
领域资讯的个性化建构抽取建模研究*
2019-08-12 02:11:10任斌斌谢振平
计算机与生活 2019年8期
任斌斌,谢振平+,刘 渊
1.江南大学 数字媒体学院,江苏 无锡 214122
2.江苏省媒体设计与软件技术重点实验室(江南大学),江苏 无锡 214122
1 引言
随着网络媒体的飞速发展,人类进入信息爆炸时代,“信息过载”[1]使得用户获取信息时往往会被动地接受一部分不感兴趣的信息。而网络资讯是当前互联网中信息的重要组成部分,具有较强的时效性,用户主动去查找感兴趣的资讯既耗时又费力,因此个性化资讯服务[2]正成为一种趋势。
个性化资讯服务以智能代理[3]为基础,用户偏好为主导,结合用户的阅读习惯,定期地获取资讯并向用户做相关推送。现有主要研究包括信息抽取、用户需求描述、语义理解[4]、情感分析[5]等。目前人工神经网络[6]在这一方面表现较为出色,但其需要大量的训练数据致使系统的效率偏低。此外,用户获取资讯具有较强的选择性,如何在数量巨大的资讯中筛选最符合用户需求的信息,对提升个性化资讯服务的效率和质量有重要意义。
人的学习是个体基于现有知识、经验生成建构理解的过程。用户在阅读资讯时发挥主动性,使得自身知识建构也在不断变化。用户利用自身已掌握的知识,结合当下获取的知识,不断完善自身知识建构,这是建构主义理论[7-8]的基本思想。为此,本文结合建构主义理论,提出一种平衡组合游走策略,对用户阅读资讯、获取知识的过程进行建模分析,旨在模拟用户网络阅读中认知的建构过程,为个性化资讯服务提供新技术手段。
本文组织结构如下:第2章给出相关网页抽取技术;第3章对个性化抽取建模进行详细阐述和分析;第4章以健康领域资讯为对象,进行相关实验研究;第5章对本文进行总结。
2 相关工作
快速准确地获取符合用户需求的网页是个性化爬取的核心。主题爬虫[9]是当前个性化爬取主要的工具之一,由主题的描述、主题相关度度量和爬行策略构成。其中主题是对用户需求的具体描述,主题描述的正确性和相关度度量直接影响网页抽取的准确性,爬行策略则影响抽取的效率。
文献[10]中提出自学习主题的爬取算法,执行时用户仅需输入一组关键词,以此作为判断是否爬取网页的依据。爬取的网页处理后作为经验保存形成知识库,后续的爬取依据知识库进行,以此循环迭代更新知识库。文献[11]中提出基于“经验树”的“二次爬行”策略。“二次爬行”考虑后续的爬取受历史爬取的影响,分别对历史网页链接和内容进行分析,将二者的相关度作为爬取“经验”,存储到“经验树”中作为后续爬取的参考,减少因相关度判别导致的误判。文献[12-13]中提出结合超文本敏感标题搜索(hyperlink-induced topic search,HITS)算法提取高质量的背景知识,利用概念背景图来描述用户需求,并依据背景图估计链接的相关性,有效提升了准确率和召回率。文献[14]中提出基于概率模型的主题爬虫并引入网页质量评价指标和历史评价指标,较好地解决了“隧道穿越”和“主题漂移”[15]的问题。
上述对于用户在网页浏览过程中的动态性、选择性建模还较少考虑,文中借鉴建构主义学习理论思想,考虑用户在资讯阅读过程中的动态选择性特点,研究提出一种新的平衡组合游走建构认知资讯抽取模型。
3 模型框架
真实用户获取网络资讯时具有一定的目的性,本文将这种“目的”描述为用户兴趣。理想的模型应能够准确描述用户需求并反映兴趣与自身知识作用关系,遂提出平衡组合游走建构认知模型,模拟用户阅读资讯和认知的建构过程。首先考虑模型的基本框架,其由数据抽取模块和用户资讯建构模块两部分组成,设计如图1所示。

Fig.1 Personalized information extraction modeling framework图1 个性化资讯抽取模型框架
3.1 相关概念
概念1(兴趣点)兴趣作为用户需求的描述,一般具有多样性,不同兴趣点构成兴趣,形如:

其中,Savor为包含不同兴趣点的兴趣,poi为相应的兴趣点。为便于描述,文中的兴趣点用相关关键词词频表示,候选兴趣点用文章内的top-k关键词词频表示。
概念2(经验性)用户阅读网络资讯是一个自我学习的过程,兴趣的经验性反映了自身建构的相关性和历史性。用户的行为具有主观能动性,在阅读资讯增加自身知识储备的同时,其对事物的认识也在不断变化,因此相邻时刻用户的兴趣理论上具有一定的继承,与之对应的是用户的经验,即不同兴趣之间相同兴趣点的二元一致性:
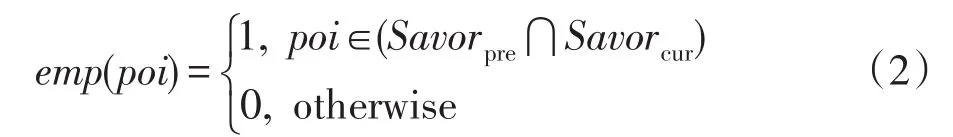
概念3(新颖性)用户在阅读资讯时,获取的新知识也常影响自身的需求,故前后时刻的兴趣一般存在一些区别。新颖性可以反映未来时刻用户认知建构的可能,以当前文章关键词作为候选兴趣点,新颖性表现为候选兴趣点未出现在前一刻兴趣的情况,即候选兴趣点与前一刻兴趣点的文本差异性:

3.2 数据抽取模块
领域资讯抽取考虑预先确定目标领域信息,并对相应的领域数据源进行甄别和筛选。数据抽取模块依据相应的领域信息对数据源进行网页抽取,具体包括领域网页抽取和页面分析。页面分析主要包括链接分析和领域文本分析;对于链接分析,采用规则提取页面内的链接过滤无关链接,并将锚文本(anchor text,At)和链接以键值对形式保存。领域文本分析是对于包含领域文章内容的网页,通过分析页面结构提取文本内容并做主题特征项抽取[16]。为便于表示和计算,采用关键词作为文本特征词。关键词提取部分包括文本分词、去除停用词和统计词频,结果以键值对保存:
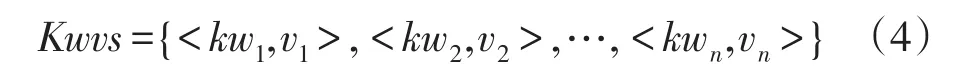
式中,kw表示相应的关键词,v表示与之对应的词频,通过计算关键词相关度判断框架中的链接与用户兴趣的相关性,确定下一个浏览的页面。由于用户对过目的事物具有短暂记忆能力,故将未访问的链接作为缓存暂时保留,并通过迭代算法生成下一时刻的兴趣。如果当前页面内没有符合需求的链接,用户则可以通过回忆近期浏览的网页,从中选取某条相关的链接并访问,如此循环,直至达到终止条件。
3.3 用户资讯建构模块
用户阅读资讯既是学习丰富知识的过程,也是建构、不断完善自身系统的过程。用户资讯建构模块负责对用户的认知进行表达与更迭,并对获取的数据进行存储。结合空间向量模型对用户兴趣进行建模[17],给予不同兴趣点各自权重以表示其受感兴趣程度,形式如下:
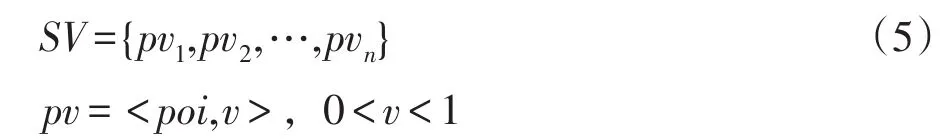
其中,poi为兴趣点,对应兴趣为Savor=<poi1,poi2,…,poin>。v表示受感兴趣程度,对应向量为vector=<v1,v2,…,vn>,v∈(0,1)。用户感兴趣则v必不为0,本文考虑用户兴趣的多样性(兴趣数大于1),故v值小于1。使用当前网页提取的top-k关键词作为候选兴趣点,结合式(4)构建候选兴趣SVcur。
本文个性化资讯抽取结合建构主义理论,充分考虑用户主观性,获取符合其兴趣的领域信息。通常用户浏览资讯后获取了一定的信息,自身的知识建构一般会改变,因此产生的兴趣也会区别于前一刻。
兴趣点更新。依据兴趣的经验性,兴趣点更新是针对前后兴趣具有的相同部分。对公共项的权重用以下公式进行更新:
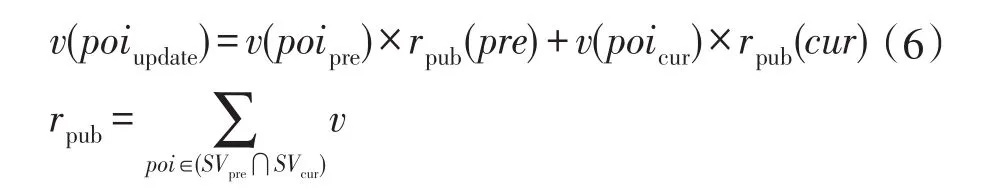
其中,rpub为各兴趣对应公共项的权重和,v(poipre)和v(poicur)分别为对应公共项的权重,v(poiupdate)为更新后的公有兴趣点的权重,故更新后的兴趣pvupdate=<poipub,v(poiupdate)>。约定SVpre⋂SVcur=∅时,用户兴趣与当前页面产生的候选兴趣点无相关性,此时用户兴趣不更新。
兴趣点增加。上文所述兴趣点的新颖性可以反映未来时刻用户认知建构的可能,故新颖性是兴趣点增加的重要依据。本文考虑使用关键词权重作为兴趣点,增加的兴趣点为候选兴趣点的若干项,作为增加的项,其必不包含在初始兴趣内,即二者差集:

其中,Savorcur为当前候选兴趣集合,Savorpre为当前兴趣集合,对应权重计算如下:
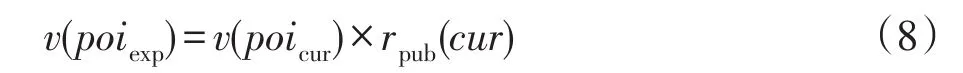
故增加的兴趣pvexp=<poiexp,v(poiexp)>。
兴趣点删除。兴趣点删除一定程度上也属于兴趣点更新。虽然本文考虑兴趣多样性,但并不意味着兴趣点越多越好,合适的兴趣量才能模拟真实用户的认知建构过程,故对兴趣点根据权重作top-k选择,权重过低的兴趣点被删除。
经过相应的更新、增加和删除,迭代后的兴趣应为:
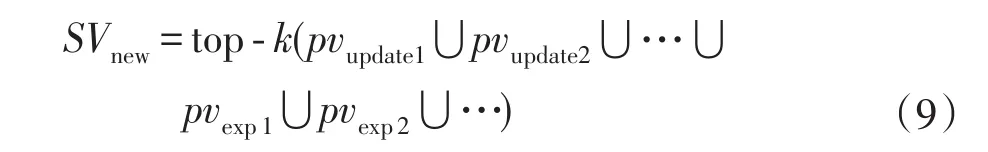
具体算法如下:
算法1兴趣建构迭代算法
输入:初始兴趣SVpre,候选兴趣SVcur。
输出:迭代兴趣SVnew。


算法中步骤1获取当前可扩展兴趣点,步骤3计算当前兴趣和候选兴趣各自的权重因子r,步骤4~5根据对应的r对初始兴趣SVpre内兴趣点的权值进行更新,并计算可扩展兴趣点的权重,步骤6~9对更新的兴趣点和扩展的兴趣点求并集,根据权值进行排序取top-k项作为迭代后的兴趣,标准化并返回。
3.4 模型实现
现实中用户通过点击网页链接来阅读网页,点击的顺序即浏览网页的顺序。不同的阅读顺序对用户认知建构影响不同,最终自身的信息储备也不同。一般来说用户阅读习惯存在差异性,因此考虑不同点击序列下,用户兴趣的建构情况。
可能有用户偏向于“最优优先”策略,即在当前页面内选出最感兴趣的资讯进行阅读。由于每次只能选出一个最优链接,并不断深入获取网页,形式上类似于深度优先策略。
另有可能用户偏向于在当前页面内选出自己感兴趣的网页,在后台中全部打开后依次阅读,形式上则类似于广度优先策略。
还有部分用户善于主动发现和获取知识,在浏览网页时,通过不断回忆阅读历程,结合当前的认知,温故知新,以获取新的网页。从此类用户学习行为方式出发,本文提出平衡组合游走策略。
平衡是指浏览网页时对网页链接的平衡选择,其本质上是深度优先与广度优先的平衡组合[18]。通常依据当前搜索需求计算分析候选网页的跳转概率,以做出局部最优选择。本文方法结合人类的阅读习惯,融入建构游走策略,图2简略描述了组合游走策略与常规策略的差异。图(a)示例了网站网页间的链接情况,其中各节点表示若干网页,相邻的网页节点间存在互链接;图(b)描述的深度优先策略下,网页的获取序列为ABCDEFGHIJ;图(c)描述的广度优先策略下的序列为ABEHCDFGIJ;图(d)描述平衡组合策略下的序列为ABDEGHCJ,其中ABD、EG、HJ为常规网页浏览路径,DE、GH为组合策略下的浏览路径,HCJ为游走策略下的浏览路径。路径HC表示,虽然网页C在最初的浏览过程中由于低相关性而被“忽略”,但随着兴趣的更迭,用户逐渐发现网页C符合自身当前的需求,遂“回忆”并浏览该网页。同理,路径CJ也是如此。

Fig.2 Comparison of different strategies图2 不同策略对比
另一方面,人脑的短暂记忆能力,使得对近期浏览的网页有较强的记忆,模仿提出网页层次优先级(pagelevelpriority)和链接新鲜度(linkfreshness,LF)。网页层次优先级是描述最近浏览网页的顺序,其数值上越大表示越近的浏览。链接新鲜度反映链接出现的时间度量,其数值上等于对应的网页优先级。考虑到网页间形成的有向图的连通性,低新鲜度的链接可能会出现在高优先级的网页内,约定此时的链接新鲜度为最大的网页优先级,即:

其中,n表示链接是否出现在当前页面内。链接新鲜度可以区别于不同历史时刻的链接记录,可以反映用户对该链接的记忆程度。用户在阅读新的网页时,原先网页的优先级和新鲜度分别递减。此外,考虑用户浏览当前页面,兴趣不发生改变的情况,依据本文策略,通过回忆近期浏览的页面确定新的访问链接。
基于上文阐述,对平衡组合游走策略进行具体描述。用网页链接池来容纳候选链接,包括网页抽取模块获取的当前页面内的链接及与模块中存储的近期保存但未访问的部分链接(即模块中的缓存链接),经过相应的计算得到下一访问链接。结合考虑兴趣点的新颖性与经验性平衡要求,设计引入如下公式进行链接重定向计算:

式中,pub(X,Y)=|{xi×yi|xi×yi≠0}|,其中|X|=|Y|。
算法2链接选择算法
输入:锚文本链接URLs_At,用户兴趣SV。
输出:重定向锚文本链接

算法中第1行表示初始化序列,第3~4行分别对锚文本分词去除停用词、计算关键词词频,第5~7行将两组关键词词频向量化,按照式(11)计算页面跳转概率,并获取跳转概率最大的锚文本和链接。
3.5 分析讨论
本文考虑以关键词辅助实现用户兴趣建模,何时建构以及如何建构是影响兴趣的重要因素。对于如何建构兴趣,前文已详细介绍。考虑实际情况中不同用户主动性与思维活跃性的差异,提出建构间隔(construction interval,CI)作为兴趣建构的时间效率描述,其数值上等于两次兴趣迭代间的网页爬取数。建构间隔较短,表明用户思维活跃,获取信息的能力较强。
互联网的实质是一个庞大的分布式网络数据库[19],其中部分网站具有较强的领域性,爬取这些网站的网页实际上是遍历网页组成的有向图。遍历的方式影响网站的爬取效率,对于用户而言,阅读网页的次序则影响其获取知识的效率。通常网页节点的出度较大,即外链数目较多,考虑模拟用户阅读网络资讯,提出平衡组合游走建构认知抽取模型。模型的关键问题在于如何平衡地选择网页链接,考虑网站的爬取深度,提出链接新鲜度(LF)作为衡量链接在时间上被选择的可能。由于用户短暂记忆能力,较新鲜的链接被选择的可能较大,故将链接新鲜度作为链接选择的标准之一。链接新鲜度影响网页的爬取范围,合理的链接新鲜度对爬取效率应有一定的提升。
个性化数据抽取模型中,复杂度主要考虑链接选择部分和兴趣迭代部分,其中读取缓存的复杂度为O(M),链接选择和兴趣迭代部分分别对链接重定向值和兴趣权重采用快速排序,因此链接选择部分时间复杂度为O(M+NlbN),兴趣迭代部分时间复杂度为O(NlbN)。考虑本文采用局部抓取,仅获取网站中部分感兴趣的网页,时间复杂度是可以接受的。
平衡组合游走的策略区别于常规的爬取策略,更加接近于人类的阅读选择习惯。该策略不追求全局爬取,仅获取自身感兴趣的部分,获取网页的同时能够根据已获取的信息对自身认知进行建构更新,符合建构主义思想。
(4)最后一公里问题突出。物资集聚于外围,无法分发到灾民手中。最后一公里问题凸显。物资投送需要多元化,可以考虑配备救灾摩托车,用于运送必要的生活用品和轻型救灾装备。
4 实验研究
4.1 实验方案
本文考虑以食品健康资讯为实验对象,对平衡组合游走建构认知模型进行性能分析。实验素材方面以食品伙伴网(http://news.foodmate.net)的食品资讯中心作为资讯抽取数据源,预爬取10 000个资讯网页作分析,以Jieba(https://github.com/fxsjy/jieba)作为分词工具对网页中提取的领域文本进行分词、去除停用词并统计词频。
为对比研究平衡组合游走策略的性能,以深度优先和广度优先策略作为参照。对于用户的兴趣建构,选取权重最高的top-k兴趣点作为更新后的兴趣,k值暂考虑10,分析模型中不同参数CI和LF下的爬取效率以及用户兴趣建构情况。区别于现有考虑爬取精度的全局爬取方法,本文从模拟用户阅读的角度出发实现抽取部分网页,故不与现有方法对比。
4.2 评价指标
网页爬取效率f是指获取的网页的相对覆盖度。通常某一资讯网站内包含大量资讯,由于其中部分资讯描述相似主题,因此网站内的主题数相对于资讯数是较少的,可以认为网页爬取效率为已获取的主题数与网站总主题数的百分比:

其中,topiccur为当前已获取的主题数,topictotal为网站内包含主题的总数,由于本文使用关键词词频作为文章的主题,随着获取的主题数不断增加,爬取效率f用以下式子近似表示:

式中,x、y分别为对应关键词的权重,numcur为当前已获取文本关键词数,numtotal为网站中所有页面文本关键词总数。
为描述用户兴趣的建构过程中的变化情况,考虑用相邻时刻兴趣的欧氏距离作为其语义距离:
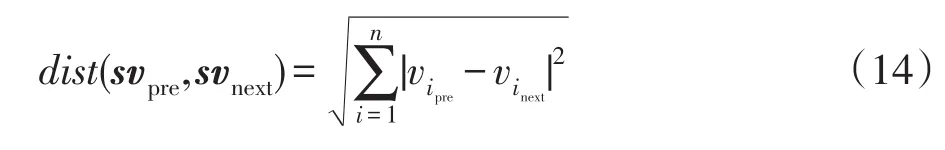
4.3 实验结果与分析
平衡组合游走的个性化爬取模型需要初始设定的参数有建构间隔CI和链接新鲜度LF。建构间隔描述兴趣迭代更新的频次,适当的建构间隔会较符合用户兴趣的建构历程。链接新鲜度描述链接被保存的历史性,鉴于用户有限的记忆能力,新鲜度较低的链接一般会选择性丢弃。
首先分析无参数下的抓取性能,考虑平衡策略与深度优先和广度优先策略的抓取效率。深度优先和广度优先暂不考虑链接新鲜度的情况,设定用户的初始兴趣为“<奶粉,0.4><国内,0.3><市场,0.2><配方,0.1>”,假设此时兴趣建构间隔为1,图3反映了三种方法抓取效率的具体情况。

Fig.3 Information extraction efficiency using DFS,BFS and balanced strategies图3 深度优先、广度优先、平衡策略下资讯抽取效率
由图3可知,深度优先的抓取效率总体上高于广度优先策略。通常网页中同一版块内资讯的主题具有一定的相似性,深度优先策略可能较容易穿越不同版块,获取更多的主题,爬取效率优于广度优先策略。平衡策略在抓取初期效率稍低于深度优先策略,但随着抓取时间的增加,以及考虑兴趣的建构更迭,后续获取的主题数逐渐增多,爬取效率也较高。
进一步分析不同参数下,平衡组合游走策略的性能。前文考虑用户自身短暂性记忆能力,提出链接新鲜度以反映链接在记忆层面被选择的可能,故不同链接新鲜度下,网页的浏览路径有差异。此外,依据不同历史记忆所产生的浏览网页顺序也会有所不同,而用户的主题信息认知建构方式也会存在个性差异,本文模型中考虑以建构间隔(CI)反映个体认知建构的能力。考虑这两点,对不同参数下的性能作分析。
图4反映了在本文平衡策略下,不同链接新鲜度(LF)和不同兴趣建构间隔(CI)下的爬取情况。可以看出,在爬取初期,不同参数下的爬取效率较相近,但随着兴趣的不断迭代,爬取效率差距较为明显。在链接新鲜度相同时,兴趣建构间隔较短,网页的爬取效率相对较高,即用户思维较活跃时,能够较高效地浏览网页。可见,LF=-3,CI=1时,模型的爬取效率最高。这一结果反映了历史记忆对获取网页信息的作用,在思维活跃时,丢弃新鲜度较低的网页可以加速用户浏览网页的速度,提高建构学习的效率。

Fig.4 Web page extraction efficiency of balanced strategies with different LF and CI图4 不同LF和CI下平衡策略的网页抽取效率
表1进一步示例地给出了LF=-3、CI=1时平衡策略下用户兴趣的变化情况。如表中所示,在爬取前5篇资讯时,用户的兴趣主要在“奶粉”“配方”“婴幼儿”等之间浮动。随着后续兴趣的不断变化,最终用户的兴趣转移到“食品”等其他兴趣点上。
进一步可知,兴趣的语义距离可反映兴趣变化发展情况。图5给出了LF=-3,CI=1时代表性模拟仿真的兴趣变化距离情况。可以看出,用户的兴趣大多数情况下虽有不同程度变化,但相对较为稳定。

Fig.5 User's interest distance whenLF=-3andCI=1图5 LF=-3,CI=1时用户的兴趣距离

Table 1 Some interest samples generated by balanced constructivist strategy withLF=-3andCI=1表1 LF=-3和CI=1时平衡建构算法产生的兴趣示例
4.4 真实用户模拟实验
为进一步分析模型性能,邀请了部分同学进行了仿真实验。实验中先告诉实验者本文的需求,即用户的预设兴趣,以指导他们获取符合需求的网页。模拟了LF=-3时,用户获取网页的情况,表2列出了LF=-3时实验者与算法模拟获取网页后部分兴趣点变化情况。
表2较为直观地反映人类用户兴趣的变化与算法模拟用户兴趣建构的情况。人类用户自身主观性较强,最终定位到感兴趣的“鸭血粉丝”上,而依据规则的模型最终兴趣点定位在“白酒”上。
图6反映了LF=-3时真实用户和本文框架中三种策略获取资讯的情况。从图中可以看到三种策略在资讯获取初期效率相当。随着获取资讯的量不断增加,用户获取资讯的效率明显高于文中三种策略。后续的资讯抽取中,广度优先策略效率最低,深度优先策略效率提升缓慢,平衡策略下抽取效率稳步提升,有逼近真实用户的趋势,这显示本文提出的平衡策略更接近用户的网络阅读行为,也一定程度上表明了平衡建构认知建模的合理性。
4.5 应用实施
考虑将本文方法应用于一个知识服务平台,以更好地提供个性化领域资讯的服务性能。相应地,平台架构如图7所示。

Table 2 Interest samples simulated by human user and model of this paper表2 人类用户与本文模型产生兴趣点对比
图7描述了该平台中个性化资讯服务的运用策略,图中虚线方框部分即本文提出的框架模型,为个性化资讯服务提供业务支撑。项目部署中涉及的语料主要包括两个来源:一方面是人工预先筛选的外部语料库,具体包括专业网络资料库和领域资讯库等;另一方面则是平台附带的检索库,二者协同为用户提供资讯服务。平台根据用户知识建构系统提供的用户特征信息,实现对外部语料库的抽取,同时补充丰富本地检索库,降低后续服务的开销。
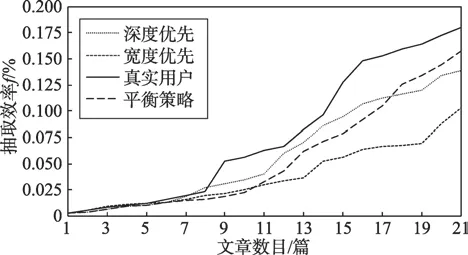
Fig.6 Comparison of efficiency between real users and method of this paper图6 真实用户和本文策略的效率对比

Fig.7 Framework of recommended application system图7 建议的应用平台架构
在用户知识建构系统中,可使用关键词词频描述用户兴趣需求,若系统经过用户信息采样后得出当前用户的兴趣为“<蛋白质,0.5><奶粉,0.5>”,其若干次读取资讯后,兴趣经过建构更新变为“<奶粉,0.362 496><婴幼儿,0.161 392>…<人之初,0.047 253><雀巢,0.042 557>”,由最初感兴趣的“蛋白质”和“奶粉”扩展到“婴幼儿”等领域相关的术语乃至部分品牌,体现兴趣的经验性与新颖性。同时平台依据本文平衡组合游走策略,抽取领域资讯并进行推送。
5 结束语
为提升领域个性化资讯服务质量,结合建构主义学习理论思想,提出了平衡组合游走建构认知的个性化领域资讯抽取模型,模拟用户网络阅读的行为。
文中的理论和实验结果表明,平衡组合游走策略相对于深度优先和广度优先策略,更加接近人类的资讯阅读过程,同时客观反映了个体知识建构过程。在实际应用中,阅读资讯的语义认知描述值得进一步深入研究,以尽可能模仿人类用户阅读行为。
猜你喜欢
中国-东盟博览(旅游版)(2020年8期)2020-08-19 09:34:28
商周刊(2018年25期)2019-01-08 03:31:08
传媒评论(2018年5期)2018-07-09 06:05:26
中国卫生(2016年12期)2016-11-23 01:09:52
小说月刊(2014年12期)2014-04-19 02:40:08
食品工业科技(2014年13期)2014-03-11 18:16:43
食品工业科技(2014年13期)2014-03-11 18:16:40
食品工业科技(2014年9期)2014-03-11 18:15:56
食品科学(2013年6期)2013-03-11 18:20:20
人生与伴侣·共同关注(2009年18期)2009-08-31 02:13:52
