
一种基于CAD图纸的管网建模开发方法
2019-08-17 07:45孙国胜高金良王晶惠张昭君郑成志
供水技术 2019年2期
阮 婷, 孙国胜, 赵 焱, 高金良, 王晶惠, 张昭君, 郑成志
(1.广东粤港供水有限公司, 广东 深圳 518000; 2.广东粤海水务股份有限公司, 广东 深圳 518000; 3.哈尔滨工业大学, 黑龙江 哈尔滨 150090 )
给水管网系统建模是为模拟管网系统动态实时运行工况而建立数学模型的过程,通过管网模型可以掌握已建管网的实时运行状况,发现存在的问题。同时,可预测管网维护和改造对整个系统的影响,从而为合理地制定近、远期管网改造和扩建计划提供科学依据。
1 管网建模流程
1.1 基础资料收集
给水管网建模基础资料的收集主要包括管网、水厂和用户3个方面,其中管网资料包括主干管、配水管及管道附件情况、管道埋深、铺设年代、管材等信息;水厂资料包括水厂设计及运行资料、二泵房基础资料;用户资料包括用户水量、用户分类、大用户位置及水量等。
1.2 管网模型的初步建立
1.2.1 建立步骤
管网模型的初步建立分为4个步骤:建立管网模型数据库、拓扑结构检查、管网节点用水量分配和管网初步平差。
一般情况下,管网模型数据库可根据所使用的建模软件类型,应用3种基本数据输入程序或其中几种组合。常用的数据库建立方法包括:
① 手动输入数据,这是一项比较繁琐耗时的工作,尤其对于规模比较大的系统。
② 在不同文件间转换数据,某些情况下需要手动编辑,特定情况时必须考虑数据来源和类型,以确定最合适的数据转换方法。
③ 利用各种文件建立模型,直接将GIS、水费数据库和其他来源的数据导入模型。
1.2.2 采用CAD图纸建立数据库
对于某些基础资料欠缺的供水企业,并无供水管网GIS系统和其他可以与建模软件相互转换的管网数据,仅有CAD图纸。手动输入管网资料工作繁琐,且容易出错。因此,基于CAD图纸通过软件处理建立管网模型数据库,在无基础资料的工程中显得非常必要,其具体处理方法如下:利用dxf2epa软件[2]将CAD图的管段导入到EPANET管网建模中,自动形成管道长度和编号;图纸中的水塔、水泵和阀门等可导入为连接节点或者管道,随后被转换或简单加入。但是这种处理方法会因为CAD图纸中管段位置距离较近、管段长度太短、管段未定义节点等原因,导致管段不易被dxf2epa软件识别,后续需花费大量时间来检查导入EPANET中管网的拓扑结构,例如管网孤立点及孤立管线、重叠管线、管网中存在相同端点的管线、管线的连通性等。
在管网形成数据库的过程中,为了避免采用dxf2epa软件形成数据库的缺点,在进行管网落图过程中,可采用专业管网设计平差的鸿业软件。将管网信息落入到该软件中,并对管网进行识别标高、重合节点检查、节点与管段的连接情况检查、节点流量初次分配等步骤,形成软件能够平差的管网图。平差结果导出为Excel格式的文件,但管网节点的坐标不能同时导出,需另外重新导出。此后,将Excel格式的文件转换为EPANET软件能识别的txt格式的文件,可建立管网模型的基本数据库,且不会改变管网的拓扑结构,其流程见图1。
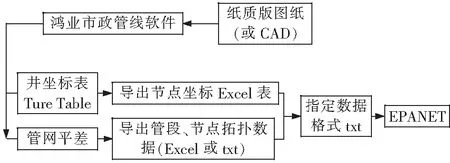
图1 管网模型数据库建立的流程Fig.1 Process of establishing pipeline network model database
建立管网模型数据库后,对管网拓扑结构进行检查、完善,并对水厂、大用户和监测点等落图、赋属性。然后确定管网建模基准日,对管网进行水量分配和模拟平差计算,平差计算通过或没有平差错误提示则说明管网模型基础数据库已建立。下一步需对管网模型进行校核,这是管网建模中的重要环节,未经校核的管网模型难以应用于实际生产中。
1.3 模型校核
管网校核一般采用4次预校核(主要为静态校核)和最后精确校核(主要为动态校核),具体校核流程如表1所示。
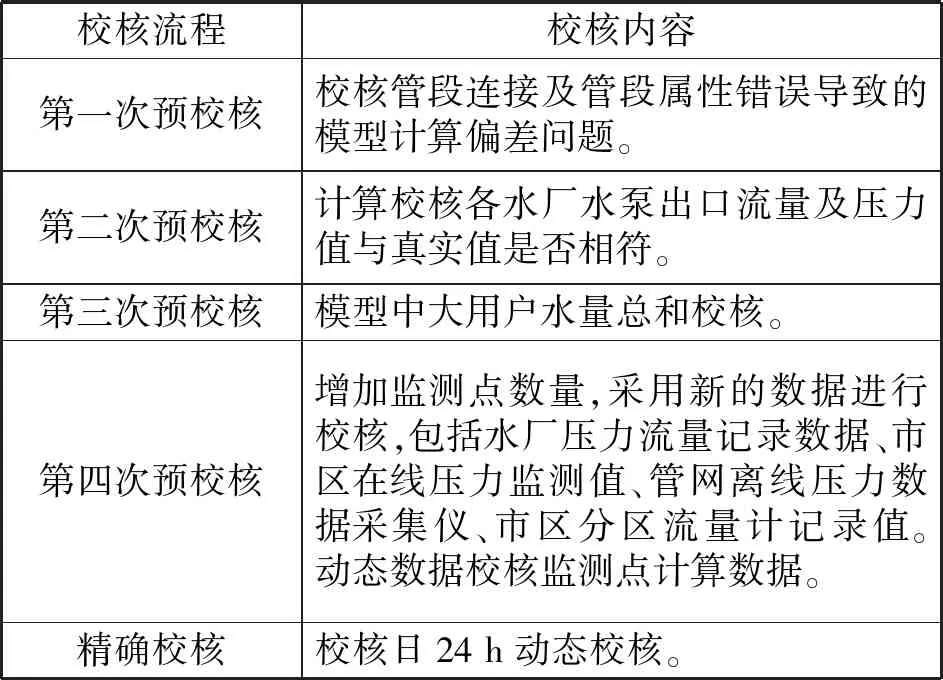
表1 供水管网模型校核流程Tab.1 Checking process of water supply network model
模型校核完毕后,还应对模型校核结果从时间和误差种类两个角度进行分析。时间角度分析,即对各测压点以时间为主要目标,分析不同时刻误差的大小,进而判断动态鲁棒性;误差种类角度分析,即分析测压点误差种类,进而避免异常测压点对整体计算结果的干扰。
2 应用实例
南方地区BY县供水范围为80 km2,DN100以上管网长度为410 km,供水能力约为9×104m3/d,供水用户9万余户,管网基础资料较差,仅有CAD图纸。
2.1 管网模型初步建立
在BY县仅有部分CAD图纸的情况下完善CAD图纸,形成管网模型数据库。形成的管网基础数据库中有节点2103个、管段2172条、阀门1343个、消防栓805个,如图2所示。

图2 管网模型初步建模效果Fig.2 Preliminary modeling effect of pipe network model
2.2 管网模型的校核
形成管网模型数据库后,对管网拓扑结构进行检查。经过数据整理筛选,选取2013年11月30日为建模基准日,对模型进行校核。
2.2.1 第一次预校核
针对该项目将管网图分成29张A0+图纸进行现场实地校核。逐张图纸校核管段的连接关系、管径、管材、管长,同时尽可能统计、核实管段的敷设年代。经核实发现有误管段221条,占总管道的4%以上。
2.2.2 第二次预校核
经过数据整理筛选,选取2013年11月30日最高时11:00和最低时2:00进行静态校核,在静态校核的基础上对水厂水泵出口流量和压力值进行24 h逐时动态校核。在静态校核过程中需校核的静态数据包括:各水厂的清水池池底标高、出厂压力监测点地面标高、水泵特性曲线。需校核的动态数据包括:对应最高时和最低时的水泵开停状况、变频水泵开启度、清水池水位、出厂流量及出厂压力。
在校核过程中,水泵特性曲线、水泵开停状况和变频水泵开启度的影响相互关联,应通过经验与数据分析择优选择,尽可能缩小出厂流量、压力的误差。模型24 h动态校核与静态校核类似,一般24 h动态校核不需要调整静态数据,主要对动态数据进行调整,以减小出厂流量、压力误差。
2.2.3 第三次预校核
该模型校核中,将每月用水量达到或超过1 000 m3的用水户定义为大用户,经用水量数据收集与分析得到BY县总共有142个大用户。该次校核与调整的参数有:校核大用户在建模月(2013年11月)的用水量、大用户落图位置、用户水表口径、用户用水类别、用户用水24 h变化规律曲线等。
经校核得出大用户落图位置有误的大用户有28户,用户水表口径有误的用户有5户。用户用水类别和用户用水24 h变化规律曲线对后续校核影响较大,用户用水类别根据大用户情况分为商服、居民、工业、机关、医院、学校、洗浴、区域供水及其他共9个类别。根据管网远传水表数据和其他城市已有的24 h变化规律曲线,分析形成BY县管网建模用户用水24 h变化规律曲线,如图3所示。
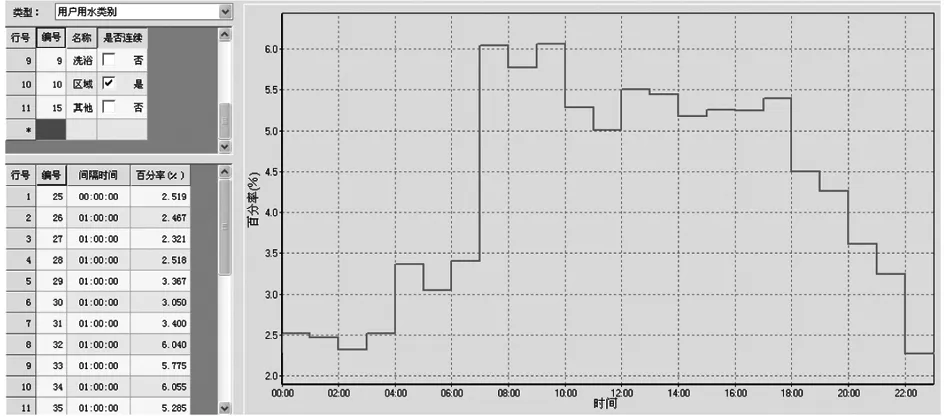
图3 大用户24 h用水量变化Fig.3 Change of water consumption of large consumer in 24 hours
2.2.4 第四次预校核
该模型校核中包括28个在线压力监测点和21个流量监测点。流量监测点的校核是将模型基准日的24 h流量数据作为管段流量,并将该管段以及与其相连的管段作为一个独立区域,建模软件自动分配独立区域内的管网节点流量,通过该种方法处理可实现流量监测点无误差校核。
在线压力监测点校核分为静态校核和动态校核,本次校核是对在线压力监测点进行静态校核,选取最高时11:00和最低时2:00进行校核。压力监测点静态校核需要核实与调整的参数有:压力监测点地面标高、节点用水量、管段粗糙系数C值[1]。节点用水量的调整可通过用户用水量变化曲线来调整,管段粗糙系数C值的调整会影响所有与其相连管段的水头损失,因此需注意调整某条管段的C值后对其他相连管段上测压点压力的影响。
2.2.5 精确校核
校核管网中的压力监测点,校核基准日24 h压力监测值与真实值是否相符,即压力监测点24 h动态校核。该校核中调整的主要参数与第四次预校核调整的参数类似。但本次校核需要保证测压点24 h压力监测值尽可能与真实值相符,某个时刻节点用水量调整同时会影响其他时刻用水量;某个时刻某条管段粗糙系数C的调整会影响其他时刻与之相连的管段的水头损失。每条管段都有其管段粗糙系数C,校核中具体选择调整哪条管段,需要综合考虑和多次尝试,这一系列因素增加了模型校核的复杂度。该次校核以调整管段粗糙系数C值为主,在一定情况下适当调整节点用水量,通过无数次反复调整与模拟,达到模型校核要求。
2.2.6 模型校核结果分析
首先以2013年11月30日11点作为模型校核基准点,调整模型各参数。然后以该日数据进行24 h动态校核,共有26个测压点参与校核,管网压力校核模型校核结果如图4所示。

图4 测压点24 h计算值与实测值误差分布情况Fig.4 Distribution of error of calculated value and measured value of pressure point in 24 h
分析可知:全天98%以上的整点时刻下测压点计算误差值满足要求,其中包括管网最高时11:00和最低时2:00两个特征点。关键时刻压力计算值误差较小,证明24 h压力计算鲁棒性较强[3-4],符合管网压力变化总趋势。
3 结语
① 采用dxf2epa软件将CAD图纸管段信息导入至EPANET建模软件中,会因为CAD图纸中管段位置距离较近、长度太短、无定义节点等问题,导致管段不易被dxf2epa软件识别,后续需投入大量时间来检查管网的拓扑结构。
② 采用鸿业软件并经过一系列步骤,可将CAD图纸处理成Epanet软件可识别的模型数据库,且不会破坏管网的拓扑结构。
③ 通过对CAD图纸进行处理并建立BY县管网模型,采用26个测压点数据进行全天24 h数据校核,98%以上的监测点数据误差均在±2 m之内,模型鲁棒性较强,符合管网压力变化总趋势。
猜你喜欢
设备管理与维修(2022年19期)2023-01-03
大电机技术(2022年5期)2022-11-17
同济大学学报(自然科学版)(2022年3期)2022-03-18
中国交通信息化(2020年12期)2020-02-06
中国交通信息化(2019年7期)2019-10-08
船舶标准化工程师(2019年4期)2019-07-24
能源(2018年8期)2018-09-21
能源(2018年8期)2018-09-21
能源(2018年8期)2018-09-21
中国公路(2017年8期)2017-07-21
