
基于Multi-probe LSH的菊花花型相似性计算
2019-08-13 01:42:30袁培森翟肇裕钱淑韵徐焕良
农业机械学报 2019年7期
袁培森 翟肇裕 钱淑韵 徐焕良,3
(1.南京农业大学信息科学技术学院, 南京 210095; 2.马德里理工大学技术工程和电信系统高级学院, 马德里 28040;3.国家信息农业工程技术中心, 南京 210095)
0 引言
表型(Phenotype)是生物某一特定物理外观或组成,是由基因和环境共同作用的结果[1-2]。植物表型代表了植物形态,是植物学领域研究的重要课题,在生态学、植物育种等领域应用广泛[3-4]。其中,表型相似性计算在植物表型[4-6]、基因组学[7]、疾病诊断[8-10]等研究中具有重要应用。
当前,数据挖掘技术为解决植物表型研究提供了重要支撑手段[11]。相似性计算作为数据挖掘和机器学习的基础问题,又称为最近邻查询。对于海量、高维数据的相似性计算,由于“维灾难”(Curse of dimensionality)问题,线性计算效率不高。为此,研究者提出了近似最近邻(Approximate nearest neighbor,ANN)查找技术[12],这是一种对查询结果质量和效率折中的技术。局部位置敏感哈希技术(Locality sensitive hashing,LSH)是近似最近邻查询计算的高效方法[13]。该方法在查询质量和查询效率方面均具有理论保证。基于LSH有多种优化查询质量和效率的技术,例如,基于熵的LSH[14],多探测的LSH(Multi-probe LSH,MPLSH)[15]等,其中MPLSH在高维数据相似性计算效率和结果质量方面具有更好的效果[16-17]。
在表型相似性计算研究方面,PENG等[6]指出,测量表型相似性在疾病诊断中发挥重要作用,提出了一种基于网络的表型相似性测量方法,用于计算表型之间的相似性。在菊花表型及分类方面,ZHANG等[18]通过简单序列重复标记建立的独特DNA指纹和分子身份鉴定中国传统菊花品种,为基于微卫星标记多态性的菊花鉴定和分类的起点。ROEIN等[19]研究利用扩增片段长度多态性和表型特征,评估菊花的遗传多样性和种群结构。KHODAKOVSKAYA等[20]通过基因片段的控制来增强菊花中的开花和分枝表型。但是,专门针对菊花表型的计算研究较少。YAN等[21]定义了菊花的不同花色表型,完成了菊花品种表型颜色的分布分析。
菊花是全球第二重要的观赏植物,具有品种数量庞大、花型变异丰富的特点[22]。菊花花型是菊花的重要表型特征之一,其相似性计算对菊花形态分类和表型研究具有重要作用,同时菊花花型种类多、瓣形繁多,这些特点给菊花的品种分类和表型研究带来较大困难[18]。表型相似性计算可以为菊花分类提供重要的参考,对于海量的菊花相似性计算,效率和质量至关重要。
本文针对海量菊花图像数据进行菊花花型相似性比较,提出采用SIFT特征和视觉词袋模型[23-24]提取菊花图像重要特征,并使用K-means对重要特征进行聚类和优化。针对菊花图像数据的高维特性,采用多探测LSH解决海量菊花花型相似性计算的质量和效率问题。在查询质量和查询效率方面寻求一种优化计算方案。
1 材料与方法
1.1 菊花图像
本文数据集共包括4 100幅菊花图像,共5种花型:翻卷型、雏菊型、飞舞型、球型和莲座型[25]。菊花图像示例如图1所示。每一种花型有800幅,共4 000幅用于训练,100幅图像用于测试。

图1 5种菊花类型示例Fig.1 Illustration of five types of chrysanthemum images
1.2 菊花图像SIFT特征
常用的图像特征包括形状、纹理等。在诸多的图像特征提取技术中,尺度不变特征转换 (Scale invariant feature transform,SIFT)[26]应用最广。SIFT通过在图像空间中搜索关键点,并提取出其位置、尺度、旋转不变量。因此SIFT对尺度变化、旋转以及一定视角和光照变化等具有不变性、稳定性及很强的可区分性和扩展性[26]。鉴于SIFT良好的性质,本文采用SIFT方法提取菊花的特征。
SIFT算法有4个计算步骤[26]:高斯差(Difference of Gaussians,DoG)空间极值检测、关键点定位、方向确定和关键点描述。
图2是一幅菊花图像经过灰化后提取SIFT特征示意图,每个点代表一个定位关键点。

图2 菊花图像SIFT特征提取示意图Fig.2 Illustration of SIFT features extraction of chrysanthemum image
1.3 BoVW-SIFT模型
由于SIFT特征提取之后的高维性,本文采用K-means聚类算法对这些向量数据进行初步聚类,用聚类中的簇作为词典的词,进而将同一幅图像的SIFT向量映射到视觉词序列生成码本,这样菊花图像可以使用一个码本向量来进行描述。本文采用了基于 SIFT的视觉词袋(Bag of visual word,BoVW)[23-24]特征来对菊花图像建模,菊花图像预处理过程如图3所示。

图3 菊花图像预处理过程Fig.3 Illustration of chrysanthemum image preprocessing
针对SIFT特征,构建BoVW码本步骤如下:①对每一幅菊花图像提取SIFT特征, SIFT特征用一个128维描述子向量表示,假设菊花图像数据集共提取出M个SIFT特征。②用K-means对提取的M个SIFT特征进行聚类,此算法把M个SIFT特征分为k个簇,表示为Ci,i=1,2,…,k,其中Ci为聚类中心。
(1)
其中
式中μi——簇Ci的均值向量
E——平方误差
x——由SIFT特征构成的向量
最小化式(1)的平方误差,以使簇内具有较高的相似度,而簇间相似度较低[27]。
本文使用K-means聚类返回的k个簇,计算每一幅图像的每一个SIFT特征到这k个视觉词的距离,并将其映射到距离最近的视觉词中。研究表明,k太小会导致图像表达能力不足,太大导致量化过拟合[28],本文设置k为512。
菊花图像数据经过提取SIFT特征后,将这些特征映射到码本向量。利用TF-IDF模型构造向量,并对向量进行归一化。菊花向量的构造包含两项因子:词频(Term frequency,TF)和逆向文件频率(Inverse document frequency,IDF)[29]。TF是给定的关键点在该菊花图像中出现的频率,IDF是一个关键点普遍重要性的度量。
(2)
式中TFij——关键点j在图像i中的频率归一化值
nij——关键点j在图像i中出现的次数
nkj——图像k中关键点j出现的次数
(3)
其中
Ti={j:ti∈dj}
式中IDFi——关键点i在图像中的逆向文件频率
D——菊花图像数量
Ti——包含关键点j的图像数量
图像向量采用TFijIDFi进行计算,最后对图像向量进行数据归一化
(4)
式中μ——均值σ——标准差

采用欧氏距离作为图像距离度量。距离最小的菊花图像作为相似性查询结果。
(5)
式中ui、vi——归一化后的向量
N——向量维度d——距离
1.4 局部位置敏感哈希技术
1.4.1LSH基本原理
相似性查询又称为最近邻查询(Nearest neighbor search,NNS),给定N维向量O={x1,x2,…,xn}∈RN,查询向量q∉O,返回元素x*∈O,x*与查询向量q在某种距离度量上最近。为解决高维数据最近邻查询计算效率问题,研究者提出了近似最近邻查询技术来折衷查询的效率和质量[12]。近似最近邻查询返回满足d(x,q)≤(1+ε)d(x*,q)的结果,其中ε>0,x*是查询向量q的精确最近邻,该查询称为(1+ε)-近似最近邻[30]。图4是(1+ε)-近似最近邻查询示意图,查询向量q真实的最近邻是o1,距离为r,该图中的o2和o4都可作为该查询的近似结果。
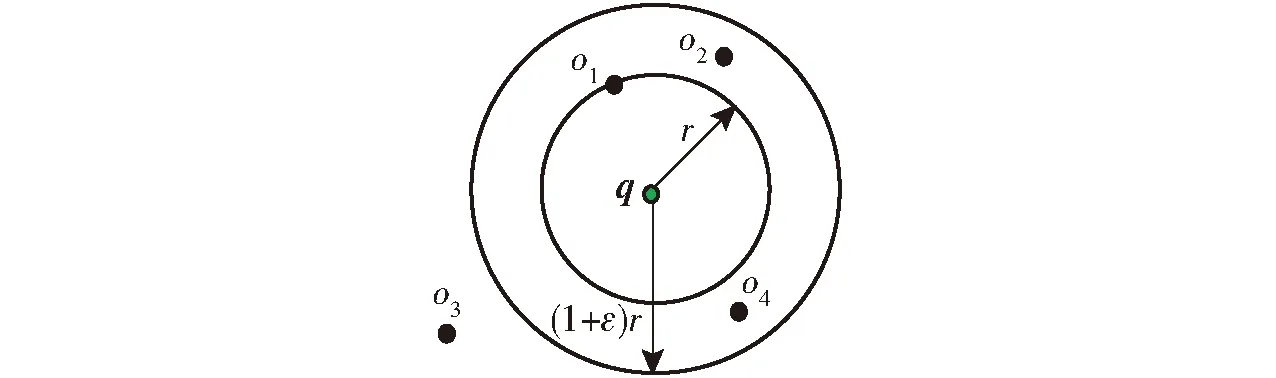
图4 (1+ε)-近似最近邻查询示意图Fig.4 Illustration of (1+ε)-approximate nearest neighbor query
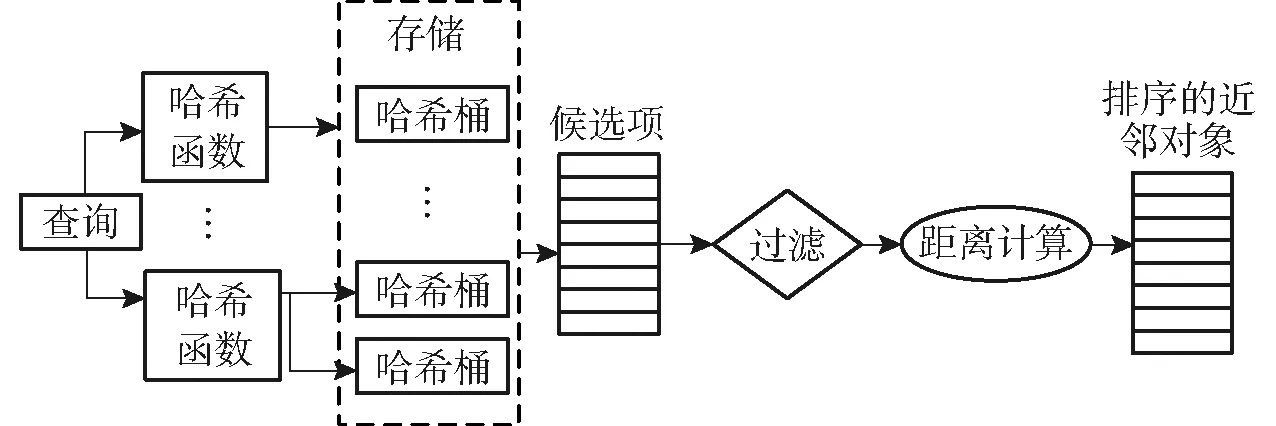
图5 LSH过滤-验证计算过程Fig.5 LSH filtering-verification evaluation procedure
LSH[12]是一种基于过滤-验证框架的计算高维数据近似最近邻的高效查询技术,过滤-验证框架计算过程如图5所示。LSH能够理论上在次线性(Sub-linear)时间内近似求解高维数据的最近邻问题。
给定距离r、近似因子ε(ε>0)和概率p1、p2,其中p1>p2,哈希函数h把N维空间的向量映射为整数集合Z,记为h:RN→Z,x1、x2同时满足:若d(x1,x2)≤r,则P[h(x1)=h(x2)]≥p1;若d(x1,x2)≥(1+ε)r,则P[h(x1)=h(x2)]≤p2,则称为(r,(1+ε)r,p1,p2)-sensitive的LSH。
LSH的基本原理为
P[h(xi)=h(xj)]=sim(xi,xj)
(6)
式中 sim()——相似性度量函数
xi、xj——数据向量
P——概率
即把两个高维向量的相似性计算转变为计算两个哈希值相等的概率。
1.4.2LSH结果放大
为了提升查询成功概率,通常使用多个独立的哈希表[31]。设局部敏感哈希函数族H,每个哈希表由k个哈希函数h∈H创建。
通过以下3种操作来提高成功概率: AND操作;OR操作;级联AND和OR操作。
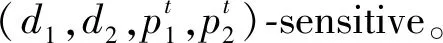
P=1-(1-st)L
(7)
式(7)的可视化如图6所示,图6是L为10时,被检出的概率与t、s的关系,AND操作时,增大t能提高过滤掉相似度小的对象的概率。通过连接t个哈希函数构造哈希关键字,降低了相似对象之间的冲突概率。为了提高查询的召回率,LSH一般使用L个函数g1,g2,…,gL,共L个哈希表。
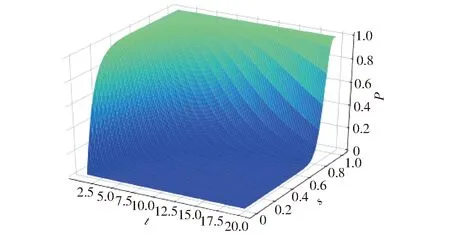
图6 公式(7)的成功概率与相似度及参数(L=10)Fig.6 Success ratio with similarity s and parameter t of formula (7) (L=10)
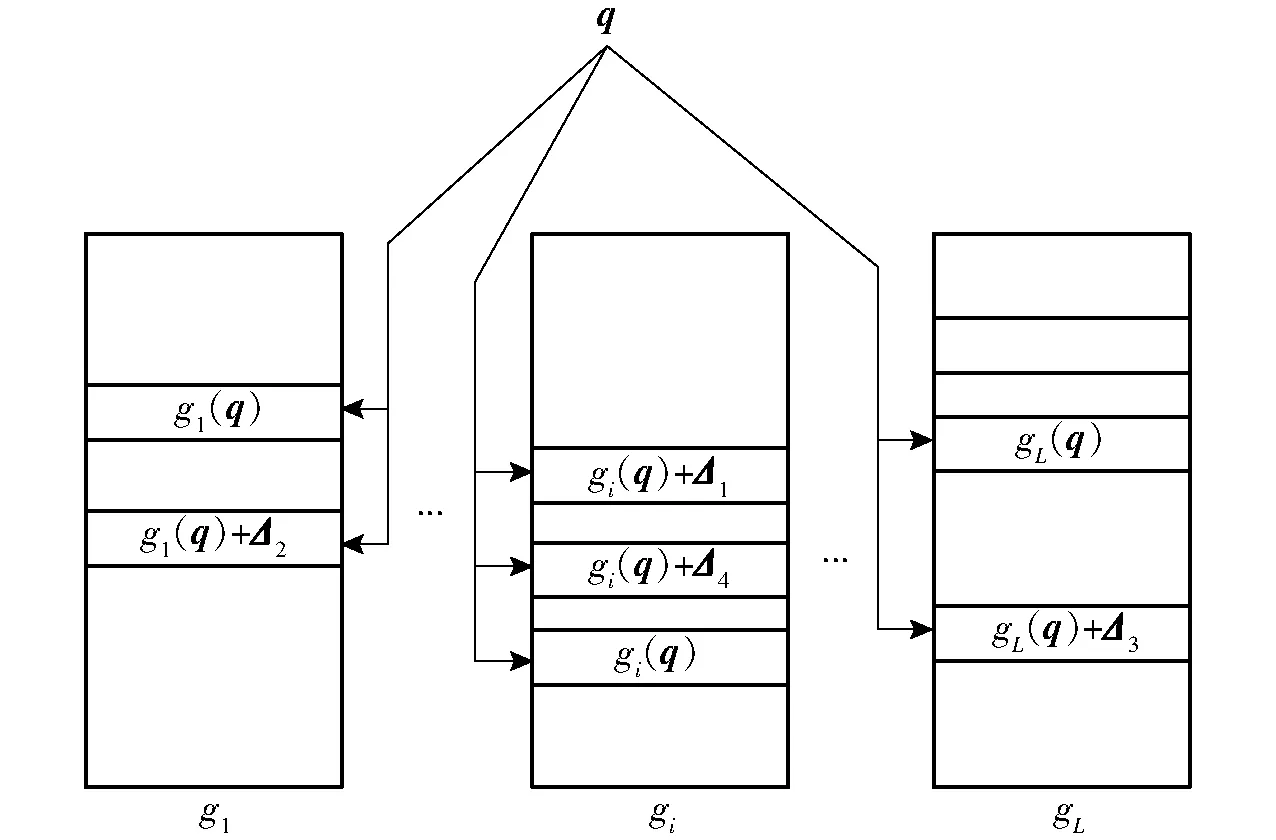
1.5 查询计算过程
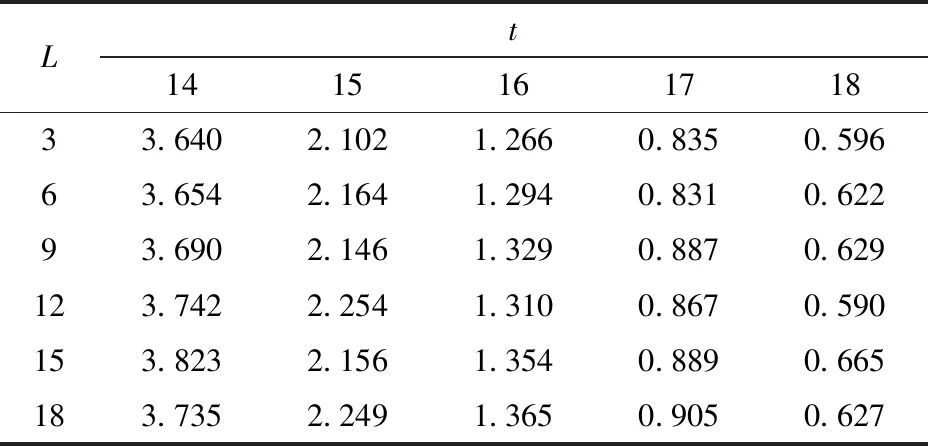
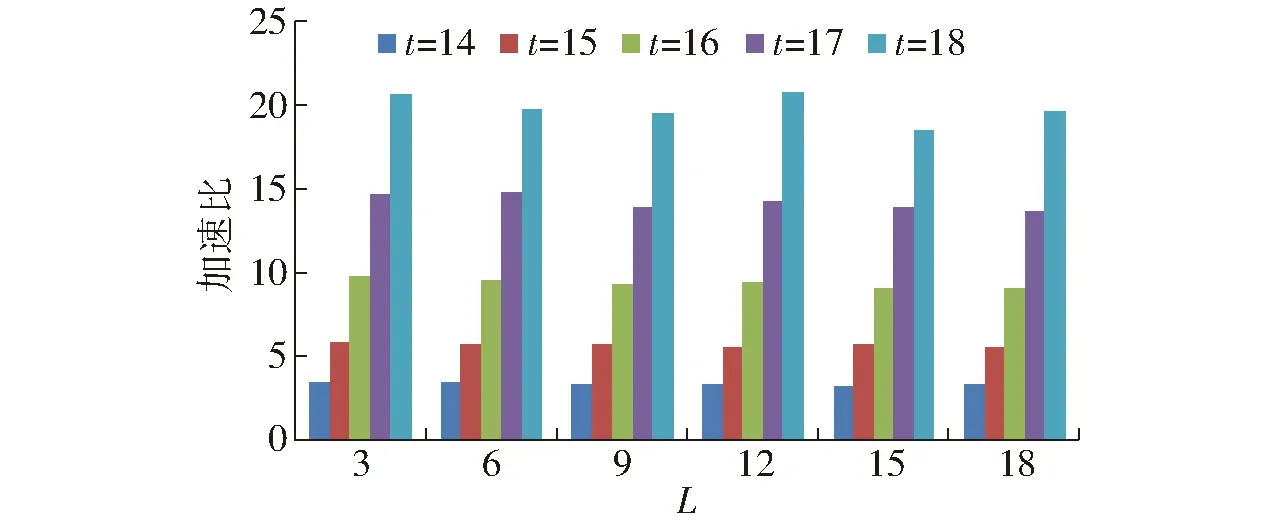
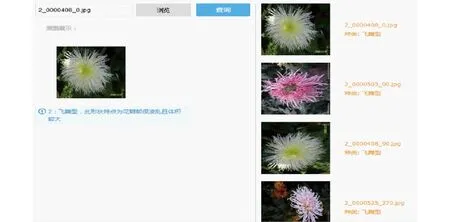
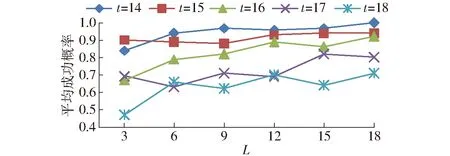
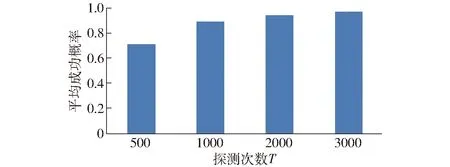
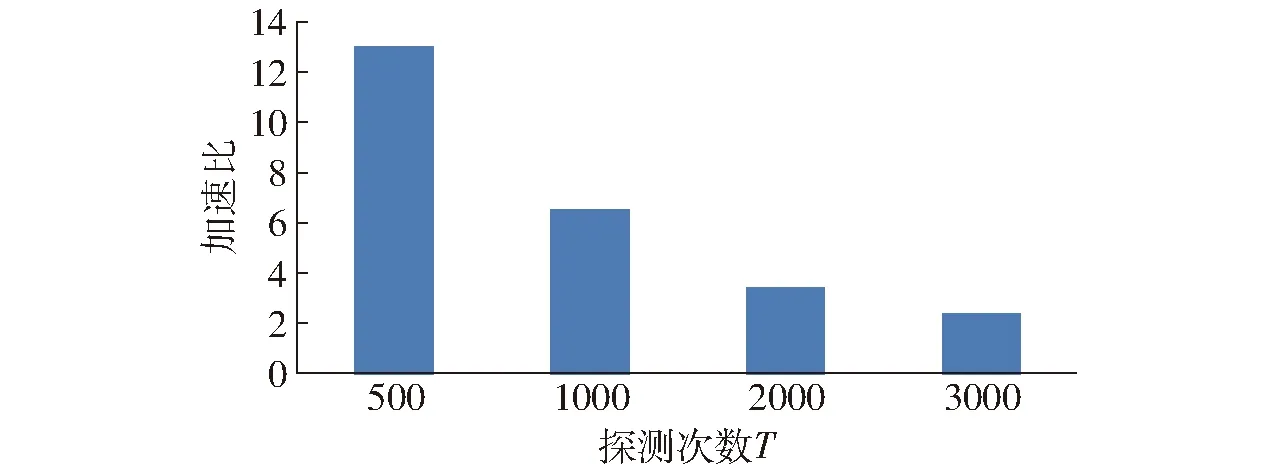
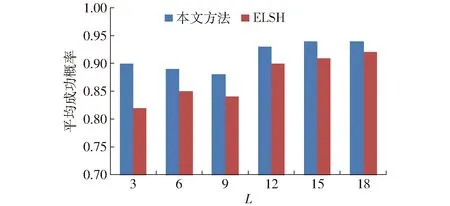
基于LSH的查询计算处理框架如图7所示。给定一个菊花查询x,计算gi(x)(1 g(x)=(h1(x),h2(x),…,ht(x)) (8) 函数g(x)通过连接t个哈希函数构造哈希关键字,该关键字作为索引桶识别号,降低了相似对象之间的冲突概率。为了提高查询的召回率,LSH一般使用L个函数g1,g2,…,gL,形成L个哈希表。 图7 LSH计算处理框架Fig.7 Basic processing framework of locality sensitive hashing 根据LSH的性质,与查询向量q相近的菊花没有被哈希到同一个桶中,它很有可能以很高的概率哈希到周围的桶中,查询向量q的近邻点落在其相邻区域的概率分布如图8所示[15]。图8是某一查询向量q在菊花图像集上的相邻区域映射概率分布,该图以0为中心,落在x=0两侧的概率基本呈现正态分布。由图8可以看出通过检查查询向量q附近的桶,可以增加查找近邻数据的概率。本文方法通过仔细推导出的探测序列,探测可能包含查询结果的哈希桶来提高查询的效率,极大地降低了哈希表所需的数量,提高菊花花型相似性的查询质量和查询效率。 图8 查询向量q的近邻点落在其相邻区域的概率分布图Fig.8 Illustration of probability distribution of query points q in adjacent buckets 采用文献[15]的方法,定义哈希扰动向量Δ=(δ1,δ2,…,δT),其中δi∈{-1,0,1}。给定菊花查询向量q,基本的LSH检索g(q)=(h1(q),h2(q),…,hL(q))的桶中元素作为候选对象,顺序地探测哈希桶g(q)+Δ,探测过程如图9所示。给定哈希桶探寻序列Δ1,Δ2,…,gi(q)+Δ1是应用扰动向量Δ1后产生的新哈希值,它指向表中一个新的哈希桶,通过使用扰动向量,可以获得多个与查询向量q指向的哈希桶邻近的桶,这些桶中含有与q邻近的元素的概率较高。 图9 哈希探测过程Fig.9 Probing procedure of hash 图9中点p落在hi(q)+δ的概率[15]估计为 P[hi(p)=hi(q)+δ]≈exp(-ηxi(δ)2) (9) 式中η——取决于‖p-q‖2的常量 xi(δ)——查询向量q与横边界hi(q)+δ的距离 假设扰动向量Δ=(δ1,δ2,…,δT),则经过t个哈希函数,得到p与q相邻的概率为 (10) 试验运行环境为Intel Core i5 1.6 GHz,8 GB内存,128 GB固态硬盘;操作系统为MacOS 10.13.3。开发环境为OpenCV 3.4和C++。 图像码本长度k为512,ε设置为0.02。查询次数设置为100,哈希探测次数默认设置为2 000。试验中参数t为每个哈希表的哈希函数个数,L为哈希表个数。试验中参数t的取值范围为14~18,L的范围为3~18。探测数量T分别为500、1 000、2 000和3 000。 为了测试计算效率,对数据集采用了增加随机高斯噪声进行扩充,使得数据集的总量为100 000,查询质量的测试仍然采用原始数据集。查询计算效率使用平均查询时间和加速比两个指标进行评价。平均查询时间结果如表1所示。其中线性式扫描的平均查询时间为12.31 ms。 表1 平均查询时间Tab.1 Average query time ms 表1中,随着参数t和L的增加,平均查询时间在减小,从3.823 ms降低到0.590 ms。每个哈希表的哈希函数越多,其查询时间越短,表明AND操作过滤后的结果越少,表1结果表明哈希表个数对查询时间影响不大。 根据加速比评价查询效率,加速比是相对于线性扫描式查找的比例因子,计算公式为 (11) 式中TA——近似查询时间 TL——线性扫描时间 加速比越大,说明本文方法相对于线性扫描式计算越快。 图10显示随着参数t和L的增加,平均加速比从3.3左右增加到19.8。哈希函数数量越多,加速比越大,哈希表个数对查询时间影响不明显。 图10 相对线性扫描加速比Fig.10 Speedup ratio compared with linear scanning 查询结果示例如图11所示,输入一幅飞舞型菊花图像,右侧输出查询到的相似图像。 图11 查询结果示例Fig.11 Illustration of query results 为了度量查询结果质量,采用平均成功概率来计算。 (12) 对查询集合Q,平均成功概率(Average success ratio,ASR)为 (13) 式中 |Q|——查询数量 ASR值越大,表明查询结果越好。 图12为平均成功概率试验结果,由图12可知,t为14、15时,平均成功概率在0.91以上,L大于6、t为14时平均成功概率大于0.95,查询结果的质量较好;t从15增加到18时,平均成功概率从0.95降到0.63左右;t一定时,L从3增加到18,平均成功概率呈上升趋势,增加了11.9%~19%。 图12 查询平均成功概率结果Fig.12 Average success rate of query 从图10、12可以得出,t为14~16、L>6时,平均加速比从3.3上升到9.3,此时平均查询时间为1.31 ms,平均成功概率在0.8以上。 在t=14、L=6时,测试了探测次数对查询质量的影响,如图13和图14所示。探测次数设置为500、1 000、2 000和3 000。 图13 查询平均成功概率与探测次数关系Fig.13 Relationship of average success rate with probe number 图14 加速比与探测次数关系Fig.14 Relationship of speedup ratio with probe number 图13中,查询平均成功概率随着探测次数的增加呈现上升趋势,从0.71提高到0.97,提高了36.6%。 图14中,加速比随着探测次数的增加呈下降趋势,从13降到2.4。 图13、14的结果表明,探测次数对查询性能有较大的影响,探测次数的增加可以提高查询结果的平均成功概率。探测次数在1 000~2 000范围可以获得较好的查询质量,但是如果要提高查询的效率,可以适当地减少探测次数。 在查询质量和性能方面,设置哈希函数个数t为14,将本文方法与基于熵的ELSH[14]进行了对比试验。试验结果如图15、16所示。图15结果表明,随着参数L的增加,两种方法的平均成功概率都在增加,而基于熵的ELSH从0.82缓慢增加到0.92左右,本文方法从0.88增加到0.94左右,表明本文方法优于基于熵的ELSH。 图15 查询平均成功概率对比Fig.15 Average success rate comparison 图16表明,在查询性能方面,随着参数增加,本文方法的查询时间在2.1 ms左右,比较稳定,而ELSH的平均查询时间是本文方法的两倍左右。以上试验结果表明,本文方法具有较好的平均查询成功概率和查询性能。 图16 查询时间对比Fig.16 Query time comparison 本文使用多探测局部位置敏感哈希技术,对菊花表型相似性进行了初步研究。植物的表型重要表现是外观,其相似性研究对菊花形态的变化、不同菊花品种之间的演变等具有重要作用。通过提取菊花的SIFT特征并对特征进行K-means聚类,构建了菊花图像的BoVW-SIFT模型。鉴于高维性质对菊花图像计算性能的影响,提出采用近似查询方案,其中基于多探测的局部位置敏感哈希针对LSH特点进一步查询优化,在提升查询效率和查询质量方面提供理论保证。 系统中多探测LSH通过哈希表个数L、哈希函数个数t和探测数量T这3个参数来灵活地调整质量和查询效率。为了寻找最佳参数设置,首先根据内存容量选择哈希表个数L,然后在哈希函数个数t和探测数量T之间进行权衡。结果表明,t为14~16、L为6~12、探测次数在1 000~2 000范围内可以取得较好的结果。 为了提升菊花表型相似性计算的质量和效率,采用多探测局部位置敏感哈希技术,提取菊花的SIFT特征,并对特征进行K-means聚类,构建了菊花图像的BoVW-SIFT模型。在菊花数据集上进行了系统性试验测试,结果表明,查询平均成功概率可以达到0.90以上,系统的平均加速比在3.3~19.8之间。通过试验测试得出了相关参数优化选择范围。与基于熵的ELSH近似查询方法相比,本文方法在查询质量和效率方面具有明显的优势。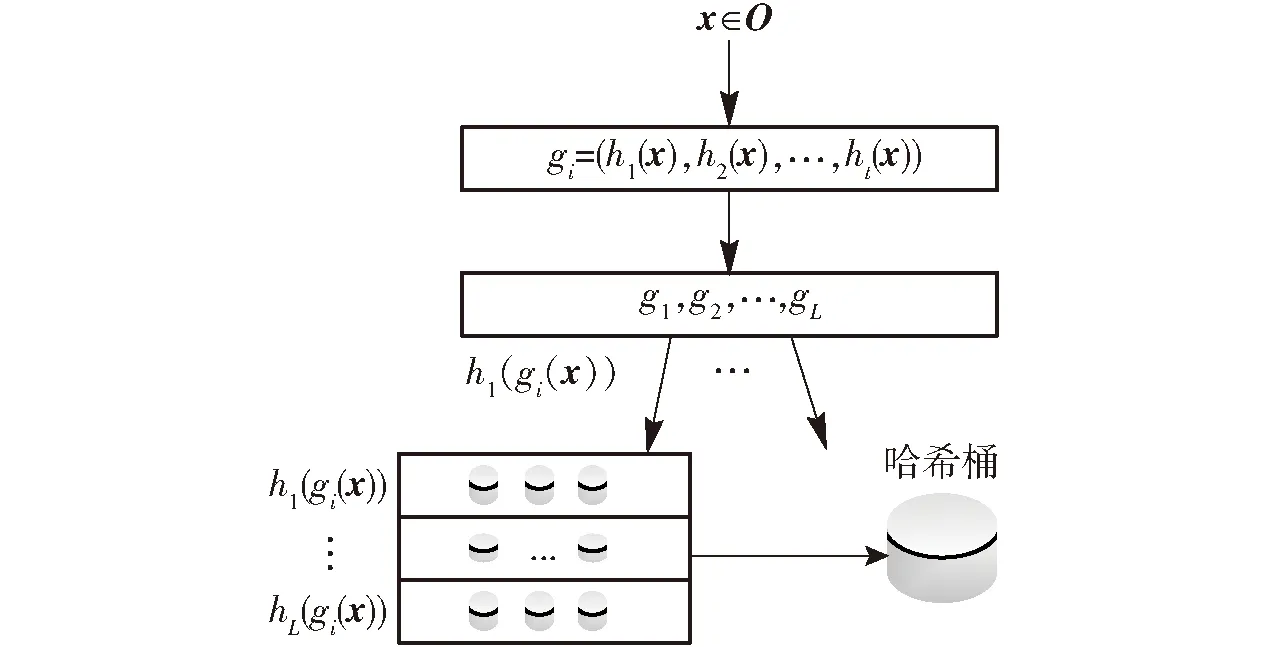

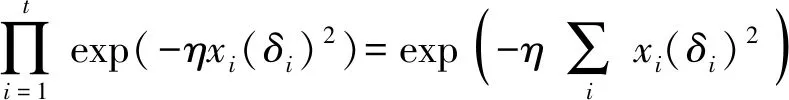
2 结果
2.1 试验环境
2.2 查询计算效率
2.3 查询结果及质量
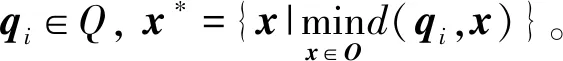
2.4 探测次数的影响
2.5 试验对比

3 讨论
4 结束语
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
河北画报(2020年8期)2020-10-27 02:54:20
现代园艺(2017年21期)2018-01-03 06:41:32
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
工业设计(2016年8期)2016-04-16 02:43:34
中国康复理论与实践(2015年10期)2015-12-24 05:42:44
计算机工程(2015年8期)2015-07-03 12:20:04
医学研究杂志(2015年5期)2015-06-10 06:43:26
现代检验医学杂志(2015年5期)2015-02-06 01:42:20
计算机工程(2014年6期)2014-02-28 01:25:40
