
基于跨语言词向量模型的蒙汉查询词扩展方法研究
2019-08-05 01:42马路佳赵小兵
中文信息学报 2019年6期
马路佳,赖 文,赵小兵
(中央民族大学 国家语言资源监测与研究少数民族语言中心,北京 100081)
0 引言
随着网络技术的发展,信息检索已经成为人们充分利用各种信息资源不可或缺的工具。从最初的基于关键字匹配到现在的基于语义分析、基于上下文分析,以及应用各种统计方法进行分析等,已经逐渐形成了一套比较完善的检索算法,并被学术界和工业界广泛应用。然而,随着网络的进一步发展及用户对查询的需求不断提高,单语言信息检索技术所表现出来的局限性越来越明显,人们已经不能满足于仅仅在同一种语言中进行检索,用户逐渐将需求转变为多语言的信息检索。
1973年,美国康奈尔大学G Salton教授提出的跨语言信息检索(Cross-Language Information Retrieval,CLIR)[1]技术是信息检索领域重要的研究方向之一,该技术主要研究根据源语言查询词检索到与源语言查询词上下文语境相关的目标语言文档[2]。该技术的主要思想为:在传统的单一语言信息检索技术基础上,通过跨语言相关技术实现源语言到目标语言的映射,根据映射选取与源语言查询词相匹配的目标语言描述信息。目前,主流的跨语言信息检索方法主要是基于机器翻译技术展开的一系列研究,主要包括:查询词翻译的方法、文档翻译的方法以及中间语言翻译方法[3]。利用非翻译方法进行跨语言信息检索的研究几乎空白。
查询词翻译方法[4]的主要思想为:在进行跨语言信息检索之前,将源语言查询词翻译为目标语言查询词,再根据翻译的目标语言查询词通过单一语言的信息检索技术实现跨语言信息检索。这种方法的优点是:在整个跨语言信息检索过程中仅对源语言查询词进行翻译,并没有涉及其他相关技术,工作量较小,可以与传统的单一语种的信息检索技术进行无缝对接。这种方法的缺点,一是查询词的翻译歧义问题无法解决,因而需要扩大目标语言的查询搜索空间,换言之,查询词的翻译错误对最终跨语言信息检索的结果将产生很大的影响;二是跨语言信息检索结果用目标语言返回,这对最终跨语言信息检索性能的主观评价造成很大的困挠。当前,查询词翻译方法主要包括以下三种:基于词典的方法、基于语料的方法、基于机器翻译模块的方法。
文档翻译方法的主要思想为:在进行跨语言信息检索之前,将所有源语言文档翻译为对应的目标语言文档,通过单一语言的信息检索技术将源语言查询词返回的检索结果映射到目标语言结果中。这种方法相比于查询词翻译方法的优点是:该方法生成的跨语言信息检索结果能够充分利用上下文信息,可以很好地解决翻译的歧义问题。这种方法的缺点是:由于当前基于文档的机器翻译的准确率还无法达到很好的效果,该方法的检索性能很大程度上取决于机器翻译的性能,故这种方法不管是在研究中还是在实用中都远不如基于查询词翻译方法。当前,文档翻译方法主要包括以下两种:基于字典进行文档索引词翻译的方法和基于文档的机器翻译系统方法。
中间语言翻译方法的主要思想为:在进行跨语言信息检索之前,将所有源语言和目标语言文档翻译为一种中间语言,并将源语言的查询词翻译为中间语言,最后通过单一语言的信息检索技术将中间语言查询词进行信息检索。这种方法的优点是:在源语言与目标语言之间不能很好地进行翻译时,采用一种中间语言作为枢轴语言进行翻译,可以很好地缓解由机器翻译困难带来的对信息检索性能的影响。这种方法的缺点是:当前基于枢轴语言的机器翻译技术并不成熟,特别是对于资源比较稀缺的语言,其性能远不能满足用户的需求。
非翻译方法的主要思想为:在进行跨语言信息检索时,完全摒弃基于翻译的方法。这种方法的主要思想是在Deerwester等[5]提出的浅层语义分析(LSI)的基础上实现的。这种方法的优点是:可以有效地避免机器翻译带来的翻译歧义问题。缺点是:跨语言信息检索性能很大程度取决于对两种语言之间的语义信息的提取准确率。当前,越来越多的学者也将目光转向非翻译方法的跨语言信息检索研究中,主要是基于浅层语义分析检索方法实现的跨语言信息检索方法。
Mikolov等[6]首次提出不同的语言之间的词向量空间具有一定的相似性,通过映射源语言词向量到目标语言词向量可以实现“词翻译”,例如,英文词向量空间模型中“movie”对应的词向量和汉文词向量空间中“电影”对应的词向量的余弦距离是最接近的。跨语言词向量训练方式一般分为有监督(在训练过程中使用双语词典等)方式和无监督(在训练过程中不需要双语词典等)方式。最近,Facebook提出的MUSE跨语言词向量训练方法[7]可以不依赖任何平行语料等先验知识,利用对抗学习(general adversarial networks,GANs)和跨领域相似度局部缩放(cross-domain similarity local scaling,CSLS)等方法来获得跨语言词向量模型,该方法在词翻译等任务上实验的效果对比其他方法要好,很多情况下甚至比有监督的方法效果还好。
由于现有的高质量蒙汉平行语料数量较少,训练出优良的蒙汉机器翻译模型尚存在一定的困难,并且利用机器翻译方法来实现跨语言信息检索时要考虑到存储空间和系统的可扩展性要求;同时,未登录词、消岐等方面的问题也会在很大程度上影响信息检索的效能。
本文采用非翻译的方法实现跨语言信息检索,即基于跨语言词向量模型实现语言统一和查询扩展目标。主要步骤为:首先,通过大规模的汉文、蒙古文单语数据及蒙汉双语词典进行跨语言词向量的训练;其次,通过训练得到的跨语言词向量,将汉文查询词映射为蒙文;最后,通过蒙文进行单一语言的信息检索。本文使用的方法与基于翻译的信息检索方法相比存在如下优点:一是本文提出的方法不需要平行句对进行机器翻译,直接利用大规模的单语数据进行跨语言词向量的训练,存储空间小,不依赖于具体的语言,适用性更强;二是本文提出的方法在一定的程度上减弱了未登录词的影响,提升了跨语言信息检索的召回率。
1 相关研究
跨语言词向量(Cross-Lingual Word Embeddings)是一种对单语言环境下的模型进行多语言扩展的有效手段。通过平行语料得到不同语种之间词向量的关联,使用这种关联关系实现了跨语言信息扩展的任务。近年来,越来越多的学者将目光转移到跨语言词向量的相关研究中,主要原因有两个:一是跨语言词向量可以在多语言环境中推断词语的语义;二是跨语言词向量可以实现不同语言之间的知识迁移,并计算多任务语言之间的相关性。
2012年,Klementiev等[8]首次提出跨语言词向量的概念,其主要思路为:首先,使用大规模的单语数据构建源语言和目标语言的初始词向量;然后,利用部分双语对齐语料中的词共现特征表征跨语言词向量。跨语言词向量概念的提出,为自然语言处理任务提供了研究基础,取得了很多突破性的进展。Faruqui等[9]基于词汇语义内容在语言之间的不变性特征,提出一种基于典型相关性分析的简单技术,并将多语言的特征并入单语言的生成向量中。该方法相比于单语言技术也表现出更好的语义表示性能,但由于采用串行级联形式表征词向量,故很难将单语言和跨语言的词向量表示同时学习到。Chandar等[10]使用基于自编码方法实现跨语言词向量表示,通过简单的学习在不同语言之间去重建句子级别的词袋表示,可以得到更高的性能,并且不需要词语对齐。这种方法构建的词向量表示对句子级别的信息表示具有很好的性能,但对词级别的信息表示缺乏语义层面的表达。此后,很多学者设计不同的目标函数来提升跨语言词向量的性能[11-13]。2015年后,越来越多的学者将跨语言词向量方法转化为单语言词向量的方法实现跨语言词表示[14-16],具体做法为:首先,采用不同的算法对训练语料中的单词进行随机混合;然后,将得到的混合语料作为训练数据,将跨语言词嵌入表示学习转化为单一语言词嵌入表示学习。
蒙古语信息检索相关研究起步较晚,巩文婧[17]提出采用词相关性扩展、加入距离模型的扩展以及关联词与词对共现距离相结合的扩展方法进行汉蒙信息检索的查询扩展。
2 本文提出的方法
本文提出的跨语言查询扩展模式在模型的可扩展性、数据冗余性以及存储空间的消耗方面相较于其他方法都有较为明显的优势,具体表现如下:
(1) 基于机器翻译方法进行跨语言探索,需要消耗大量的存储空间,并且在翻译的过程中会产生大量的冗余数据。跨语言词向量方式只需经过一次词向量训练,后续的跨语言信息检索只需要对已训练的词向量进行查询词的扩展和映射,占用的资源较少。
(2) 基于跨语言词向量查询扩展方式,存储空间消耗小、依赖较少且易扩展。这使得它很容易移植到其他语言的跨语言信息检索任务中,是一种语言无关的跨语言信息检索查询扩展方法。
基于以上两点,本文提出使用三种策略进行蒙汉跨语言词向量的查询扩展,分别为:串联式查询扩展、串联式查询扩展过滤、交叉验证筛选扩展。
2.1 串联式查询扩展
该方法的主要步骤为:首先,根据大规模的单语训练数据及蒙汉双语词典训练源语言(汉文)和目标语言(蒙古文)的跨语言词向量;其次,根据跨语言词向量将汉文查询式中的所有词进行扩展并得到其蒙古文查询词;最后,将扩展的蒙古文查询词根据汉文查询式中的查询词先后关系串联拼接,得到最后的蒙古文查询式。本文使用的跨语言词向量映射方式如图1所示。

图1 跨语言词向量映射方式
图1中x表示一个汉文查询词,X表示汉文的词向量空间,Y表示蒙古文的词向量空间,Vx为汉文查询词x在汉文词向量空间X中的词向量表示,通过计算蒙古文词向量空间Y中与Vx余弦距离,并选择距离最近的k个蒙古文词作为其候选扩展词y1,y2…,yk。

2.2 串联式查询扩展过滤

2.3 交叉验证筛选过滤
对于串联式查询扩展和串联式查询扩展过滤两种方法,存在一个很大的问题:对于一个汉文查询词,经过跨语言词向量映射可以扩展出多个蒙古文查询词,因此,如何对扩展出的蒙古文查询词进行筛选和排序成为提高跨语言信息检索性能的重要途径。交叉验证筛选方法的主要思想为:利用跨语言词向量对查询词进行扩展时,同时考虑到汉文查询词与蒙古文候选扩展词之间的余弦相似度以及蒙古文候选扩展词与其他汉文查询词之间的余弦相似度,根据汉文查询词上下文语义,对蒙古文扩展词与其周围的词进行排序以达到蒙古文查询扩展式上下文语义的连贯。具体做法如下:
Step1计算蒙古文候选扩展词集合中的每一个词与汉文查询式中的其他查询词之间的余弦相似度,如式(1)所示。
(1)

Step2从候选蒙古文扩展词集合中选取n个最相似的扩展词。
该方法的跨语言词向量映射如图2所示。

图2 交叉验证筛选过滤映射方式
其中,x1,x2,x3,x4为汉文查询词,交叉验证筛选方法的目标就是从x2的蒙古文候选扩展词y21,y22,y23中选择一个使跨语言信息检索性能最优的扩展词。具体做法为:计算每个蒙古文候选扩展词和汉文查询式x1,x2,x3,x4之间的整体相似度(计算方法见公式(1))来对这些候选词进行排序。例如,对于扩展词y21,计算其与汉文查询式的整体相似度值cos(x1+x2+x3,y21),经计算,y21,y22,y23对应的结果分别为s1,s2,s3,最后选择最大相似度值对应的蒙古文候选扩展词作为x2最终的扩展词。
3 实验
3.1 实验数据与准备
本文所使用的语料为实验室收集的大量的蒙古文文档,共包括28 166篇文档。实验中使用的蒙古文查询词来源于训练词向量语料中的高频词,共收集21个蒙古文查询词,这些扩展词语并不包含在训练跨语言词向量时所使用的小规模蒙汉双语词典中,平均每个查询词语对应300个候选文档进行实验验证。
本文实验中使用的查询词语与巩文婧等[17]相同,如表1所示。
在训练跨语言词向量之前,需要利用蒙古文和汉文大规模的单语数据训练各自的词向量,本文使用FastText来训练蒙古文和汉文的单语言词向量,其中汉文单语数据来源于维基百科中文语料,共1.1GB,蒙古文单语数据来源于实验室从蒙古文网页中爬取的数据及CWMT全国机器翻译评测蒙汉任务数据集中的蒙古文数据,共329MB。相关训练词向量参数为:

表1 汉文查询词经跨语言查询扩展后的蒙古文查询式
—minn:最短子串长度,两种语言都指定为2;—maxn:最长子串长度,蒙古文指定为15,中文指定为4;—dim:词向量维度300维。
训练蒙汉跨语言词向量时训练集词典大小为3 224,测试集词典大小7 732,汉文词不唯一。
本文使用的跨语言词向量训练工具为Facebook开源的MUSE[7],最终生成跨语言词向量包括蒙古文167MB,汉文698MB。
3.2 实验结果与对比分析
本文使用平均精度均值(mean average precession,MAP)作为信息检索的评价指标。该评价指标的计算方法如式(2)所示。
(2)
其中,Pi为第i个查询式的平均计算精度。
3.2.1 串联式查询扩展
串联式查询扩展方法将每个汉文查询词扩展为两个蒙古文查询式,结果如表2所示。
从表2可以看出,串联式查询扩展方式扩展出来的蒙古文词语相当于词翻译的效果,出现了很多冗余的词,这些冗余扩展词的出现在很大程度上影响了信息检索性能。故过滤冗余扩展词成为了提升信息检索性能有效的解决办法。

表2 串联式查询扩展方法
经计算,使用串联式查询扩展方法实验结果如下:MAPseries=0.440 5,准确率:0.743 7,查全率:0.692 7。
3.2.2 串联式查询扩展过滤
对串联式查询扩展方法扩展出来的蒙古文查询式进行过滤,本方法采用余弦相似度进行扩展词的过滤,取得了很好的效果。在对蒙古文扩展词进行过滤时,设置一个阈值(本文选取0.51),根据阈值过滤掉相似度值低于阈值的词。该方法生成的蒙古文查询式如表3所示

表3 串联式查询扩展过滤方法

经计算,使用串联式查询扩展过滤方法实验结果如下:MAPseries_opt=0.626 2,准确率:0.809 7,查全率:0.781 9。
3.2.3 交叉验证筛选过滤
交叉验证筛选过滤方法是在串联式查询扩展过滤方法的基础上充分考虑上下文信息对检索结果的影响,对扩展式进行进一步的筛选,以及对候选扩展词重排序的一种方法,该方法生成的蒙古文查询扩展式如表4所示。

表4 交叉验证筛选过滤方法

经计算,使用交叉验证筛选过滤方法实验结果如下:MAPcross_valid=0.706 8,准确率:0.851 9,查全率:0.818 7。
3.2.4 三种查询扩展方式对比
本文以文档翻译方法为基线方法,分别对本文提出的三种跨语言查询扩展方式进行对比实验,结果如表5所示。
对于串联式查询扩展过滤方法,通过去除冗余的查询扩展词可以明显地提升系统的检索效果。对于交叉验证筛选过滤方法,充分利用查询词的上下文信息对候选扩展式进行筛选和重排序,取得了最佳性能,其MAP值超过了基准测试的MAP值0.601 2,说明了当前方法的有效性。
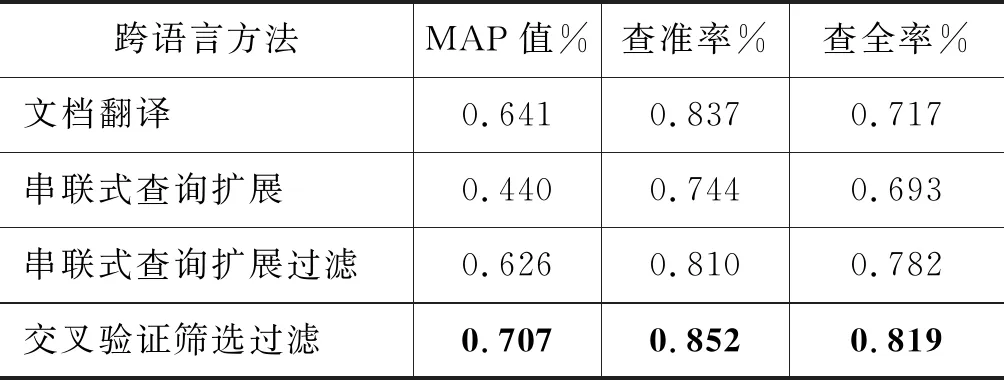
表5 跨语言方法性能对比
对于“十九大”、“一带一路”以及“四风”这样的词,词本身表示一个完整的含义,而经过分词处理后含义与分词前的含义完全无关(例如,“一带一路”分词后变为“一带”和“一路”)。在面对这些词时,文中的方法不再适用,结果不理想,查询结果如表6所示。

表6 非叠加词结果
对于上面3个查询式,结果为MAP:0.042,准确率:0.215,查全率:0.211。
4 结论
本文基于跨语言词向量模型,提出了串联式扩展、串联式查询扩展过滤以及交叉验证筛选过滤查询扩展3种查询扩展方法,实验表明,本文提出的方法,在进行信息检索时,可以根据汉文查询词本身的上下文信息生成符合蒙古文上下文语境的扩展词,大大提升了检索性能。
猜你喜欢
蒙古学问题与争论(2021年0期)2022-01-19
教育教学论坛(2019年18期)2019-06-17
河南教育·高教(2019年3期)2019-04-11
蒙古学问题与争论(2019年0期)2019-03-29
北方文学(2018年18期)2018-09-14
文理导航(2017年25期)2017-09-07
中国信息化周报(2017年30期)2017-08-31
考试周刊(2015年36期)2015-09-10
科学中国人(2014年22期)2014-07-23
疯狂英语·中学版(2013年7期)2013-08-01
