
基于改进词向量GRU神经网络模型的藏语实体关系抽取
2019-08-05 01:42王丽客郭莉莉
中文信息学报 2019年6期
孙 媛, 王丽客,郭莉莉
(1. 中央民族大学 信息工程学院,北京100081;2. 中央民族大学 国家语言资源监测与研究中心 少数民族语言分中心,北京100081)
0 引言
随着互联网的迅猛发展,大量的电子文本信息资源出现,越来越多的网上信息以多语言的形式发布,其增长速度远超过几年前的水平。我国是多民族国家,除了汉语,近年来多种民族语言资源也在互联网上快速增长。截至2014年3月7日,维基百科已有28 827 086词条,文章总量104 932 838篇,包含285种语言,其中英文条目4 466 451条,中文条目754 867条,藏语条目8 966条。如何利用这些庞大的数据为人类生活创造出有价值的东西,是当今计算机技术发展的重要方向,也是当今互联网领域的研究热点。自然语言处理技术正是在这样一个社会大背景中得到长足发展的一项计算机技术。不论是在信息处理领域还是在人工智能领域,如今自然语言处理技术己成为重要的研究方向之一,其研究成果也为人类社会带来了不可估量的巨大价值。因此,如何从大量的信息中快速准确地获取人们所需要的信息,成为了一个被关注的主要问题。
互联网数据的爆炸式增长,使得研究热点更多转向Web内容结构化分析[1]。在自然语言处理领域的研究中,知识图谱(Knowledge Graph)已经成为大数据时代的一个非常热门的关注点。在信息检索、问答系统以及知识库构建等研究中知识图谱提供了完善的资源与支撑[2],但少数民族语言知识图谱的构建才刚刚起步。目前,藏语信息以文本显示为主,缺少知识的结构化表示。如果将藏语知识以实体方式表示,并通过实体和实体之间的链接表征知识之间的关系,将会有利于藏语知识的结构化分析和深度挖掘。
藏语实体关系抽取是从藏语语料中抽取藏语实体关系的属性,如出生年月、性别、国籍、职业等,是将无结构文本转化为有结构文本来满足人们的需求。虽然藏语的显示输出技术、编码技术、输入技术、音节处理技术、网页制作技术等得到了很好的发展,但是与汉语、英语等信息处理研究相比仍差距较大,主要表现在词法、句法分析及其相关应用方面。因此,无法直接将英、汉实体关系抽取中相对成熟的方法应用到藏语中。在这种情况下,藏语实体知识的获取更多依靠人工的方式,无法实现大规模数据的处理及知识获取。因此,如何利用现有的语料资源,挖掘藏语实体知识是亟待解决的关键问题。藏语实体关系抽取的研究,为藏语知识问答、信息检索以及知识库构建等领域的研究提供了一定的支撑。
1 相关研究
实体关系抽取是信息抽取领域的一个重要部分。实体关系抽取是从无结构化或者半结构化的文本语料中抽取两个实体之间的关系,一般都只考虑一个句子中两个实体间的关系,即实体关系抽取问题的输入是一个句子和句子中已经标记出来的两个实体,输出则是这两个实体间的关系。本文中藏语实体关系抽取也是针对句子级别的。例如,句子“张继科的父亲是张传铭。”中包含一个实体对(张继科,张传铭),这两个实体对之间的关系为“父子”。
1.1 英汉实体关系抽取研究现状
英汉实体关系抽取的研究取得了很大进步,关注点也从语言学简单模型发展到复杂多样的机器学习模型。在实体关系抽取方法中,从研究初期采用基于特征的方法[3],随后逐渐发展到基于核函数的方法[4],到现代非常热门的基于深度学习[5]的方法。
基于深度学习的方法要求具有一定规模的训练语料。目前,英语实体关系抽取研究的语料通常使用ACL组织在2010语义评测会议中的评测任务8[6](SemEval-2010 Task 8:Multi-Way Classification of Semantic Relations Between Pairs of Nominals)和2007语义评测会议中的评测任务4(SemEval-2007 Task 4:Classification of Semantic Relations between Nominals[7])。这两个任务的要求是给定已经标注好两个实体e1和e2的关系实例,识别出该实例所包含的关系类别,并且该关系类别是数据集中预先定义好的。SemEval-2010 Task 8数据集有10种类别关系,共包含10 717个带有标注的数据实例;SemEval-2007 Task 4 数据集有7种类别关系,共包含1 529 个带有标注的数据实例。中文实体关系抽取研究的语料通常使用中文倾向性分析评测(COAE2016)中的任务3[8],基于句子级的实体关系分类抽取任务。其中,实体关系类别为10类,包含出生日期、出生地、毕业院校等关系类别,以及1 471个带有标注的数据实例。
基于特征的方法最主要的是构建分类特征与选择机器学习模型,一般特征包含词汇特征、句音节语法组合、实体特征以及语义特征等。在模式匹配的基础上,邓擘等[9]加入了词汇语义匹配来进一步研究汉语实体关系抽取。车万翔等[10]使用2004年ACE评测训练数据作为实验数据,利用Winnow与SVM两种方法进行了实验,实验证明质量好的特征对关系抽取的研究很重要。2005年,Guodong Z等[11]研究了语义特征、词汇特征和句法特征在实体语义关系抽取中的影响,并利用SVM作为分类器对研究内容进行了实验探讨。2007年董静等[12]构造了新的句法特征,在已拥有的句法特征的基础上利用条件随机场模型进行分类。
基于核函数的方法利用核函数在样本实例和相互依赖的基础上来计算特征向量的内积,得到关系样本间的相似性,研究实体关系抽取。Zelenko等[13]最早使用核函数的方法来研究实体关系抽取。Culotta等[14]使用SVM分类器来研究关系抽取,并且定义了依存树的核函数。Zhang等[15]提出了复合卷积树核函数来研究实体关系抽取。2008年,Huang等[16]使用作用在语法树上的卷积核实现了中文实体关系抽取的研究。2015年,陈鹏等[17]在研究中加入了领域知识短语树,从而实现在中文Web信息领域的实体关系抽取。与基于特征的方法不同的是,基于核函数的方法保存了实例的原状结构,而且可以经过选取特定的核函数对在高维度的特征中计算这两个实体关系的相似度。
基于深度学习的方法是经过把底层次的特征进一步重新组合来获得比较抽象的相对较高层次的表达形式,是在实体关系实例或者特征的基础上得到样本实例数据的分布式的表达,而且分布式的特征表达是经过深度学习的神经网络模型结构中许多隐含层结构一层一层来得到的。2006年,加拿大多伦多大学的Geoffrey Hinton教授与学生Ruslan Salakhutdinov在Science杂志上发表了相应的文章[18],此后开始了学术界与工业界对深度学习的研究热浪。2012年,陈宇等[19]把One-hot Representation方法表达的语言特征融入到DBN模型,从而实现了中文命名实体关系抽取。隐含层设计为三层时,F1值达到了73.28%。2014年同样在英文关系抽取的工作中,Zeng等[20]结合句法特征、词汇特征以及上下文语义特征等,用卷积深度神经网络模型进行了实验研究。F1值达到了82.7%。Cai等[21]结合CNN和RNN提出了双向循环卷积神经网络(BRCNN),可以从正反两个方向训练学习最短依存路径上的特征,对英语实体关系抽取研究F1值为86.3%。
1.2 藏语实体关系抽取研究现状
藏语实体关系抽取的研究仍然处于起步阶段,还有很多工作需要完成。用于藏语实体关系抽取的语料还没有像英语和汉语一样的公共语料。为了研究,我们构建了用于藏语实体关系抽取的语料,并且在不断地扩充。在藏语实体知识建设研究中,对藏语文本分类、文本的统计[22]、分词方法[23]、藏语自动分词[24]和藏语命名实体识别[25]等领域的研究都有一定程度的发展。加羊吉等[26]利用最大熵和随机场模型对藏语人名进行识别。在文献[27]中提出基于泛化模板和SVM相结合的方法抽取实体关系。 在文献[28]中提出基于支持向量机的方法进行藏语人名属性抽取研究,并且已经取得一定的成果。这对藏语信息处理以及本文藏语实体关系抽取的研究做了很好的铺垫和相关知识的积累。
2 本文提出的方法
基于改进词向量GRU神经网络的藏语实体关系抽取的整体架构,如图1所示。预处理之后的语料输入到神经网络结构中发现特征的多个层次,其中比较复杂的句子具有更高层次的特征。它主要包括以下三个部分:藏语词向量模型构建,藏语特征选取和深度学习模型构建。经过分词标注的藏语语料通过词向量将转化为向量以及对藏语特征抽取,选取藏语词汇特征和藏语句子特征,然后直接连接起来形成特征向量,经过线性变换得到最终的特征向量。最后,使用深度神经网络模型训练进行藏语实体关系分类抽取。

图1 整体框架图
2.1 藏语词向量模型
Hinton在1986年提出了一种词向量表征方法,该方法是将每个词训练映射成低维的实数向量a,然后通过计算相 似度以及欧式距离等来判断词和词之间的语义相似度。在2013年,Mikolov等[29]提出了Skip-gram和CBOW对数线性模型。在识别词语之间的语义关系方面,Skip-gram模型有着更好的效果,因此,本文在Skip-gram模型的基础上进行词向量优化,Skip-gram模型如图2所示。
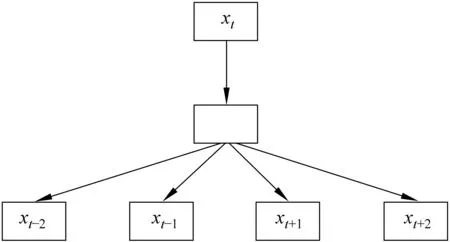
图2 Skip-gram模型
2.1.1 基于藏语音节、词的向量表示
通过训练神经语言模型,生成的词向量表相当于一个矩阵W∈d×|V|,矩阵中的每一行对应一个词的词向量。其中,|V|表示该词表的大小,即词表中词的个数,d为词向量的维度。
本文对传统的词向量做了进一步的改进。将藏语音节向量融入藏语词向量中,提高藏语词向量的效果,如图3所示。我们用C来表示藏语音节向量集,用W表示藏语词向量集。cj表示每个音节向量(cj∈C),Nj表示第j个词中字的个数,wj表示每个词向量(wj∈W)。我们要求音节嵌入和音节符嵌入的维数相等,然后把音节向量cj的平均值和词向量wj相加得到新的向量xj,如式(1)所示。
(1)

图3 音节词向量融合

(2)
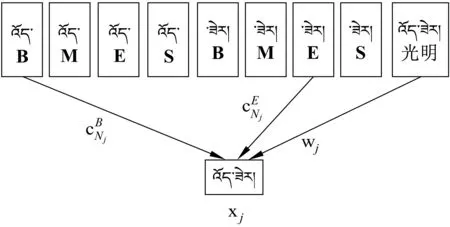
图4 音节位置和词向量结合
2.1.2 基于藏语词性词融合向量表示
和汉语、英语不同的是,藏语句型是谓语后置,动词是句子的关键。而且藏语有丰富的格助词,藏语格助词在藏语句子中的使用频率很高。格标记往往在动词的周围,并含有丰富的语义信息,在一定程度上格标记体现了藏语句子中谓语和主语间的关系,在藏语实体关系抽取工作中,格标记同样有很大帮助作用。
我们用训练词向量的模型训练词向量和词性向量。在不同的句子中相同的词具有不一样的词性,表达的含义也是不一样的。例如,“扮演”既可以作为名词,也可以作为动词。本文将词性向量延展融入词向量,那么同一个词不同的词性就可以得到不同的向量。本文首先将词和词性作为一个整体元组[word-pog]来进行词向量训练,得到词向量w1,然后将词性向量和词向量进行结合,最终得到词性向量W,如式(3)所示。第i个词的词向量Wi为词性向量W1i和词向量W2i经过权重计算得到,其中a,b为常数,通过设置参数,试验证明a=0.8,b=0.2时所得向量效果最好。
Wi=a·W1i+b·W2i
(3)

图5 词性向量和词向量结合
2.2 藏语特征选取
词汇特征是判断实体的一个重要线索。传统的词汇特征主要包括名词本身,实体之间的名词对和词序列的类型。在实体关系抽取任务中,对于某些实体周围存在的固定词语组合,利用这些组合可以有效地促进不同实体的区分。词向量模型受到严格限制,因为它们不能得到长距离特征和语义组合特征。在句子特征中,我们融入了词汇特征(Word Feature)和位置特征(Position Feature)。
2.2.1 藏语词汇特征

词向量模型受到严格限制,因为它们不能得到长距离特征和语义组合特征。在句子特征中,我们又融入了词汇特征(WF)和位置特征(PF)。WF是组合了词向量及其上下文中的词的向量。例如,所有词标记为向量(x0,x1,…,xi),其中,xi对应于句子中第i个词的词向量。为丰富词特征,使用W窗口的上下文大小。例如,当我们取w=3时,考虑整个句子,WF可以表示为式(4)。
WF={[xs,x0,x1],[x0,x1,x2],…,[x4,x5,xe]}4
(4)
PF是当前词与实体1和实体2的相对距离的组合。我们获得当前词与实体1和实体2的相对距离d1和d2,位置特征的表示如式(5)所示。
PF=[d1,d2]
(5)
2.2.2 藏语句子特征
词汇特征和位置特征结合为X=[WF,PF]T,经过线性变换处理得到Z=W1X(W1∈n1×n0,X∈n0×t,其中,n0=w×n,n是特征向量的维数,t是输入句子的标记数,W1∈n1×n0是线性变换矩阵,n1是第一层隐含层的节点数。在应用线性变换之后,输出取决于t。为了确定特征向量每个维度中最有用的特征,我们在Z上随时间执行最大操作,mi=maxZ(i,·)(0≤i≤n1)。其中,Z(i,·)表示矩阵Z的第i行。最后,我们获得特征向量m={m1,m2,…,mn1},其维度不再与句子长度相关。为了学习更复杂的特征,我们设计了非线性层并选择双曲线tanh作为激活函数,具有容易计算反向传播训练梯度的优点。形式上,非线性变换为g=tanh(W2m),W2∈n2×n1是线性变换矩阵,其中,n2是第二层隐藏层的节点数。与m∈n1×1比较,g∈n2×1,可以考虑更高层次的功能(句子层面特征)。
上面提到的词汇特征和句子特征被连接到一个向量f=[l,g](l为词汇特征向量,g为句子特征向量)。为了计算每个实体的置信度,使用softmax激活函数对特征向量f∈n3×1(n3等于n2+词汇特征的维数)进行归一化处理。最后词向量的输出为o=W3f(W3=n3×n4是变换矩阵),其中,n4是实体关系分类的数量。
3 实验
3.1 语料预处理
本文的藏语语料是通过配置的爬虫系统从多个藏文网站获取的,如维基百科(藏语版)、康巴传媒网、中国藏族中学网等。然后再从中筛选出关于藏族人物介绍的文章,并对这些句子做一些预处理。例如,人工分词、词性标注等。最后得到用于藏语实体关系抽取的语料形式,如图6所示。

图6 分词词性标注语料
语料集中包含9种实体关系,分别为出生时间、出生地、逝世时间、父亲、母亲、职业、国籍、性别及著作。本文藏语语料包含了4 126句带有标注的数据实例,其中75%用来做训练数据实例,25%用来做测试数据实例。
3.2 评价指标
实体关系抽取的性能评价使用了信息检索中的评价方法,召回率(R)用来测量被正确抽取的信息的比例,而准确率(P)用来测量抽出的信息中有多少是正确的。一般召回率和准确率存在反比的关系,即准确率增大会导致召回率减小,反之亦然。本文采用了F1值对最终系统的性能进行评价,如式(6)所示。F1值越接近1表示结果越好。
(6)
3.3 实验结果及分析
本文基于音节向量、音节位置向量、词性向量对传统词向量进行改进,训练出不同的词向量加入到GRU神经网络模型中进行实验。词向量的维度分别设置为50、100进行实验,实验结果如表1和表2所示。

表1 词向量维度为50

表2 词向量维度为100
通过实验对比发现,词向量维度设置为50时比设置为100时效果要好,使用改进的词向量文本特征在实体关系抽取的效果上优于使用传统词向量模型,同时也表明了音节向量特征、音节位置向量特征以及词性特征确实增强了文本特征向量的表达效果,如图7所示。当词向量的维度设置成50时,基于音节位置和词性改进的词向量在GRU神经网络模型中对藏语实体关系抽取的效果最好,F1值达到78.43%。

图7 不同维度不同词向量F1值
我们与文献[27]中提出基于SVM和泛化模板协作的方法以及BP神经网络模型的实验结果进行了比较,如表3所示。实验结果表明,本文方法在藏语实体关系抽取中效果有所提高。

表3 实验比较
4 结论
本文提出了一种基于改进词向量GRU神经网络模型的藏语实体关系抽取的方法。考虑到藏语的音节特征、音节位置的特征以及词性特征都含有文本信息,所以我们在传统词向量基础上增加了相应的特征表示,实验证明了这些方法的有效性。目前,藏语语料还不够丰富,和汉语的数据相比,实验中的藏语数据比较单一,而且标注的数量有限,语料的丰富和检验工作还需进一步完善,在藏语实体关系抽取研究上仍有很大空间可以提升和改进。
猜你喜欢
客联(2022年2期)2022-04-29
通信技术(2021年12期)2022-01-25
西藏研究(2021年1期)2021-06-09
西藏艺术研究(2020年3期)2021-01-18
考试与评价·七年级版(2020年6期)2020-11-02
西藏艺术研究(2020年2期)2020-09-04
快乐作文(1.2年级)(2019年9期)2019-09-10
计算机应用与软件(2018年9期)2018-09-26
作文周刊·小学一年级版(2018年32期)2018-01-15
外语教学理论与实践(2014年2期)2014-06-21
