
基于序列到序列模型的事件识别
2019-08-05 07:42:08张俊青
中文信息学报 2019年6期
张俊青,孔 芳
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
事件抽取是当前自然语言处理(natural language processing,NLP)领域的研究热点之一,具有重要的理论及应用价值,不仅推动数据挖掘和机器学习等学科理论的发展,而且其研究成果被广泛应用于信息检索等领域。事件抽取首先进行事件识别,即判别给定句子是否表示事件描述,如果是,则对事件描述进行类别的判定;识别出事件后再寻找事件的各个参与对象,并为他们分配相应的语义角色。显然,事件识别是事件抽取的基础,它的性能将直接影响后续事件参与对象的语义角色的识别。
具体而言,事件识别又包含两个子任务:事件触发词识别和事件类型确定。例如,给定句子,“Portillo acknowledged he had killed two of his former students.”事件触发词识别将识别出触发词“killed”触发了一个事件,而事件类型确定过程则将该事件归为“Life.Die”类别。基于事件识别的结果,后续事件论元的识别将进一步识别出该“Die”事件的攻击者是“Portillo”,受害者是“two of his former students”。
目前,事件识别所用的语料主要有Doddington等[1]使用的ACE数据,Kim等[2]使用的BioNLP分享的生物医疗数据和Dubbin等[3]使用的TACKBP数据。事件抽取相关的研究方法主要分为基于特征的方法和基于词表示的方法两类。其中,基于特征抽取的研究工作,大多数学者是基于句子级别信息进行事件抽取,代表性的工作有Ahn等[4]、Grishman等[5]、Li等[6]。然而,对于有些事件,只考虑句子级别信息很难判断事件所属的类型,于是部分学者把目光放转向跨句子的事件推理,如Gupta等[7],Hong等[8],Liao等[9],以及跨文档的事件推理,如Ji等[10]。近年来,深度学习在自然语言处理任务中表现优异,众多学者也开始专注基于词表示方法的事件识别研究,代表性工作包括:Nguyen等[11]利用卷积神经网络来自动学习一些特征完成触发词的识别;Chen等[12]在管道框架上,利用动态多池化卷积神经网络进行事件抽取;Nguyen等[13]构建双向循环神经网络,利用记忆单元捕获论元和触发词之间的依赖关系,同时完成论元和触发词的抽取工作;Duan等[14]通过循环神经网络利用词向量和文档向量的方法提高事件识别的性能。
基于句子级别的事件识别[15-16],虽然有其可取之处,但忽略了文档中的其他信息,限制了事件识别的性能。例如,给定句子,“Elop is the one that needs to go[注]从“ENG_DF_001471_20140717_G00A0FRCS”文档中选取”。基于句子级别的事件识别模型在识别该句子时,由于信息不足,不能充分理解Elop是从公司离职的语意,难以把触发词“go”识别为End-Position事件。但如果充分考虑事件的上下文信息,比如该文档主旨是Stephen Elop 从Microsoft离职,那么触发词“go”触发的事件类型就比较容易判别了。
此外,语料统计分析发现,相似的事件经常出现在相同的文档中,比如Attack,Injure,Die事件经常出现在同一个文档,但是很少和Transfer Money事件同时出现。换言之,一个文档中发生的事件具有一种很强的联系。
综上所述,为了减少因抽取大量特征而消耗的时间与精力,并把文档信息应用于事件抽取中,本文针对事件识别任务展开,提出了一个序列到序列(Seq2Seq)的双向循环神经网络模型,并在模型中引入注意力机制,对局部的词、实体和全局的文档信息进行统一向量化。在KBP2016测试集上的实验证明了本文方法的有效性,实验结果表明,触发词识别的F1值达到了58.56%,比实验基准1和基准2分别提高了3.76%和2.60%,而事件类型判别的F1值达到了51.82%,比实验基准1和基准2分别提高了4.83%和1.19%。
1 任务描述
根据TAC-KBP2016的定义,事件是发生的事情或导致某种状态的改变,共有8大类型和18个子类型,具体如表1所示。
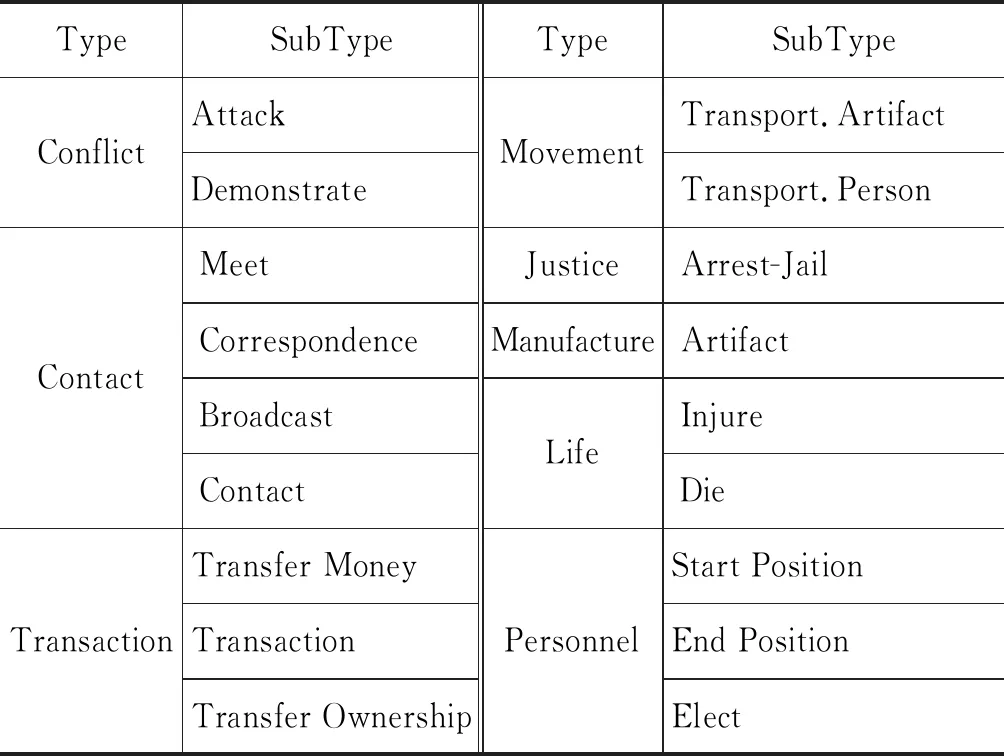
表1 TACKBP2016数据集上定义的事件类型
下面引入KBP测评中与事件相关的术语。
实体:现实世界中一个对象或者一组对象。
触发词:可以清晰表达出事件发生的主要词汇。
事件类型:事件所属的类型。
真伪性:辨别事件所属的REALIS类别(Actual,Generic,Other)。
本文着重于事件识别任务,具体包括事件触发词识别和事件类型确定两个子任务。例如,针对句子“Portillo acknowledged he had killed two of his former students”,事件识别系统需要识别出触发词“killed”和其触发的事件类型“Life.Die”。根据先前的工作[8],我们把类型分成18子类型和None类型。
2 模型
本节将详细地描述Seq2Seq模型。假设W=w1w2…wn代表句子,n代表句子的长度,wi表示句子的第i个词。E=e1e2…ek表示在该句子中的实体,k表示句子中实体的数量。本文将事件识别任务看作对触发词及其他词的序列标注问题,对于wi词,对其分配子类型标签(18类之一)或None类型标签。
2.1 句子编码
句向量是Seq2Seq模型的基础,本节将详解句向量的构建过程。将句子W编码成向量X,X中包含如下四个方面信息:
(1)W中wi的词向量,词表示可以自动学习词之间隐藏的丰富特征,将从预训练好的词向量中查找[注]https://github.com/stanfordnlp/GloVe。
(2)E中ej的实体向量,使用Stanford工具包[注]https://stanfordnlp.github.io/CoreNLP对句子进行实体识别,向量随机初始化。
(3)W中wi词性向量,词性是用Sanford工具包进行抽取的,并采取随机初始化向量的方法构建词性向量表。
(4)W的文档向量,文档还有句子之外其他的信息,并且一个文档中所发生的事件总是相关的,比如Attack 、Die和Injure事件,很有可能发生在同一个文档中。本文通过PV-DM模型[17]训练文档向量,由使式(1)最大化所得:
(1)
其中,w1,w2,…,wn是文档中包含的词,wt-m,…,wt+m是wt的上下文,m的窗口大小为7,doc是包含训练数据的向量,与词向量维度相同的随机初始化向量。
预测的工作主要通过多元分类器完成,例如softmax算法,如式(2)所示。
(2)
式(2)中,ywi是词wi非正则化的统一概率,计算方法如式(3)所示。
y=b+Uh(wt|wt -m,…,wt +m,doc)
(3)
式(3)中,b、U是softmax参数,h是将wt|wt -m,…,wt +m,doc级联或求平均得到。由于doc是共享的,每次训练中输入都包含该向量,因此能表达文档的主旨信息。
综上可知,最终的输入向量是由上述向量拼接组合而成,把句子W映射成向量X,作为Seq2Seq模型的输入。
2.2 Seq2Seq模型
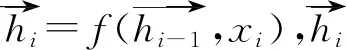
由于我们使用了BahdanauAttention[18]注意x机制的Seq2Seq网络模型,输出序列为式(4)。即隐藏状态si、语义向量ci和时间i-1的输出yi-1经过非线性变换得到时间i的输出yi。
P(yi|y1,…,yi-1,X)=g(yi-1,si,ci)
(4)
对于隐藏状态si,经隐藏状态si-1、语义向量c和时间i-1的输出yi-1非线性变换得到,如式(5)所示。
si=f(si -1,yi -1,ci)
(5)
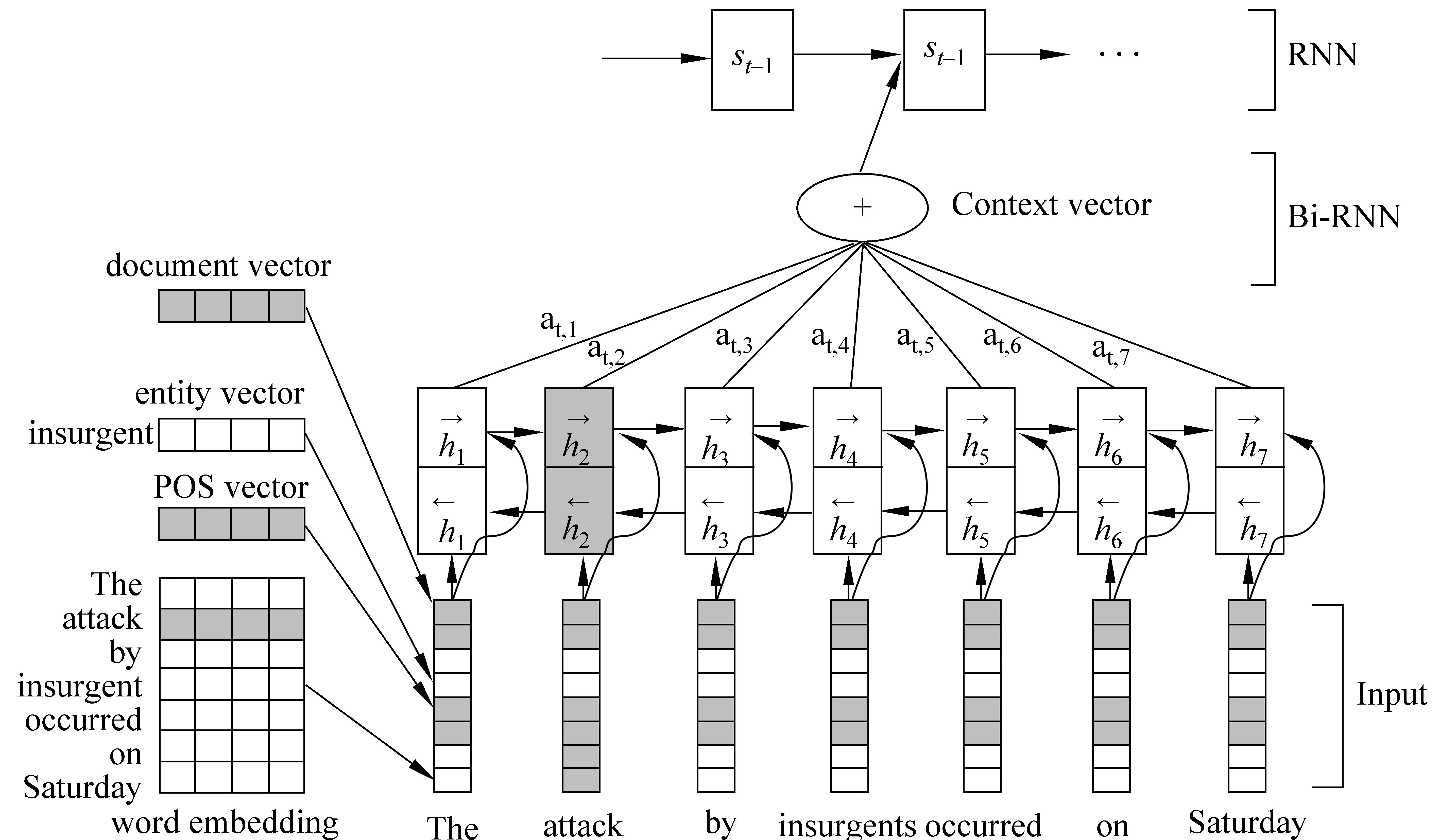
图1 输入句子“The attack by insurgents occurred on Saturday”后,识别事件Conflict.Attack示意图
隐藏状态ci等于Tx个输入向量与其权重相乘求和,具体如式(6)所示。
(6)
式(6)中权重向量αij由式(7)得到,式(7)中mij由式(8)得到,式(8)中函数a通常为非线性函数。
简而言之,相互独立的四种向量拼接成输入向量X,向量X进入Seq2Seq模型中,注意力机制通过给四种向量不同的权重以表达句子不同成分对事件识别的影响,再经过解码阶段得到相应的序列类别,根据交叉熵得到预测与标准类别的损失值,同步更新权重。
3 实验
3.1 基准平台
参加KBP2016测评队伍中,触发词识别F1值最高的为Mihaylov 和Frank[19]的模型,触发词分类F1值最高的为Lu和Ng[20]的模型;Yang[21]等将事件识别当作序列化标注任务,在KBP2016测试集结果表明,其方法达到了先进水平。因此,本文选择了两类基准平台。
基准1Mihaylov 和Frank把事件触发词识别当作序列化标注任务,使用词、词性与依存关系等构建词向量,作为双向LSTM模型的输入向量,通过softmax进行标签分类,在KBP2016语料上触发词的识别F1值为54.80%。 Lu和Ng的UTD1模型先对训练集合测试集进行词性还原,把测试集中词的词性还原和训练集中词的词性还原相同的词作为候选触发词;其次利用Stanford CoreNLP抽取候选触发词的语义依存关系,对于动词性候选触发词,提取该词的主客体头部信息;对于名词性候选触发词,提取该词的施事与受事头部信息;最后把提取的信息作为k近邻模型输入特征,对候选触发词进行识别与分类。在KBP2016语料上对触发词分类结果的F1值为46.99%。
基准2Yang等首先使用最大池化的卷积神经网络获得字表示,其次利用双向循环神经网络获得词表示,最后通过CRF进行推理获得最终的标注标签。他们的方法在KBP2016语料上进行事件识别评估,获得的触发词识别与分类的F1值分别为55.96%和50.63%。
3.2 数据集
本文使用的语料为官方提供的LDC2017E02语料集,包含TACKBP2014训练集与测试集,TACKBP2015训练集与测试集和TACKBP2016测试集。采用Mihaylov 和Frank[14]的训练集、验证集和测试集的划分方法,把2014英文训练集与测试集、2015英文训练集当作本文的训练集,2015英文测试集为验证集,2016英文测试集为测试集,实验具体的文档和事件分布情况如表2所示。
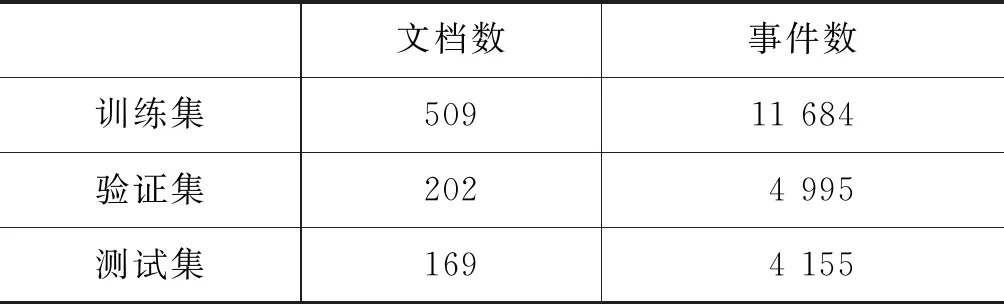
表2 训练集、验证集与测试集所包含的文档与18类事件
对于训练集中的事件句,我们采用BIO标签,B表示事件的开始,I表表示事件的内部,O表示非事件,可以把事件触发词识别和事件的识别联合抽取出来。比如输入句子为W={The,attack,by,insurgents,occurred,on,Saturday},对应的标签为Y={O,B-Conflict.Attack,O,O,O,O,O}
3.3 评价指标
对于触发词和事件类型,本文采用P(准确率)、R(召回率)和F1值的评价指标,并采用TAC-KBP2016组织者提供的官方评价脚本[注]http://cairo.lti.cs.cmu.edu/kbp/2016/event/Event-Mention-Detection-scoring-2016-v29 Official Event Nugget Detection and Coreference Scoring for TAC KBP 2016.进行测评。值得注意的是,事件类型评价得分是基于触发词识别的错误传播的,若触发词触发了两种事件类型,评价指标中应含有这两种事件类型。
例如,句子“the murder[Conflict.Attack,Life.Die]of John on Tuesday and Bill on Wednesday”,触发词“murder”触发了“Conflict.Attack”和“Life.Die”两种事件。因此,如果一个文档中含有100个触发词,其中6个触发词触发了两种事件,在评价指标中应有106个触发词和其触发的相应事件类型。
3.4 结果及分析
我们首先关注本文提出方法在事件抽取任务上的有效性。
表3给出了本文方法取得的事件识别的性能。从表3的结果可以看到:
(1) 在词向量的基础上依次加入词性向量、实体向量和文档向量,最终识别的F1值逐渐提高。
(2) 从C组实验和D组实验对比结果推理可知,实体向量与文档向量蕴含的信息相当,在触发词识别和事件类型确定两个子任务上得到的性能相当。
(3) E组实验结果表明,事件触发词识别的F1值为58.56%,事件类型的F1值为51.82%。对比C和D组实验与E组实验的结果可以看到,相比C和D组式样,E组实验在两个子任务上都获得了更好的准确率、召回率和F1值,说明实体向量和文档向量具有一定的互补性,实体向量包含事件局部的参与者信息,而文档向量包含事件之间的关系,将两者结合能更好地进行事件的识别与分类。
总体而言,本文提出的Seq2Seq模型在KBP2016语料上触发词识别和事件类型分类F1值分别为58.56%和51.82%,特别地,引入的实体向量和文档向量能有效提升系统性能。
表3 用KBP2016官方测评各组实验结果(%)
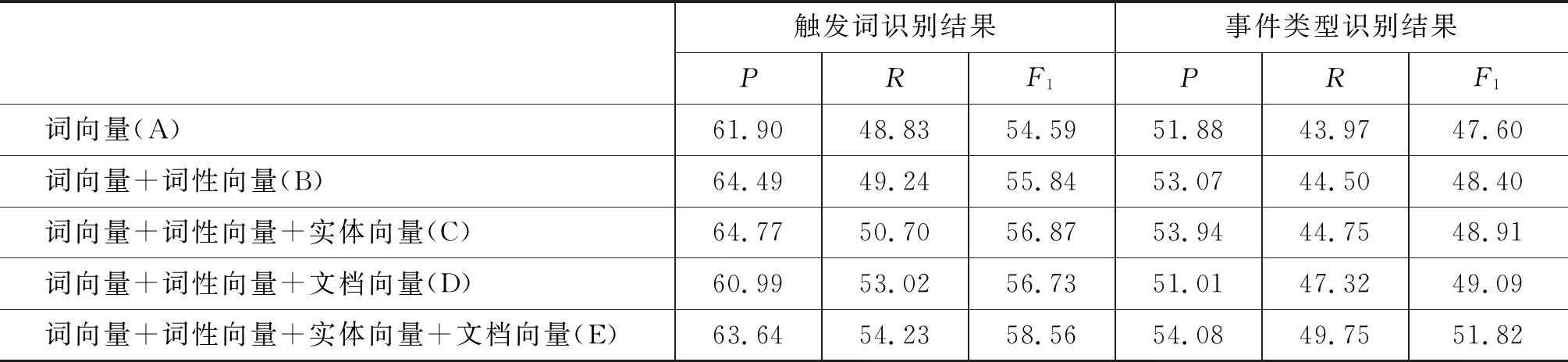
触发词识别结果事件类型识别结果PRF1PRF1词向量(A)61.9048.8354.5951.8843.9747.60词向量+词性向量(B)64.4949.2455.8453.0744.5048.40词向量+词性向量+实体向量(C)64.7750.7056.8753.9444.7548.91词向量+词性向量+文档向量(D)60.9953.0256.7351.0147.3249.09词向量+词性向量+实体向量+文档向量(E)63.6454.2358.5654.0849.7551.82
在本文提出的Seq2Seq模型中我们引入了注意力机制,接着我们关注各种注意力机制对事件识别任务性能的影响。
表4给出了不同注意力机制下本文方法在事件抽取上的性能。从表4可知:
(1) 对比加入了BahadanauAttention机制的Seq2Seq模型和没有注意力的模型,事件触发词识别的F1值提高了4.45%,事件类型识别的F1值提高了6.71%,说明注意力机制的引入能较大提升系统的F1值;
(2) 不同注意力的表现略有差别。使用BahadanauAttention机制与使用LuongAttention[22]机制,我们的Seq2Seq模型在触发词识别上的F1值性能提高了约0.64%,事件类型识别的F1值提高了约0.56%。
表4 各种attention实验对比结果(%)

触发词识别结果事件类型识别结果PRF1PRF1withoutattention52.4958.6254.1144.9445.2945.11BahadanauAttention63.6454.2358.5654.0849.7551.82LuongAttention64.0652.8657.9254.9148.0651.26
与基准系统相比,本文给出的方法不论在触发词识别还是事件类型的识别上都取得了最佳的F1值。
表5给出了E组实验结果与实验基准结果的详细对比。从表5可以看到,本文触发词识别最终的结果比实验基准1和基准2分别提高了3.765%和2.60%,在事件类型分类上分别比实验基准1和基准2提高了约4.8%和1.2%,证明了该方法的有效性。UID1的k近邻模型在提取候选触发词时,只提取了和训练集中触发词词性还原一致的词,这导致忽略了其他词性还原不一致的词;而本文的模型是利用Seq2Seq模型自动挖掘词之间的联系,能抽取和训练集中触发词词义相近的词,提高了触发词的识别F1值。Mihaylov和Frank模型只局限于句子信息,忽略了实体信息和文档信息;实体含有部分事件类型的信息,文档含有句子之外的其他信息,如相似类型的事件经常出现在同一个文档中,本文利用词性、词、实体和文档的信息进行事件识别,并且加入了注意力机制,从而提高了事件类型的识别F1值。句子中不同的成分对事件识别的重要性不同,Yang等的模型并没有对词的权重加以区分,而本文引入注意力机制,使得模型能区别不同词在事件识别中的作用,赋以不同权值,从而提高了事件识别的性能。
表5 E组实验与基准对比结果(%)

触发词识别结果事件类型识别结果PRF1PRF1基准1UTD155.3653.8554.5947.6646.3546.99Mihaylov和Frank58.4151.6054.8048.4542.8145.45基准2Yang等58.4353.6955.9652.3149.0650.63Seq2Seq(本文实验E)63.6454.2358.5654.0849.7551.82
最后我们进一步分析了事件类型识别在各个不同类型上的识别性能。表6给出了E组实验在18类不同事件上的识别性能,可以看到部分事件类型识别的F1值仍然偏低,主要原因为:
(1) 训练集规模不大,共有11 684个事件实例。
(2) 词组形式触发词的训练数据不足,训练集中,词组形式的触发词仅有251个,导致词组的触发词识别正确的仅有两个。
(3) 事件类型分布不平衡,有些事件类型实例比较少,比如Transaction_Transaction类型的训练实例仅有42个,所占比例为0.36%,从表6可知,Transaction_Transaction类型识别的F1值11%,远远低于事件类型识别的F1值51.82%。
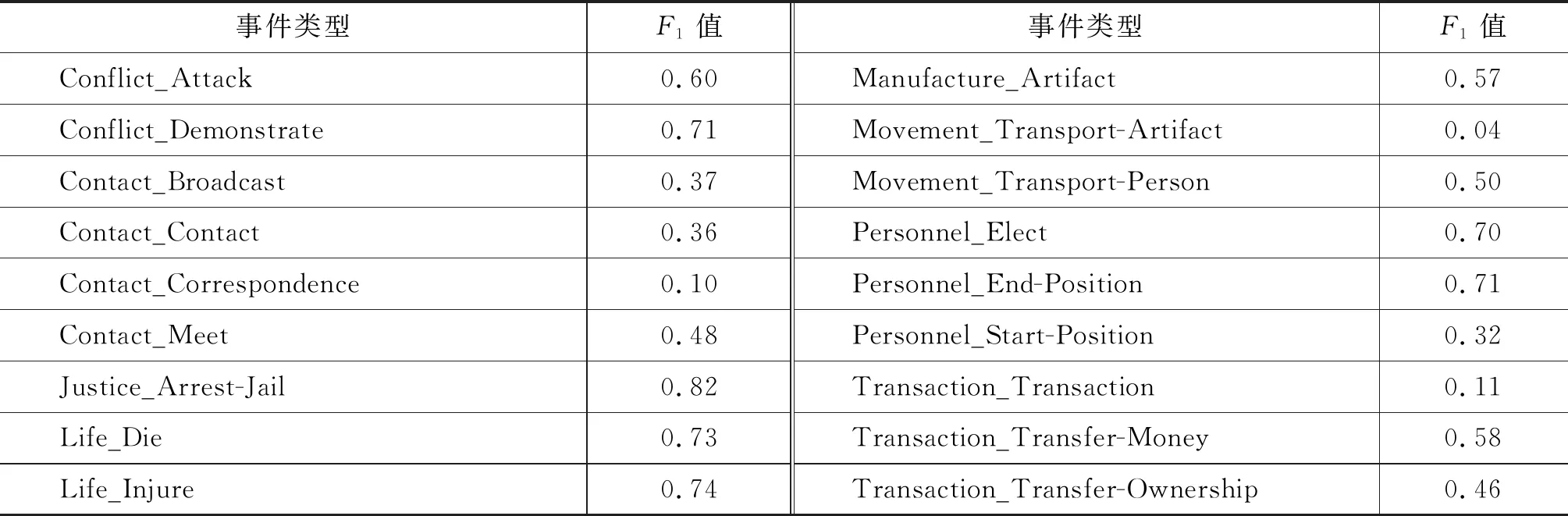
表6 E组实验18类事件识别结果的F1值
4 总结
为了提高事件识别的性能,本文给出了一种序列到序列的神经网络模型,并将词、词性、实体和文档信息以向量的形式进行表征,并通过注意力机制的引入更好地凸显各个成分的重要性。在TACKBP2016语料上的实验结果证明了方法的有效性。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中国新闻周刊(2021年26期)2021-07-27 04:02:12
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
信息安全研究(2016年4期)2016-12-01 06:06:54
公民与法治(2016年19期)2016-05-17 04:18:15
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
读者·校园版(2015年7期)2015-05-14 13:11:40
河南科技(2014年15期)2014-02-27 14:12:35
