
美沙酮维持治疗剂量的分类探索
2019-08-17 02:03唐逸云王永彬钟晓妮
中国药物滥用防治杂志 2019年4期
唐逸云,王永彬,钟晓妮
(重庆医科大学公共卫生与管理学院,重庆400016)
面对药物滥用,许多国家选择美沙酮维持治疗(methadone maintenance treatment, MMT)作为主要的戒毒方法[1]。数十年的临床经验表明,美沙酮维持治疗时间是患者康复的最重要原因,维持时间越短,复发越容易,愈合效果越差[2]。
根据西安市的调查结果可知,美沙酮维持治疗药物的剂量应该个性化,以保证治疗效果的同时,也要减少治疗后的不良反应[3]。根据纽约的一项研究,低剂量美沙酮维持治疗中的艾滋病发病率高于服用高剂量美沙酮的患者[3]。总之,根据个体患者的病情,可以探索适当的美沙酮维持治疗剂量以达到所需的治疗效果[3]。
1 对象与方法
1.1 研究对象
选取贵州省贵阳市某个美沙酮维持治疗试点的美沙酮患者从2015年1月至2017年3月的服药记录以及基线记录等,重新设置与定义变量,保留缺失值纪录(得到407个患者);之后,筛选服药次数大于10次(维持期)的患者[4]。同时,有文献认为大于180天的患者维持剂量较为有代表性,并且本研究中服药次数的平均数为183次,综合专业和数据特征的考虑,因此筛选服药次数大于183次的患者[5],得到182人。
1.2 分析方法
患者的服药剂量数据选择患者初始剂量,末次剂量,还有患者服药剂量的中位数和四分位间距来代表数据的集中趋势和离散趋势;之后对这四个变量进行K-means聚类,根据聚类图可视化可以明显辨别出异常点,异常点为13例,删除异常点后得到169例,由于患者的特殊性导致随访数据部分缺失值较多,缺失值为69例,删除缺失值后得到100人数据完整的样本。
探索不同服药剂量类别人群个体特征。不同剂量的使用描述性统计分析和卡方分析,方差分析和其他工具对人口学基本统计数据进行基本统计分析,并探讨维持治疗阶段的剂量使用现状及剂量相关因素。使用R软件建立用聚类得出的结果为类标号,来建立分类模型,决策树模型构建步骤如下:
(一)数据准备,变量的筛选
将经过预处理的数据集读入。选入建模的变量如下:性别,工作状况,民族,婚姻状况,文化程度,年龄,患HCV情况,持续吸毒时间,是否注射过毒品, 吸毒方式,是否戒过毒, 是否共用过注射器,是否有过性行为,居住状况,自我感觉与家人的关系,和吸毒朋友交往的频率,生活费用主要来源,平均每天毒品花费,参加治疗的途径,来门诊的交通方式,来门诊参加治疗所需时间。
(二)随机生成训练集和测试集
采用保持的方法,给定数据集随机地划分为两个独立的集合,即抽取三分之一的训练集中为测试集(testset),剩下的三分之二是训练集(trainset),用于构建决策树模型。使用训练集导出分类法,其准确率用测试集评估[7]。
(三)参数的调整并可视化决策树结果
将rpart函数的参数minsplit调为10,xval调为50,cp调为 0.001。
2 结果和分析
2.1 维持治疗剂量分类探索结果
为了发现什么是合适的剂量分类,使用 K-means法聚类后采用轮廓系数法[6]并可视化结果,如图1所示。结果表明轮廓系数为2时最大。因此,患者分为两类最佳。

图1 用轮廓系数法可视化的聚类结果
表1显示了低剂量组的起始剂量平均为48.29,终末剂量平均为49.24,剂量中位数平均为51.01,剂量四分位间距平均为5.46;高剂量组的起始剂量平均为73.61,终末剂量平均为72.89,剂量中位数平均为74.33,剂量四分位间距平均为8.25;两类各阶段标准差接近,离散程度大致相同。
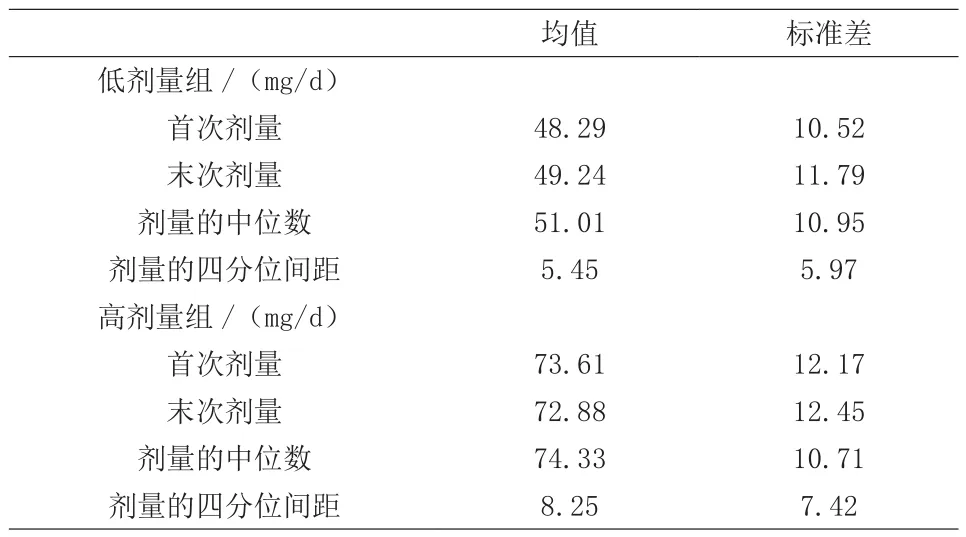
表1 聚类结果的类中心均值与标准差
2.2 决策树分类模型结果
由图2可知,决策树图的每个节点显示了三条信息:第1行是预测的目标分类值,第2行是该分类值的百分比(概率),第3行是该类例数占全部例数的比例。比如根节点(最上面的那个矩形)表示目标分类是第二类,百分比是0.58,占全部数据的比例是100%。再如第3行左面的结点:目标分类是第一类,百分比是0.41,占全部数据量的56%。例如,新来一位患者时,在不知道任何条件的情况下,我们将他分为第二类的概率为58%,然后附加关于居住状况的信息,如果他居住状况为1(与家人/亲属),那么我们就有更小的概率51%将他分为第二类。如果他居住状况不为1,那么他被分为第二类的概率则上升为92%。下面的以此类推。然后我们再根据cp图,对决策树进行剪枝,设定cp值为0.007,剪枝后决策树并无差别。最后保留在决策树中的特征为居住状况、吸毒方式、工作状况、来门诊所花费的时间、吸毒持续年龄、患HCV情况。

图2 调参后决策树可视化结果
建好新的决策树后,将图2的结果进行回代测试。由表2可知训练集回代正确率为84.9%。再进行测试集的回代,由表3可知准确率为66.7%。

表2 决策树训练集混淆矩阵

表3 决策树测试集混淆矩阵
3 讨论
由于美沙酮维持期治疗剂量的用药指导并没有规范化,目前仍然是基于经验规定的。本文基于患者维持期数据,把患者分为了高剂量类别和低剂量类别两类。低剂量类别指维持期剂量≤51mg/d,高剂量类型指维持期剂量≥74.3mg/d。与其他研究者相较而言,李杏莉和谢小虎以60mg/d作为高低剂量的分界点[8-9],在钟玉宇的研究中是以50mg/d天作为高低剂量的分界点,>50mg/d为高剂量[10]。由于美沙酮维持期治疗剂量的用药指导并没有规范化,目前仍然是基于经验规定的。因此研究者普遍都采用的是50~69mg来作为高剂量的临界点,分类之后探索以此临界点为标准,两类患者的差异性。因此本研究旨在通过对美沙酮维持治疗患者服药剂量聚类,探索不同服药剂量类别人群个体特征,进而达到基于患者的个体状况,精准化给与所需治疗效果的美沙酮维持治疗剂量的目的,为用药管理提供数据支持。
然后建立分类模型,这种通过构建决策树的方法,对于判别患者所属维持期剂量类别是十分有效的,可以实现患者个性化治疗,当患者的基线数据以及其他既往数据输入模型时,就可以产生对应的规则,并且自动判别患者所属的维持期剂量趋势类别。那么对于患者,在实现精准给药,使之保持在组中,从而提高维持期治疗效果是有重大意义的。对于门诊的管理来说,可以更好的修订给药指南,而且在日常管理中可以预先判断患者的剂量趋势,杜绝患者包药的可能性,从而杜绝的美沙酮流入黑市的可能性。本文的创新之处在于整体的数据处理思路,基于系统中已有的数据,去探索合适的分类类别,再运用决策树模型对患者进行相应的分类判别,从而达到精准化治疗剂量的目的。但是依旧有很多不足之处,本文的样本量较小,建议之后有兴趣的研究者可以扩大样本量进行研究,进一步挖掘确认纳入决策树的特征。除此之外剂量分类类标号不够个性化,只分出了高低两类,这主要也是受限于样本量较小。往后的研究者可以在扩大样本的基础上继续进行研究。
总而言之随着美沙酮剂量的提高以及个性化治疗剂量方案的出现,会提高美沙酮患者对美沙酮的依从性,从而使患者对于生活更有自信,更加乐观和健康。对于整个社会的稳定、和谐也具有重要的意义。
猜你喜欢
中老年保健(2022年3期)2022-08-24
中老年保健(2021年5期)2021-12-02
陶瓷学报(2021年4期)2021-10-14
祝您健康(2020年10期)2020-10-12
少儿画王(3-6岁)(2020年4期)2020-09-13
保健医苑(2020年1期)2020-07-27
电子制作(2018年16期)2018-09-26
科学与财富(2016年32期)2017-03-04
电子制作(2017年24期)2017-02-02
决策与信息·下旬刊(2013年1期)2013-03-11
