
基于融合图像的无参考立体图像质量评价
2019-08-02 02:41:20李素梅薛建伟秦龙斌
天津大学学报(自然科学与工程技术版) 2019年10期
李素梅,薛建伟,秦龙斌,
(1. 天津大学电气自动化与信息工程学院,天津 300072;2. 昌都市公安局,昌都854000)
近年来,随着多媒体技术的发展,立体图像受到越来越多的关注,而立体图像在采集、压缩、传输、显示等过程中均会产生降质问题,立体图像的质量会直接影响人们的视觉感受,因此,如何有效地评估立体图像的质量成为立体图像处理和计算机视觉领域的关键问题之一.由于立体图像主观质量评价要求测试者在特定的情况下对立体图像进行打分,费时费力,成本较高,且极易受测试者主观情绪的影响,不适于实际应用;而立体图像客观质量评价方法是通过客观模型给出立体图像的质量分数,能够有效弥补主观评价方法带来的不足.因此,本文提出一种客观评价模型对立体图像的质量进行评价.
根据对参考图像的依赖程度,立体图像质量客观质量评价可以分为全参考图像质量评价、半参考图像质量评价和无参考图像质量评价.全参考图像质量评价需要测试图像和参考图像的全部信息,半参考图像质量评价需要获得参考图像的部分信息.但在实际环境中,参考图像可能没有或者很难获得,因此,这 2类方法的应用范围有限.相比而言,无参考图像质量评价方法仅利用失真图像来进行评价,更符合实际应用的需要.
立体图像质量评价的研究之初,人们将平面图像质量评价方法[1-3]应用于立体图像的质量评价中,如峰值信噪比、均方误差、结构相似度等[4].由于该类方法未考虑立体图像的深度信息和人类视觉特性,因此不适合直接用于立体图像的质量评价.随后,一些文献提出基于双目视觉特性的立体图像质量评价方法.文献[5]提出了一种融合人类双目特性的立体图像评价方法,使之更符合双目特性.但是,目前对人类视觉系统的认知还很有限,传统的方法难以全面反映人类对于立体图像的视觉感受,因而研究人员采用能模拟人类大脑的神经网络方式进行立体图像质量评价[6].但是传统的机器学习方法需要人工选取立体图像特征,选取的特征不一定能够完全反映立体图像的质量情况,限制了立体图像质量技术的发展.2011年后,深度学习网络,特别是卷积神经网络(convolution neural network,CNN)快速发展[7].卷积神经网络能够从图像中自动选取特征,在图像分类、语音识别等方面能得到更高的正确率,比如 2012年Hiton等在 Imagenet挑战赛上使用 Alexnet[8]图像分类模型中夺得第 1名,性能远超其他机器学习方法.基于 CNN在图像识别,对象检测和语义理解等领域的巨大成功,文献[9]提出了一种 3通道 5层卷积神经网络,网络初始化参数通过迁移学习训练二维图像得到,将立体图像的左视图、右视图和差值图分块分别作为网络输入,通过卷积提取立体图像特征,最终全连接加权得出最终的质量分数.文献[10]首先通过主成分分析法将左右视图融合,然后对融合图像进行减均值和对比度归一化操作,最后采用非重叠切块的方法将图像切成小块送入网络进行训练,通过CNN建立图像特征与主观评分差值之间的关系模型.但文献[9]和文献[10] 2种方法都没有考虑到人眼的视觉显著特性,并且在对图像进行分块时采用的均是不重叠切块方法,这种方法可能会造成图像结构信息丢失.而且以上文献的视点间处理方式并不完全符合大脑立体视觉先融合后处理的视觉处理机制[11].另外,在机器学习和数据挖掘算法中,迁移学习可以避免重新搭建一个网络进行调参的繁琐性,并且使带有标签的数据得到充分利用.基于以上问题,本文模拟人脑的处理机制,将左右视图进行融合,使用重叠切块的方法送给 Alexnet网络进行迁移学习训练,预测得到立体图像的质量,最后再利用人眼的视觉显著特性对图像小块的输出进行加权.
本文内容主要包括以下 3个方面:①图像融合,分别对左右视图提取图像特征,然后融合来模拟人脑处理立体图像的过程;②迁移学习,将 Alexnet网络用于迁移学习,通过使用改进后的 Alexnet网络对数据库进行训练,能得到更为准确的分类模型;③视觉显著性,权重系数通过中央偏移因子进行确定,进一步模拟人眼视觉系统的显著性特征.
1 方法概述
算法结构如图 1所示.首先对左右视图进行图像融合,用来模拟人脑处理立体图像的过程;然后对融合图像进行重叠切块得到卷积神经网络的输入;最后对网络输出的各个小块的输出进行视觉显著性加权得出立体图像的质量分数.
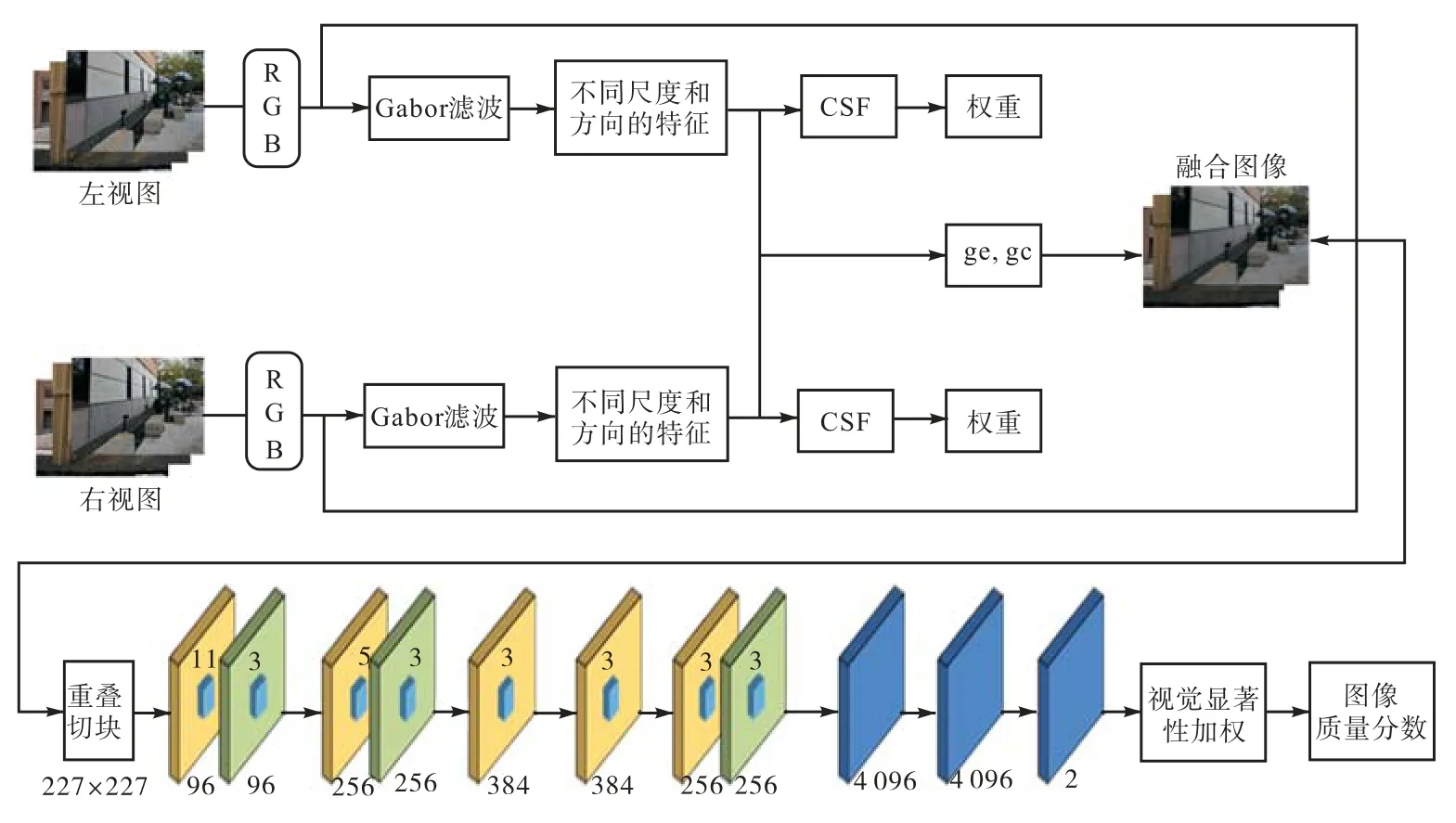
图1 算法结构Fig.1 Algorithm structure
1.1 图像融合
与平面图像相比,立体图像包含更多的视觉信息,能给观看者带来沉浸式的视觉体验.立体图像左、右视图有所不同,通过视网膜传入人脑后,存在视觉多通道现象,同时也会产生双目融合和双目竞争[12],为了更好地模拟人眼视觉特性,本文提出了一种立体图像的融合方法.
首先,左、右视图分别在 RGB 3个通道上进行Gabor滤波以模拟人眼的视觉多通道特性,获取其不同尺度和方向的结构特征,随后通过对比敏感度函数(contrast sensitivity function,CSF)滤除图像的不重要频率信息,最后通过式(1)获得融合图像.在每个通道中,2只眼睛会互相施加增益控制,其施加的增益控制与其能量成正比,并且每只眼睛会对另一只眼睛产生的增益控制进行控制,即增益增强.

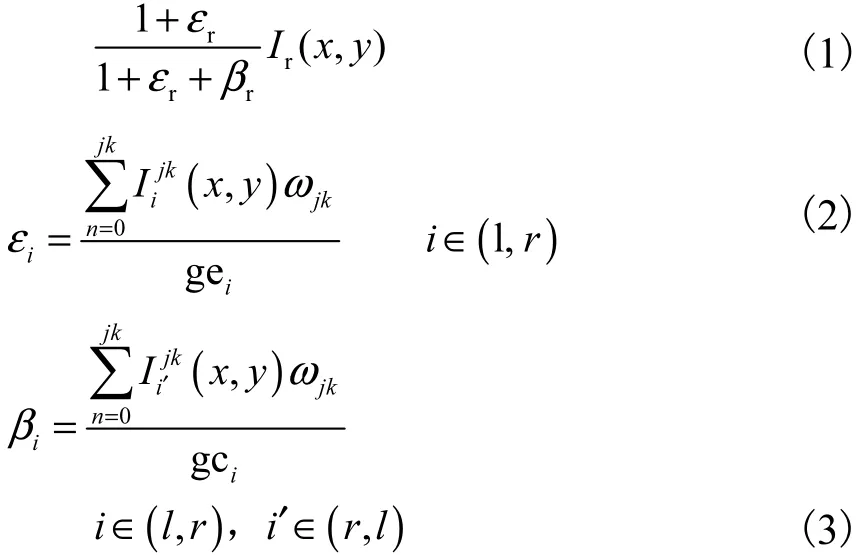
式中:C(x,y)是融合后的图像;Il( x, y)、Ir( x, y)分别是左视图和右视图;j和k分别是6和8,表示使用6个尺度(fs ∈ {1.5,2.5,3.5,5,7,10}(cycles/degree))和 8 个方向(θ∈{k π /8|k = 0 ,1,···,7})的 Gabor滤波器提取图像特征;εl、εr是输入的左视图和右视图用于增益增强的视觉权重对比能量;βl、βr是左视图对右视图的增益控制和右视图对左视图的增益控制;gei、gci分别表示左视图对右视图的增益控制门限和右视图对左视图的增益控制门限.

本文提出的融合图像方法具有自适应性.当左右视图的对比刺激低于某一确定阈值时,εl和εr接近于 0或者远小于 1,融合图像是左右视图的线性叠加[11],可用式(4)来表示;反之,当左右视图的对比刺激高于这个阈值时,融合图像是左右视图非线性叠加形成的,如式(1),不过,自然场景下的所有图像都高于该阈值.无论左视图和右视图的对比度刺激如何,总能找到合适的gei和gci,使其具有显著的增益控制和增益增强,所以本文所提出的方法既适合对称失真也适合非对称失真.
1.2 Alexnet网络用于迁移学习
机器学习技术在分类、回归和聚类上取得了巨大的成功,但使用此类方法有一个重要的前提是:训练和测试数据必须从相同的特征空间去取得,且必须具有相同的分布.当分布改变时,就需要重新构造训练数据模型.在现实生活中,重新收集训练数据或重新构造一个数据模型的成本很高甚至是不可能的,而迁移学习可以充分利用带有标签的数据[13],将已经学习到的模型参数通过某种方式来分享给新模型,从而加快并优化模型的学习效率.
基于卷积神经网络的立体图像质量评价方法能够建立输入图像和输出质量值之间“端到端”的映射.本文利用Alexnet网络,修改其最后1层,改为二分类.该网络结构一共有10层,第1层为输入层,输入图像块;第 2~6层为卷积层,输入图像经过卷积层提取一系列特征;第 7~9层为全连接层,全连接层将学到的特征通过权值的方法映射到样本的标记空间;第10层为网络的输出,即小块的质量分数.该网络输入图像大小227×227,各层参数如表1所示.
其中第 1列为每层的名字,包括卷积层(Conv-1、Conv-2、Conv-3、Conv-4、Conv-5)、池化层(Pooling)、全连接层(Full-Connected-1、Full-Connected-2、Full-Connected-3);第 2列为每层的参数配置,Fm为特征图的数量,kernel为用于运算的核的大小,stride为运算的步长的大小,pad为对特征图尺寸扩展的大小,group-2为采用 GPU并行加速,Max为池化层池化方法,FC为每个全连接层神经元的个数.
该网络使用ReLU非线性激活函数,加快网络的收敛速度,防止了梯度消失的问题.在卷积层和池化层后经过局部响应归一化层,实现局部抑制,加快网络收敛速度,提高网络的泛化能力.全连接层使用Dropout层,随机让网络某些隐含层节点的权重不工作,有效地防止过拟合,采用 3层全连接层实现更好的拟合效果.
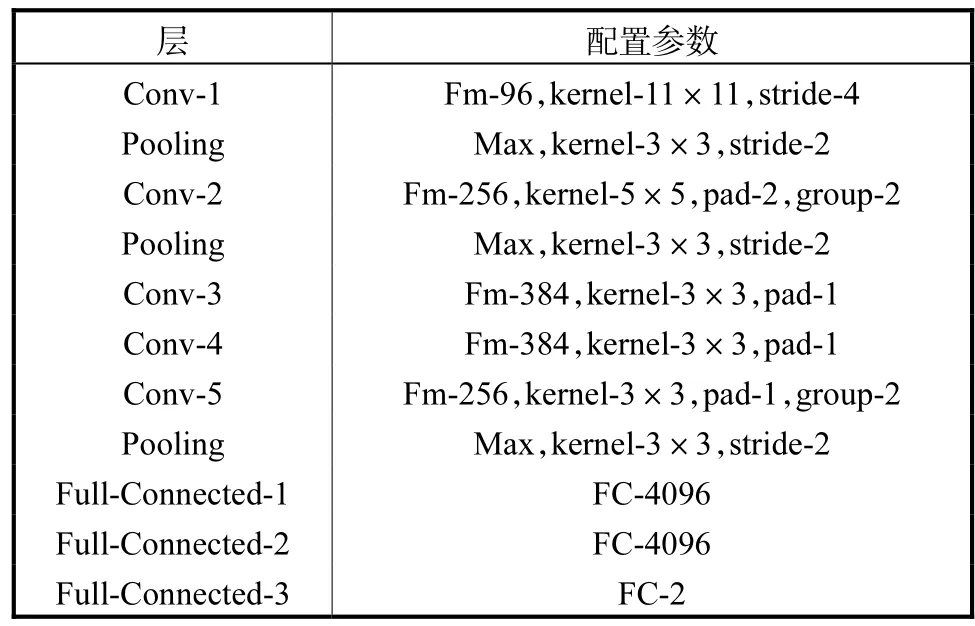
表1 网络参数Tab.1 Network parameters
1.3 视觉显著性
视觉心理物理学研究发现,在观看图像时人眼会不自觉地关注某些区域,并优先处理该区域的信息[14],这些区域就是显著性区域,这种特性称为视觉显著性.人眼在观看图像时总是倾向于从图像的中心开始寻找视觉注视点,然后其注意力由中央向四周递减[15],即中央偏移(center bias,CB)特性.

图2 基于视觉显著性的光亮度Fig.2 Luminance graph based on visual saliency
如图2所示的光亮度图,像素的坐标位置越处于图像的中间位置,该像素越容易受到关注;中间区域亮度最亮,表示人们对此区域最敏感,所分配的权重最高,亮度向四周逐渐变暗,权重也依次递减.视觉中央偏移特性可采用具有各向异性的高斯核函数[16]进行模拟,即
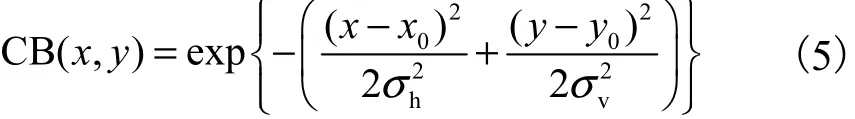
式中:CB(x,y)表示像素点(x, y)对中心点 ( x0,y0)的偏移信息;σh和σv分别表示图像水平和垂直方向的标准差.
归一化CB(x,y)得到图像对应的权值矩阵CBnormal(x, y)表示为

式中M和N为图像的长和宽.将归一化的权值矩阵按原始图像分块的方式进行分块处理并求和得到块归一权值 C Bnormblock(i)所示为

将对应位置的权值矩阵与输入图像块质量相乘,得到图像块的质量值,再将1幅图像所有图像块的质量值相加,即得到基于人眼视觉显著特性图像质量值value,即

式中:T为图像分块的数量;v a lueblock(i)为图像块i的质量值.
2 实验结果与分析
2.1 实验环境、数据库及数据预处理
本文实验服务器 CPU为 3.5GHz的 Intel xeon E5-2637 v3,64G RAM,使用 GPU 并行加速,GPU为 Titan X,显存 12GB,Ubuntu 14.04 系统,采用Caffe深度学习框架对网络进行训练.
采用 LIVE实验库提供的 LIVE3D phase-Ⅰ、LIVE3D phase-Ⅱ图像测试库进行实验.LIVE3D phase-Ⅰ数据库对左、右视点图像进行相同的失真处理,共有 20种场景,包含 5种失真,共有 20对参考图像和 365对失真图像;LIVE3D phase-Ⅱ数据库是对 LIVE3D phase-Ⅰ数据库的完善,左、右视点图像的失真程度不一定相同,共有8种场景,包含5种失真,共有8对参考图像和360对失真图像.本文实验挑选了 80%的融合图像作为训练集,剩余的 20%作为测试集,所有的融合图像被切成 227×227大小的小块.
2.2 性能比较与分析
采用分类准确率(accuracy)、Pearson相关系数(PLCC)、Spearman相关系数(SROCC)和均方误差(RMSE)等指标对立体图像质量进行评价.SROCC和 PLCC越接近于 1,表示模型性能越好;RMSE越接近于0,表示性能越好.
为了验证所提方法方法的有效性,将本文方法与其他文献进行性能比较,如表2所示.其中,文献[17-19]为全参考立体图像质量评价方法;文献[10,20-23]为无参考立体图像质量评价方法.
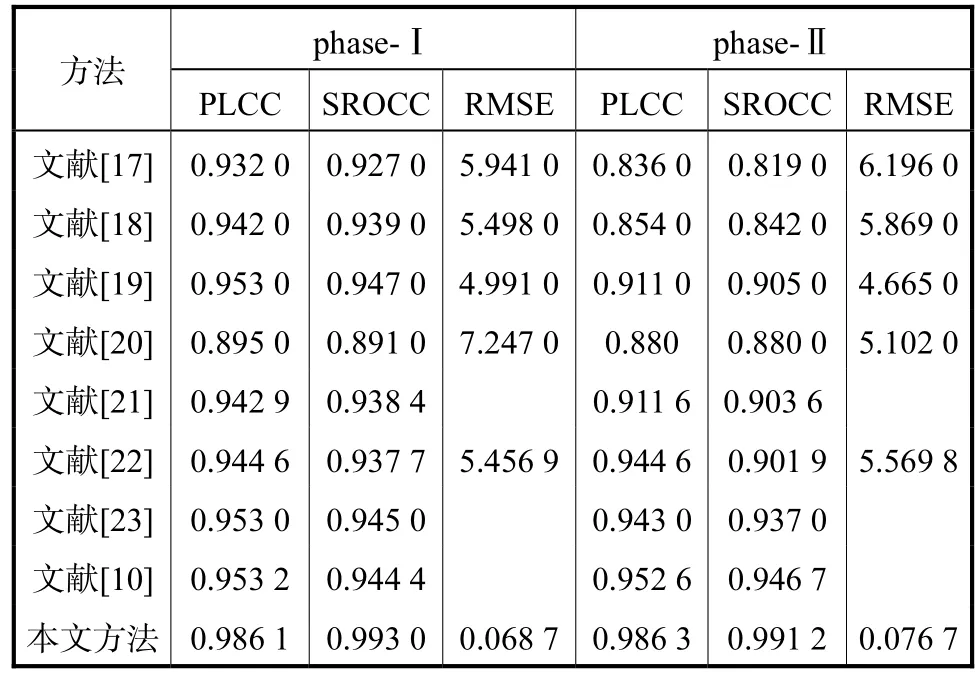
表2 各种评价方法的总体性能比较Tab.2 Comparison of the overall performance of various evaluation methods
从表2可以看,PLCC、SROCC、RMSE 3个指标均取得了较好的结果,其中,PLCC值超过 0.986,SROCC值超过 0.99.这与 Alexnet在分类任务上展现出卓越的泛化能力不无关系.因为 Alexnet网络在由数百万张图像组成的 Imagenet数据库上接受训练,提取了几乎完整的基向量,而构成图像的基向量是普适的,所以该网络也可作为迁移学习的网络用于立体图像质量评价.另外,无论是只有对称失真的LIVE3D phase-Ⅰ数据库还是既有对称失真也由非对称失真的 LIVE3D phase-Ⅱ数据库,所提方法均能取得较好的结果.最后,本文实验结果的RMSE值在同类所比文献中最为出众,这与图像的预处理过程有很大关系.文中将图像库按照质量好与质量差分为 2类,很大程度上降低了回归的复杂度,因此,本文的RMSE的值比其他文献实验结果更小.
为了探究本文方法在不同失真类型下的效果,分别在LIVE3D phase-Ⅰ和LIVE3D phase-Ⅱ上进行实验.如表 3所示,本文所提出的方法在不同失真类型上均展现出了非常好的效果,有些失真类型的 PLCC和 SROCC甚至达到了 1,RMSE达到了 0.但LIVE3D phase-Ⅰ上的 JPEG失真和 LIVE3D phase-Ⅱ上的 FF失真,没有达到像其他失真一样的效果,说明本文所提网络对于这 2种失真的学习能力还有待提升.
2.3 使用融合图像与否对结果的影响
为了说明本文融合图像算法的有效性,在LIVE3D phase-Ⅰ数据库上进行了对比实验,并得出了衡量算法性能指标的相应值,如表 4所示,其中,如果使用此立体图像融合算法,其分类准确率由0.9835提升至0.9953,另外,PLCC和SROCC分别提高了0.0339和0.0177,RMSE也由原来的0.1285降到了 0.0687.可以很明显地看出,论文所采用的立体图像融合方法可以很好地模拟人眼视觉特性,与主观评价相一致.
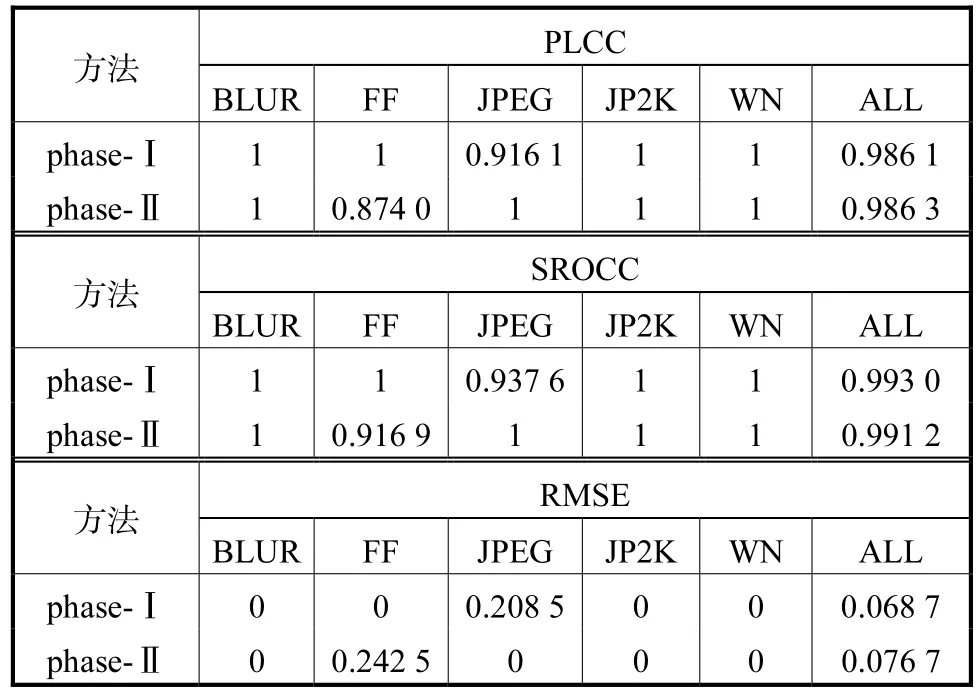
表3 不同失真类型的PLCC、SROCC以及RMSETab.3 PLCC,SROCC,and RMSE of different distortion types

图3 重叠切块步长与分类准确率的关系Fig.3 Relationship between overlapping step size and classification accuracy

表4 验证融合图像的作用Tab.4 Verify the function of the fused image
2.4 重叠切块步长对实验结果的影响
因为本文采用重叠切块的方式将所得的小块作为网络的输入,而进行重叠切块时,重叠切块的步长会影响 1个图片所分割出来的小块数目.本文因此探究了重叠切块步长的大小对实验结果的影响.如图 3所示为本文所做的重叠切块步长大小与分类准确率的关系,图3(a)为在LIVE3D phase-Ⅰ上进行实验,图3(b)为在LIVE3D phase-Ⅱ上进行实验.
文中实验的重叠切块步长最小为 20个像素,最大为50个像素,每间隔5个像素做1次实验,一共7组实验.从图 3(a)的折线图中,可以看到,当步长step设置为45时,其实验结果的分类准确率最高,达到了 0.9953;而切块步长在 20~40像素点之间保持1个恒定值0.9906;而切块步长由45变成50时,分类准确率下降到 0.967.同样,在图 3(b)的折线图中,也得到了相同的变化趋势.从中可以推断,当重叠切块的步长较小时不足以引起图像结构信息的改变,致使分类准确率维持不变;当重叠的步长比较大时,又丢失了部分结构信息,使其分类准确率迅速下降.故重叠切块的步长存在 1个最优值,使其既能够捕捉到图像像素间的相关性又能够很好地捕捉图像内部的结构信息,使其分类准确率达到1个最大值.
3 结 语
本文提出了一种基于融合图像的无参考立体图像质量评价算法,取得了较好的分类效果.网络模型通过使用图像融合算法,更好地模拟了人眼处理立体图像的过程,减少了数据量;通过使用迁移学习,减少了调参这个繁琐的过程,大大缩短了训练时间;最后利用人眼视觉显著性特性来处理图像小块的输出,使其更符合人眼视觉特性.
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30 06:25:30
小猕猴智力画刊(2021年4期)2021-05-11 18:13:56
农技服务(2020年8期)2020-08-19 04:13:38
长江蔬菜(2018年10期)2018-06-23 03:37:30
中学生数理化·中考版(2017年6期)2017-11-09 02:46:46
非公有制企业党建(2017年10期)2017-11-03 02:26:27
现代兵器(2017年4期)2017-06-02 15:59:24
现代兵器(2017年4期)2017-06-02 15:58:14
河北农业(2016年1期)2016-03-08 00:17:04
河北科技大学学报(2015年5期)2015-03-11 16:16:37
