
基于深度学习的视频目标跟踪检测算法研究综述
2019-08-12 01:27李琴王靖
电脑知识与技术 2019年16期
李琴 王靖

摘要:基于深度学习的视频目标跟踪检测技术当中,对目标进行视频跟踪是最基本的技术之一,正确的检测到基于深度学习的视频目标跟踪,是准确地对视频每帧图像序列的基于深度学习的视频目标跟踪进行跟踪的关键所在。因此,基于深度学习的视频目标跟踪检测技术的质量标准,直接影响到基于深度学习的视频目标跟踪的好坏。本文主要介绍基于深度学习的视频目标跟踪检测常用的三种方法,并对不同的方法进行对比研究,分析其优缺点,希望对视频跟踪检测算法的深入研究提供一点帮助。
关键词:深度学习;视频跟踪;算法
中图分类号: TP3 文献标识码:A
文章编号:1009-3044(2019)16-0187-02
开放科学(资源服务)标识码(OSID):
1 前言
视频和图像处理的基础是基于深度学习的视频目标跟踪检测,基于深度学习的视频目标跟踪检测的准确度是高层次的处理工作是否能顺利进行的直接因素,需要高准确度的检查行为主要包括三个,第一个是对后期的目标的跟踪准确度,第二个是对目标的识别准确度,第三个是对场景理解的准确度。虽然我们常见的基于深度学习的视频目标跟踪检测方法多种多样,但由于目标通常速度是时变的而且随着时间改变的路径和速率是无规律的,这也是这种检测技术的难点之所在。再加上检测时外部信息的干扰,有太多的噪音夹杂在目标特征之中,所以,基于深度学习的视频目标检测的准确度很难得到保证,是一个亟待解决的问题。
根据拍摄器材与基于深度学习的视频目标跟踪之间运动状态的不同,基于深度学习的视频目标跟踪检测方法通常被分成两大类,第一类是在动态背景下对目标的检测,第二类是静态背景下对目标的检测,当录像仪器不动,只有检测目标移动,这就是静态背景下的基于深度学习的视频目标跟踪检测;而动态背景下的运动检测是指拍摄器材在监视过程中运动,被检测的物体在录像仪器的镜头下也在移动,使得对物体的跟踪变的复杂多变。现在通常使用的静态背景对目标的检测的方法有三种:第一种是光流法(0ptica1 f1ow),第二种是帧差分法(frame difference)第三种是背景差分法(backgr0und subtracti0n)。由于其各自的实现原理不同,其使用的场合也有所不同。
2 视频目标跟踪检测的常用方法
2.1 目标跟踪方法概述
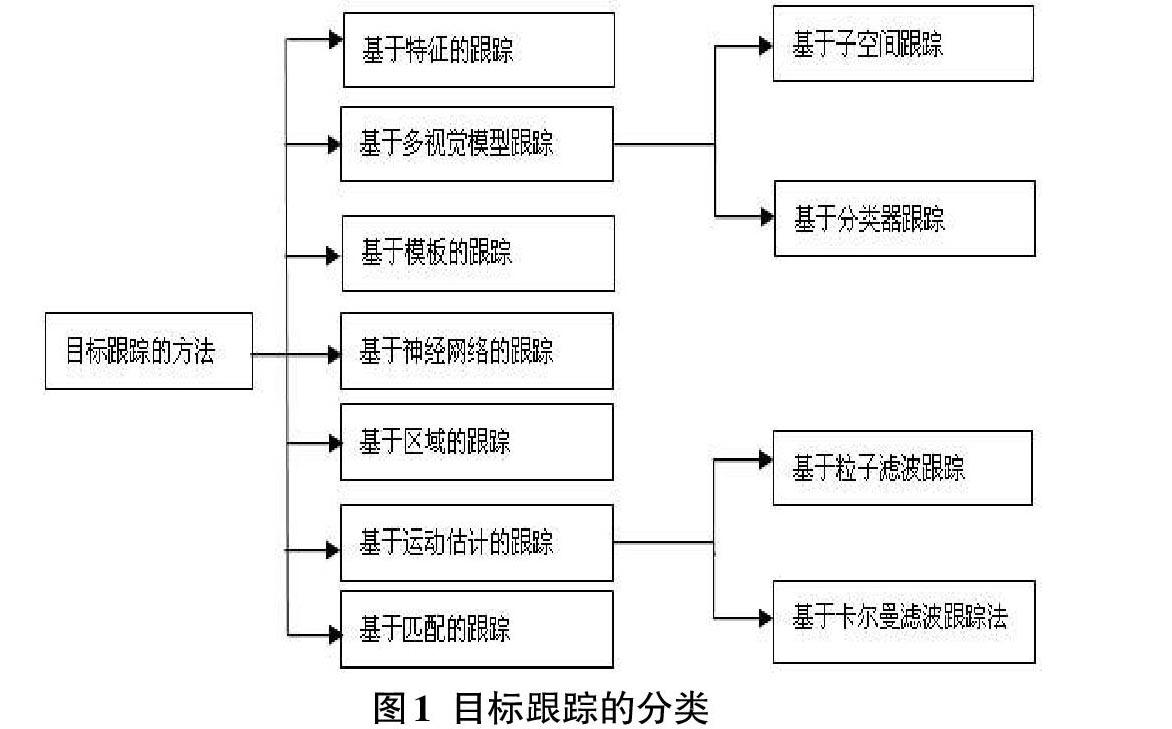
近年来,由于国家对科研项目的重视,使得基于深度学习的视频目标跟踪技术也迅速的发展,在基于深度学习的视频目标跟踪领域国内外专家学者都进行了大量的研讨学习,许多目标跟踪的算法被提了出来。一般情况,根据特定的情况适用于对应的特定方法,跟踪的对象不同、适用场合的不同也就有了多種不同的分类方法,按照拍摄器材在跟踪过程中运动状态的不同,可以分为静态背景下的目标跟踪和动态背景下的目标跟踪;按照跟踪拍摄器材数量的不同可分为单设备跟踪和多设备跟踪,如图1所示。
2.2 视频目标跟踪检测的常用方法
1)光流法
早在二十世纪五十年代Gibs0n就提出了光流的概念,这一概念的意思是当物体运动时,拍摄出来的画面的每一个像素点的瞬时移动速度就称为光流。为了从序列图像中近似计算出图像的运动场,进而研究光流场。所以,计算光流场是光流法的主要作用,也就是在合适的平滑约束性条件下,按照图像序列的时空梯度估算运动场,通过对运动场的变化进行分析,对基于深度学习的视频目标跟踪和场景进行分割。
在监视场景中目标发生移动,灰度模式运动在物体表面形成这就是光流场,以假设目标的灰度梯度基本恒定为基础是这种方法最主要的特征。光流指的是灰度图像的表面运动,基于深度学习的视频目标跟踪的三维速度矢量反应在成像平面上的投影实际上是光流中所包含的基于深度学习的视频目标跟踪的信息,其反映了在图像中的瞬时变化。光流法的工作流程,首先对所在环境中目标的结构与运动状态的关系进行分析,然后对图形灰度随时间的变化进行分析,最后实现目标检测[33]。使用光流法的最大好处在于录像设备是否运动对拍摄结果没有影响,不需要考虑目标的背景环境信息。但是光流法也有它的不足之处,即计算量庞大,算法复杂且耗时,很难实现目标的实时检测,并且环境其他影响较大,抗噪差,因此实现起来很复杂,在实时监控很难应用。
2)帧间差分法
两帧差法,又叫帧差分法。在连续的两帧到三帧的图像里,将检测目标的灰度阈值化,然后提取图像当中检测目标所在的运动范围,以此检测基于深度学习的视频目标跟踪。因为只用检测相邻帧图像之间的差异,所以是一种简单实用的方法。一方面,计算量不大,另一方面,实时性很强,再有就是在检测中使用广泛 [34]。
当录像设备处于不动时,拍摄出视频图像,然后在视频图像里取出连续的序列,对第一帧图片[fk(x,y)]以及第二帧帧图片[fk-1(x,y)]做两个处理,第一个是平滑噪处理,第二个是帧差法处理,也就是用第一帧图片[fk(x,y)]减去第二帧图片[fk-1(x,y)],得到二值图像[Dk(x,y)]。公式表示如下:
对相同环境下所拍摄的连续两帧图像进行差分处理,就得到了差分图像Dk(x,y),这时候由于是相同的背景,所以进行查分时,连续的两帧图像的灰度是不会改变的,所以两张图像的差分图像去掉了背景图像,而背景灰度和基于深度学习的视频目标跟踪有很大的不同,且在相邻两帧图像中的位置也不一样,所以基于深度学习的视频目标跟踪在两帧图像相减后就很明显了。帧差分法的最大好处在于,外界的光线发生改变时对这种方法进行检测的效用影响很小,对动态条件下的检测结果稳定有效,在基于深度学习的视频目标跟踪的变化明显时跟踪效果很好。其中,T的选择可根据经验获得。若T选取的太大,可能出现较大的空洞甚至漏检的检测目标,若T选取太小,对于运动变化较慢的目标检测的将会出现大量噪声,影响准确性。但是同时,因其对图像中目标入侵能够快速判别,所以也得到了广泛的应用。帧间差法原理图如图2所示。
3)背景差分法
背景差分法,又名背景减除法,基于深度学习的视频目标跟踪的检测是对比图像序列中当前图片和背景模型图片。这个方法是在视频上建立背景图像的像素模型,设定阈值,对比每帧图像和背景图像,将两幅图像像素差别大于阈值的像素点看作是基于深度学习的视频目标跟踪,像素差别小于阈值的像素点看作是背景。该方法需要考虑背景模型的表示方法,初始化以及背景模型更新的方法等。
采用背景差分法对其进行差分处理,得到的图像是二值图像[Mk(x,y)],在这个二值图像里,白色的区域表示检测到的前景,黑色区域代表背景。
首先,背景模型[Bk(x,y)]是通过图像进行统计建模后得到的,将当前帧图像[fk(x,y)]与背景帧图像[Bk(x,y)]相减,比较相减后图像中的像素值与阈值T,如果说图像的像素值比阈值要小一些,就说明这是背景像素,如果说图像的像素值比阈值要大一些,就说明是目标像素,这样就成功的检测出了目标像素,再将其二值化,再用形态学处理二值化以后的目标图像提高被检测出的图像的质量[2]。背景差分法的主要特点有两个,一个是这种方法能够提供全面的目标特征,第二个是这种方法对目标的位置进行提取的速度和精度就很高。本课题通过对上述几种方法的对比,在基于深度学习的视频目标跟踪的检测中最后决定采用背景差分法进行检测。
使用背景差分法做目標图像跟踪检测首要的工作是将背景模型建立起来,方法多种多样,其中,用得最多是高斯背景模型里的自适应背景模型,高斯背景模型有两种类型,一种单高斯模型,另一种是多高斯模型。对于模型的选择主要遵循以下原则:第一,如果背景点的颜色很集中,应该使用单高斯模型;第二,如果像素点离散度高就应该使用多高斯模型,共同描述图像模型需要多个分布模型。但是背景环境的信息都能通过图像模型反映出来,所以这种方法只适合应用在背景变化较小的场景中,如图3所示。
3 结论
本文介绍的几种跟踪方法各有优缺点,对于杂波下的目标跟踪,基于神经网络的算法是一种最优选择的算法,它有很好的跟踪效果,其缺点是需要经过大量训练,运算任务繁重将对计算机造成一定的计算负担。总体来说,现在的目标跟踪方法下特定算法应用与特定问题是相对应的,只要是在复杂变化的跟踪场景下算法的适应能力就会变得很差。
参考文献:
[1] 戴凤智,魏宝昌,欧阳育星,金霞.基于深度学习的视频跟踪研究进展综述[J/OL].计算机工程与应用:1-14[2019-0403].http://kns.cnki.net/kcms/detail/11.2127.tp.20191644.016.html.
[2] 吴润泽.基于学习、检测的目标稳定跟踪[D].中国科学院大学(中国科学院光电技术研究所),2018.
[3] 周辉.基于深度学习的多目标跟踪算法研究[D].电子科技大学,2018.
【通联编辑:张薇】
猜你喜欢
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
西安工程大学学报(2016年6期)2017-01-15
江苏教育·中学教学版(2016年11期)2016-12-21
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
现代防御技术(2016年1期)2016-06-01
