
实验考试系统中的基于词频代码反剽窃技术
2019-08-12 03:43赵靖
现代计算机 2019年19期
赵靖
(安徽科技学院,凤阳233100)
0 引言
随着网络发展,在线编码在线考试系统OJ 的大量应用,有效地检测源代码克隆剽窃有着应用,是代码设计课程,作业拷贝现象尤为严重。由于编程作业这类电子文件易于拷贝,拷贝者只需要通过修改代码外观,或者增加注释、增加多余代码就可达到拷贝目的。现有文本检测工具往往只能针对某些特定的拷贝手段,检测效果和效率都比较低,也很难应用到代码中去。
1 源代码克隆与相似性检测研究现状
通过对OJ 后台源代码拷贝情况的研究发现,源代码拷贝行为不仅仅指原封不动的拷贝复制,更多的是把别人的源代码拷贝过来后稍作修改为自己所用。根据拷贝所付出的努力,常用的拷贝方式[1-4]从易到难依次为:
(1)完整拷贝;
(2)更改注释语句;
(3)更改空白区域;
(4)修改源代码格式、行数;
(5)重命名标识符;
(6)修改代码表达式中的操作数或操作符的次序;
(7)修改源代码次序;
(8)修改数据类型,但不会基本的代码执行结果,如int 改为long;
(9)添加冗余语句或变量;
(10)用更为复杂的等价语句替换原有语句。
通过对AOJ 后台的代码查看:一类学生拷贝别人的源代码是因为根本不懂怎么编程,所以采取完全复制,这样的拷贝是最简单的;还有一类是不太明白也不想花时间去学习编程,他们往往把别人的源代码复制过来做点简单修改,例如上述第(1)到第(6)类的修改,这样的修改不需要对相关知识做深入了解就可进行,所以也是一种明显的拷贝行为;另外一类是想通过模仿别人的来入手去编程,其方法也多是在别人源代码的基础上进行修改,但这样的修改往往是对相关知识已有一定了解或做了一定了解之后的修改,实际上已经涉及到了修改源代码的结构,如第(7)到第(10)类的修改。一个好的检测系统应该对上述10 种拷贝手段有比较强的检测能力,否则学生就会利用系统无法检测蒙混过关。
2 基于保留词词频分布的源代码相似度计算
2.1 保留词集合的选择
代码的特征是指根据代码的内在性质,提取出在源代码中的不易变化的修改特性:代码的物理结构,包括代码文件大小、行数,等等,这里以GCC 源代码为例,C 源代码的特征可以包含到多个方面,这些特征均可以用于定量统计来反映C 源源代码本身的特征。C语言源代码中存在许多各种类型的标识符,主要分为操作符、保留字和用户自定义标识符三大类,如表1所示。
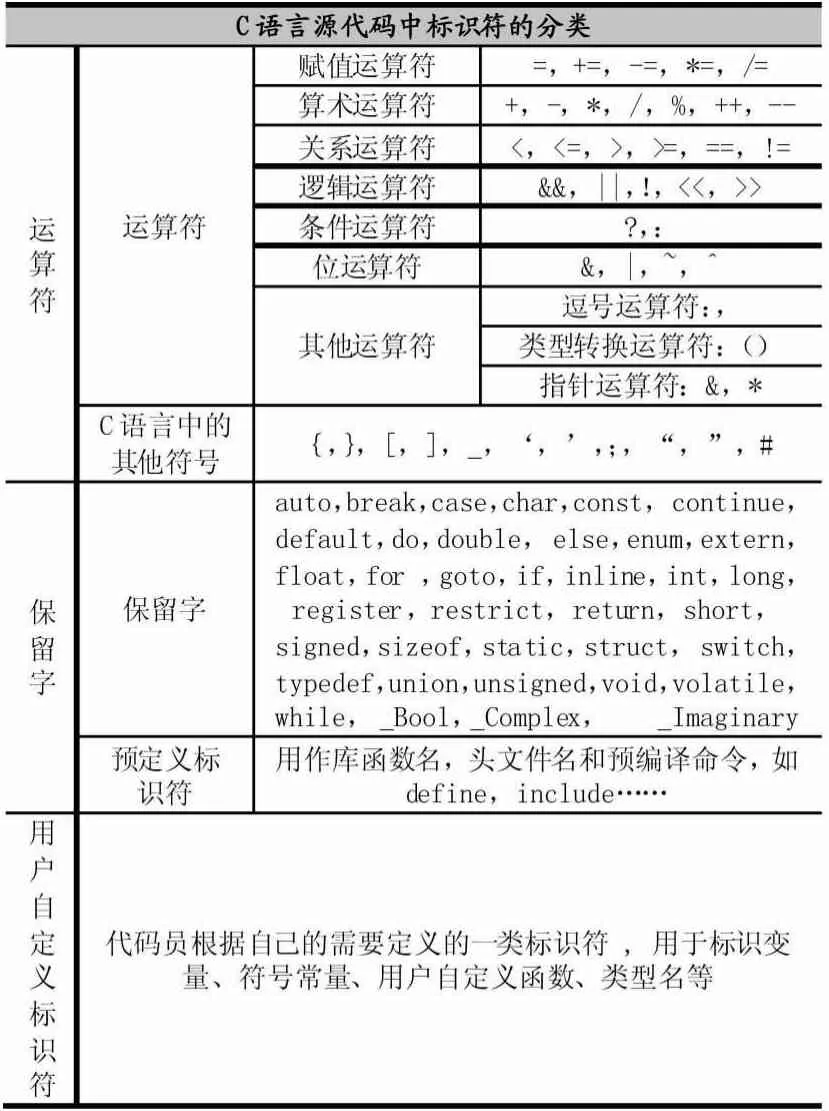
表1 高级语言的标识符分类(C 语言为例)
代码特征一般不会随代码的表现形式的变化而变化,即使修改也是少数的。所以一般而言,相似代码的特征之间存在某种内在的联系。当需要判别代码间的相似度时,可以通过统计代码的特征,获取代码特征相似度值。
2.2 基于保留词词频的源代码相似度算法
在传统的文本相似度方法的基础上,我们着重利用代码语言自身的特点——特别是代码的良构型和表达的等价性上给出如下的计算算法:
输入:代码文档簇Ci (i=1..n)_
输出:相似度矩阵Sij (i=1..n,j=1..n)矩阵S 为实对称阵,显然满足Sii=1,Sij=Sji,0<=Sij<=1
步骤:
(1)for i=1 to n,对文档Ci a) 预处理子代码:如删除注释,展开宏定义等
b) 将等价的系统保留词全部用统一的关键词替代:如for 全部替换为while,switch-case 全部替换为if else 等
c) 线性扫描统计关键词词频
d) 得到词频向量Kvi
(2)for i=1 to n
a) for j=i+1 to n-1
b) 对Kvi,Kvj 利用夹角余弦方法[2,3,5]计算相似度Sij,并排序输出
(3)利用对称性填充S
(4)输出S 结束
3 代码重复检测子系统设计与测试
3.1 代码重复检测子系统
AOJ 代码重复检测系统功能模块和逻辑结构:①预处理源代码:预处理源代码主要是解决两个问题:删除掉那些与代码结构无关的空格、注释等无用信息;把一些不影响到句子语义或代码结构的词法元素用一个规定的通用标记串去替换。由于不是用字符串比较的方法,而采用特征计数的方法,从而,空白行对本文的结果不会构成任何影响,所以预处理中不需要处理空白行。②词法分析:词法分析的任务是根据语言的词法规则对构成源代码的字符串进行分解,识别出具有独立意义的记号序列(Token)。词法规则是Token 的形成规则,它规定了符号字符Token 的起止序列。③展示出代码分析结果:展示出代码分析结果的任务是能够以3D 柱状图或3D 饼图或文本的形式展示出单个代码和两个代码的分析结果,可以仅展示保留字、常量、用户自定义标识符、预编译指令、头文件名、分界符、运算符、运算符,也可以展示全部Token 的,可以展示单个代码,也可以展示两个代码的对比情况。④计算两个代码的相似度:采用特征计数的方法计算两个代码的相似度,把每个代码分析出的特征放入Map,计算时先让每个Map 中包含所有要比较的字段(最大化),然后取出组成相应的值组成多频集合,通过集合的交集与并集求出每个字段的权重,然后相加,最后除以集合总的大小(归一化),从而求出了两个代码间的相似度,最后由相似度的值给出两个代码是否存在拷贝可能的结论。
3.2 实验数据与测试结果
为了验证基于词频的源代码相似性检测方法,我们利用JFC/Eclipse/JFreeChart 等插件技术实现了原型系统系统可以对源代码文本进行处理分析,并给出可视化分析结果与评价意见,如图2-4 所示,由于系统算法效率较高,可以对大尺寸、多文件的源代码文件计算给出实时响应。
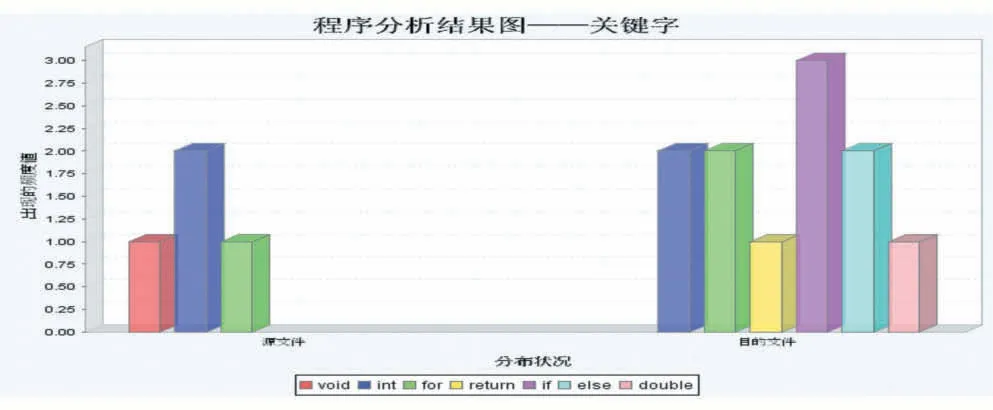
图3 样例源代码对比分析——关键字的柱状图
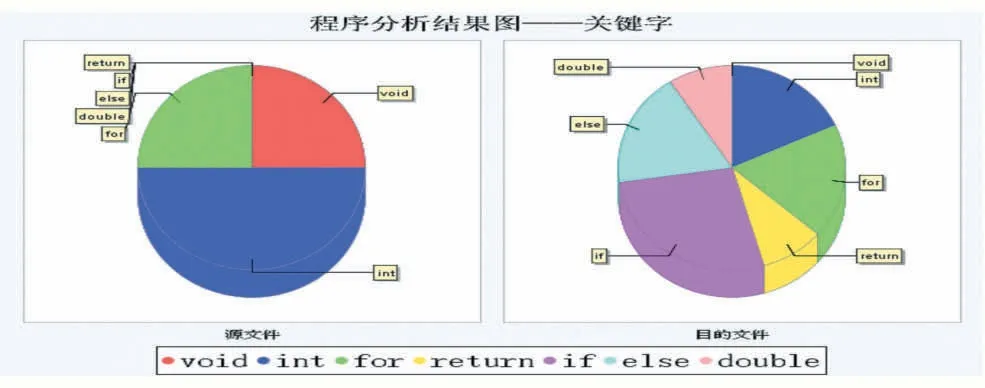
图4 样例源代码对比分析——关键字的饼图
3.3 系统测试结果
我们针对上文所述的几种常见的拷贝手段的分析做了以下的实验,包括对while-for 循环、int-long、子函数替换源代码块等替代,部分源代码来自于在线竞赛平台的服务器,其结果如表2。

图5
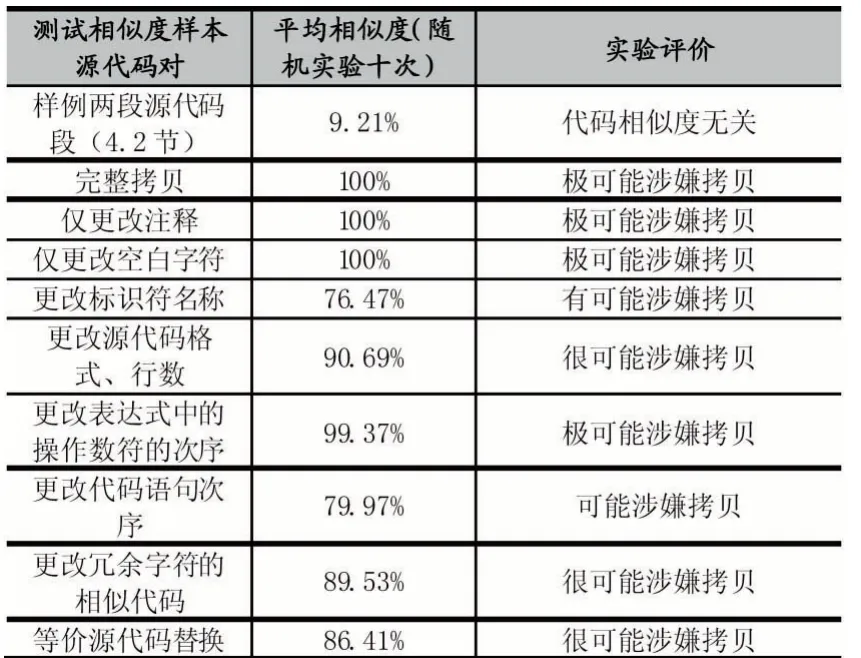
表2
4 结语
考虑到代码的高度结构化特征,以及结构化特征是依赖于代码保留词的事实,我们在传统的基于特征或者结构度量的方法基础上引入了保留字频率向量模型来检测代码间的相似性,实验表明基于保留词词频的相似性检测方法具有较强的抗干扰能力,可以克服常用的拷贝方法带来的噪声;实验效果表明可以快速检测出上述的近10 种源代码简单克隆方法,实验效果较好。以后考虑进一步改进等价保留字模型或结合代码的语义层面或引入编译优化技术和反汇编工具对源代码进行规一化,消除增加冗余源代码、重排序源代码块、替换控制结构等价等常规方法无法检测到的干扰等。
猜你喜欢
科技经济市场(2017年5期)2017-09-16
今日中国(2017年8期)2017-09-03
今日中国·中文版(2017年8期)2017-08-14
青年文学家(2017年21期)2017-07-28
读者·校园版(2015年7期)2015-05-14
诗歌月刊(2014年12期)2015-04-14
心理学报(2014年4期)2014-02-02
中学生英语高效课堂探究(2011年4期)2011-07-07
青年文摘·上半月(1982年5期)1982-01-01
