理熵为车间稳健优化度量指标,能很好地满足系统高稳定性、持续改善的要求。
根据文献[18-19]所述,由某种相似粒子组成的系统,N和Es分别表示系统中粒子的数量和其所拥有的能量,系统某一时刻处在微观状态(N,Es)的概率为
(4)
式中,a、b为归一化系数。
由物理熵表达公式可知系统的熵值表达式:
(5)
研究过程中将车间视为一个无序的开放系统,单元设备、物料等视为系统粒子。衡量布局熵的关键在于如何定义概率P,根据物理熵公式的含义及其单调性可知,概率P越大,熵值越小,系统越稳定。考虑车间布局实际情况,将P定义为车间某种状态可能崩溃情况的映射概率。布局鲁棒性能差则无法应对车间机器故障等不确定性因素,柔性程度低则无法及时应对多生产工艺路线更改等扰动因素,两种情况都有可能导致车间停产崩溃。因此将各种引起崩溃的情况综合为鲁棒性与柔性两种,建立概率P与鲁棒性(R)和柔性(F)的映射关系,以布局熵反映车间紊乱度,能够很好地表征布局系统的稳定程度。
对布局层面而言,产品工艺鲁棒性体现在加工距离差异性上。不同产品的工艺路线与加工距离各不相同,保证加工距离的一致性能够保证生产稳定性,即
(6)
s.t.
式中,Lp为产品p经过完整工艺路线的加工距离;wp为产品p的工序集合;I(J)表示第I(J)道工序。
布局柔性体现布局系统自身调节能力,主要影响因素有生产路径、物流量、可变单元数、单元负载量等。布局柔性定义为
(7)
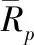
建立概率P与鲁棒性R和柔性F的映射模型:
(8)
(9)
其中,Rmax、Rmin、Fmax、Fmin分别为理论上鲁棒性和柔性的最大值、最小值;考虑到布局实际与概率映射模型,崩溃概率P∈(e-1,1),鲁棒值R越大,则车间稳健性能越好,崩溃概率P1越小;柔性程度越高,则车间容纳性能越好,崩溃概率P2越小。
在式(8)、式(9)基础上建立表征车间布局稳定程度的布局熵模型:
E=e·(P1lnP1+P2lnP2)+1
(10)
由式(10)的单调性可知,崩溃概率越小,熵值E越小,车间稳定性能越好。为了将E映射至(0,1)区间,参考文献[5],取E∈[0.2,0.8],认为在此区间布局系统的熵值合理。
1.3 车间布局多目标优化模型
笔者提出的单位面积布置成本、单位物流成本以及布局熵3个目标之间存在着相互竞争的关系:单位面积布置成本越高,单元分布越紧凑,物流量距越小,工艺路线交叉越频繁,直接引起车间布局熵增加。因此建立多目标优化模型,利用改进的多目标求解算法求解Pareto解集,模型如下:
(11)
(12)
f3=min(e·(P1lnP1+P2lnP2)+1)
(13)
1.4 约束条件
将车间看作一个二维矩形平面,各功能单元为矩形,平面内以车间左下角为原点建立长宽方向的坐标系,如图2所示。因本文编码方式存在边界约束性,因此只需建立位置约束:
(14)

图2 车间坐标示意图Fig.2 Workshop coordinate diagram
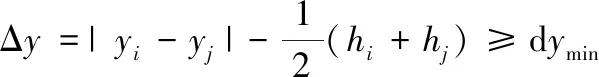
(15)
式中,dxmin、dymin为沿x轴和y轴方向的最小间距,用来保证任何两个单元不会重叠布置。
2 算法设计
针对多目标车间布局问题,提出基于Pareto优化的聚类并行多目标遗传算法(cluster parallel multi-objective genetic algorithms,CPMGAs),在每一代进化过程中得到的当前种群中引入模糊C-均值聚类算法,依据布局模型的多个优化目标将种群分成n类元胞种群,元胞种群存在组内染色体相似度最高、组间染色体差异性最大的特征,该进化过程可以提高Pareto解集分布的多样性与均匀性;提出改进的多元胞差分进化重插入操作,并采用“移民策略”避免算法陷入局部最优[20-21]。提出的算法能够有效地保证整个Pareto曲面解集的均匀分布,保证种群的多样性。改进的多元胞差分进化重插入操作与移民策略能起导向进化作用,保证优质解的有效遗传,提高进化效率。
2.1 CPMGAs基本框架
引入模糊C-均值聚类算法,依据各目标将种群划分为若干元胞种群,并组成环状拓扑结构进行协作进化,以增强种群的导向性进化,基本框架如图3所示。
图3 CPMGAs模型框架Fig.3 Framework model of CPMGAs
2.2 染色体编码策略
根据布局模型,染色体需要包含三类信息:单元坐标、形状和组合分布情况。为避免编码冗长,采用FBS(flexible bay structure)编码方式:每条染色体由单元排序编码与单元分割点编码两部分组成。单元排序编码由n个单元组成,表示车间由左至右,从上至下排列顺序;分割点编码由n-1个0/1二进制编码组成,0表示单元处于同一纵列,1表示单元为某纵列最后单元。
为方便编码与计算,对车间单元和编码环境作如下简化:
(1)研究的单元是包括机器群、通道、缓冲区等组成的综合单元模块,单元面积确定,形状可变。
(2)FBS编码前,总面积的长与宽已知,即各单元填充排布的总区域是确定的,如图4所示,即
LH=SA+SB+SC+SD+SE+SF
其中,L、H为已知单元填充区域的长与宽;SA为单元A的面积,其余解释同SA。

图4 FBS编码方式示意图Fig.4 FBS encoding scheme diagram
FBS编码过程确定了各单元间的相对位置,接下来根据L、H及各单元面积确定精确位置坐标。由FBS编码规则可知,单元A的左下角为直角坐标系原点处,具体求解步骤如下(以图4为例)。
(1) 单元A的宽度已知,即hA=H,长lA=SA/hA,则单元A的坐标(xA,yA)=(SA/(2hA),H/2)。
(2)计算第二列单元坐标。由于lB=lC=lD,SB/lB+SC/lC+SD/lD=H,因此lB=lC=lD=(SB+SC+SD)/H,hB=SBH/(SB+SC+SD),hC=SCH/(SB+SC+SD),hD=SDH/(SB+SC+SD)。则第二列各单元坐标:(xD,yD)=(lA+(SB+SC+SD)/(2H),hD/2),(xC,yC)=(lA+(SB+SC+SD)/(2H),hD+hC/2),(xB,yB)=(lA+(SB+SC+SD)/(2H),hD+hC+hB/2)。
(3)依次计算剩余单元的坐标。
(4)根据式(14)、式(15),排除不符合约束的染色体,如两长度足够小且相邻的单元,其单元间距有可能不满足位置约束。
在FBS编码前提下计算精确位置,能够最大限度地减少不满足间距约束的染色体生成,提高编码的效率与有效性。
2.3 模糊聚类操作
与传统聚类算法对数据的硬划分不同,模糊聚类是依据多个聚类特征的综合隶属度进行聚类,是一种分类界限模糊化处理的软划分[22]。由于布局问题复杂多变,故允许同一布局方案(染色体)同时处于多个分类,避免算法陷入局部最优陷阱。参考GARCIAHERNANDEZ等[8]提出的聚类方法,引入模糊C-均值聚类算法,算法模型如下:
(16)
s.t.
(17)
(18)
(19)
式中,FC为聚类目标函数,用来衡量聚类特征综合相异程度;V为数据个数;K为聚类中心的个数;g为聚类特征类别;z为聚类特征;vr为第r个数据;ch为模糊组h的聚类中心;urh(v)为隶属度函数,表示第r个数据点隶属于第h个聚类中心的程度;vrg为以特征g为分类指标时的第r个数据;chg为以特征g为分类指标时模糊组h的聚类中心;z为聚类特征个数,以单位面积布置成本、单位产品物流成本、布局熵为聚类特征,即z=3;f为大于1的模糊参数,取值为2。
图5为初始种群模糊聚类为若干元胞种群示意图。通过各染色体的单位面积布置成本、单位物流成本以及布局熵的值计算染色体隶属度,并做划分处理,得到的各种群存在内部相似性最大,种群间差异性最大的特点。

图5 初始化种群元胞组合示意图Fig.5 Initialized population cell assembly schematic
2.4 进化算子
选择、交叉、变异的操作过程是同时在各自元胞种群中独立完成的,这三步操作环境相对封闭,既能最大程度地保证各组特征的遗传,也为元胞种群间的协作进化奠定基础。
(1)选择算子。选择过程既要保证各自元胞种群特征的遗传,也需要引导种群向最优Pareto解进化。本文采用锦标赛法,该方法是基于个体的秩与隶属度对父代种群进行选择的。步骤为:①根据个体的支配关系,对种群分层,确定个体的秩,第一层秩为1,依次递增;②选出当前个体的邻居个体,比较邻居个体的秩,秩越小则个体性能越优秀,保留下来;③若与邻居个体的秩相等,则比较它们的种群隶属度,隶属度越大的个体表明与中心个体性能越接近,保留。由①、②、③三步确定出优秀个体。
(2)交叉算子。根据编码方式的特殊性,采用两种不同的交叉算子进行交叉。针对单元排序部分,采用部分映射交叉算子可以有效地避免交叉后设备的重复性。针对单元分割点部分,采用多点交叉算子交换片段。
(3)变异算子。针对单元排序部分,为了避免变异后的单元排序中有重复单元编号,采用单元交换法:任意选取同一染色体两个单元位,交换单元位置。针对单元分割点部分,采用基因位0-1转换法:依据概率任意选择基因位,将0转换为1,将1转换为0。
2.5 多元胞差分重插入操作
为保证子代染色体数量保持不变和种群多样性,每一轮进化完成后需补充若干新个体进入种群池。多元胞差分利用各元胞中个体的距离与方向的优势信息,具有全局并行搜索的优点。具体操作如下。
在第G+1代重插入开始之前,首先从3组元胞种群中各随机选择一个个体作为父代个体,记作f1,i(G)、f2,i(G)、f3,i(G),i=1,2,…,f1,i(G)表示第i次重插入时从第G代种群的第1个元胞中随机选择的父代个体。判断是否存在全局支配解。
(1)如存在全局支配解则将其定义为fbest,变异按下式规则操作:
fi(G+1)=αfbest+(1-α)(f1,i(G)+
F(f2,i(G)-f3,i(G)))
(20)
(2)若不存在全局支配解,则变异按下式规则操作:
fi(G+1)=f1,i(G)+s(f2,i(G)-f3,i(G))
(21)
式(20)表示取父代个体f2,i(G)、f3,i(G)的差值,将其缩放的结果直接加到个体f1,i(G)上获得新个体,再将其与全局支配解进行交叉,获得变异后的个体。α为贪婪因子(α∈(0,1)),α值越大,表示保留全局支配解的基因片段越多;s表示缩放因子,为一个确定的常数,s∈[0,1];fi(G+1)表示第(G+1)代第i个变异个体。式(21)表示取父代个体f2,i(G)、f3,i(G)的差值,将其缩放的结果直接加到父代个体f1,i(G)上获得新个体。
经测试,改进后的多元胞差分重插入操作充分利用了各优势种群的全局非支配解集,确保优势基因的遗传,提高了解的质量。图6为多元胞差分重插入操作示意图。

图6 重插入操作示意图Fig.6 Reinsertion operation schematic
2.6 移民策略
各元胞之间存在最大差异性,且各元胞内均有属于自己的Pareto解,为使这些“精英染色体”得到最大程度的遗传并对种群起到导向进化的作用,需在下一代进化开始之前,进行优秀个体的移民操作。具体如下:随机排列元胞种群并连接组成环状拓扑结构,为元胞间指定某种迁移拓扑,确定个体交换的方式。移民路径如图7所示,图中,k1、k2、k3表示按比例从各组元胞种群中复制的优秀个体数量。
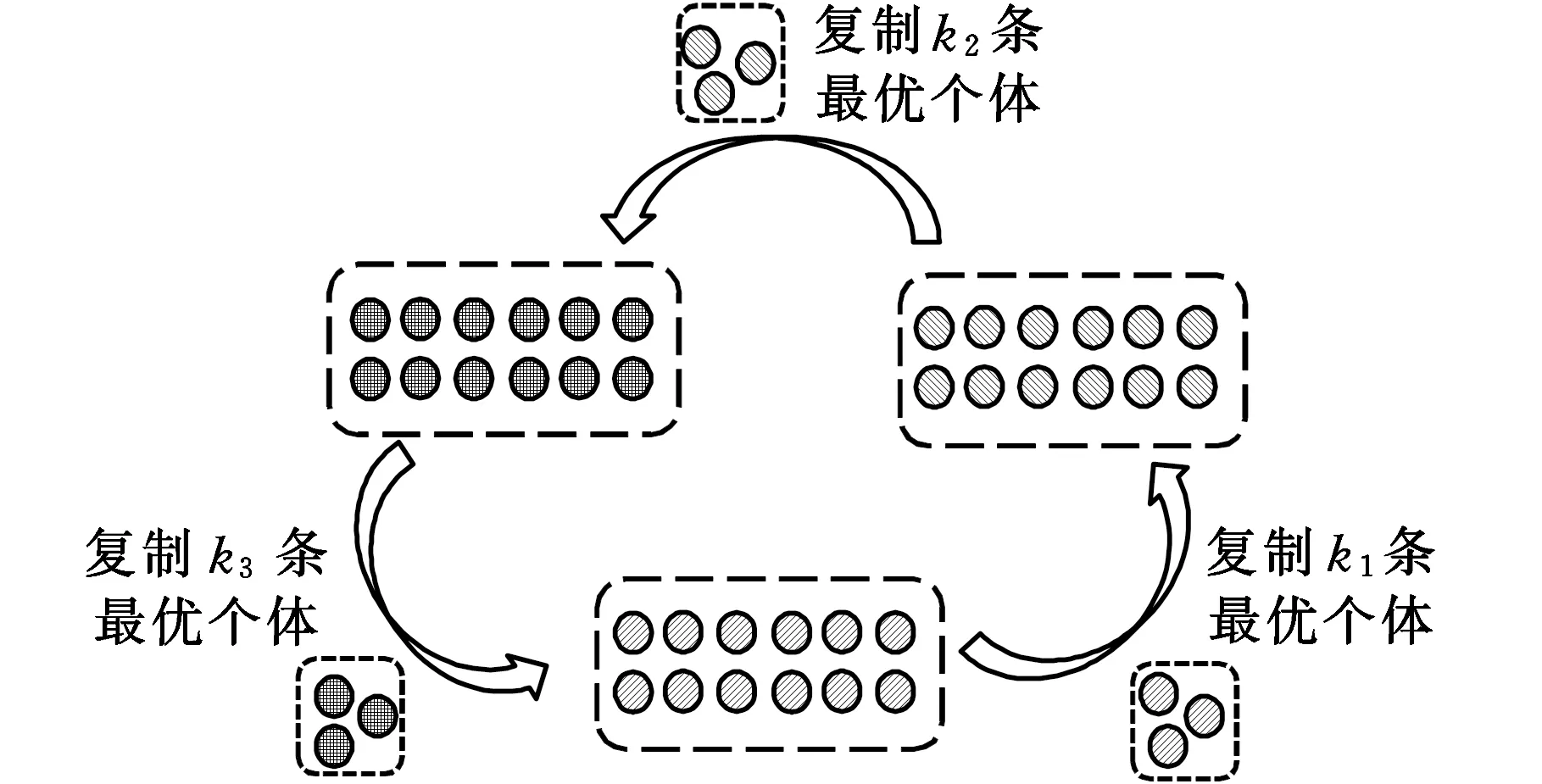
图7 染色体移民示意图Fig.7 Chromosome migration diagram
2.7 循环终止条件
循环执行模糊聚类、选择、交叉、变异、移民等操作,算法迭代niter次或在迭代过程中连续mopt次产生PN条Pareto解集,则进化结束。
3 算法步骤与流程
算法流程如图8所示。
(1)利用FBS编码随机产生一定规模的种群。
(2)计算所有染色体的f1、f2、f3的目标值,运用模糊C-均值聚类算法,对所有染色体聚类,分为PC组种群元胞,文中取PC=3。
(3)各元胞同时进行独立的选择、交叉、变异。
(4)重插入操作。按照多元胞差分操作规则,生成一定数量的新个体平均分配给各元胞。
(5)将各元胞组成环状拓扑结构,对环状邻域种群元胞进行精英个体的移民操作。
(6)如果算法迭代niter次或在迭代过程中连续mopt次产生PN条Pareto解集则结束计算,输出Pareto解集,否则返回步骤(2),进行下一轮进化。

图8 算法流程Fig.8 Algorithm flow
4 算法性能分析与算例验证
为验证本文算法的性能,选用一个多约束、多变量的双目标测试函数ZDT3和一个高维多目标函数DTLZ2[23],分别利用文献[13]的MOPSO、文献[14]的NSGAⅡ以及本文的CPMGAs对上述测试函数进行计算,并分析相同评价体系下三种算法的性能。
4.1 算法性能评价指标
采用分布指标[23]、世代距离和超体积指标对算法性能进行评价[24]。
(1)分布指标TD。分布指标用来衡量获得的Pareto前沿的分布情况,该指标的值越小,表明Pareto前沿分布越均匀,且
(22)

(2)世代距离GD。世代距离用来计算所得的Pareto前沿收敛到最优 Pareto前沿的程度,GD越小,解的收敛性越好,且
(23)
式中,n为近似Pareto前沿中个体的数目;di为第i个解的目标函数构成的向量与Pareto最优前沿之间的最近距离。
(3)超体积。超体积(HV)用来计算获得的Pareto前沿在目标空间所覆盖的体积。超体积越大,说明获得的Pareto前沿的多样性、收敛性越好,有
(24)
在三维目标空间中,Q表示所有Pareto解的个数,Vi是由参考点W与解i的目标向量作为对角点所形成的长方体的体积。为方便处理,将最差的分目标值构成的一个向量作为参考点W,合并所有Vi得到HV。
4.2 算法测试结果及性能分析
ZDT3与DTLZ2基准测试函数如表1所示。
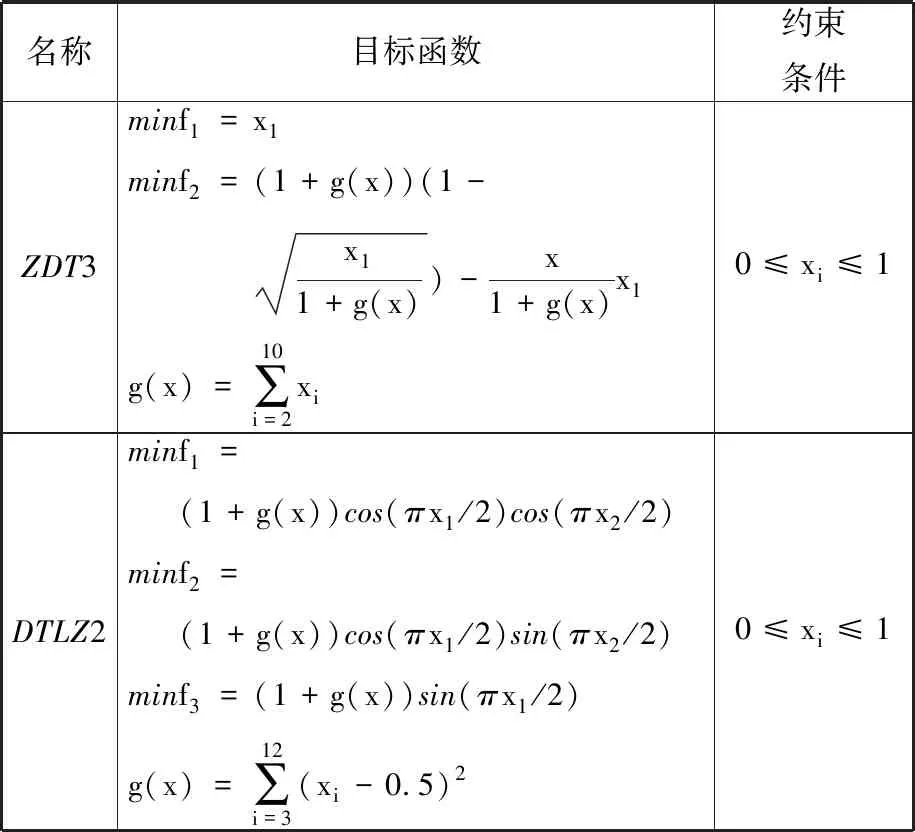
表1 ZDT3与DTLZ2基准测试函数Tab.1 ZDT3 and DTLZ2 benchmark functions
NSGA Ⅱ、MPSO、CPMGAs算法参数设置如下:均采用实数编码,多项式变异;采用模拟二进制交叉;MPSO算法的学习因子均取0.8;CPMGAs的元胞种群分组取PC=3,移民率为各元胞的5%;交叉概率取0.8,变异概率取0.3,种群规模取100,进化代数为50。三种算法对测试函数ZDT3和DTLZ2均进行20次测试,表2表示三种性能指标统计结果均值。图9、图10分别表示测试函数ZDT3和DTLZ2的Pareto解前沿分布。

表2 算法有效性分析表Tab.2 Algorithm validity analysis table

(a)NSGAⅡ算法Pareto解集前沿

(b)MPSO算法Pareto解集前沿
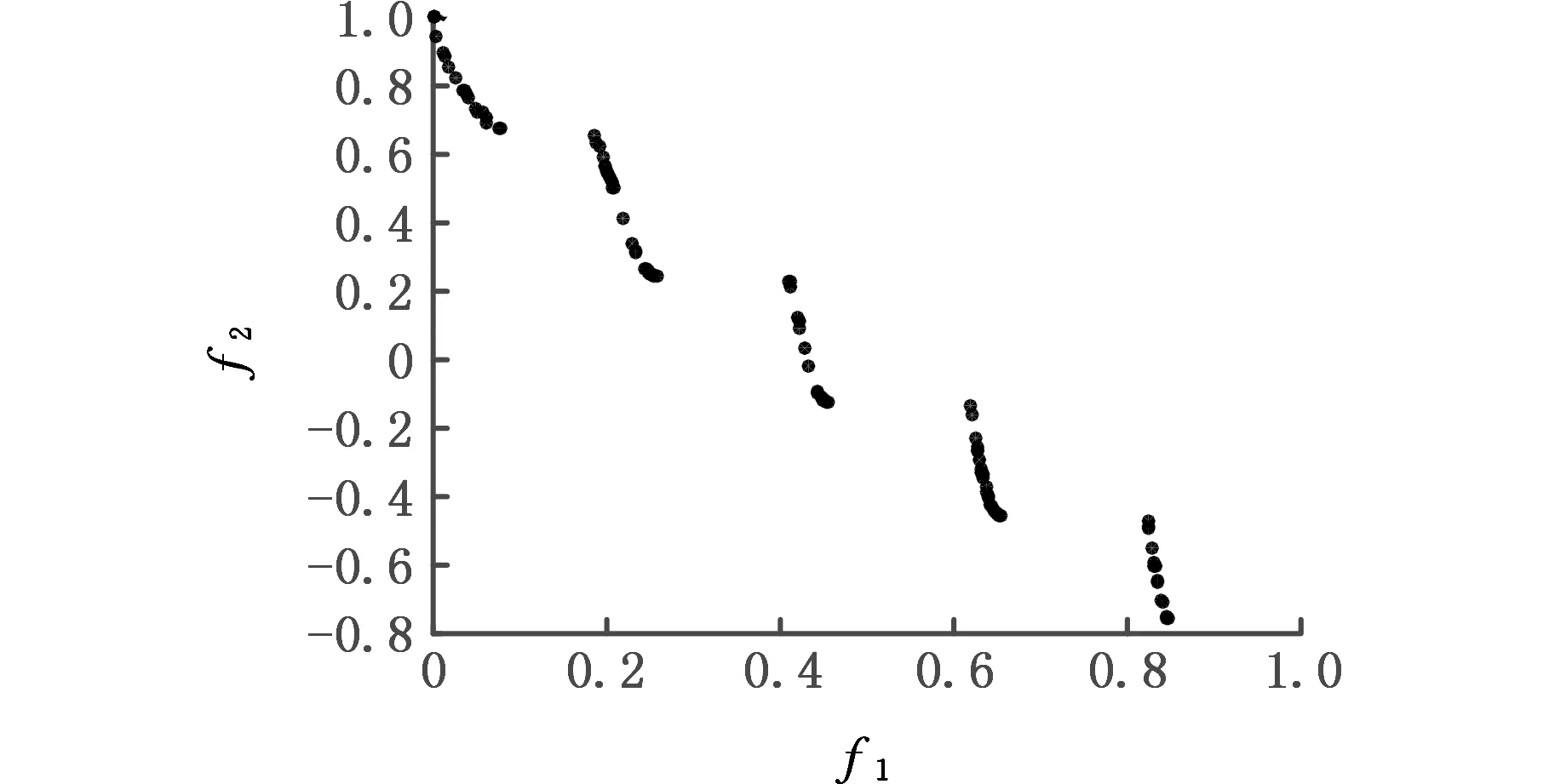
(c)CPMGAs算法Pareto解集前沿图9 NSGAⅡ、MPSO、CPMGAs算法在ZDT3上的Pareto前沿对比图Fig.9 Pareto frontier contrast diagram of NSGA Ⅱ、 MPSO、CPMGAs algorithm on ZDT3
(a)NSGAⅡ算法Pareto解集前沿

(b)MPSO算法Pareto解集前沿

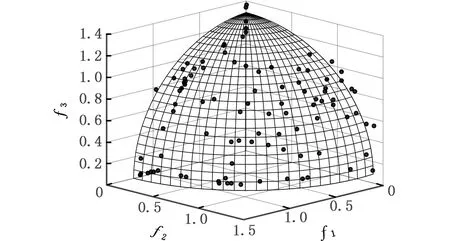
(c)CPMGAs算法Pareto解集前沿图10 NSGAⅡ、MPSO、CPMGAs算法在DTLZ2上的Pareto前沿对比图Fig.10 Pareto frontier contrast diagram of NSGA Ⅱ、MPSO、CPMGAs algorithm on DTLZ2
由图9、图10定性分析三种算法性能的对比结果可知:NSGAⅡ算法的收敛性最差,解集多样性好,但分布不均;MPSO算法的收敛性较好且解集的分布均匀性能好;本文提出的CPMGAs的收敛性比NSGAⅡ算法好,与MPSO算法具有相同的收敛性,但解集的均匀分布性与覆盖广度较MPSO算法要好。
表2记录了三种算法在测试函数ZDT3和DTLZ2上的三种性能指标。由指标性能的含义可知,在求解ZDT3和DTLZ2函数时,CPMGAs算法在收敛性(GD)和分布均匀性(TD)上比其他两种算法更优,虽然在求解ZDT3函数上,MPSO算法也表现了较好的收敛性(GD),但CPMGAs的标准差更小,说明在收敛性上表现更加稳定。在分布均匀性(TD)上,MPSO算法在ZDT3函数上表现最佳,而CPMGAs算法在DTLZ2函数上表现最佳,说明二者在解集分布均匀性上均有良好性能但不够稳定。CPMGAs算法在覆盖范围(HV)上表现出最佳性能,是因为在模糊聚类操作中,各元胞种群间存在最大差异性,且多元胞差分进化重插入与移民操作保证了种群的多样性与分布均匀性。因此本文的CPMGAs算法总体上能够满足求解多目标、多维度非线性问题,且具有良好的性能。
4.3 算例验证
为进一步验证算法的有效性,本文选用国际上公布的旅行商问题(traveling salesman problem,TSP)标准测试库(TSPLIB)中的8组算例(oliver30,eil51,rand100,rand300,kroab100,kroac100,krobc100,kroab200)进行算例验证,并与文献[25]提出的混合遗传算法(hybrid genetic algorithm,HGA)进行结果的对比与验证。
参考文献[25],算例中的目标1为最小化总距离,目标2为最小化总成本。针对算例oliver30、eil51、rand100、rand300,与目标1相关任意两点坐标值由标准库所给,与目标2相关的任意两点成本值随机生成[25]。采用超体积(HV)、计算时间(t)、相对误差(e)三个指标验证本文算法解的质量。指标e的定义如下:
其中,f1为只考虑单目标TSP问题时目标1的最优值(由TSPLIB给出),f2为考虑双目标TSP问题时目标1的最优值,由算法计算所得。测试过程中,HGA算法的参数设置与文献[25]一致,本文算法参数与4.1.2节一致。种群规模取50,针对算例oliver30、eil50,迭代次数取200,其余算例取500。每个算例各单独测试10次,取指标均值,测试结果如表3所示。
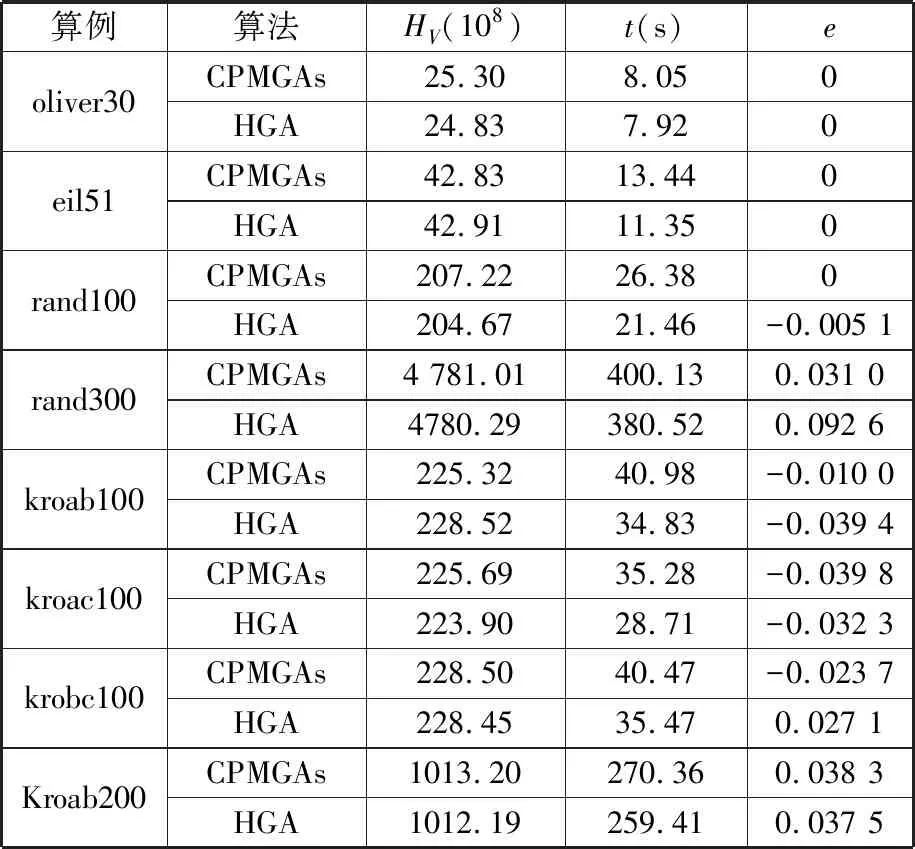
表3 算例验证结果对比表Tab.3 Examples comparison of verification results
由表3可知,本文算法CPMGAs在超体积(HV)指标上的值比文献[25]的HGA更高,说明解的空间范围更广,验证了本文算法在计算结果的多样性与收敛性方面更好;在计算时间上,因为存在聚类、移民等多步操作,CPMGAs所耗费的计算时间更长。在相对误差e上,CPMGAs的值普遍更小,进一步论证了本文算法在多样性与收敛性上具有一定的优势。因此CPMGAs算法以相对较长的计算时长为代价,换来计算多样性与收敛性上的相对优势,能较好地满足离散组合优化问题的需求。
5 企业应用分析
将多目标布局模型应用于企业布局中,研究模型的实用性。 A公司目前的生产装配车间仍是以大规模重复的生产作业方式来满足客户的订单需求。车间的总面积为100×100 m2,包括15个功能单元区域。车间物流量关系如表4所示,车间功能单元约束如表5所示,其中,S1、S2、…、S5表示5类产品编号。Y表示Yes,N表示No。车间布局现状如图11所示,其中,F1、F2、…、F5表示单元内的设备编号。

表4 车间单元间物流量关系Tab.4 Relationship of material flow among units in workshop (104元·件/m)
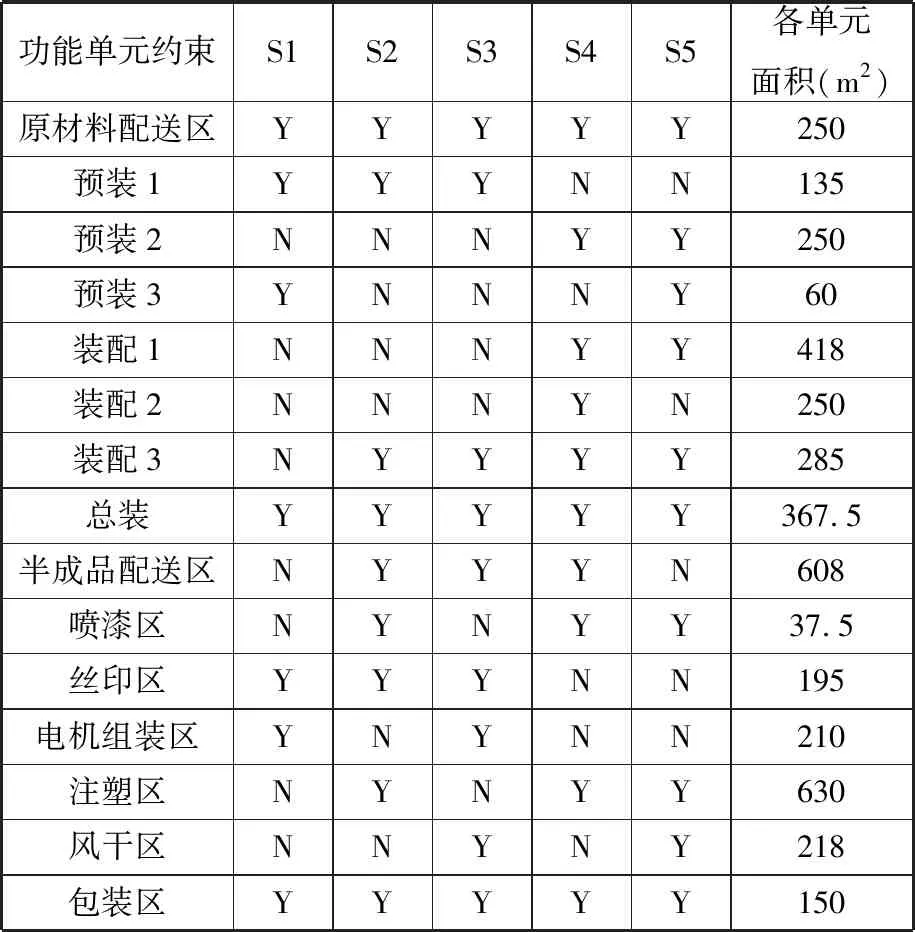
表5 产品功能单元约束Tab.6 The constraint of functional unit
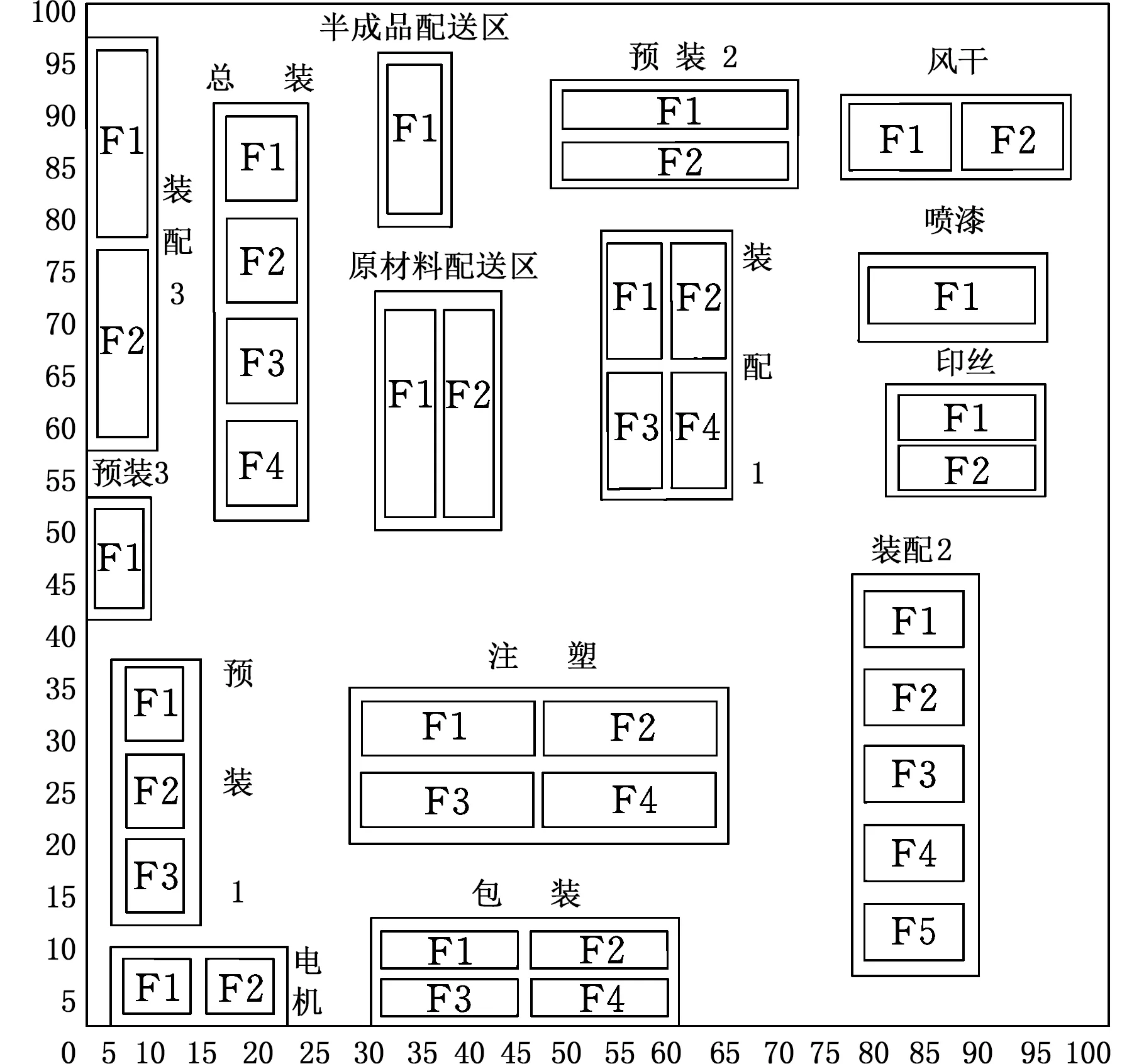
图11 车间布局现状图Fig.11 Workshop layout map
利用本文模型与算法进行布局优化,参数选取:种群规模M=1 000,聚类数p=3,交叉概率Pc=0.75,变异概率Pm=0.001,移民率Y=5%,课题组在企业实地调研后,取ηopt=4/3,ηmax=5,迭代次数niter=100,用MATLAB2010a仿真计算。由于布局问题的复杂性,以算法产生的Pareto解作为最优解集,如图12所示。
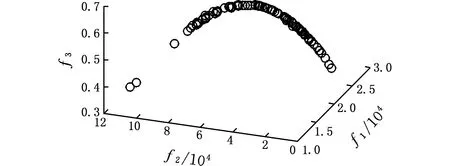
图12 布局多目标Pareto解集前沿Fig.12 Layout multi-objective pareto solution frontier
因进化过程中的低熵化引导,所产生的布局方案的布局熵均在[0.2,0.8]的合理区间范围内,说明布局方案均有较高的稳定性。图13表示子目标f1与f2的解集前沿,可以看出,左上方的解具有较低的单元布置成本与较高的物流成本;右下角的解具有较高的单元布置成本与较低的物流成本。目标空间的解集能为决策者根据自己偏好提供有效布局解。解码,得到部分布局解。
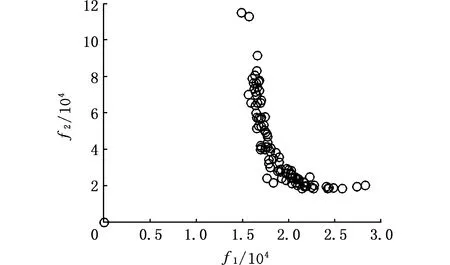
图13 布局子目标f1与f2的Pareto解集前沿Fig.13 The Pareto solution frontier of layout subtargets f1 and f2
表6提供了部分Pareto解,选择序号1为实例布局解进行解码,考虑车间运输工具等原因,规定车间长度方向、宽度方向最小间距分别是4.5 m和2.5 m,边界间距均为5 m,解码得到实际布局如图14所示。

表6 Pareto解集Tab.6 Pareto solution sets

图14 优化后的车间实际布局Fig.14 Optimized workshop layout
6 结语
随着制造业的发展,企业不仅需要面对复杂多样的需求波动,也需要低成本、高稳健发展以满足可持续性。提出单位面积布置成本、单位产品物流成本与布局熵为目标的车间布局优化模型,设计聚类并行多目标遗传算法,进行算例论证和实例验证,有效降低了布置成本、物流成本,提高了布局稳定性,表明算法和模型的有效性和可靠性。但本文的布局过程中并没有与产品的动态调度相结合,同时也假设了单元的规则性,在一定程度上限制了应用,在今后研究中,可以注重这一方面的研究。
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
今日农业(2022年15期)2022-09-20
纺织科学研究(2021年6期)2021-07-15
湖南电力(2021年1期)2021-04-13
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
中学生物学(2018年8期)2018-03-01
北京测绘(2016年2期)2016-01-24
创业家(2015年1期)2015-02-27
汽车零部件(2015年5期)2015-01-03
