
基于邻域最小生成树的半监督极化SAR图像分类方法
2019-08-07 00:42滑文强郭岩河
雷达学报 2019年4期
滑文强 王 爽 郭岩河 谢 雯
①(西安邮电大学计算机学院 西安 710121)
②(西安邮电大学陕西省网络数据分析与智能处理重点实验室 西安 710121)
③(智能感知与图像理解教育部重点实验室 国际智能感知与计算联合研究中心西安电子科技大学 西安 710071)
1 引言
极化SAR图像分类作为极化SAR图像理解与解译的重要研究内容,近年来受到越来越多研究者的关注,并广泛应用到各个领域,如土地覆盖类型判别、地面目标检测、地质勘探、植被种类判别等[1-3]。根据分类方法中标记样本和无标记样本的利用方式,极化SAR地物分类方法主要可以分为3种类型:无监督分类方法[4,5]、监督分类方法[6,7]和半监督分类方法[8,9]。
对于极化SAR图像分类问题,监督分类方法通常比无监督分类更容易获得好的分类结果,但是监督分类方法通常需要充足的标记样本作为训练样本,而实际中标记样本的获取是非常困难,需要耗费大量的人力物力。而无标记数据获取相对容易,并且无标记的数据也能反映数据的某些信息,能够有效地帮助学习分类器。因此,如何利用大量的无标记样本对少量的标记样本进行补充辅助训练的半监督学习方法,引起了研究者的广泛关注,成为了当前研究的热点。近年来,很多半监督分类方法被提出来,如自训练(Self-training)方法[10]、协同训练方法(Co-training和Tri-training)[11,12]、标签传播聚类算法、基于图的半监督分类算法[13,14]和基于半监督的神经网络算法[15-17]等。然而针对极化SAR图像分类问题的半监督方法研究较少,Hansch[18]提出了一种基于聚类算法的半监督极化SAR分类方法,将半监督思想同聚类方法相结合,通过被选择未标记样本对聚类中心进行约束,利用未标记样本的约束影响聚类中心,获得更好的分类结果。为利用极化SAR数据中的空间信息,Liu等人[19]提出了基于邻域约束半监督特征提取的极化SAR图像分类方法。为使半监督训练中选择的未标记样本具有更高的可靠性和多样性,Wang等人[20]提出了基于改进协同训练的半监督极化SAR图像分类方法,通过协同训练的方式选择多样性的样本,通过预选择的方法增加被选择样本的可靠性。此外,结合深度学习方法和半监督学习思想,Geng等人[21]提出了基于超像素约束的深度神经网络半监督极化SAR分类方法。但是这些半监督分类方法都需要一定的标记样本,在标记样本非常少,只有几个标记像素的条件下,很难获得较好的分类结果。因此,本文针对此问题,提出一种基于邻域最小生成树的半监督极化SAR图像分类方法。该方法利用邻域最小生成树方法辅助半监督学习,在自训练的过程中通过邻域最小生成树辅助的方式选择更可靠的无标记样本扩大训练样本集,改善分类器的性能。
自训练学习方法是一种典型的半监督学习方法,该方法利用现有的标记数据训练得到的模型对无标记的样本进行预测,选择可靠性高的样本以及其被赋予的标签加入到标记样本集中,通过不断循环的自训练,逐渐增加训练集中的样本数量并逐步改善分类器性能,该方法的框架图如图1所示。由图1可以看出,自训练方法的关键是选择可靠性的样本,如果选择的样本不正确,使错误的样本加入到训练集中,不仅不能使分类器性能得到改善反而会降低分类器的性能。因此,如何选择高置信度的样本成为自训练算法的关键。而在极化SAR图像分类中,由于只有少量的标记样本,在少量标记样本下训练的分类器是一个弱分类器,直接在弱分类器的结果中选择的样本很难保证其可靠性。如果将错误标记的样本加入到标记样本集中,反而会使分类器的性能下降。因此,为增加被选择样本的可靠性,结合极化SAR图像像素间的空间信息,本文提出了基于邻域最小生成树的样本选择方法,通过邻域最小生成树辅助选择的方法增加被选择样本的可靠性。

图1 自训练方法Fig. 1 Self-training method
因此,本文算法的主要贡献为:(1)针对极化SAR图像分类中标记样本非常少的问题,提出了一种新的基于邻域最小生成树的半监督极化SAR图像分类方法,该方法同时利用未标记样本和标记样本的信息有效地提高分类正确率;(2)为增加自训练过程中被选择样本的可靠性,结合极化SAR图像像素间的空间信息,在最小生成树的基础上针对极化SAR图像分类的特性,提出了基于邻域最小生成树样本选择方法。
2 极化SAR数据
在极化SAR数据中,每个像素点都可以表示为一个相干矩阵T或协方差矩阵C

其中,HH表示水平发射水平接收,VV表示垂直发射垂直接收,HV表示水平发射垂直接收。由协方差矩阵C的矩阵表示形式可以看出,协方差矩阵是一个对角线为实数的复共轭对称矩阵,并且由协方差矩阵转换的9维特征向量通常可以作为极化SAR数据特征的一种表示,并在极化图像处理中取得良好的效果[9],该向量表示为
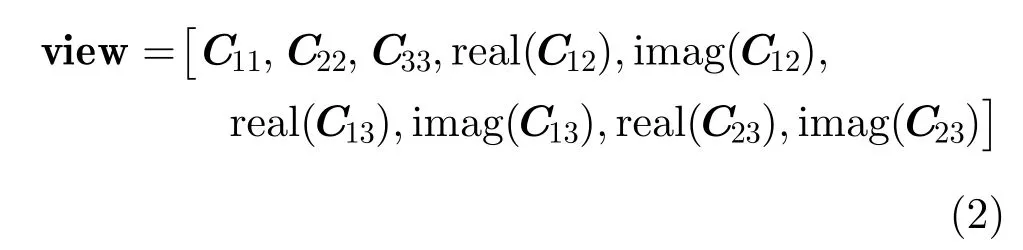
其中,real()表示实部,imag()表示虚部。
图2(a)为美国旧金山地区的极化SAR数据,图2(b)-图2(j)为由该数据的协方差矩阵转化的9维特征向量中每一元素增强10倍的灰度图。由9维特征向量每一元素的灰度图可以看出,每一元素都可以基本描述原始图像的大致信息,并且不同元素的灰度图都不相同,具有一定互补性,因此可以直接做为极化SAR图像的特征信息来描述极化SAR图像。
3 邻域最小生成树
为增强自训练过程中被选样本的可靠性,在训练过程中逐步优化基分类器,结合极化SAR图像像素间的空间邻域信息,本文提出了基于邻域最小生成树的样本选择方法。
3.1 最小生成树

由图3(a)可以看出任意两个节点都通过带权重的边相连,对于无向图G来说,可以由不同的节点出发得到不同的生成树模型。图3(b)为由权重最小的边遍历所有节点得到的最小生成树,对于无向图G来说,图3(b)是其唯一的最小生成树。

图2 极化SAR协方差矩阵中9个元素的灰度值Fig. 2 The gray value of 9 elements in PolSAR covariance matrix

图3 带权无向图G及其最小生成树Fig. 3 Weighted undirected graph G and its minimum spanning tree
本文采用Prim算法[23]计算最小生成树,该算法是一种产生最小生成树的算法。该算法从给定的顶点开始,每次选择一个与当前顶点最近的一个点,将该点与顶点之间的边加入到树中。其形式描述如下:
步骤1 输入:在一个加权无向图G中,顶点集合为V,权值边的集合为E;
3.2 基于空间邻域信息的最小生成树

步骤1 构建无向图G(V,E),其中V为顶点(已标记像素点),用式(3)计算每一顶点于其8邻域边的集合E;
步骤2 选择顶点其8邻域内与其边的权值最小的边,并对与其权值最小的像素点进行标记,然后将其作为标记样本加入到顶点集合V中;
步骤3 重复步骤1-步骤2过程直到选择完整幅图像中所有的像素点。
该方法中需要计算各个顶点之间边的距离,由于极化SAR数据服从复Wishart分布,因此在极化SAR图像中,两个像素点之间的相似距离通常采用Wishart距离[24]表示

图4为该算法的生成过程,图中绿色的矩形表示初始的顶点,灰色的矩形表示其邻域的顶点,矩形中的数字表示中心像素点与邻域像素点的距离,距离越小越相似。第1次学习过程,选择初始顶点邻域边最小的顶点,距离为‘1’的点,如图4(b)所示,然后再在新的顶点集合的邻域内选择边最小的顶点,如图4(c)所示,添加到以初始顶点为根的树的集合中,依次循环,直到选择完所有的顶点为止。
4 本文所提方法
本文针对极化SAR图像分类中只有少量标记样本的问题,为在少量标记样本的条件下获得较高的分类正确率,在传统自训练方法的基础上提出了基于邻域最小生成树的半监督极化SAR图像分类方法。该方法的核心是在自训练的过程中由大量的无标记样本中选择可靠的样本,将其添加到标记样本中,扩大标记样本的数量,逐渐优化分类器性能,最终实现提高分类正确率的目的。为此,结合最小生成树方法和极化SAR图像中像素点的空间信息,提出了基于邻域最小生成的样本选择方法,增加被选择样本的可靠性。本文所提方法的整个框架图如图5所示,具体步骤如下:

图4 基于邻域的最小生成树生成过程Fig. 4 The spanning process of neighborhood minimum spanning tree

图5 基于邻域最小生成树的半监督极化SAR分类方法Fig. 5 Semi-supervised PolSAR classification based on the neighborhood minimum spanning tree
步骤2 以初始的标记像素点为初始顶点,构建无向图G,生成多个邻域最小生成树,每一个树中的像素点具有相同的标记;
步骤3 利用初始的标记样本点,以view为每一个像素点的特征信息训练SVM分类器,并用训练好的SVM分类器对邻域最小生成树标记的样本进行测试;
步骤4 挑选由分类器测试得到的结果中与邻域最小生成树生成的结果中标记一致的样本,添加到初始的标记样本集中,更新标记样本集;
步骤5 重复步骤2到步骤4过程t次,直到得到满意的分类器;
步骤6 用训练好的分类器对剩余样本进行测试。
5 实验结果与分析

本文以SVM为基本分类器,采用径向基核函数和5倍的交叉验证,为了验证本文算法的有效性,将本文方法与传统的基于自训练的半监督方法(Self-training)[10]、基于SVM分类器的监督分类方法(采用径向基核函数和5倍的交叉验证)[26]和监督Wishart方法[27]进行比较,并用总分类正确率和Kappa系数对实验结果进行评估,所有的实验进行10次,用平均值表示最终的分类结果。
5.1 AIRSAR L波段荷兰地区的图像分类
本实验中每类别选择不同数量的标记样本(10,8, 6, 4)作为训练样本。图6(a)为Pauli分解的RGB图,图6(a1)为真实地物。实验结果如图6,表1和表2所示。图6(b)为本文方法的分类结果,图6(c)为传统Self-training算法的分类结果,图6(d)为监督Wishart方法的分类结果,图6(e)为SVM方法的分类结果。 表1为每类训练样本数量为10时不同方法的分类正确率。
由表1可以看出,本文分类方法的分类正确率为89.92%,高于Self-training分类方法12.73%,高于SVM分类方法19.62%,高于监督Wishart方法10.52%,而且本文方法中大部分类别的分类正确率都高于其它的对比方法。这主要是因为本文所提出半监督分类算法能够有效地利用标记样本和无标记样本的信息,并采用邻域最小生成树的策略辅助选择高可靠性的样本,改善了基分类器的性能。但是本文方法在Rapeseed的分类正确率只有59.58%,低于Self-training方法7.56%。由图6(b)可以看出,在本文方法中一部分Rapeseed被分为了Wheat 2和Wheat 3,这主要是这几种农作物的叶子形状非常相近,很难区别。对比图6(c)可以看出,在Selftraining方法中一部分Wheat 2和Wheat 3被错分为Rapeseed,因此虽然在Self-training方法中Rapeseed的分类正确率高,但是Wheat 2和Wheat 3分类正确率要低于本文方法的分类结果。此外本文方法在Bare soil区域的分类正确率虽然低于Wishart方法的分类正确率,但是分类正确率也已经大于96%。而且由图6(d)可以看出,Wishart方法将很大一部分Water区域错划分为Bare soil区域,使Water区域的分类正确率只有46.85%,远低于本文方法在该区域的分类正确率93.35%。由表2可以看出不同标记样本时本文方法的分类正确率都要高于对比方法的分类结果;本文方法的Kappa系数也高于对比方法的Kappa系数,而且通过对比图6中本文方法和对比方法的分类结果表示,也可以看出本文方法的分类结果的区域一致性也比其它的对比方法好。

图6 Flevoland地区AIRSAR L波段数据不同方法的分类结果Fig. 6 Classification results of the Flevoland data acquired by AIRSAR
5.2 Radarsat-2 C波段荷兰地区的图像分类
本实验中分别选择每类别为不同数量的标记样本(10, 8, 6, 4)作为训练样本。图7(a)为Pauli分解的RGB图,图7(a1)为真实地物。实验结果如图7,表3和表4所示。图7(b)为本文算法的分类结果,图7(c)为Self-training方法的分类结果,图7(d)为监督Wishart方法的分类结果,图7(e)为SVM方法的分类结果。 表3为每类选10个标记样本时,不同方法的分类正确率。
由表3和表4可以看出,本文方法的分类结果明显高于传统的Self-training方法,SVM方法和Wishart分类方法。由表4可以看出当每类训练样本数量10时,本文分类方法的分类正确率为84.03%,高于Self-training分类方法4.58%,高于SVM分类方法10.08%,高于监督Wishart方法5.22%。由表3可以看出本文方法在Urban和Cropland区域的分类正确率都要高于对比方法,但是在Forest区域的分类正确率低于监督Wishart方法的分类正确率。由图7(d)可以看出,这主要是因为Wishart方法中一部分Cropland区域被分为了Forest类,虽然Wishart方法的Water区域分类正确率高,但是Cropland区域的分类正确率只有55.27%,明显低于本文所提方法,而且本文方法Forest和Cropland区域总的分类正确率也要高于Wishart方法。而由表4可以看出选择不同数量的标记样本时,本文方法的分类正确率都要高于对比方法;同时本文方法的Kappa系数也高于对比方法的Kappa系数,而且通过对比图7中本文方法和对比方法的分类结果图,也可以看出本文方法的分类结果的区域一致性也比其它的对比方法要好。因此可以得出相同的结论,本文所提方法要明显优于传统的分类方法,尤其是在标记样本较少的情况下。
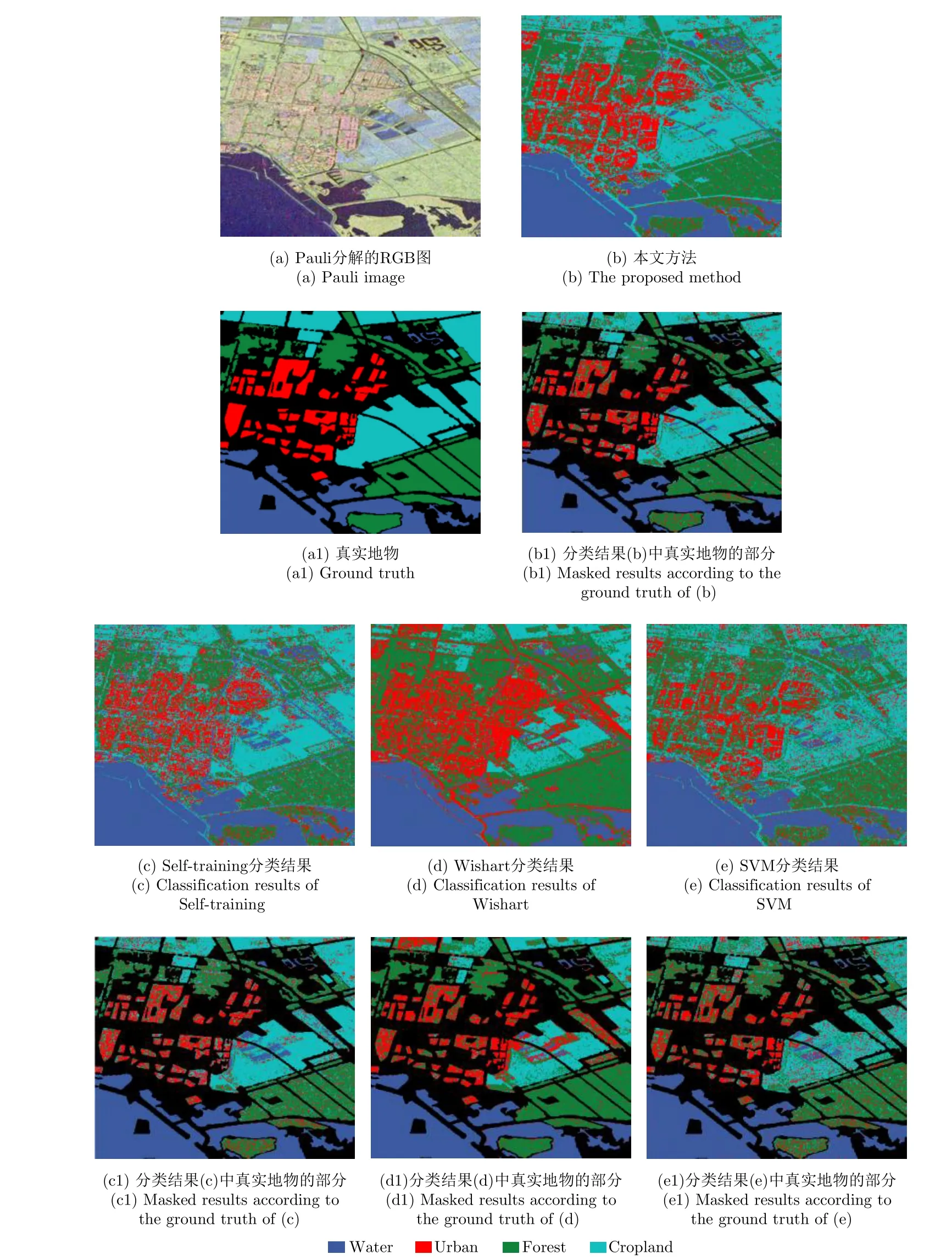
图7 Flevoland地区Radarsat-2 C波段数据不同方法的分类结果Fig. 7 Classification result of the Flevoland data acquired by Radarsat-2

图8 旧金山地区Radarsat-2 C波段数据不同方法的分类结果Fig. 8 Classification result of the San Francisco data acquired by Radarsat-2
5.3 Radarsat-2 C波段美国旧金山地区的图像分类
本实验分别选择每类别为不同数量的标记样本(10, 8, 6, 4)作为训练样本。图8(a)为Pauli分解的RGB图,图8(a1)为真实地物。实验结果如图8,表5和表6所示。图8(b)为本文方法的分类结果,图8(c)为Self-training方法的分类结果,图8(d)为监督Wishart方法的分类结果,图8(e)为SVM方法的分类结果。表5为每类选10个标记样本时,不同方法的分类正确率。
由表5和表6可以看出,本文方法的分类结果明显高于传统的Self-training方法,SVM方法和Wishart分类方法。由表6可以看出当每类训练样本数量10时,本文分类方法的分类正确率为78.71%,高于Self-training分类方法10.29%,高于SVM分类方法16.31%,高于监督Wishart方法4.94%。由表5可以看出本文方法在大部分区域的分类正确率都要高于对比方法,但是在Low-Density Urban区域的分类正确率低于监督Wishart方法的分类正确率。由图8(d)可以看出,这主要是因为Wishart方法中Low-Density Urban区域和High-Density Urban区域没有被有效地区分开,一部分的High-DensityUrban区域被错分为Low-Density Urban,导致虽然Wishart方法的Low-Density Urban区域分类正确率高,但是High-Density Urban区域的分类正确率只有42.58%,明显低于本文所提方法,而且在本文方法中这两个区域总的分类正确率也要高于Wishart方法。而由表6可以看出当标记样本数量不同时,本文方法的分类正确率都要高于对比方法;对比本文方法的Kappa系数和对比方法的Kappa系数,可以发现本文方法的Kappa系数要明显高于对比方法的,而且通过对比图8中本文方法和对比方法的分类结果图,也可以看出本文方法的分类结果的区域一致性也比其它的对比方法要好。因此我们可以得出相同的结论,本文所提方法要明显优于传统的分类方法,尤其是在标记样本较少的情况下。
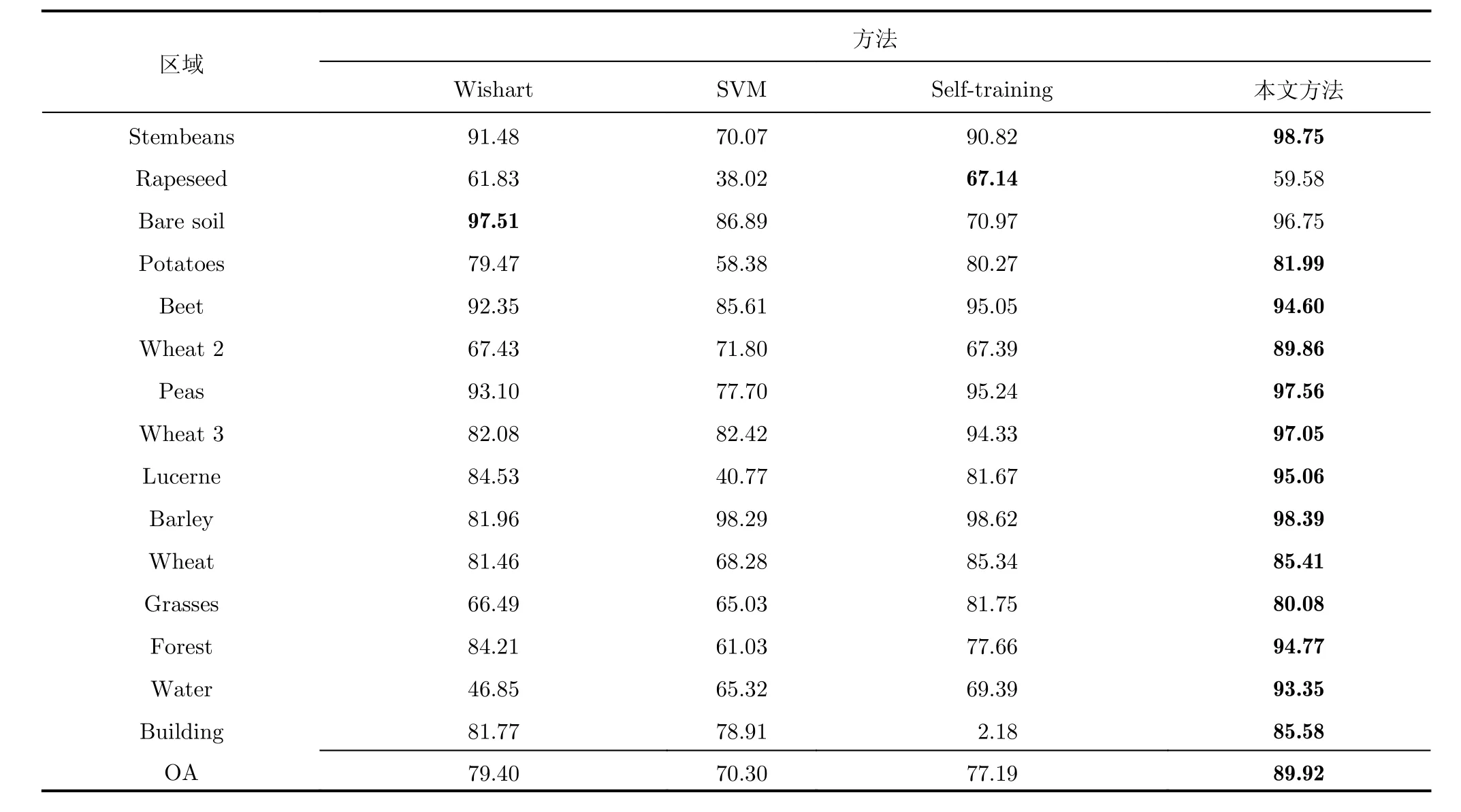
表1 AIRSAR L波段的Felvoland地区不同分类算法的分类精度(%)Tab. 1 Classification accuracy of the Flevoland area acquired by AIRSAR L band (%)
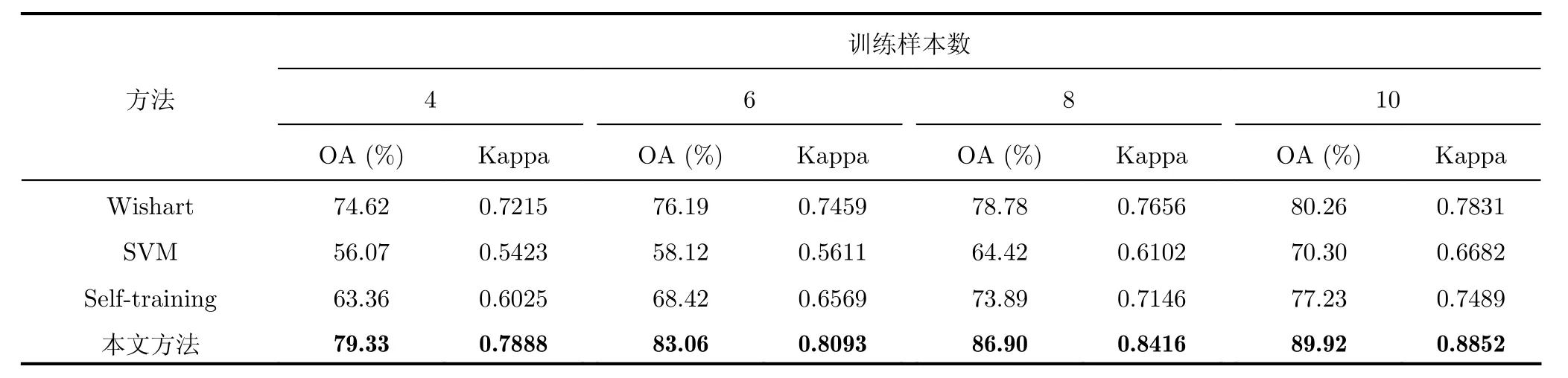
表2 AIRSAR L波段的Felvoland 地区不同训练样本的分类结果Tab. 2 Classification results of the Flevoland area acquired by AIRSAR L band with different number of training samples

表3 Radarsat-2 C波段的Felvoland地区不同分类算法的分类精度(%)Tab. 3 Classification accuracy of the Flevoland area acquired by Radarsat-2 C band (%)

表4 Radarsat-2 C波段的Felvoland 地区不同训练样本的分类结果Tab. 4 Classification results of the Flevoland area acquired by Radarsat-2 C band with different number of training samples
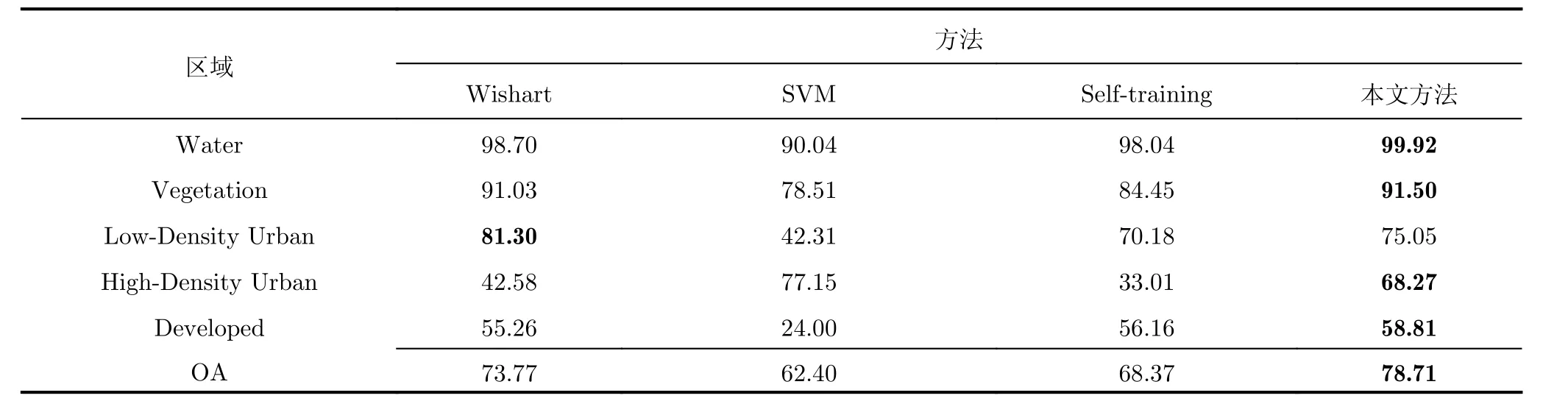
表5 Radarsat-2 C波段的旧金山地区不同分类算法的分类结果(%)Tab. 5 Classification accuracy of the San Francisco area acquired by radarsat-2 C Band (%)

表6 Radarsat-2 C波段的旧金山地区不同训练样本的分类结果Tab. 6 Classification results of the San Francisco area acquired by Radarsat-2 C band with different number of training samples
5.4 自训练次数对本文方法的影响
前面的实验已经验证了本文方法的有效性,本节分析迭代次数(自训练次数)对实验结果的影响。图9(a)为迭代次数对分类正确率的影响,由图9(a)可以看出随着迭代次数的增加分类正确率逐渐增加,当迭代次数大于8次的时候分类正确率的增长逐渐减小趋于平滑。图9(b)为迭代次数所消耗的时间成本,由图9(b)可以看出随着迭代次数的增加所耗费的时间迅速增加,这主要是因为随着迭代次数的增加,标记样本数量增加,最小生成树的种子点数量增加,最小生成树所需要的时间增加,自训练分类器的时间也增加。
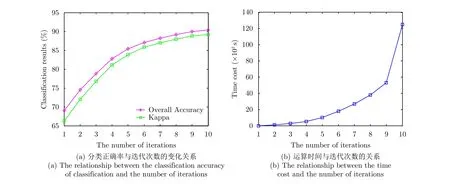
图9 迭代次数对实验结果的影响Fig. 9 The effects of number of iterations in the proposed method
6 结论
本文提出了一种基于邻域最小生成树的半监督极化SAR图像分类方法。该方法能够有效地利用标记样本和无标记样本,通过邻域最小生成树辅助学习的方式选择高可靠性的样本,添加到标记样本集中,通过自训练的方式不断扩大标记样本集,优化分类器,使在只有少量标记样本时能够获得较高的分类正确率。并对3组真实极化SAR数据进行测试,实验结果表明本文方法能够获得满意的分类结果,尤其是在标记样本非常少的情况下。而且通过选择不同比例的训练样本实验表明相较于传统的方法本文方法获得的分类精度更高。此外,通过分析迭代次数对实验结果的影响实验表明,本文方法选择的无标记样本是可靠的,通过添加被选择的无标记样本扩大标记样本集逐渐改善分类器的性能。
猜你喜欢
农业工程学报(2022年7期)2022-07-09
航天电子对抗(2022年2期)2022-05-24
电子产品世界(2022年4期)2022-04-21
北京航空航天大学学报(2021年9期)2021-11-02
逻辑学研究(2021年3期)2021-09-29
波谱学杂志(2021年3期)2021-09-07
雷达学报(2021年1期)2021-03-04
计算机系统应用(2021年2期)2021-02-23
计算机应用与软件(2020年1期)2020-01-14
航天电子对抗(2019年4期)2019-06-02
