
天气雷达体扫数据的G P U并行处理
2019-08-15 02:00谢千里朱伟伟
装备制造技术 2019年6期
谢千里,林 光,朱伟伟
(中国民用航空中南地区空中交通管理局,广东 广州510403)
0 引言
天气雷达对于气象预报的作用极其重要,不可替代。随着我国天气雷达组网建设,全国大部分地区基本完成覆盖,目前全国气象局的新一代天气雷达数量已达二百多部,民航空管和机场的天气雷达也有一百多部,对如此多数量的雷达数据进行处理,对计算机的运算性能要求越来越高。CPU擅长逻辑控制,串行的运算和具有复杂计算步骤的处理。而GPU则擅长大吞吐量、大规模、简单运算的并发计算。天气雷达基数据解析处理的特点是数据量大,计算密集,重复量大,但是逻辑计算简单,所以非常适合用GPU进行并行计算。本文提出一种使用GPU来代替传统的CPU进行天气雷达基数据的解析运算的方法,大大提高了数据的处理速度。
1 天气雷达体扫数据的结构
如1所示,天气雷达体扫数据一般由5-14个仰角层组成,每层一般由360条由中心向四周辐射的径向数据条组成,每条径向数据由从中心到边沿顺序排序的基本单元数据组成。体扫基数据所覆盖的空间是一个很扁的倒圆锥体,但是数据是离散的,在这个锥体中存在大量数据空隙。并且数据以极坐标方式排列,对这些数据进行统计和图形化显示,必须变换为直角坐标系,并对空隙进行插值填充,以得到一个栅格状的类似魔方的立体数据。

图1 天气雷达体扫数据结构
显然,数据中所有点的计算都可以独立进行,并不依赖于其它点处理的结果。故其运算适合进行并行分解。
2 英伟达G P U的硬件结构
如图2所示,一个GPU由若干个SM(流多处理器)构成,每个SM由若干个SP(流处理器,也称核心)组成,每个SM中的SP共用一个寄存器文件(高速寄存器),以及一个共享内存,SP由线程束调度器进行线程调度,全局内存(即显存)为所有SP所共用。

图2 英伟达G P U的硬件架构
3 英伟达C U D A程序结构
CUDA的操作包含3个基本步骤[1]:
(1)CPU在计算机内存上准备好数据,在GPU上分配显存,并把数据从内存传送到GPU显存。
(2)CPU启动GPU核函数,GPU创建并发线程,运行核函数,处理显存数据。
(3)CPU把数据从GPU显存取回到内存中,并释放GPU显存。

图3 英伟达C U D A线程结构
CUDA程序分为host和device两部分,结构如图3所示,host运行于CPU端,device运行于GPU端。CPU通过核函数(kernel)启动GPU多线程运算。每次核函数的调用使用一个线程网格(grid),一个线程网格由若干个线程块(block)组成,每个线程块由若干个线程(thread)组成。
4 计算任务
如图4所示,计算任务是要把有很多空隙的倒圆锥体扫极坐标系数据通过插值和变换,得到一个密实的栅格化的立方体。

图4 天气雷达体扫数据栅格化
计算每一个点的取值,该点的取值需要从两个方向进行计算,先计算出该点在相邻的仰角扫描层表面上的等半径投影位置,如图5,然后将上一步得到的每个投影点位置在该仰角层中再向相邻两条径向线进行等半径投影,得到两个径向条上的点,如图6[2]。

图5 垂直方向栅格插值

图6 水平方向径向定位
如果计算点处于两个仰角层之间,那么通过上述投影取值,将获得4个最终的投影点位置和值;如果计算点处于最低仰角之下,或处于最高仰角之上,那么通过上述投影取值,将获得2个最终的投影点位置和值。最后通过距离加权计算出插值的大小。
确定插值后,还要确定一个标准的位置,即进行海拔高度和水平距离的计算。如图7所示,O点为雷达天线所在位置,h0为雷达天线所处的海拔高度,A点为探测范围空中某点,B点为A点与地心的连线和海平面的交点。r为A点距离雷达天线的直线距离,R为地球半径,线段AB即为A点的海拔高度[2]。
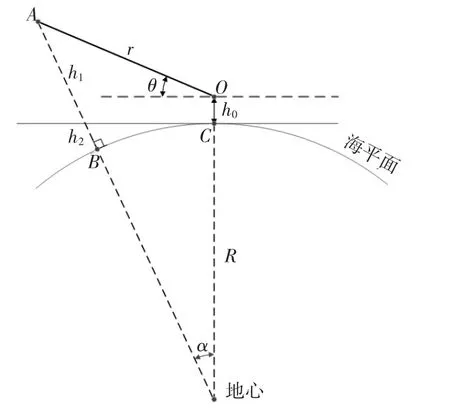
图7 栅格海拔高度计算
A点所处位置的海拔高度AB由两个部分组成:

式中,h1为A点距雷达天线所处的海平面延伸平面的垂直高度;h2为因地球曲率而增加的高度;A点距雷达站的水平距离为弧BC的长度B(C。
由几何关系推导出:
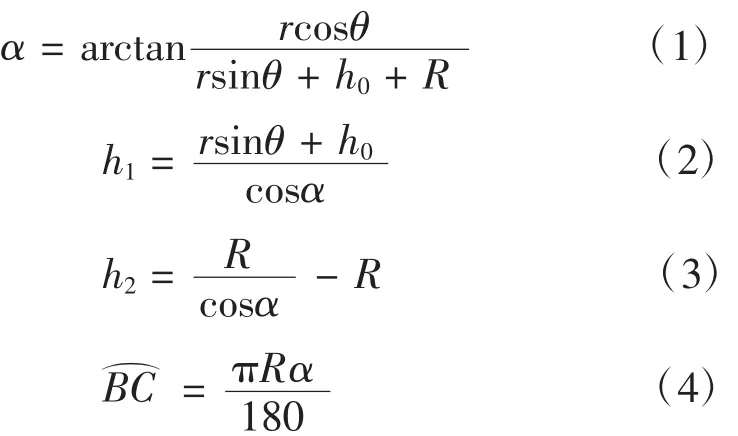
由(1)(2)(3)(4)式可以计算出某点的海拔高度和离雷达站的水平距离,通过该算法进行三维栅格化[2]。
5 计算任务的并行分解
下面以一个范围为150 km,库长为300 m的雷达,使用英伟达Quadro M2000M显卡处理为例,来设计一个并行算法。
栅格化后的立方体每一小格的尺寸为300 m边长的正方体,高度取15 000 m,则该立方体的长宽高为:1 000× 1 000× 50,共 50,000,000 (约 50 M)个数据值。
每个栅格点的取值计算由一个线程运行。每个线程计算出某一个位置的栅格点的取值。算法见第4部分计算任务的描述。
GPU的基本调度单元是线程束,一个线程束需要占用一个SM来运行,多个线程束需要轮流进入SM,对于M2000M,SM的数量是5,线程束大小是32,即一个线程束由32个线程组成,故每个线程块中线程的数量应设计为32的整数倍,才能发挥最大的并发性。M2000M的硬并发线程数量实际上是5×32=160个。每个线程块有独立的寄存器和共享内存,供一个块中的线程共同使用,故每个线程块中的线程数量不宜过多。例如对于M2000M,每个线程块最大线程数为1024,那么,对于本计算任务,每个线程块中的线程数量设为128个较为合理。线程的维数和线程块的维数均为逻辑划分,对于实际性能并无影响,故为了简化数据结构以便于向GPU传送和取回数据,把数据1维化,所以线程块和线程的组织均只需1个维度即可。
那么核函数kernelGet3dVolume<<
6 核函数的设计
核函数原型如下:
__global__void kernelGet3dVolume(int layer-Count, int radialCount, int stdBinCount, int std-HeightCount, int stdBinWidth, int altitude, float stdSweepAngle,float*pmtElevation,int*z,unsigned char*volume,int volumeTotalCount)
参数说明:
layerCount:体扫数据层数
radialCount:每层径向条数
stdBinCount:每条径向库数
stdHeightCount:栅格化后的z轴栅格数
stdBinWidth:库长
altitude:雷达站海拔高度
stdSweepAngle:水平扫描角度间隔
pmtElevation:各层仰角
z:按顺序排列的库数据,从低仰角到高仰角,正北径向开始顺时针旋转,在径向中从最近点开始到最远点。
volume:处理完成后生成的三维栅格数据
volumeTotalCount:volume的字节数。
该核函数的作用是计算三维栅格中某一个点应取的值。
回波的值在z中,z是一维数组,可以通过体扫数据层数、每层径向条数等其它参数来配合数组下标计算,定位出在倒锥面中的空间位置,以进行插值计算。
CPU整理好体扫数据后装载至一块连续内存中,然后将该内存块复制至GPU内存即显存中的数组z,启动核函数展开所有线程,产生50,000,000个逻辑并发线程,由GPU按blockNum和threadNum两个参数来进行自动调度。
7 G P U与C P U的性能对比
下面对714CDP雷达基数据201607061059240.05V进行处理,文件信息如图5所示。

图5 714CD P型天气雷达基数据
该体扫总层数为14,每层径向数为720,每条径向的库数为1 000。栅格化后生成组合反射率产品如图8所示。

图8 基数据201607061059240.05V生成的组合反射率图
CPU和GPU均使用C++代码,CPU代码已进行多线程优化,已充分利用CPU的多核,编译器均为VS2017,对某个天气雷达进行1 000×1 000×50个点的栅格化计算,使用相同的处理算法和天气雷达基数据文件,分别在笔记本电脑(联想Thinkpad P50),以及台式机(联想Thinkstation P510)上多次运行,得到耗时平均值如表1所示。

表1 G P U和C P U处理天气雷达基数据性能实测
在笔记本电脑上,E3-1505是移动端的高端CPU,M2000M是移动端的专业绘图显卡。在台式机上,E5-1620是工作站级别的中高端性能 CPU,P2000是中端绘图显卡,故它们之间的对比是匹配的,具有参考价值的。
从上表可以看出,在笔记本和台式机上,GPU的运算速度均比CPU高约8.5倍。假如有200部天气雷达体扫基数据汇总到一台主机上处理,那么,CPU所需时间为1.038×200=208 s,即3分28秒,而使用GPU,则仅需0.122×200=24 s,比CPU节约3分4秒。
8 结束语
GPU用于高性能计算已有多年,其海量硬并发的特点,很适合用于天气雷达基数据的处理,比起用CPU计算,速度得到显著的提升,如果要处理的天气雷达数据很多,例如200部,那么,使用GPU后,所累积使用时间将大大缩减,即气象产品的处理延时大大缩减,使气象预报工作能更及时地开展。
猜你喜欢
安徽农学通报(2022年6期)2022-04-07
科技创新与应用(2021年31期)2021-11-09
北京汽车(2021年1期)2021-03-04
中北大学学报(自然科学版)(2020年4期)2020-07-13
初中生世界·九年级(2020年2期)2020-04-10
科技视界(2016年15期)2016-06-30
弹箭与制导学报(2015年1期)2015-03-11
雷达学报(2014年4期)2014-04-23
红领巾·成长(2009年8期)2009-01-12
