
基于主题模型的微博评论方面观点褒贬态度挖掘
2019-08-05 07:41张士兵任福继张晓格
中文信息学报 2019年6期
张 茜, 张士兵, 任福继, 张晓格,2
(1. 南通大学 电子信息学院,江苏 南通226019;2. 南通先进通信技术研究院有限公司,江苏 南通 226019;3. 德岛大学 工程学院,日本 德岛 7700855)
0 引言
微博2.0是最受欢迎的应用之一,它给予用户更自由、更快捷的方式来沟通信息、表达观点、记录心情。这种140字左右的文字更新信息为公开可用的文本提供了丰富的资源。因此,很多对中文文本情感分析的研究都是基于微博平台展开的[1-3]。新浪微博中的原创微博下存在着用户评论,对这些评论进行褒贬态度的挖掘能帮助用户快速了解评论用户对原创微博内容的认可程度,对评论进行方面观点的提取可以为用户提供细粒度的信息。
微博情感分析的方法按照学习方法的不同可以分为监督学习方法、半监督学习方法与无监督学习方法。近年来,以LDA(Lateut Dirichlet Allocation)为基础的主题情感模型能有效地避免传统无监督学习方法依赖情感词典的缺点,达到较好的情感识别效果[4-7]。然而,直接对原创微博下的用户评论进行情感极性分析,并不能完全反映用户对原创微博的褒贬态度。因为有些评论针对原创微博,有些评论是用户阅读原创微博后有感而发表达的与原创无关的评论。现举例说明:
例1:原创微博内容有关全国政协委员白岩松,提案中呼吁要多关注“非名校”的学生。让他忧心的是,“这些非名校的学生绝对是中国未来建设的基石。但他们大学四年就在不自信、自卑、迷茫,甚至混日子中度过”。
用户1: 字字珠玑!醍醐灌顶[good]
用户2: 工人农民都是建设国家的基石!!
用户3: 本科还好啦,专科出去更不招人待见。[二哈][二哈][二哈]
用户1的评论内容很容易看出,该评论针对原创微博本身。而用户2与用户3的评论都属于与原创无关的评论,它们没有表明对提案的态度倾向。用户2感慨工人农民对于国家建设都很重要,用户3则叙述其认为的专科生求职现状。
由例1我们可以看出,只是分析情感极性而忽略评论对象,会影响评论集褒贬态度分类结果的准确率。其次,用户在发表评论时,会选择表情符号表达感情或是强调补充文字所表达的情感倾向,其中表情符号蕴含了大量的情感信息[8],若将其作为噪声去除,有可能会产生情感极性的误判。
针对上述问题,我们提出了微博评论方面观点褒贬态度挖掘方法。首先,提出通过三个相似度方法计算每条评论与原创微博的相关度,识别出与原创微博内容无关的评论;其次,提出用融入了表情符号情感层与文本情感层的主题模型,实现微博评论方面观点与褒贬态度的同步推导。实验表明,表情符号情感层的融入能提高模型的褒贬态度识别能力。
1 相关工作
随着互联网的快速发展,互联网评论信息的日益增长,观点挖掘技术逐渐成为数据挖掘技术中重要的一部分[9-10]。方面、持有者、观点内容及情感是组成观点的四个元素[11]。Hu等[12]提出了通过关联挖掘,提取高频名词及名词短语作为意见目标的方法。Zhou等[13]提出CMiner系统用于实现方面提取到观点总结,他们首次将CMiner系统用于微博话题评论数据。
近年来,以LDA主题模型[14]为基础的方面观点挖掘的方法逐渐受到关注。在这些方法中,方面和观点词被建模为主题。Titov等[15]通过拓展标准主题建模方法来归纳多粒度主题。他们表明当局部主题可以发现方面时,全局主题可以发现实体。李晨曦等[16]考虑到文本属于不同类别的隐含信息,基于LDA主题模型建立了“类别—文档—主题—单词”四层结构的新模型,用于提取多类型文档的观点信息。
微博的表情符号通常反映用户的心情,蕴含情感信息。谢丽星[17]指出表情符号在微博文本中以“[(.*?)]”的正则表达式出现。Zhang等[18]建立了一个加权网络分析微博的情感,该网络中表情符号为节点,互信息关联系度为边的权重值。黄发良等[8]提出了一个基于多特征融合的微博主题情感挖掘模型TSMF(Topic Sentiment Model Based on Multi-feature Fusion)。该模型将情感表情符号与微博用户性格情绪特征纳入到图模型LDA中,实现微博主题与情感的同步推导。
本文基于主题模型对原创微博下的评论进行细粒度信息分析。我们将原创微博内容与评论中的名词及名词短语作为每条评论的方面,其他词语作为观点词语,来研究微博评论方面观点提取的问题。如:“酸奶和养乐多是最好的选择”这句评论中“酸奶”、“养乐多”是这条评论语句的方面信息,“最好”“选择”是该条评论语句的观点信息。我们首先计算语句之间方面的相关度,识别出评论对象与原创无关的评论;其次,我们使用JAOES(Joint Aspect-Based Opinion and Emoticon-Sentiment)模型实现评论集方面观点和褒贬态度的同步推导。
2 方面观点褒贬态度挖掘方法
本节首先介绍与原创微博内容无关评论的判别方法,然后详细介绍我们提出的微博评论褒贬态度挖掘算法。
2.1 与原创无关的评论判别
新浪微博原创微博下存在着很多评论,有些评论内容是针对原创微博内容本身,带有褒贬态度倾向;有些评论则是用户阅读完原创微博内容后有感而发写下的,评论对象与原创微博内容无关。因此,我们提出与原创无关的评论判别方法,通过计算原创微博与评论之间的相关度,识别与其无关的评论。
字符串相似度考虑的是同时出现在两个方面当中的汉字的个数。例如,“白岩松委员”,“白老师”和“白岩松”都是同一个评论对象,它们都拥有汉字“白”。通常用杰卡德相似性系数去度量短语AO1与AO2之间的字符串相似度,如式(1)所示。
(1)
其中,A(·)表示一个方面包含的汉字集。
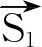
(2)
为了得到两个方面之间的语义相似度,我们使用Word2Vec训练词向量。基于训练好的词向量模型,计算两个方面之间相似度的值,从而判断它们之间的关联程度。如:“桃子”与“草莓”之间的相似度的值会远远大于“桃子”与“手机”之间相似度的值。
我们计算原创微博方面与每条评论语句方面之间的字符串相似度和语义相似度;计算每条评论观点词语与原创微博观点词语之间的情景相似度。将上述方法得到的三个相似度值进行累加并归一化,作为每条评论与原创微博的相关度。若相关度小于0.5,则认为该评论是与原创内容无关的评论。这个阈值是通过大量的实验而决定,可以使得与原创无关的评论的判别准确率达到最优。如果评论中不存在方面,则默认评论对象存在于原创微博中。
2.2 褒贬态度挖掘
LDA“文档—主题—单词”三层贝叶斯主题模型,是无监督学习算法,是典型的词袋模型。LDA模型在训练数据时不需要手工标注训练集,只需要文档集以及指定主题的数目。在文本主题识别、文本分类的研究中广为使用。
本文基于LDA主题模型,提出融入表情符号情感层与文本情感层的新模型JAOES (joint aspect-based opinion and emoticon-sentiment)(图1所示,符号说明见表1),JAOES模型可以实现方面观点和褒贬态度的同步推理。
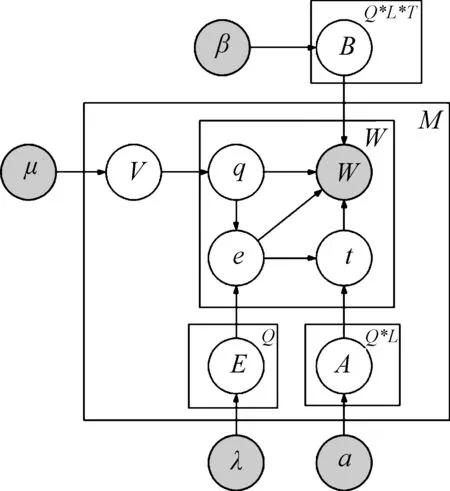
图1 JAOES图模型
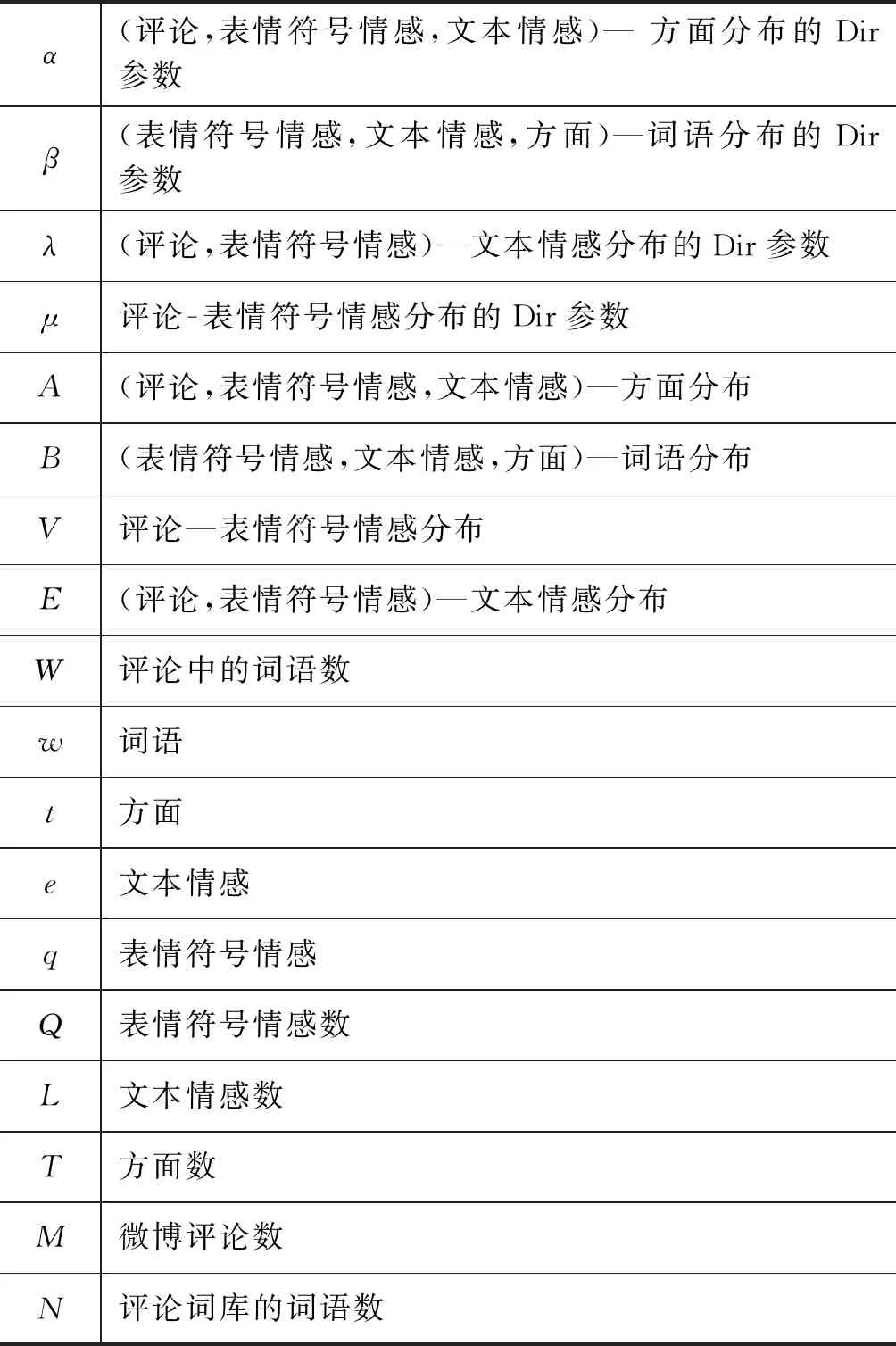
α(评论,表情符号情感,文本情感)—方面分布的Dir参数β(表情符号情感,文本情感,方面)—词语分布的Dir参数λ(评论,表情符号情感)—文本情感分布的Dir参数μ评论-表情符号情感分布的Dir参数A(评论,表情符号情感,文本情感)—方面分布B(表情符号情感,文本情感,方面)—词语分布V评论—表情符号情感分布E(评论,表情符号情感)—文本情感分布W评论中的词语数w词语t方面e文本情感q表情符号情感Q表情符号情感数L文本情感数T方面数M微博评论数N评论词库的词语数
过滤掉人工标注的与原创无关的评论得到的微博评论集D={s1,s2,…,sM}。其中,M为微博评论集D的总数,N为评论集D的词库的词语数,每一条评论sm的文本部分是由Wm个单词构成的。JAOES生成评论集D的过程大致如下:首先,某条评论以一定的概率从评论—表情符号情感分布中选择表情符号情感q,V服从参数为μ的Dirichlet分布;其次从(评论,表情符号情感)—文本情感分布中选择文本情感e,E服从参数为λ的Dirichlet分布;根据(评论,表情符号情感,文本情感)—方面分布选出方面t,A服从参数为α的Dirichlet分布;最后,从(表情符号情感,文本情感,方面)—词语分布选出词语w,B服从参数为β的Dirichlet分布。算法1为该过程的形式化描述。
算法1微博评论集D的生成过程
for eachq∈{1, 2, …,Q}
for eache∈{1, 2, …,L}
for eacht∈{1, 2, …,T}
for eachw∈{1, 2, …,N}
chooseBq,e,t,w~Dir(β)
for each microblogm∈{1, 2, …,M}
for eachq∈{1, 2, …,Q}
chooseVm, q~Dir(μ)
for eache∈{1, 2, …,L}
chooseEm, q,e~Dir(λ)
for eacht∈{1, 2, …,T}
chooseAm, q,e,t~Dir(α)
for each wordwin microblog commentsm:
chooseq~(Vm)
choosee~(Em,q)
chooset~(Am,q,e)
choosew~(Bq,e,t)
2.2.1 模型推理
JAOES模型的推导采用Gibbs 采样的方法,计算参数分布A,B,V与E。Gibbs 采样是统计学中用于马尔科夫蒙特卡洛(MCMC)的一种算法,它可以通过迭代采样的方式对复杂的概率分布进行推导[3]。词语w、表情符号情感q、文本情感e与方面t的联合分布P(w,t,e,q)如式(3)所示。
P(w,t,e,q)=P(w|t,e,q)P(t|e,q)P(e|q)P(q)
(3)
分别对分布B、A、E和V进行积分得到式(3)各因子的推导公式,如式(4)~式(7)所示。
(4)
其中,nq,e,t,w表示词语w同时属于表情符号情感q、文本情感e、方面t的频数,nq,e,t表示所有同时属于表情符号情感q、文本情感e、方面t的词语的总频数。Γ(*)为伽马函数。
(5)
其中,nm,q,e,t表示第m句微博评论中,方面为t的词语 同时属于表情符号情感q、文本情感e的频数,nm,q,e表示第m句微博评论中,属于表情符号情感q、文本情感e的词语的总频数。
(6)
其中,nm,q,e表示第m句微博评论中,文本情感为e的词语属于表情符号情感q的频数,nm,q表示第m句微博评论中,属于表情符号情感q的词语的总频数。
(7)
其中,nm,q表示第m句微博评论中属于表情符号情感q的词语的频数,nm表示第m句微博评论总词语数。
由上述联合概率可以进一步得到评论集方面观点褒贬态度的后验分布,如式(8)所示。
(8)
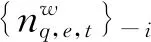
分布V,E,A,B可形式化为式(9)~式(12)。
(9)

(10)
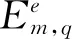
(11)
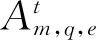
(12)
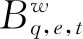
2.2.2 JAOES模型的先验
为了提升JAOES模型情感学习能力,在初始阶段赋予微博评论词库里的每一个词语情感极性。同时对每个词语的表情符号情感进行定义。
(1) 词语情感先验
本文结合HowNet的正面/负面情感词语、正面/负面评价词语与NTUSD的正面/负面情感词语,得到正面情感词语语料库与负面情感词语语料库。微博的论题开放的功能使得微博数据集的方面观点跨领域性极强,经常会出现一些新的情感词。文献[19]提出潜在情感词的自动挖掘并计算其极性权重的算法。该方法利用共现特性,基于朴素贝叶斯公式计算未知情感词语的情感权重值的大小并判断其极性。该算法与应用领域无关,拓展性良好。对于评论词库中的每一个词语,如果它存在于语料库中,则直接赋予相应的情感值。否则,采用上述方法对词语进行情感赋值。
(2) 表情符号先验
对于不带有表情符号的语句,它拥有特定的标签且迭代过程中不发生任何变化。基于之前表情符号情感标签的研究结果[20],我们将情感库里参与研究的68个表情符号的情感分为三类:绝对积极情感符号(用来增强语句积极情感的表情符号,例如,[开心])、绝对消极情感符号(用来增强语句消极情感的表情符号,例如,[怒])和语境情感符号(表情符号的情感极性随着语句的不同而改变,例如,[微笑])。对于每一条微博评论,若包含的表情符号属于绝对积极/绝对消极情感符号,则直接赋予相应的表情符号情感,且在迭代过程中不会发生改变。对于不存在于情感库的其他表情符号与语境情感符号,由模型进行随机赋值,迭代过程中会发生改变。
2.2.3 微博评论褒贬态度挖掘算法
通过2.2.1节推导出求解JAOES模型需要的公式后,利用模型判断用户评论文本情感与表情符号情感,从而挖掘出每条用户评论的褒贬态度倾向。为了方便叙述,构造变量集WC={nm,nm,q,nm,q,e,nm,q,e,t,nq,e,t,w,nq,e,t}。
在进行微博评论时,有些用户的文字表达很直接,有些很含蓄,有些则使用反语。若充分考虑表情符号提供的情感信息可以效提升微博情感分析的能力[21-22]。社会神经系统科学研究表明[23],人类将表情符号视为真实的物理行为进行响应,而不是简单的将其当作一个符号。因此,表情符号带有的情感极性,能在一定程度上提高我们对情感判别的准确性。针对上述现象,评论集褒贬态度挖掘算法包含以下四个部分。
(1) 数据预处理部分:该部分主要包括微博数据的去噪去停用词与语句的分词和词性标注,对词语的表情符号情感、文本情感以及方面进行初始赋值等。
(2) 对每条微博评论中的每个单词w,计算P(qi=q,ei=e,ti=t|q-i,e-i,t-i,w),并且更新变量集WC。重复上述过程直到达到最大迭代次数。
(4) 通过评论的表情符号情感与文本情感判别评论的褒贬态度。如果存在表情符号,则根据表情符号情感判别褒贬态度,表情符号情感为消极的评论为贬义态度评论,反之则为褒义态度评论;对于不存在表情符号的评论,则按照文本情感进行褒贬态度判别,文本情感为消极则该评论为贬义态度评论,反之则为褒义态度评论。
输入: 微博评论集D,α,β,μ,λ,Q,L,T;
输出: 评论集中每条评论的褒贬态度倾向。
1. 微博评论数据预处理,对评论里的每一个词语进行表情符号情感,文本情感与方面的初始化;
2. count=1
3. while count <= 1000:
4. for eachsm∈D:
5. for each wordwinsm:
6. 从WC中除去当前词语所属的表情符号情感,文本情感与方面;
7. 如果词语w所在语句不包含表情符号或是包含的表情符号情感均为绝对积极/绝对消极情感,则词语的表情符号情感的赋值不发生改变;否则,随即赋予词语w表情符号情感。通过公式(8)可以重新赋予词语w文本情感与方面;
8. 更新变量WC;
9. count=count+1
10. for eachsm∈D:
11. if 存在表情符号:
13.sm为贬义态度评论;
14. else:
15.sm为褒义态度评论;
16. else:
18.sm为贬义态度评论;
19. else:
20.sm为褒义态度评论。
3 实验与分析
3.1 实验数据
基于微博平台的研究大部分是围绕文本情感分类而展开的,现有的公开微博实验数据集缺少带有表情符号的评论用户的褒贬态度倾向数据,因此无法满足本文实验要求。因此,我们通过新浪微博API接口编写网络爬虫构造数据集。对于采集到的数据集,进行如下预处理:1)微博评论中存在“@回复”形式的评论?为评论用户之间的互动评论,此类评论不属于本文的研究对象,因此在预处理的过程中会过滤掉。同时,不包含汉字或表情符号的评论,汉字长度不超过5个字符的用户评论,都会进行删除;2)使用中科院的汉语分词系统对所有语句进行分词,去除停用词后保留语句的名词及名词短语、形容词及形容词短语和动词及动词短语部分。经过预处理后的实验数据包括10组原创微博及其评论,共有2721条语句。数据集包含三类标签:褒义态度标签、贬义态度标签和与原创无关的评论标签。
3.2 实验设置
实验由两个部分构成:第一部分使用准确率(Accuracy)评价2.2.3节提出的褒贬态度挖掘算法。设置JAOES的迭代次数为1000次,α设为0.1,β设为0.01,μ设为1/Q,λ设为1/L,方面数T的值为10。实验中,将我们提出的方法与baseline方法基于评论集D进行褒贬态度分类准确率的比较。baseline方法同样基于LDA模型实现,从JAOES中去除表情符号层进行训练。基线方法认为文本情感极性为消极的评论为贬义态度评论,反之则为褒义态度评论;第二部分通过具体实例从以下两个角度分析与原创无关的评论判别方法的必要性:1)与原创微博无关的评论判别方法对初始评论集褒贬态度分类准确率的影响; 2)初始评论集和经过与原创无关的评论判别方法过滤得到的评论集方面观点提取结果的分析。
3.3 结果与分析
我们按照实验设置的内容进行实验并对结果进行分析。
3.3.1 表情符号情感层对褒贬态度分类准确率的影响
图2展示了提出的方法与baseline方法褒贬态度分类的准确率。
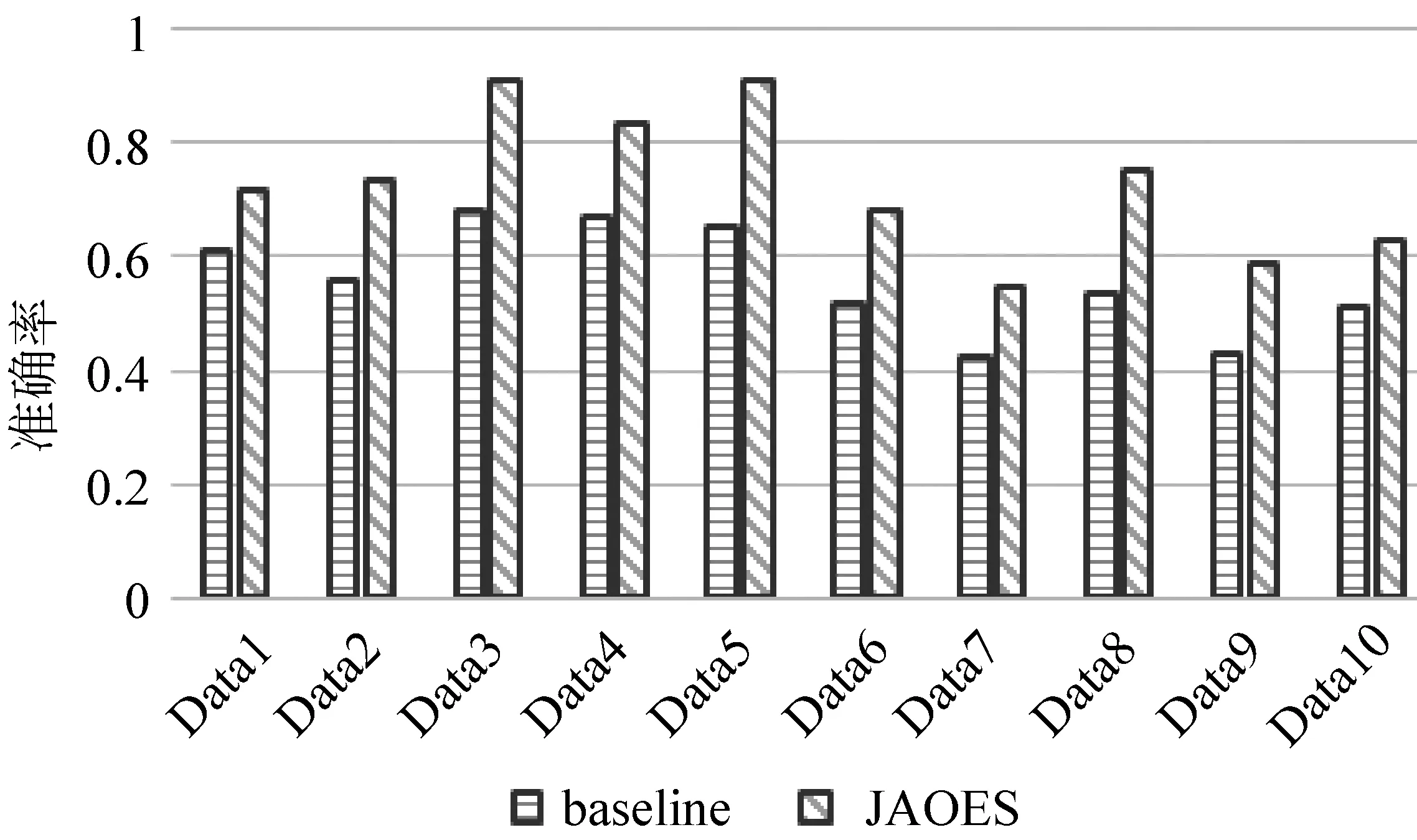
图2 褒贬态度分类的准确率
从图2中我们可以看出,融入了表情符号情感层的JAOES模型褒贬态度识别的准确率优于baseline方法。原因有以下几点:1)用户选择表情符号营造出语境氛围,同一个语句伴随不同的表情符号能表现出不同的情感。因此,表情符号提供的情感信息更有助于判别评论的情感极性;2)用户表达方式各有不同,当某些用户表达得委婉含蓄时,增加了情感分类的难度。表情符号提供的信息更能体现评论的情感倾向,从而提高了褒贬态度分类的准确率。
3.3.2 与原创无关的评论判别方法的影响
本节我们通过一个具体实例从两个角度分析与原创无关的评论判别方法的影响。
例2: 原创微博内容是“人大代表杨琴在2018两会上表示:临近除夕大家已无心工作,建议春节假期延长至十天。这个建议你支持吗?”该原创微博及其评论经过预处理后得到357条评论语句。经人工标注后对该建议表示支持的褒义态度评论有146句;不支持该建议的贬义态度评论有58句;与原创无关的评论有153句。也就是说,40.90%的评论用户是支持杨琴代表的建议的,16.25%的评论用户表示不支持,其他的用户则是发表了与原创无关的评论,并未表明是否支持该建议。
如果未剔除无与原创微博内容无关的评论,使用JAOES模型训练后得到的评论的褒贬态度倾向结果如下:265条评论为褒义态度倾向,92条评论为贬义态度倾向。即:74.23%的评论用户支持杨琴代表的建议,25.77%表示反对;通过本文的评论判定方法识别出评论对象并非原创微博的用户评论,再对其他用户评论进行褒贬态度挖掘得到的结果为:170条褒义态度倾向评论,70条贬义态度倾向评论。即:47.62%的评论用户支持杨琴代表的建议,19.61%的评论用户表示反对。
评论集中存在与原创无关的评论的这个事实,如果忽略它直接进行微博评论褒贬态度挖掘,会影响评论集的褒贬态度分类结果。在例2得到的实验结果认为,74.23%的评论用户是支持杨琴代表的建议的,与实际情况误差了30%多;而进行了与原创无关的评论判别后,再挖掘褒贬态度倾向的方法得到的结果认为47.62%的评论用户支持杨琴代表的建议,这个结果更接近于真实的支持率。
我们仍然使用例2分析初始评论集和经过与原创无关的评论判别方法过滤得到的评论集方面观点提取结果。表2展示了使用JAOES模型对初始评论集进行方面观点的提取得到的出现概率最高的词语。
从褒义态度部分的方面观点词中,我们可以看出用户对“临近除夕大家已无心工作,春节假期延长至十天”这条建议的支持,及希望在拥有假期的同时不存在调休情况;贬义态度部分的方面观点词中,大概可以看出用户觉得正常放假不调休就足够了,就算延长假期,放假前还是会无心工作。表2中的一些方面观点并不能让他人明白评论用户保持某态度的原因,尤其是“支持”一词以高概率出现在贬义态度部分,更加让人疑惑。

表2 初始评论集方面观点
表3展示了2.1节提出的与原创无关的评论的判定方法后,使用JAOES模型对评论集进行方面观点的提取所得到的出现概率最高的词语。

表3 评论集方面观点
与表2得到的初始评论集方面观点相比,表3的褒义态度部分“春运”“路程”,“关系民生”能看出一些用户支持建议的原因。表3的贬义态度部分的方面观点能看出用户不支持该建议的更多原因:除了上述分析的原因外,有些用户由于值班的原因,对假期的长短抱无所谓的态度; 有些用户觉得这个建议听听就行,不会真正被实施。
通过对例2的分析,我们可以看出:1)进行与原创无关的评论判别后的评论集褒贬态度分类结果更接近于真实情况;2)进行了与原创无关的评论判定后的评论集提取的方面观点更能看出评论用户保持某态度的原因;3)与原创微博相关度小的评论不参与方面观点的判定,因此没有出现表2中“支持”一词存在于贬义态度部分让人产生疑惑的现象。
对与原创无关的评论集进行方面观点的提取,可以让用户了解由原创微博内容衍生而出的新的方面观点,这个结果为话题的推送等研究提供了丰富的信息。
4 总结
新浪微博中,原创微博下存在着大量评论。这些评论反映原创微博的内容,用户对原创内容的态度以及与原创内容相关的一些话题,包含了丰富的信息。若忽略评论对象,会影响评论集褒贬态度分类结果的准确率。因此,我们首先提出与原创无关的评论判别方法识别对象并非原创微博的用户评论;其次,将融入了表情符号情感层与文本情感层的主题模型,用于实现微博评论方面观点与褒贬态度的同步推导。实验表明:表情符号情感层的融入能提高模型的褒贬态度识别能力。
猜你喜欢
消费电子(2022年6期)2022-08-25
初中生学习指导·中考版(2021年2期)2021-09-10
初中生学习指导·中考版(2021年1期)2021-09-10
疯狂英语·新阅版(2020年11期)2020-12-21
文苑(2018年20期)2018-11-09
文苑(2018年17期)2018-11-09
Coco薇(2017年8期)2017-08-03
试题与研究·高考英语(2016年3期)2016-12-23
新高考·英语进阶(高二高三)(2016年4期)2016-09-19
大作文(2016年7期)2016-05-14
