
变量变换回归分析(Ⅳ)偏好评分资料的结合分析法
——
2019-08-13 01:44:52胡良平
四川精神卫生 2019年3期
胡良平
(1.军事科学院研究生院,北京 100850;2.世界中医药学会联合会临床科研统计学专业委员会,北京 100029
1 基本概念
1.1 偏好评分
在心理、生理和精神卫生等学科领域中,研究者常使用各种量表对患者进行评定[1-4],此类评分一般被视为“计量资料”。然而,在很多其他领域,研究者常基于自己的知识、经验、感受和偏好,来给被评价对象(以下简称为“被评者”)评分,此即“偏好评分”。这里的“被评者”可以是人(如某病患者、参加比赛的歌手、前来应聘的求职者、课题或项目的申请者等)、物品或商品(如电脑、汽车、住宅或服装等)等。评价者进行评分时,通常依据被评者在若干方面或属性或因素的表现或真实情况,并结合自己的“偏好”,给出一个自己认为最合理的分值。由此可知,“偏好评分”不像试验结果那样客观、精准,而在一定程度上带有主观性。这就不难理解,为什么同一位患者的影像学光片由多位放射科医生来阅读,通常会给出不同的评分结果。
1.2 因素及水平
如何区分“被评者A”与“被评者B”?通常需要根据具体情况,从几个主要方面或角度来度量或认定被评者,用统计学的术语来描述,就是拟考虑的“因素”。以一位患者的CT光片为例,假定要考虑的主要因素有A、B、C、D,每个因素又可分为好、中、差3个档次。于是,这4个因素都具有3个水平。请一位临床医生基于前述4个因素来给100例某病患者的CT光片进行病情评分,病情由轻到重依次评为1、2、……、10分。这样就可以获得对这100例患者的“偏好评分”。这里的“偏好”主要反映了该临床医生在阅片方面的经验和技能,显然不可能像定量检测样品中某种物质含量那样精准。
1.3 偏好评分的性质
通常,偏好评分有两种具体形式,其一,仅用很少的几个分值来描述所有的“被评者”,如用“1、2、3、4、5”5个分值来描述100例某病患者;其二,使用1~ 81共81个不相同的分值来描述81例某病患者。前一种“偏好评分”只能被视为“有序资料”;而后一种“偏好评分”可以被视为“有序资料”,也可被近似视为“计量资料”。
1.4 偏好评分资料的数据结构
在一项关于轮胎的消费情况的调查中,假定轮胎主要属性(或因素)有4个:品牌、价格、使用寿命、有无公路意外保险计划,各属性包含不同水平[5]。见表1。
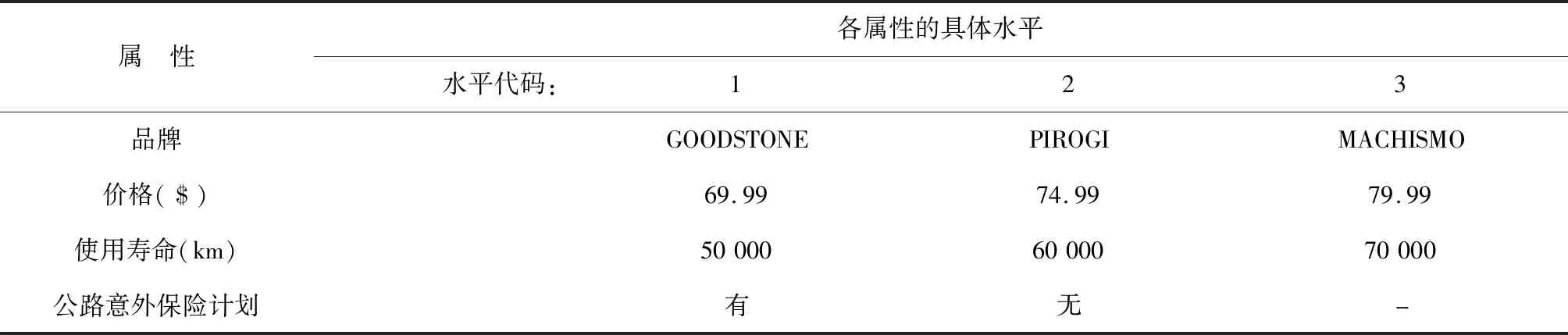
表1 轮胎的属性及其水平
若将各属性的所有水平进行组合,一共有3×3×3×2=54种可能的组合形式(相当于有54种不同的轮胎或54种不同的试验条件;在多因素试验设计中,每种“组合”被称为一个“试验点”)。最好的做法是采用析因设计,即在54个试验点的每个试验点上至少做2次独立重复试验。那么总试验次数至少需要108次。为了节约成本,研究者拟采用正交设计。利用SAS软件产生一个组合数为18的正交设计表。见表2。其中最后两列为两名顾客(即在各试验点上均做了2次独立重复试验)给出的偏好评分,用1~18来表示其偏好(1表示最愿意购买,18表示最不愿意购买)。

表2 具有18种水平组合的混合水平正交表
由表2可知,偏好评分资料的数据结构由两种性质的变量及其取值构成:定性的影响因素(表2中第2~5列)和偏好评分(表2中最后2列)。就整体而言,它是一个多因素析因设计或正交设计(或均匀设计)下所收集的一元或多元有序资料。
由于未找到合适的临床实例,故借用上面关于“商品”的例子。若临床工作者能在临床工作中发现与此实例类似的“临床问题”,可以采用本文介绍的“结合分析法”进行数据处理。
1.5 偏好评分资料的分析任务及分析方法
针对每一位顾客(即评价者)给出的“评分”,需要回答以下三个问题:其一,4个因素的“重要性(或贡献率)”分别是多少(重要性之和为100.00%)?其二,每个因素各水平的“分值效用”(即每个水平的“重要性”,确切的含义为“水平效用”)是多少?其三,该顾客最偏爱或喜欢的轮胎是哪一款(即理想试验点)?为实现前述的统计分析任务,需要选择“结合分析法”。
2 结合分析简介[6-8]
2.1 何为结合分析
结合分析也叫联合分析,它用于确定哪些产品(或服务)的属性(或因素)对于消费者(或评价者)来说是最重要的、哪些是中等重要的、哪些是次要的;还可用于估计每种属性(或因素)的每个水平的“效用(即对偏好评分的作用)”大小。
2.2 结合分析的基本思想
结合分析的基本思想是:将偏好评分近似视为计量因变量,将每个属性的每个水平视为一个“二值自变量”。假定每个属性的所有水平对因变量的影响是可以叠加的,进一步假设每个属性所有水平效应之和为0(这在统计学上被称为“约束条件”,以保证计算出的“效用值”有正有负,代表不同的作用方向)。在前述假设成立的条件下,构建多重线性回归模型,并基于最小平方法原理求解回归模型中的参数估计值。
2.3 结合分析的基本模型
结合分析中通常采用普通最小平方法估计回归模型中的参数,因素的每个水平被视为一个自变量,并且,每个自变量只有0或1两个可能的取值。模型可用式(1)表示。
Y=a+∑vx
(1)
在式(1)中,Y表示所有属性(或因素)的一种水平组合条件下被评价对象的总效用,也被称为“轮廓(即一个试验点)”的总效用。a为截距,v为各水平的分值效用(相当于回归系数),x为取值为0或1的哑变量,当它代表的某属性的一个水平出现时,x=1;否则x=0。
若模型中属性水平的分值效用的差值(最大效用与最小效用之差)越大,则该属性的相对重要性越高。一般用百分比来描述各属性的重要性。见式(2)。
(2)
在式(2)中,m表示属性个数,Wj表示第j个属性的相对重要性,max(vj)和min(vj)分别表示第j个属性各水平中最大和最小的分值效用。
3 实例的SAS实现
3.1 对实例的进一步解说
在前面的“实例”中,表1列出了拟考察的“属性(或因素)及其水平”,表2是将这个实际问题付诸研究所给出的一种“试验设计”(第2~5列)及其两位顾客给出的“偏好评分”(最后两列)。表2中的每一行代表4个因素各取一个水平所对应的一种组合(也叫试验点),也就是一款特定的产品(在本例中为一种轮胎)。统计分析的目的是希望依据某位顾客的“偏好评分”,回答前述“偏好评分资料的分析任务”中提及的问题。
3.2 分析实例所需要的SAS程序
options validvarname=any;
proc format;
value brandf 1=' goodstone' 2=' pirogi' 3=' machismo' ;
value pricef 1=' $69.99' 2=' $74.99' 3=' $79.99' ;
value lifef 1=' 50,000' 2=' 60,000' 3=' 70,000' ;
value hazardf 1=' yes' 2=' no' ;
run;
data tires;
input brand price life hazard rank1 rank2 @@;
format brand brandf9. price pricef9.
life lifef6. hazard hazardf3.;cards;
;
run;
proc transreg utilities cprefix=0 lprefix=0;
ods select convergencestatus fitstatistics utilities;
model identity(rank1 rank2/reflect)=
class(brand price life hazard/zero=sum);
output out=out replace predicted;
run;
proc print label data=out;
var rank1 rank2 prank1prank2 brand price life hazard;
run;
【说明】“model语句”中的选项“reflect”的含义:代表各水平取正的“分值效用”时,对应着最好的“偏好评分”。这样可以免去使用者在下专业结论时,需要顾及结果变量究竟属于高优指标还是低优指标。
若忽略了选项“reflect”,当结果变量为高优指标时,需要选取绝对值最大的正效用值对应的水平组成“理想试验点”;而当结果变量为低优指标时,需要选取绝对值最大的负效用值对应的水平组成“理想试验点”。
3.3 主要输出结果及解释
因篇幅所限,下面仅给出第一位顾客偏好评分对应的结合分析结果:

RootMSE1.72562R-Square0.9385DependentMean9.50000AdjR-Sq0.8955CoeffVar18.16446
以上结果表明:模型对资料的拟合优度较高,均方根误差=1.72562、R2=0.9385。与“分值效用(Utility)”和“重要性(Importance)”有关的计算结果见图1。
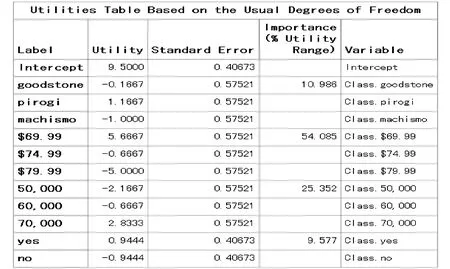
图1 与表2中顾客A的偏好评分对应的计算结果
由图1中第4列计算结果可知:轮胎的4个属性的相对重要性为:价格>使用寿命>品牌>是否有公路意外保险计划。价格方面,越便宜越受顾客偏好;使用寿命方面,越长越受顾客偏好;品牌方面,顾客最偏好的是pirogi;是否有公路意外保险计划方面,顾客更偏好有保险计划的轮胎。最受顾客欢迎的轮胎属性组合为“品牌pirogi +使用寿命70 000km+价格$69.99+有公路意外保险计划”,它们都是各属性中“分值效用”取最大正值的“水平”。
4 讨论与小结
4.1 讨论
4.1.1 式(1)的解读
结合分析的“回归模型”式(1)的真实含义,就是把“偏好评分值”视为“计量因变量”,而把所有的“属性(或因素)”视为“定性自变量”,但需要对每个属性变量产生哑变量。值得注意的是:在对每个属性变量产生哑变量时,不采取通常的方法(以其中一个水平为基准),而是将其每个水平产生一个“0与1”的二值变量,但必须限制该属性的所有水平对应的哑变量之和等于0。例如:对于“品牌”这个属性变量而言,由表2的第2列可知,第1~6行都是第1种品牌“GOODSTONE”,若用TB1代表它,则TB1=1,其后的12行都不是该品牌,故TB1=0;同理,可用TB2代表第2种品牌,则在第7~12行令TB2=1,其他行上令TB2=0;可用TB3代表第3种品牌,则在第13~18行令TB3=1,其他行上令TB3=0。于是,就将一个具有3水平的“品牌”转换成TB1、TB2、TB3三个“二值变量”了。
类似的,利用以上方法可将“价格”转换成TP1、TP2、TP3三个“二值变量”,将“使用寿命”转换成TL1、TL2、TL3三个“二值变量”,将“有无公路意外保险计划”转换成TH1、TH2两个“二值变量”。于是,可用拟合多重线性回归模型的REG过程来实现模型(1)的拟合。
4.1.2 用REG过程拟合式(1)
/*结合模型的构建与参数估计*/
data abc;
input a b tb1 tb2 tb3 tp1 tp2 tp3
tl1 tl2 tl3 th1 th2;
cards;

161510010001010171810010000101541000101000199100010010012210000110010751000010011012110101001000118170101000010111120100101001014160100100011067010001010103301000101001131400110010010151300110001010480010100100110600101000110110010011000181000100100101
;
run;
proc reg data=abc;
model a=tb1-tb3 tp1-tp3 tl1-tl3 th1 th2;
restrict tb1+tb2+tb3=0,tp1+tp2+tp3=0,
tl1+tl2+tl3=0,th1+th2=0;
run;
4.1.3 上述SAS程序的主要输出结果

方差分析源自由度平方和均方FPr>F模型7454.7222264.9603221.82<0.0001误差1029.777782.97778校正合计17484.50000

均方根误差1.72562R20.9385因变量均值9.50000调整R20.8955变异系数18.16446
以上结果与前面使用“TRANSREG过程”输出的“拟合优度”结果是相同的。
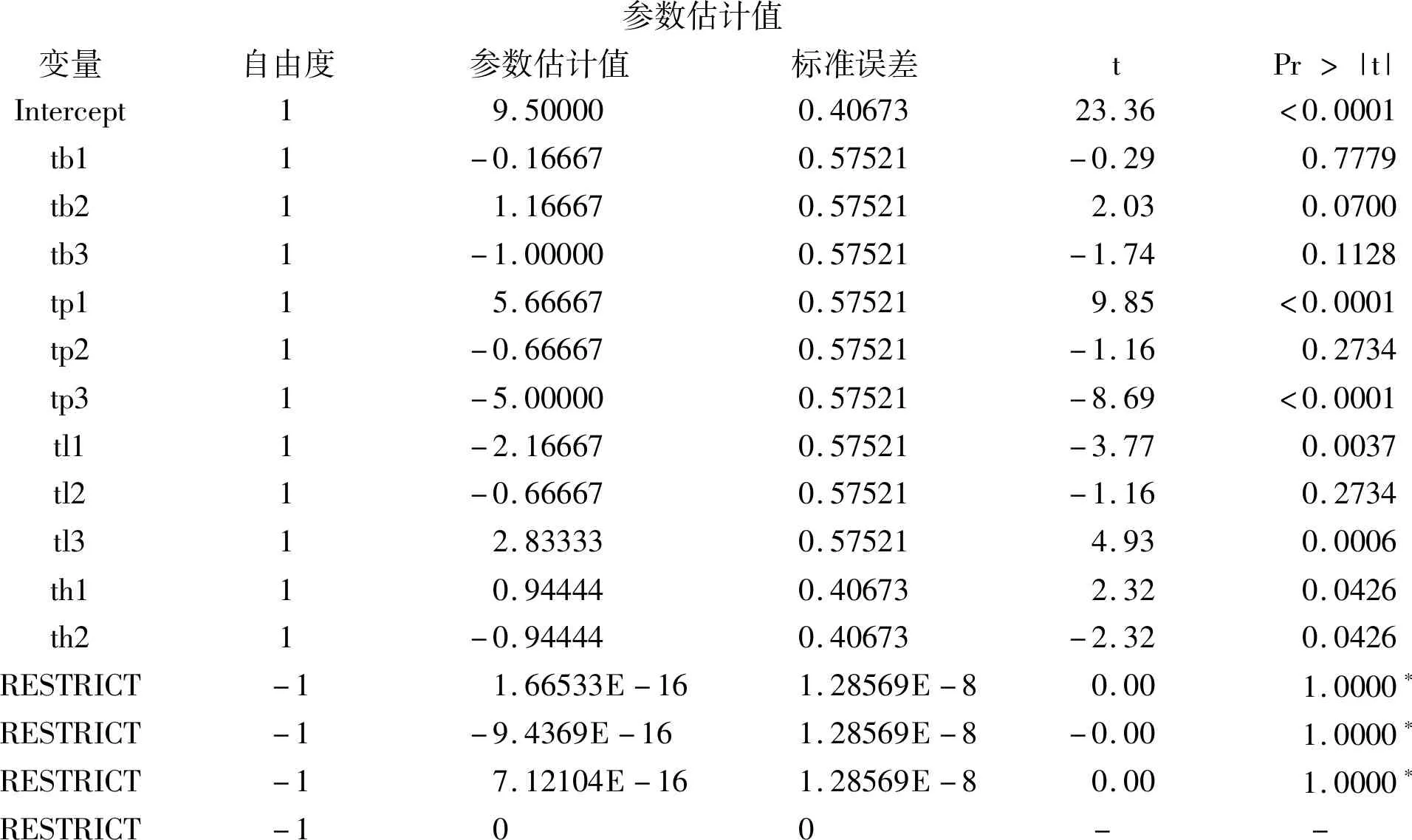
参数估计值变量自由度参数估计值标准误差tPr>|t|Intercept19.500000.4067323.36<0.0001tb11-0.166670.57521-0.290.7779tb211.166670.575212.030.0700tb31-1.000000.57521-1.740.1128tp115.666670.575219.85<0.0001tp21-0.666670.57521-1.160.2734tp31-5.000000.57521-8.69<0.0001tl11-2.166670.57521-3.770.0037tl21-0.666670.57521-1.160.2734tl312.833330.575214.930.0006th110.944440.406732.320.0426th21-0.944440.40673-2.320.0426RESTRICT-11.66533E-161.28569E-80.001.0000∗RESTRICT-1-9.4369E-161.28569E-8-0.001.0000∗RESTRICT-17.12104E-161.28569E-80.001.0000∗RESTRICT-100 - -
以上的输出结果中,除了最后“RESTRICT”所在的4行外,第3列和第4列与前面图1中第2列和第3列是完全一致的。此处,还多出了“t值”和“P值”,但少了关于各属性“重要性”的计算结果。但若利用上面的计算结果代入式(2),就不难计算出“重要性”的数值。例如:

属性最大值-最小值重要性(%)品牌1.1667-(-1.0000)=2.16672.1667/18.8889=0.114708=11.471%价格5.6667-(-5.0000)=10.666710.6667/18.8889=0.564707=56.471%寿命2.8333-(-2.1667)=5.00005.0000/18.8889=0.264705=26.471%保险0.9444-(-0.9444)=1.88881.8888/18.8889=0.099995=10.000%合计18.8889
上面的“重要性”计算结果与前面图1中第4列对应的结果略有出入,可能是每一项“分值效用”输出时仅保留了4位小数,属于“舍入误差”所致。
4.1.4在第3.2节SAS程序的“model语句”中不使用“reflect”的输出结果
若将前面第3.2节SAS程序“model语句”中的选项“reflect”删除,其他内容不变,与图1对应的输出结果见图2。
将图2与图1对照,仅第2列中各因素的各水平的“分值效用”的正、负号发生了反转,绝对值没有任何改变。此时,若希望找出“理想试验点”,必须弄清楚“偏好评分”属于“高优指标”还是“低优指标”。本例开始就交代了“偏好评分”为“低优指标”,故“理想试验点”应由各属性中“分值效用”取最大绝对值且为负号对应的“水平”组合起来,即品牌pirogi+使用寿命70 000km+价格$69.99+有公路意外保险计划。
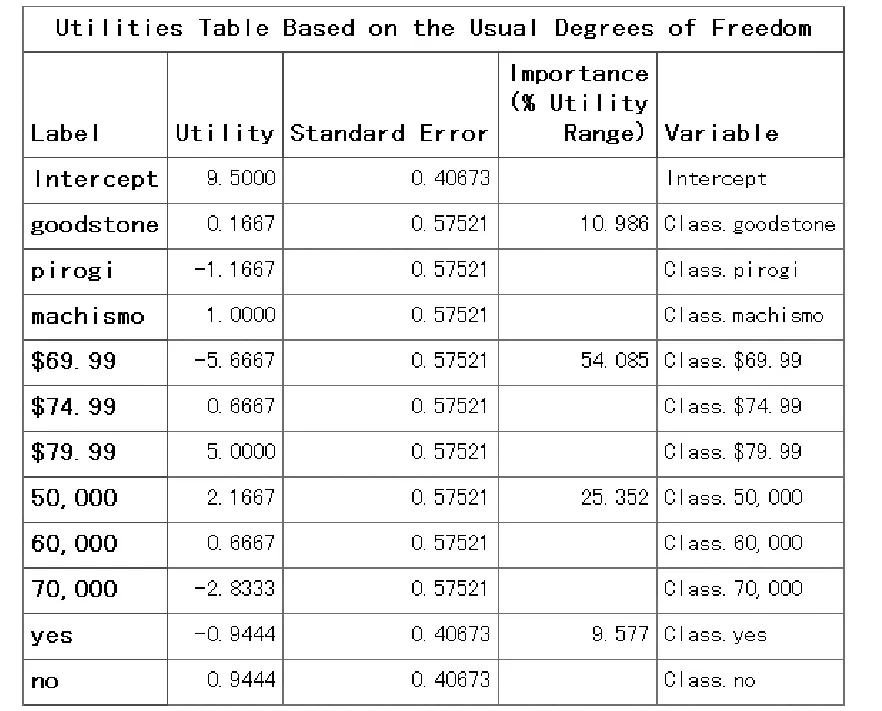
图2 与表2中顾客A的偏好评分对应的计算结果(未用reflect选项)
4.2 小结
结合分析模型是基于各属性(或因素)的分值效用可以简单叠加的假定成立的条件下构造出来的,当实际问题符合此假定时,其分析结果是正确的;否则,要慎重使用。必要时,需要选择其他统计模型。
猜你喜欢
工会博览(2022年8期)2022-06-30 12:19:30
中国石油石化(2021年9期)2021-07-17 09:24:16
少儿美术(2019年7期)2019-12-14 08:06:22
中国塑料(2016年9期)2016-06-13 03:18:48
山东青年(2016年1期)2016-02-28 14:25:27
中国洗涤用品工业(2015年6期)2015-02-28 19:02:35
现代农业(2015年5期)2015-02-28 18:40:44
现代农业(2015年5期)2015-02-28 18:40:42
江苏卫生事业管理(2014年2期)2014-02-28 01:59:36
江苏卫生事业管理(2014年2期)2014-02-28 01:59:35
