
一种基于张量积扩散的非监督极化SAR图像地物分类方法
2019-08-07 00:42邹焕新李美霖孙嘉赤秦先祥
雷达学报 2019年4期
邹焕新 李美霖 马 倩 孙嘉赤 曹 旭 秦先祥
①(国防科技大学电子科学学院 长沙 410073)
②(空军工程大学信息与导航学院 西安 710077)
1 引言
极化合成孔径雷达(Synthetic Aperture Radar,SAR)是用来测量目标散射信号极化特征的成像雷达,它具有全天候、全天时的工作能力,能够提高目标检测、辨别和分类精度,具有可获得多通道极化图像的优越性,因此,极化SAR图像包含更丰富的地物散射信息,对极化SAR图像进行解译可获取有关地物的大量信息。极化SAR图像地物分类是极化SAR图像解译中非常重要的一个任务。
通常,根据是否需要人工标注样本数据,极化SAR图像分类算法可分为两类:监督分类算法与非监督分类算法。一般来说,监督分类算法可以达到更高的分类精度[1-4],但是人工标注样本数据需要消耗大量的时间与人力且自动化程度很低,不具备普适性。与监督分类算法相比,非监督分类算法[5-8]不仅自动化程度高,并且不需要人工标注大量样本数据,而且随着非监督分类算法研究的不断深入,分类精度也在不断地提高。因此,非监督分类算法在极化SAR图像地物分类领域愈加重要。
根据处理单元的不同,极化SAR图像非监督分类算法也可以分为两类:基于像素的非监督分类算法与基于区域/对象的非监督分类算法。基于像素的非监督分类算法[5-8]可以较为完整地保留地物的边缘与细节,但仍然会在一定程度上受到极化SAR图像中固有相干斑噪声的影响,从而导致地物分类精度不高;而基于区域/对象的非监督分类算法[9,10]可以有效地结合区域信息,从而能够较好地降低相干斑噪声对分类结果的影响,并且可以提高后续处理的计算效率,提高地物分类精度。因此,本文开展基于超像素的非监督极化SAR图像分类方法的研究。
在多种非监督分类方法中,谱聚类因其能够在任意形状的地物特征空间上取得较好的结果且能收敛到全局最优值而得到了较多应用[11]。目前,研究人员也已经提出了很多用于极化SAR图像的改进谱聚类算法。Yang等人[12]基于谱聚类提出了利用模糊C均值聚类的隶属度构建模糊相似度矩阵的算法;Hu等人[13]针对极化SAR图像利用7种不同的相似度度量构建相似度矩阵,之后再采用谱聚类以评价分类效果;考虑到在实测数据中数据点间关系不仅仅是成对度量的,Li等人[14]提出了超图谱聚类算法。但这些算法只关注到了相似度矩阵构建时的核函数选择或者距离度量问题,忽视了数据流形结构上的内在相似度关系。
在传统的极化SAR图像非监督分类系统中大多采用的距离度量不能有效考虑到数据集(图像)的全局特征信息,故由此构建的相似度矩阵就不具备足够的判别力。但是,对给定的相似性度量在图上进行扩散并学习周边信息,可以得到一个全局的相似性度量;同时在此基础上,采用在张量积图(Tensor Product Graph, TPG)上扩散[15]的相似度学习方法,能够使扩散过程根据数据内在关系在张量积图上传播全局相似性,进行上下文信息的学习并构建分类能力更强的相似度矩阵。
针对一般的距离度量无法获取数据内在的高阶相似度信息,从而无法构建更具判别力的相似度矩阵的问题,本文提出一个基于张量积扩散的非监督极化SAR图像地物分类框架。首先,采用一种快速超像素分割算法(Pol-IER算法)[16]对极化SAR图像进行过分割,从而利用区域信息克服极化SAR图像中固有的相干斑噪声的影响;其次,基于超像素提取7个具有代表性的特征:SPAN特征[17]、散射功率熵特征[5]、同极化比特征[5]、异极化率特征[18]以及HSI(Hue, Saturation and Intensity)[19]颜色特征,将这7个特征组合形成一个特征向量,并基于高斯核函数构建相似度矩阵;然后,对此相似度矩阵进行张量积扩散,得到判别能力与分类能力更强的相似度矩阵;最后,基于此扩散后的相似度矩阵进行谱聚类,获得最终的地物分类结果。本文的主要贡献如下:(1)将张量积扩散引入到非监督极化SAR图像地物分类方法研究中;(2)将本文算法与其它4种性能较优的算法进行了大量的对比分析实验,本文算法能够获得更高的分类精度,从而验证了本文算法的优越性。
2 算法描述
本文算法分为4个步骤,主要包括:(1)超像素分割;(2)特征提取与相似度矩阵构建;(3)相似度矩阵张量积扩散;(4)谱聚类。本文算法的框架流程如图1所示。

图1 本文算法框架流程图Fig. 1 The flowchart of the proposed method
2.1 超像素分割
本文直接采用先前提出的Pol-IER算法[16]来完成极化SAR图像的超像素分割。Pol-IER算法是一种用于极化SAR图像的超像素快速分割算法,主要包括4个步骤:(1)初始化;(2)不稳定点局部k均值聚类;(3)更新超像素模型和不稳定点集;(4)分割后处理。Pol-IER算法不仅可以生成具有较高边缘贴合度的超像素,并且拥有较高的计算效率。关于极化SAR图像的超像素快速分割算法的详细过程请参阅文献[16],在此不再赘述。
2.2 特征提取与相似度矩阵构建
极化特征能够客观地表征极化SAR图像中的微观结构,是极化SAR图像分类系统的基本要素。后续的处理步骤以及分类性能的优劣均取决于特征的提取。一般来说,所选极化特征的判别能力直接决定了极化SAR图像分类系统的分类性能。
为了构建判别能力更强的相似度矩阵,获得更好的分类结果,则需要从极化SAR图像中提取出具有较强判别能力的1个或者多个特征。通常,极化特征可分为两类:(1)原始极化矩阵(如散射矩阵、协方差矩阵等)以及对它们的简单数学变换;(2)经典的极化分解特征(如Freeman极化分解特征[20]、Cloude-Pottier's极化分解特征[21]等)以及对它们的简单数学变换。本文算法中采用的原始极化矩阵为协方差矩阵,采用的极化分解特征为Freeman极化分解特征以及相应的数学变换形式。本文从极化SAR图像中共提取出了7种具有较强判别能力的极化特征形成一个特征矢量以构建相似度矩阵,主要包括:SPAN特征、散射功率熵特征、同极化比特征、异极化率特征以及HSI颜色特征[5,17,18]。
在利用Pol-IER算法对极化SAR图像进行超像素过分割后,可以获得大量的超像素。为了更好地对每个超像素进行特征表示,采用如下步骤:(1)提取极化SAR图像中每个像素点处的7个特征,并组合形成一个特征向量来表示该像素点;(2)计算处于同一个超像素内的所有像素点的平均特征向量作为表示该超像素的特征向量。因此,极化SAR图像中的每一个超像素都可以用一个特征向量来表征。为了方便后续的数据处理,本文采取了min-max标准化对提取的特征数据进行了归一化处理。


2.3 张量积扩散
在传统非监督极化SAR图像分类系统中,相似度矩阵通常由数据点(像素或者超像素)间的成对相似性来决定,忽略了极化SAR图像的全局特征信息。因此,之后的研究工作提出了在图结构上将相似度度量向周围扩散的方法,考虑每一个数据点与它邻域内的点的关系,从而实现相似度的学习[15,22]。本文在张量积图上传播和扩散相似度信息,相较于原图,张量积图考虑了更高阶的上下文关系,可以更好地揭示数据的内在流形结构,以构建出具有更强判别能力和分类能力的相似度矩阵,从而提高地物分类的精度。
对于谱聚类算法,输入的相似度矩阵的判别能力直接影响着分类结果。张量积扩散能在张量积图上基于数据内在结构关系传播全局相似性。具体来说,本文以2.2节获取的相似度矩阵作为张量积扩散过程的输入,利用张量积扩散获取扩散后的相似度矩阵来作为2.4节谱聚类算法的输入,以提高极化SAR图像地物分类结果的精度。
下面首先介绍简单基于原图的扩散过程,然后再介绍基于张量积的扩散。
2.3.1 基于原图的扩散
众所周知,基于图论的扩散过程能够揭示数据点间的内在几何关系。基于图的扩散最简单的理解即图相似度矩阵的乘积(为迭代次数),但是,这一经典扩散过程受到迭代次数的制约。若相似度矩阵的行和均小于1,则基于的经典扩散过程最终会收敛为0矩阵,因此,迭代次数的设定显得至关重要。为了降低迭代次数对扩散过程的影响,可以采用对相似度矩阵进行加权的扩散形式,如式(3)所示[15]


2.3.2 基于张量积的扩散


图2 张量积图简易示例Fig. 2 An example of tensor product graph





上述算法在原图上的扩散过程等价于在张量积图上的扩散过程,但节约了大量的计算时间与存储空间。由于其等价于在原图上的扩散,因此其对存储空间的要求仍为,对计算量的要求主要取决于矩阵相乘。如果采用算法[15]进行矩阵相乘,则其计算量可降至如果张量积扩散的迭代次数,则其总的计算量为。通常,当迭代次数为20时,扩散后的相似度矩阵的分类能力可以达到相对稳定的水平,因此,在本文的实验中设置迭代次数
2.4 谱聚类
近几年来,谱聚类算法[11]由于其能够在任意形状的(地物)特征空间上取得较好的聚类结果,且具有较完善的数学框架而受到越来越多的关注。本文算法将张量积图扩散后生成的相似度矩阵作为谱聚类算法的输入,从而获得最终的分类结果。谱聚类算法的详细过程请参阅文献[11]。
3 实验结果与分析
为了评估本文算法的性能,将本文算法与其它多种算法基于一幅仿真图像和一幅实测极化SAR图像进行了对比分析实验。本文采用的仿真极化SAR图像由逆变换法[24]生成,其大小为200×200像素,相应的Pauli-RGB图像和真值图分别如图3(a)和图3(b)所示。实测极化SAR图像为ESAR拍摄的L波段极化SAR图像,拍摄地区位于Oberpfaffenhofen测试区,图像大小为700×1000像素,其Pauli-RGB图像如图4(a)所示。通过参阅文献[25,26]以及该实测极化SAR图像获取地区不同时期的光学遥感图像(其中心位置坐标为11°16′30. 84E, 48°05′20. 82N),如图4(b)所示,绘制该实测极化SAR图像的真值图如图4(c)所示。该实测极化SAR图像中主要包含3类地物:林地(Woodland)、开放区1(Open area 1)和开放区2(Open area 2)。

图3 仿真极化SAR图像Fig. 3 The simulated PolSAR image
本文实验部分的组织如下。首先,将在3.1节验证本文算法中张量积扩散的有效性;然后,有关本文算法的参数分析将会在3.2节进行讨论;最后,为验证本文分类算法的有效性,分别基于仿真和实测极化SAR图像进行了5种算法的对比分析实验,包括:基于散射功率熵和同极化比的非监督分类算法[5](Unsupervised Classification based on Scattering power entropy and Copolarized ratio,UCSC)、非监督K均值Wishart分类算法[6](Unsuper-vised K-means Wishart Classification algorithm,UKWC)、基于测地线距离的Wishart分类算法[7](unsupervised Wishart Classification algorithm based on Geodesic Distance, GDWC)、基于极化分解的Wishart分类算法[8](unsupervised Wishart Classification using Polarimetric decomposition,CPWC)以及本文算法(Proposed Method, PM)。
为保证对比实验的公平性,所有实验中的类别数目均根据先验知识预先人为给定,且均基于超像素进行分类实验,4种对比算法的实验参数则根据相应论文的最优参数进行设定。本文基于仿真和极化SAR图像对5种算法进行了大量的对比实验,并对实验结果进行了详细的分析,共采取5种常用的度量来评估分类性能,主要包括:混淆矩阵(Confusion Matrix, CM),其每一列代表了预测类别,每一行代表了数据的真实归属类别;用户精度(User Accuracy, UA),表示在分类为第类的所有像素中,其实测类型也是第类的像素所占的比例;制图精度(Producer Accuracy, PA),表示在所有实测类型为第类的像素中,被正确分类也是第类的像素所占的比例;总体精度(Overall Accuracy,OA),表示在所有样本中被正确分类的像素比例;Kappa系数(Kappa coefficient, K),综合了UA和PA用来评价分类图像的精度。
3.1 有效性分析
为了验证基于原相似度矩阵进行张量积扩散对揭示极化SAR数据内在关系的有效性,将本文算法与直接基于原相似度矩阵进行谱聚类所获取的分类结果进行对比,本文称其为OM (Original Method)。为了降低相干斑噪声的影响,本文对仿真和极化SAR数据均采取了IDAN滤波处理[27],IDAN滤波处理的滑窗大小设置为30。


图4 实测极化SAR图像Fig. 4 The real-world PolSAR image

图5 仿真极化SAR图像的分类结果Fig. 5 Classification results of the simulated PolSAR image

表1 OM方法基于仿真数据的5种评价度量结果Tab. 1 The five evaluation criteria of the OM method for the simulated PolSAR image

表2 PM方法基于仿真数据的5种评价度量结果Tab. 2 The five evaluation criteria of the PM method for the simulated PolSAR image

3.2 参数分析
在本文所提的算法中,S,k与3个参数直接决定了分类结果的好坏,并且这3个参数的不同组合也对分类结果有着重要的影响。
首先,S是极化SAR图像超像素中的初始分割网格数,决定了超像素分割的精度以及后续的数据处理量。
对于不同尺寸的极化SAR图像,应选择合适的网格大小;其次,在计算相似度时,需要构建尺度参数来消除缩放问题,因此,需要计算超像素与其k-NN超像素之间的欧氏距离;再次,是一个超参数,用于构建相似度矩阵(详细信息请参考2.2节)。此外,这3个参数之间也互相有所影响。因此,本文将对这3个参数对分类结果的影响进行深入分析。
本文主要基于实测极化SAR图像对这3个参数进行分析。超像素分割属于分类的预处理环节,只有得到一个良好的超像素分割结果,才有可能获得精度较高的分类结果。因此,本文首先就S的取值进行了实验分析,并采用3种常用评价度量进行评估,包括:边缘回调率(Boundary Recall, BR)[16]、欠分割误差(Under-Segmentation Error, USE)[16]、可达分割准确率(Achievable Segmentation Accuracy,ASA)[16]。实验结果如图7所示。从图7中的超像素分割实验结果可明显看出,针对本文给定的极化SAR图像数据,当S取值为13和15时,均可以得到较好的超像素分割结果。因此,为了便于分析比较,本文共选择了2个有代表性的S值、5个典型的k值以及5个典型的值形成参数组合,开展实验并分析实验结果。
图8展示了在不同参数组合下的OA值。虽然初始分割网格数S的值越小越接近逐像素处理,但是对比图8中的数据可以明显看出S=15时的分类精度高于S=13时的分类精度。因此,对于不同尺寸的极化SAR图像,要合理地选择超像素分割网格数。当S=15时,总体精度OA值平均可以增加4.58%;然而,当网格数S较小时则会产生有干扰性的冗余数据,并且不能有效地减缓极化SAR图像中固有相干斑噪声的影响,从而降低分类精度。

图6 实测极化SAR图像的分类结果Fig. 6 Classification results of the real-world PolSAR image

表3 两种算法基于实测极化SAR图像的整体精度和Kappa系数Tab. 3 The OAs and Ks of two methods for the real-world PolSAR image
观察图8(a)和图8(b)可发现,随着k值的增大,分类精度大体呈增加趋势。当k值较小时,邻域信息没有得到充分利用,不能较好地构建适应当前极化SAR图像的相似度矩阵,从而得到较低的分类精度。当S=15,k=14时比k=12时OA值最多可提高12.84%,至少也可提高0.48%。但是无论S取何值,都可在k=15时得到最佳的分类结果。而随着k值的进一步增大,则会造成过度缩放的情况,反而会降低相似度矩阵的判别能力,从而影响最终的分类精度。
3.3 5种算法的对比实验
3.3.1 基于仿真极化SAR图像的对比实验
本文选择的5种算法的对比实验结果如图9所示,表4所示为此5种算法的PA值、Kappa系数以及OA值。

图7 实测极化SAR图像超像素分割实验结果Fig. 7 The results of the superpixel segmentation for the real-world PolSAR image

图8 实测极化SAR图像在不同参数值S,k和时的整体精度Fig. 8 The OAs for the real-world PolSAR image under different parameters of S, k and
从表5中的数据可以直观地看出,UKWC与CPWC两种算法的分类精度最低,其OA值分别为71.62%和71.05%;从图9(b)和图9(d)中可明显看出UKWC对类别2误分严重,CPWC算法基本丧失对类别4的判别能力,这可能是由于其没有采用较多的具有良好判别能力的特征。而GDWC算法略高于上述2种算法,这是因为GDWC算法的原理是寻找两个数据点(超像素)间最短距离以构建相似度矩阵。因此,从图9(c)中可看出,其分类结果轮廓清晰,边缘贴合;但是,由于GDWC算法没有结合有效的极化SAR图像特征进行分类,因此仍然存在着较为严重的误分现象。图9(a)展示的UCSC算法的分类性能较好,但仍有部分超像素被误分。而对于本文算法,由于采用了多种典型的极化SAR图像特征,同时通过张量积扩散得以充分利用上下文高阶信息,从而得到更具判别能力的相似度矩阵,因此,本文算法的极化SAR图像分类精度最高,分类结果也最优。
3.3.2 基于实测极化SAR图像的对比实验
5种算法的实验结果如图10所示,表5所示为此5种算法的PA值、Kappa系数以及OA值。

图9 仿真极化SAR图像5种算法的分类结果Fig. 9 Classification results of five methods for the simulated PolSAR image

表4 5种算法基于仿真极化SAR图像的3种评价度量结果Tab. 4 The three evaluation criteria of five methods for the simulated PolSAR image

表5 5种算法基于实测极化SAR图像的3种评价度量结果Tab. 5 The three evaluation criteria of five methods for the real-world PolSAR image
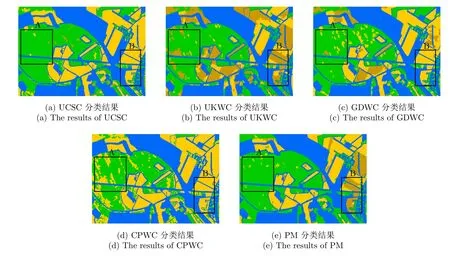
图10 实测极化SAR图像5种算法的分类结果Fig. 10 Classification results of five methods for the real-world PolSAR image
从图10(d)中可以看出图中存在很多孤立的小区域,这说明CPWC算法的分类结果受极化SAR图像中固有的相干斑噪声影响严重,如区域A所示;同时CPWC算法所选择特征较为单一且不能有效地寻找数据点(超像素)间的测地线距离,使得其在区域B中无法分类出开放区2。而UCSC算法将大量的开放区2误分为开放区1,如图10(a)中区域B所示,这说明没有较多的极化SAR特征的确会对地物的判别能力造成一定影响。图10(b)中部分地物边缘和同质区域呈现破裂不完整的现象,这可能由于UKWC算法没有充分地利用邻域相似性信息,其相应的Kappa系数为0.6666。GDWC算法的OA值可达80.74%,均高于上述3种算法,这再一次印证了寻找数据点(超像素)之间最短距离的重要性。然而,观察图10(c)中的区域A,仍然有较多的噪声,这主要也是因为其没有结合多种有效的极化SAR特征进行分类所导致的现象。综上所述,本文算法不但结合了多种典型的极化SAR特征,并且利用张量积图寻找数据流形结构上的测地线距离,可以充分学习数据的高阶相似信息,因此,其既能较为准确地区分出不同的地物,又能有效地降低相干斑噪声对分类结果的影响,这对于非监督极化SAR图像的地物分类是非常重要的。
4 结束语
本文针对利用原始的相似度矩阵进行极化SAR图像分类,导致无法获取数据内在高阶信息的问题,提出了一种基于张量积扩散的非监督极化SAR图像地物分类算法。首先,为了在提高计算效率的同时降低相干斑噪声对分类结果的影响,对极化SAR图像进行超像素分割;然后,采用常用于图像检索的张量积扩散,将基于超像素提取的7种特征构建的原始相似度矩阵进行上下文相似性信息的学习,生成判别能力和分类能力较强的相似度矩阵;最后,通过谱聚类获取分类结果。本文算法采用混淆矩阵、总体精度和Kappa系数等5个度量参数对分类结果进行全方位的评估。首先基于一幅仿真图像和一幅实测极化SAR图像,对张量积扩散的有效性进行了验证;同时,将本文算法和其它4种较优的极化SAR图像非监督分类算法进行了对比实验,验证了本文算法分类性能的优越性;并且基于实测图像对实验参数进行了分析。大量的实验结果表明,张量积扩散可以有效地度量数据流形结构上的测地线距离,充分利用数据内在的高阶信息,并获得更优的分类结果和更高的分类精度。然而,需要指出的是,如何合理地选择不同数量、不同类型的特征形成一个高维特征向量以生成判别能力和分类能力更强的扩散后的相似度矩阵,是本文未来需要进一步深入研究的问题。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小哥白尼(军事科学)(2022年2期)2022-05-25
航天电子对抗(2022年2期)2022-05-24
北京航空航天大学学报(2021年9期)2021-11-02
计算机应用与软件(2021年7期)2021-07-16
雷达学报(2021年1期)2021-03-04
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
红领巾·萌芽(2019年8期)2019-08-27
航天电子对抗(2019年4期)2019-06-02
互联网天地(2016年1期)2016-05-04
