
生成式对抗网络在图像补全中的应用*
2019-08-12 02:11:24郭小明李芹芹张露月
计算机与生活 2019年8期
时 澄,潘 斌,郭小明,李芹芹,张露月,钟 凡
1.辽宁石油化工大学 计算机与通信工程学院,辽宁 抚顺 113001
2.辽宁石油化工大学 理学院,辽宁 抚顺 113001
3.山东大学 计算机科学与技术学院,山东 青岛 266237
1 引言
图像补全是一种在图像缺失区域中填充替代内容的技术。使用该技术,可以为图像中的缺失区域根据某种规则进行补全,使补全后的图像达到以假乱真的效果。目前,已有多种方法应用于图像补全领域,但是由于对补全效果的高要求,图像补全仍然是一个具有挑战性的研究方向[1-2]。
对图像进行补全不仅要考虑图像纹理细节的合理性,也要考虑图像整体结构的统一性,生成式对抗网络(generative adversarial networks,GAN)为图像补全提供了新的思路。
本文提出了一种基于GAN的图像补全方法。GAN模型由生成器模型和判别器模型两部分组成。生成器模型和判别器模型均采用卷积神经网络(convolutional neural network,CNN)实现。首先,通过生成器模型进行图像补全;然后,利用判别器模型对图像的补全效果进行判别。其中,判别器模型又分为整体图像判别器模型和局部图像判别器模型,整体图像判别器模型将整幅的补全图像作为输入,从整体上判别图像场景是否具有一致性,而局部图像判别器模型只判别以补全区域为中心的局部区域的纹理细节信息。
通过对GAN模型进行迭代训练,得到稳定的网络模型。在每一次的迭代训练过程中,首先更新判别器模型,以便正确区分输入的图像是真实的图像还是补全的图像;然后更新生成器模型,使图像的缺失区域有更好的补全效果。
2 相关工作
图像补全是数字图像处理领域的重要研究方向,在老照片的修复、图像冗余场景的去除以及图片场景的合理化延伸等方面有着广阔的应用前景。
基于扩散的图像补全方法,是一种较为传统的图像补全手段。该方法使用缺失区域周围的信息来补全图像,例如Ballester等[3]提出的基于等照度线进行传播的方法。但是,基于扩散的方法只能填充面积小的或者狭窄的缺失区域,对于面积较大的区域补全效果并不理想。
相较于基于扩散的图像补全方法,基于样本块的方法可以用来填充图像中较大的缺失区域。基于样本块的图像补全方法由Efros等[4-5]在纹理合成理论中首次被提出,该方法从图像的完好区域中截取与缺失区域周围纹理相同的样本块,填充到缺失区域中来完成图像的补全。后来,基于样本块的图像补全方法进一步发展,例如Criminisi等[6]提出的优化样本块搜索的方法,Wexler等[7]和Simakov等[8]提出的基于图像整体的样本块填充方法,该类方法可以从图像中可获得的部分搜索与缺失块相似的区域来填充缺失区域,取得了较好的补全。但是此方法太依赖于图像的已知部分,如果已知部分不存在这样的相似块,那么将不能较好地补全缺失区域。Hays等[9]提出了一种使用大型图像数据库的图像补全方法。该方法首先在数据库中搜索与待补全图像最为相似的图像,然后截取相似图像中与缺失区域相对应的片段,最后将截取的片段填充到缺失区域完成图像的补全。但是,该方法是以数据库中包含与待补全图像相似的图像为前提的,极大地限制了方法的适用性。
为了解决待补全图像中缺失大量结构化场景的问题,提出了一些基于结构特点的图像补全方法,例如Drori等[10]提出的根据感兴趣区域进行补全的方法,Sun等[11]提出的根据图像中线条的变化进行补全的方法以及Pavić等[12]提出的根据图像的透视变换进行补全的方法。这些方法通过保留重要的结构特征来提高图像补全的质量,但是这些方法仅限于特定的结构,不具有普遍性。
近年来,随着深度学习的迅速发展,基于机器学习的图像补全方法被提出[13-14]。Zhao等[13]提出的Context Encoder的图像补全方法,利用对抗损失来补全图像缺失区域。但是,该方法存在缺失区域与非缺失区域不连续的问题,有明显的修补痕迹,在视觉效果上较粗糙;Yang等[14]提出的基于GAN的优化方法,须对每幅图像进行优化,这大大增加了计算时间和空间的消耗。
本文提出了一种基于GAN的图像补全方法。相较于之前的方法,本文的生成器模型采用马尔科夫随机场(Markov random field,MRF)与均方误差(mean square error,MSE)相结合的损失函数进行训练,以提高生成器模型的精度和对图像纹理细节的处理能力。
3 图像补全
3.1 生成式对抗网络的基本工作原理
GAN的提出,最初是受到博弈论中二元零和博弈的启发。通常,GAN中包含了一对相互对抗的模型:生成器模型和判别器模型。
生成器模型的作用是使补全的图像尽可能地逼近真实的图像;判别器模型的作用是正确区分真实的图像和补全的图像。两个模型相互博弈,二者需要不断提高各自的生成能力和判别能力,从而使补全的图像得到最佳的效果。GAN的基本工作原理如图1所示。

Fig.1 Schematic diagram of basic working principle of generative adversarial networks图1 生成式对抗网络基本工作原理示意图
3.2 卷积神经网络
CNN作为一种深度神经网络,其在图像处理方面具有突出的优势。CNN的基本功能分为两部分:特征提取层和分类器。特征提取层主要用于逐层提取图像特征,而分类器的主要工作是将提取到的图像特征进行归纳和分类。在本文中,特征提取层由卷积层和扩张卷积层构成,分类器由全连接层构成。
3.2.1 卷积层
卷积层是卷积神经网络的重要组成部分,是进行图像特征提取的重要手段。卷积层的局部连接性和权值共享性,可以很好地帮助卷积神经网络处理大尺寸图像。卷积层的计算公式可以表示为:
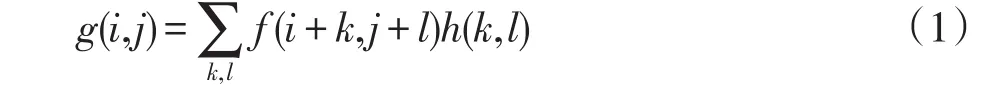
其中,(i,j)表示像素在图像上的位置,h(k,l)表示卷积核的大小。卷积的操作过程如图2所示。

Fig.2 Schematic diagram of convolution operation图2 卷积操作示意图
3.2.2 扩张卷积层
扩张卷积层是卷积层的一种变形[15],这种卷积层在权值数目不变的情况下,增大了特征图的输入面积,同时又保证了输出特征图的大小保持不变。扩张卷积的计算公式可以表示为:
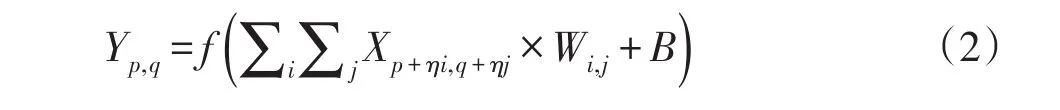
其中,Xp,q表示输入层的像素分量,Yp,q表示输出层的像素分量,Wi,j表示卷积核的大小,B表示偏置项,×表示卷积操作,η表示扩张系数,f()表示激活函数。当扩张系数η不同时,扩张卷积层可读入的特征图的面积不同。特征图在不同扩张系数下的输入面积如图3所示。
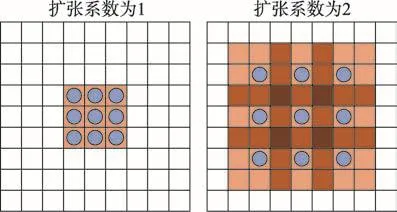
Fig.3 Schematic diagram of input area of feature map图3 特征图的输入面积示意图
3.2.3 全连接层
在使用卷积层提取图像特征的基础上,本文采用全连接层将卷积层提取到的图像特征进行分类。全连接层的输入是卷积层提取到的二维图像特征,使用与提取到的二维图像特征大小一样的卷积核进行卷积,全连接层的输出是由一个个节点组成的一维向量。
3.3 生成器模型
本文将Iizuka等[16]提出的补全网络加以改进构建生成器模型,生成器模型与补全网络模型相比减少了一个扩张卷积层,在不影响图像补全效果的前提下,降低了生成器模型的运算消耗。生成器模型由卷积层、扩张卷积层、反卷积层三部分构成。生成器模型的结构如图4所示。
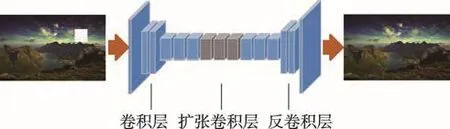
Fig.4 Schematic diagram of generator model图4 生成器模型结构示意图
在对图像进行补全之前,可以使用卷积层来降低待补全图像的分辨率:一部分卷积层的卷积步幅为2,目的是将输入的待补全图像的大小减小为原来的一半,以降低图像的存储空间和计算时间。同时,生成器模型中也加入了一部分卷积步幅为1的卷积层,目的是在待补全图像的一些特征级上提取更多的特征图。在降低了待补全图像的分辨率后,可以使用扩张卷积层进行图像补全,扩张系数η的不同正是扩张卷积层的优势所在,在不增加计算消耗的同时,成倍地扩大了可以涵盖的缺失区域的周围区域,而这也正是本文方法可以对高分辨率图像进行补全的关键所在。在补全工作完成之后,又可以参照Long等[17]提出的理论使用反卷积层将补全好的图像恢复到原始的分辨率。需要注意的是,由于考虑到图像整体纹理结构的合理性,这里仅将图像的分辨率降低到原来的1/4。生成器模型的体系结构如表1所示。

Table 1 Architecture of generator model表1 生成器模型的体系结构
3.4 判别器模型
本文根据Iizuka等[16]提出的鉴别器网络设计判别器模型,图像判别器模型分为两部分,即整体图像判别器模型和局部图像判别器模型。使用这两个判别器模型,可以判别一幅图像是原始的图像还是补全后的图像。判别器模型是采用CNN实现的,先使用卷积层不断对图像进行压缩,然后再使用全连接层对图像进行分类,判断图像的真实性,生成器模型的结构如图5所示。
整体图像判别器由6个卷积层和1个全连接层组成,它将整幅图像压缩到256×256作为输入,输出为一个1 024维的向量,所有卷积层使用5×5的卷积核,并且使用2×2的步幅来降低图像的分辨率。整体图像判别器模型的体系结构如表2所示。
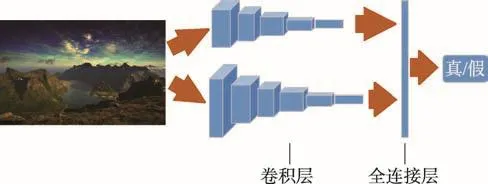
Fig.5 Schematic diagram of discriminator model图5 判别器模型结构示意图

Table 2 Architecture of global image discriminator表2 整体图像判别器模型的体系结构
局部图像判别器遵循与整体图像判别器相同的模式,但是局部图像判别器的输入是以补全区域为中心的128×128的图像块。由于输入图像的分辨率是整体图像判别器的一半,因此在构成结构上,局部图像判别器可以减少一个卷积层。局部图像判别器模型的体系结构如表3所示。

Table 3 Architecture of local image discriminator表3 局部图像判别器模型的体系结构
最后,将整体和部分图像判别器的输出连在一起,生成一个2 048维的向量,然后经过sigmoid函数的处理,得到一个0到1范围内的数值,这个数值就是该图像是原始图像的概率。
3.5 生成式对抗网络的训练
为了使补全的图像更具真实性,在使用GAN损失函数对模型进行训练的基础上,引入MRF与MSE损失相结合的损失函数对生成器模型进行训练。两种损失函数的优势相互结合,可以训练出更加稳定的高性能网络模型。
将生成器模型用G(z,θg)表示,其中,z是待补全的图像,θg是生成器中的参数,G(z)是生成器模型的输出。将判别器模型用D(x,θd)表示,其中,x是生成器模型补全后的图像,θd是判别器中的参数,D(x)是判别器模型的输出。
训练生成器模型的损失函数包括MRF和MSE损失两部分,其中MSE损失函数定义为:
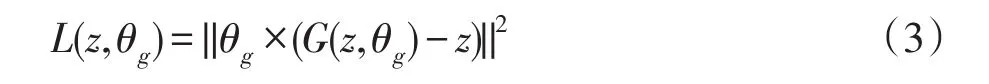
其中,×表示卷积操作,||∙||表示欧几里德范式。
在使用MSE损失函数训练生成器模型的基础上,为了进一步提高补全图像的能力,把MRF的能量函数添加到损失函数中。该能量函数的加入,将补全区域中的像素在最大概率上与其周围像素在图像特征上保持了连续性。补全区域和完好区域之间图像特征的连贯性不断加强,使得损失函数加速下降,进一步提高了生成器模型的训练效果。MRF的能量函数定义为:

其中,xi是补全区域中的像素点,xj是完好区域中的像素点,β是使图像的补全区域和完好区域保持一致性的权重参数。并将此与MSE损失相结合,最终,使生成器模型的损失函数定义为:

判别器模型的训练是通过GAN损失函数来完成的。GAN损失函数作为本文方法的关键部分,其直接将生成器模型和判别器模型的对抗过程转化成一个最小-最大问题,使得在每次对抗的过程中,生成器模型和判别器模型被联合更新。对于本文的方法,GAN损失函数可简化定义为:
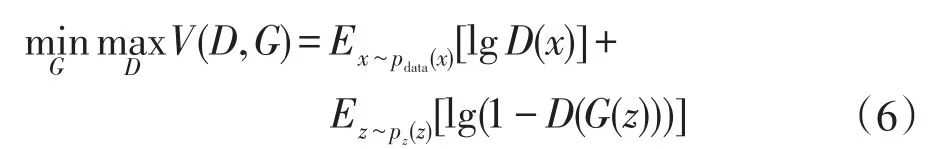
进一步将GAN损失函数与生成器模型的损失函数相结合,可得到:

其中,α是一个权重参数。
在模型训练优化的过程中,生成器模型和判别器模型的状态在不断改变,这实际意味着模型中卷积核的参数在不停地变化,直到模型达到最优状态。模型的训练优化过程可以分为两个阶段:第一阶段,使用GAN损失函数更新判别器模型;第二阶段,使用MRF和MSE相结合的损失函数更新生成器模型。模型的训练优化过程如图6所示。

Fig.6 Model training flow chart图6 模型训练流程图
4 实验验证
在实验阶段,本文GAN模型使用Python3.5和Tensorflow1.1.0进行搭建。而模型的训练,则是从Places2图像数据集[18]和SUN图像数据集[19]中随机选取的一百万幅图像,包含了多种场景的图像,提高了生成式模型对不同场景图片的补全效果。在配置为双NVIDIA GTX TITAN X的Windows平台上训练时间为两周。
本文的图像补全方法对图像的补全效果如图7所示。图7(a)是原始图像;图7(b)是待补全图像,其中的红框区域是待补全的区域;图7(c)是补全后的图像,其中的红框区域是完成补全的区域。从图7(c)可以看出,补全的区域与周围的区域在纹理结构和整体风格上保持了较高水平的一致性,进一步证明了本文的GAN模型对图像的补全效果。

Fig.7 Image completion effect chart图7 图像补全效果图
将本文的补全效果与Barnes等[20-21]提出的Patch-Match方法的补全效果、Huang等[22]提出的基于结构方法的补全效果以及Zhao等[13]提出的Context Encoder方法的补全效果进行比较。各个方法的图像补全效果如图8所示。图8(a)是原始图像;图8(b)是待补全的图像;图8(c)是PatchMatch方法的图像补全效果;图8(d)是基于结构方法的图像补全效果;图8(e)是Context Encoder方法的图像补全效果;图8(f)是本文方法的图像补全效果。虽然PatchMatch方法会从图像的完好区域提取与缺失区域相似的片段补全到缺失区域,但它并不能使补全图像的整体和部分保持一致性。基于结构的方法可以进行缺失区域的填充,但是补全效果过于模糊,使补全区域太易于区分。Context Encoder方法对图像的缺失区域的填充较合理,但补全区域在视觉效果上较粗糙。而使用本文的方法补全出的图像更加自然,更加贴近于原始图像。

Fig.8 Comparison chart of image completion effect图8 图像补全效果对比图
本文使用峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity index,SSIM)对图像的补全效果进行更加全面的评价。其中,PSNR是衡量图像失真或是噪声水平的客观评价标准,补全图像与原始图像之间PSNR值越大,则越相似。而SSIM是另一种衡量两幅图像相似度的指标,其值可以较好地反映人眼主观感受,取值范围在0到1之间,值越大,表示图像的补全效果越好。不同图像补全方法的PSNR值和SSIM值如表4和表5所示。表4和表5展示了图8中使用各种方法补全的室内图和外景图的PSNR值和SSIM值。从表中可以看出,使用本文方法补全的室内图和外景图得到了最好的PSNR值和SSIM值。
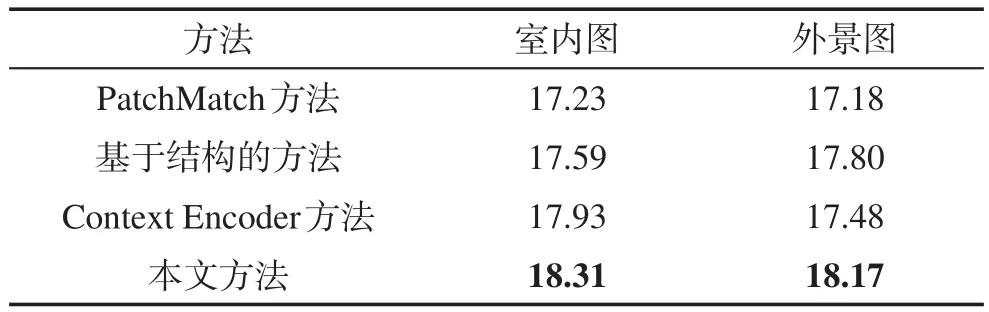
Table 4 PSNR of different image completion methods表4 不同图像补全方法的PSNR值 dB

Table 5 SSIM of different image completion methods表5 不同图像补全方法的SSIM值
5 结束语
本文提出了一种基于GAN的图像补全方法,使用MRF与MSE损失相结合的损失函数训练生成器模型,可以生成逼真的补全图像,而且与基于样本块的方法不同,生成的新片段是原图像中完全不存在的。本文方法可以应用于补全各种各样的场景图像,例如风景、建筑、墙面等,即使是很大的缺失区域,补全的结果看起来也很自然。
由于生成器模型和判别器模型都是依靠CNN实现其功能,因此GAN模型中会有多个卷积层,进而增加了模型的时间复杂度和空间复杂度。另外,训练集的选择对GAN模型的训练过程也十分重要,使用数量大、涵盖范围广的训练集训练的GAN模型可以生成理想的补全图像。因此,如何进一步简化获取图像结构特征的过程,是本文下一步的主要研究内容。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
新世纪智能(数学备考)(2021年9期)2021-11-24 01:14:34
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中学生数理化·中考版(2021年3期)2021-07-22 07:41:30
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
新世纪智能(数学备考)(2020年9期)2021-01-04 00:25:12
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28 08:43:52
电子制作(2019年11期)2019-07-04 00:34:38
今日农业(2019年15期)2019-01-03 12:11:33
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
